前言
我从2020年进入人工智能行业,开始为AI训练提供存储解决方案及技术支持,随着这几年行业以及公司的发展,采用的存储方案经历了几次大的演变 ,最开始使用的是分布式并行文件系统Lustre,接着是BeeGFS+Ceph,再到最近的分布式异步对象存储DAOS,本文结合自己的经历,将历次存储架构/方案选型的背景,考量及部署,思考记录如下(保密要求,略过了部分配置及拓扑细节),供参考。
第一阶段
在2020年之前,国内AI还是以计算机视觉为主,如:AI四小龙,聚焦在计算机视觉,语音识别等方向的算法优化,以提高人脸,图形,物体的识别率,主要用于智能安防,智慧城市,智慧教育等行业。主要的训练数据类型是图片,音频。
AI与HPC有相似的地方,比如:都能用于科学技术,都需要高效的计算能力,都需要处理不断增长的数据集等,TensorFlow,PyTorch等机器学习框架对posix文件系统接口支持也更友好,因此在这个时期我们直接选用了HPC领域使用最广泛的文件系统Lustre作为AI存储基础设施。Lustre是一个Linux集群并行文件系统,提供了符合POSIX标准的UNIX文件系统接口,这对于不熟悉/没有存储背景的科研人员/Ai研究员非常友好,可以像访问本地文件数据一样访问Lustre文件系统上的数据。
与现在流行的分布式存储系统不同,Lustre没有实现原生的数据可靠性机制,服务的可用性也需要借助外部机制实现。为提供可靠的存储服务,综合考虑性价比,对于容量集群:在硬件层面,我们提供2节点MDS+2(2+)节点OSD的Lustre集群,采用IP-SAN盘阵作为Lustre系统的后端持久化介质,典型的配置:每个机头节点包含2颗62xx系列的CPU+512GB DDR4内存+100Gbps RoCE网络,24盘位的SATA-SSD盘阵组成RAID10作为Lustre MDT通过多路径挂载到两个MDS节点,80盘位的SAS-HDD盘阵组成RAID6作为Lustre OST通过多路径挂载到两个OSD节点;在系统和软件层面,2.10.x/2.12.x版本的Lustre部署在CentOS7.6/7.9系统上,2节点MDS组成Active-standy模式,通过crosync+pacemaker实现故障时的MDT和OST资源转移,提供5分钟级的故障恢复能力。
Lustre缓存集群没有强可靠性要求,因此直接使用存储节点上的本地NVMe SSD来搭建,6节点组成100TB的高性能集群,典型的硬件配置:每个节点包含2颗62xx系列的CPU+512GB DDR4内存+100Gbps RoCE网络+若干4TB的 NVMe SSD,在系统和软件层面,2.10.x/2.12.x版本的Lustre部署在CentOS7.6/7.9系统上。MemCache缓存集群使用各计算节点上的内存构成分布式缓存(提供对小于1MB图片的缓存)。
得益于Lustre系统良好的稳定性及性能,该存储方案较好的支持了公司的Ai训练业务及工作负载,截止2021年底,我们上线了数十套容量在500TB~3PB不等的Lustre容量集群以及数十套容量在100TB的Lustre缓存集群,总计存放了数十PB的数据集。在每个Ai训练(Slurm计算)分区,我们提供一套Lustre容量集群、一套Lustre缓存集群以及一套MemCache缓存集群作为整套存储方案,Lustre容量集群用于存储本分区的所有数据集,Lustre缓存集群作为用户家目录,主要用于存放训练代码,MemCache缓存集群用于加速训练中的图片访问。
第二阶段
从2021年初开始,随着积累的训练数据越来越多,每套集群数十亿平均几十KB的小图片以及单次Ai训练数据集规模从数十万~ 数百万增长到数千万~亿级小图片,运营Lustre集群过程中遇到的问题越来越多:
- 升级困难,集群可用性降低:Lustre是纯内核态实现,支持不足,修复Bug或者想要使用新特性需要停机升级,导致数小时不可用
- 数据孤岛,数据归集困难:分散各地的训练集群通过专线连接,跨地域跨集群访问效率低下,数据迁移困难
- 大量小文件,集群性能遇瓶颈:单集群数十亿单数十KB的图片,Lustre 元数据服务MDS遇到容量和性能瓶颈
- 并发训练,集群稳定性降低:训练程序与MemCache集群争抢内存,导致oom,Lustre过载导致客户端hang
- 集群众多,管理复杂:数十套集群,权限管理及资源分发运营量大,数据管理复杂
于是我们启动了Lustre的替代计划,首先我们分析了Ai训练过程及对存储的要求,如下表
| 数据采集 | 预处理 | 模型训练 | 推理 | ||
| 是指通过网络爬虫,数据采购等方式收集模型训练所需要的原始数据并储存起来(主要是图片) | 对采集的原始数据进行清洗和处理,如:去重,填充缺失值、删除异常值,(人工)标注等 | 主要是根据预定的目标和要求,选择合适的机器学习算法或构建深度学习网络(主要是CNN,RNN等),对预处理后的数据进行训练,建模 | 利用训练好的模型对新的数据进行预测,并将预测结果应用到实际场景中,例如分类、回归、聚类等 | ||
| 存储需求 | 具备处理高度多变数据格式的灵活性 | 减少数据准备时间 | 缩短训练时间 | 具备处理高度多变数据格式的灵活性 | |
| 对存储系统的要求 | 访问模式 | 随机写 | 随机 | 随机 | 随机 |
| 工作负载 | 写密集型 | 读写混合 | 读密集型(某些写入来自checkpoint) | 读密集型 | |
| I/O大小 | 小 | 小 | 小 | 小 | |
| 服务质量 | 高 | 高 | 非常高 | 非常高 | |
| IOPS | 非常高 | 非常高 | 非常高 | 中等 | |
厘清需求后,我们分析调研了IO 500榜单中及各流行的开源存储系统,如:Ceph,BeeGFS,Glusterfs,SeaweedFS,JuiceFS,CubeFS,DAOS等,结合上述的存储需求及自身的研发能力,从存储系统的可靠性,可用性,可维护性,可扩展性,社区支持能力,性能等11个指标对主流的系统进行了评估以及测试,鉴于BeeGFS对Posix的良好支持、优秀的扩展能力及优异的性能表现等,Ceph优秀的稳定性及活跃的社区支持等,最终我们选择了BeeGFS+Ceph OSS作为我们新的Ai存储技术方案。
BeeGFS可以看作是应用态实现的增强型的Lustre版本,其除私有客户端在内核态实现,服务端组件都在应用态实现,相比Lustre极大的简化了维护成本以及降低了开发难度,相比Lustre,BeeGFS的增强主要体现在:分布式的MDS集群,可以轻松扩展到数十组节点,支持数PB的容量以及基于副本的可靠性,BeeGFS也有不足的地方,如:单节点MGS,不支持QoS,依赖本地文件系统(Ext4、XFS、ZFS)的Quota,单目录文件数受限等,因此在上线前,我们也对这些方面进行了增强:实现了基于Raft的MGS,多副本的可靠性,基于目录的QoS,基于目录/用户/用户组的Quota等。在我们的方案中,BeeGFS用作用户家目录,存放代码仓库以及训练数据缓存,因此,我们采用高配置部署,每套集群包含数十台节点,提供数PB容量,千万级IOPS:每个节点包含2颗63xx系列的CPU+512GB DDR4内存+100Gbps RoCE网络+若干7.68TB的 NVMe SSD。
Ceph OSS得益于其优秀的稳定性,在国内被大规模的使用,是用作数据湖的不错选项。在我们的方案中,Ceph OSS用作原始数据仓,提供HDD存储池以及SSD存储池,HDD存储池用于存放采集的原始数据,鉴于数据量较大,我们采用了大容量HDD磁盘,每套集群包含近百台节点,提供数十PB容量:每台节点包含2颗63xx系列的CPU+256GB DDR4内存+100Gbps RoCE网络+数十块18TB的SATA HDD,SSD用于存放处理后的数据以及checkpoint,兼具容量和性能,每套集群包含数十个节点,提供数PB容量:每个节点包含2颗63xx系列的CPU+512GB DDR4内存+100Gbps RoCE网络+若干7.68TB的 NVMe SSD。
为方便系统的运营管理,我们开发了一套数据管理系统,用于上线后的系统运维和运营,实现资源的可视化发放,用户数据的可视化管理,数据迁移等。
随着新采集数据的存入以及Lustre数据逐步迁移到新集群,截止2022年下旬,我们在两个机房分别上线了一套新架构存储集群: 2PB的BeeGFS+30PB的Ceph OSS HDD+4PB的Ceph OSS SSD,支撑了公司绝大部分的Ai训练任务及工作负载(少部分在Lustre上),存储网络示意图如下:
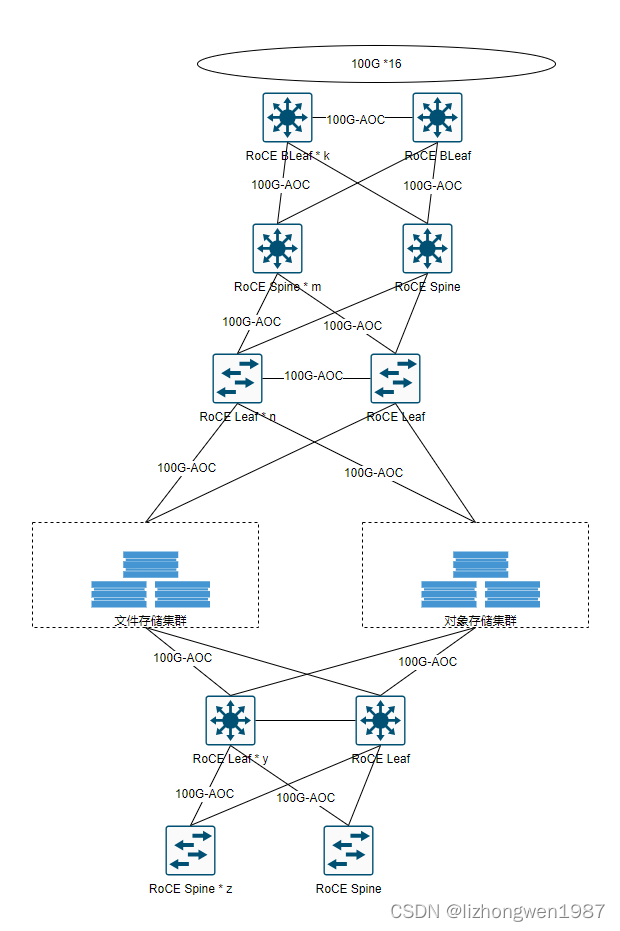
随着Lustre数据逐步迁移,新存储架构成为公司主要Ai存储设施,Lustre系统面临的升级问题,数据孤岛问题,性能问题以及管理问题等都得到了极大的缓解及改善。
当前
上线以来,基于BeeGFS+Ceph OSS的Ai存储系统整体运行良好,目前仍然是我们线上的主存储系统,使用率已超过60%,随着大模型的火爆也带来了一些挑战。2022年11月OpenAI发布ChatGPT3.5后,国内也掀起了“LLM百团大战”。与计算机视觉以图片,音频,视频为训练数据不同,大模型的训练数据为文本,多模态则包含了文本,图片,后面可能还会包含音频,视频等。采集的文本,通常是数GB的文本文件,生成的tokenize文件也在数(十)MB,与计算机视觉的处理过程相同,大模型训练也包含4个阶段:
| 数据采集 | 预处理 | 模型训练 | 推理 | ||
| 是指通过网络爬虫,数据采购等方式收集模型训练所需要的原始数据并储存起来(主要是文本) | 对采集的原始数据进行清洗和处理,如:去重,去广告,格式化,tokenize等 | 主要是根据预定的目标和要求,选择合适的机器学习算法或构建深度学习网络(主要是Transformer),对预处理后的数据进行训练,建模 | 利用训练好的模型对新的数据进行预测,并将预测结果应用到实际场景中,例如问答,生图等 | ||
| 存储需求 | 具备处理高度多变数据格式的灵活性 | 减少数据准备时间 | 缩短训练时间 | 具备处理高度多变数据格式的灵活性 | |
| 对存储系统的要求 | 访问模式 | 顺序写 | 随机 | 随机 | 随机 |
| 工作负载 | 写密集型 | 读写混合(可能达到50/50) | 读密集型(某些写入来自checkpoint) | 读密集型 | |
| I/O大小 | 大 | 大 | 小 | 小 | |
| 服务质量 | 高 | 高 | 非常高 | 非常高 | |
| 吞吐量 | 非常高 | 非常高 | 非常高 | 中等 | |
对比上述的两个表格,可以发现大模型对存储系统的要求比计算机视觉更高。计算机视觉训练更多的是随机小I/O,对IOPS和延迟更敏感,大模型训练则是混合I/O,对IOPS,吞吐及延迟都提出了很高的要求。
2023以来,随着大模型参数的急剧增长,以及新热点的出现,如:长文本处理,文图多模态训练等,当前BeeGFS+Ceph OSS的存储方案也面临挑战,主要表现在:
- 吞吐不足,带来训练加载以及checkpoint写入等待(对于checkpoint目前是先写到计算节点的本地NVMe盘,再异步回写到后端存储上)
- 目录或存储桶性能扩展性不足,导致目录或存储桶存放的文件数受限,大目录访问性能下降
- 存储效率偏低,BeeGFS和Ceph引擎面向HDD设计,NVMe的性能效率较低
鉴于此,Intel Daos再次进入了我们的视线,在此前考虑到产品的成熟度,稳定性以及Intel Optane停产风险等因素后,Daos被排除出第二阶段的候选方案。经过两年多的发展,基于(intel Optane)的Daos版本开始成熟,商业及云方案也开始出现,如:Google Cloud和IBM Cloud上的DAOS方案, Metadata-on-SSD的技术落地社区也在如火如荼的推进中(第一版已经发布),根据社区计划,预计24年Q1发布完整的Metadata-on-SSD的功能,考虑到DAOS对新型硬件的支持能力及未来CXL技术的发展和应用,和存储的发展趋势,我们认为:用DAOS方案替代BeeGFS+Ceph OSS方案是个值得尝试的选项,目前已经在内部测试及验证DAOS Metadata-on-SSD版本替代BeeGFS的可行性,第一阶段计划24年H1线上试点,取代新增的BeeGFS需求。
注:据观察了解,现在Ai项目还处于不计成本阶段,Ai基础设施的成本大头在计算(GPU)和高性能网络,而