我们结合《获取上证50的所有股票代码》,《根据股票代码和起始日期获取K线数据到excel表》两文中的脚本,搞出新的脚本:
import tkinter as tk
from tkinter import messagebox
from tkcalendar import Calendar
import pandas as pd
import requests
from urllib.parse import urlencode
import requests
from bs4 import BeautifulSoup
import os
import shutil
def gen_secid(rawcode: str) -> str:
'''
生成东方财富专用的secid
Parameters
----------
rawcode : 6 位股票代码
Return
------
str: 指定格式的字符串
'''
# 沪市指数
if rawcode[:3] == '000':
return f'1.{rawcode}'
# 深证指数
if rawcode[:3] == '399':
return f'0.{rawcode}'
# 沪市股票
if rawcode[0] != '6':
return f'0.{rawcode}'
# 深市股票
return f'1.{rawcode}'
def get_k_history(code: str, beg: str, end: str, klt: int = 101, fqt: int = 1) -> pd.DataFrame:
'''
功能获取k线数据
-
参数
code : 6 位股票代码
beg: 开始日期 例如 20200101
end: 结束日期 例如 20200201
klt: k线间距 默认为 101 即日k
klt:1 1 分钟
klt:5 5 分钟
klt:101 日
klt:102 周
fqt: 复权方式
不复权 : 0
前复权 : 1
后复权 : 2
'''
EastmoneyKlines = {
'f51': '日期',
'f52': '开盘',
'f53': '收盘',
'f54': '最高',
'f55': '最低',
'f56': '成交量',
'f57': '成交额',
'f58': '振幅',
'f59': '涨跌幅',
'f60': '涨跌额',
'f61': '换手率',
}
EastmoneyHeaders = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; WOW64; Trident/7.0; Touch; rv:11.0) like Gecko',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Referer': 'http://quote.eastmoney.com/center/gridlist.html',
}
fields = list(EastmoneyKlines.keys())
columns = list(EastmoneyKlines.values())
fields2 = ",".join(fields)
secid = gen_secid(code)
params = (
('fields1', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f11,f12,f13'),
('fields2', fields2),
('beg', beg),
('end', end),
('rtntype', '6'),
('secid', secid),
('klt', f'{klt}'),
('fqt', f'{fqt}'),
)
params = dict(params)
base_url = 'https://push2his.eastmoney.com/api/qt/stock/kline/get'
url = base_url+'?'+urlencode(params)
json_response: dict = requests.get(
url, headers=EastmoneyHeaders).json()
data = json_response.get('data')
if data is None:
if secid[0] == '0':
secid = f'1.{code}'
else:
secid = f'0.{code}'
params['secid'] = secid
url = base_url+'?'+urlencode(params)
json_response: dict = requests.get(
url, headers=EastmoneyHeaders).json()
data = json_response.get('data')
if data is None:
print('股票代码:', code, '可能有误')
return pd.DataFrame(columns=columns)
klines = data['klines']
rows = []
for _kline in klines:
kline = _kline.split(',')
rows.append(kline)
df = pd.DataFrame(rows, columns=columns)
return df
def select_start_date():
def on_date_selected():
selected_date = cal.selection_get()
start_date_entry.delete(0, tk.END)
start_date_entry.insert(0, selected_date.strftime('%Y%m%d'))
top.destroy()
top = tk.Toplevel(root)
cal = Calendar(top, selectmode='day')
cal.pack()
confirm_button = tk.Button(top, text='确认', command=on_date_selected)
confirm_button.pack()
def select_end_date():
def on_date_selected():
selected_date = cal.selection_get()
end_date_entry.delete(0, tk.END)
end_date_entry.insert(0, selected_date.strftime('%Y%m%d'))
top.destroy()
top = tk.Toplevel(root)
cal = Calendar(top, selectmode='day')
cal.pack()
confirm_button = tk.Button(top, text='确认', command=on_date_selected)
confirm_button.pack()
def get_kline_data(code,index):
# code = stock_code_entry.get()
start_date = start_date_entry.get()
end_date = end_date_entry.get()
# 修改文件保存的位置
save_path = os.path.join('sz50_all_k_data', f'{code}.csv')
try:
df = get_k_history(code, start_date, end_date)
df.to_csv(save_path, encoding='utf-8-sig', index=None)
print(index,'提示', f'股票代码:{code} 的 k线数据已保存到代码目录下的 {code}.csv 文件中')
except:
print(index,'错误',{code}, '获取K线数据失败')
def get_sz50_all_data():
url = "https://q.stock.sohu.com/cn/bk_4272.shtml"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
# 找到包含class为'e1'的元素
elements = soup.find_all(class_="e1")
# 提取数据并剔除非数字的成员
data_list = [element.text for element in elements if element.text.isdigit()]
# 打印list最终的成员
print(data_list)
#遍历所有成员,并调用get_kline_data
# 检查并创建目录
if not os.path.exists('sz50_all_k_data'):
os.makedirs('sz50_all_k_data')
else:
shutil.rmtree('sz50_all_k_data')
os.makedirs('sz50_all_k_data')
index=0
for code_tmp in data_list:
index += 1
get_kline_data(code_tmp,index)
print(">>>>>>>>>>>>>>>>完成")
root = tk.Tk()
root.title('上证50所有个股数据获取')
# stock_code_label = tk.Label(root, text='股票代码')
# stock_code_label.pack()
# stock_code_entry = tk.Entry(root)
# stock_code_entry.pack()
start_date_label = tk.Label(root, text='起始日期')
start_date_label.pack()
start_date_entry = tk.Entry(root)
start_date_entry.pack()
select_start_date_button = tk.Button(root, text='选择日期', command=select_start_date)
select_start_date_button.pack()
end_date_label = tk.Label(root, text='结束日期')
end_date_label.pack()
end_date_entry = tk.Entry(root)
end_date_entry.pack()
select_end_date_button = tk.Button(root, text='选择日期', command=select_end_date)
select_end_date_button.pack()
get_data_button = tk.Button(root, text='获取K线数据', command=get_sz50_all_data)
get_data_button.pack()
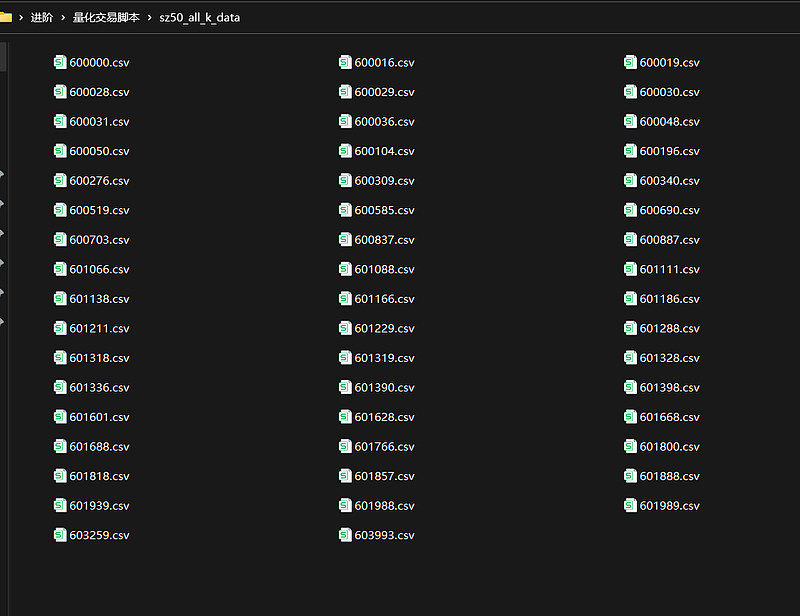
root.mainloop()效果:

保存到名为sz50_all_k_data的文件夹中: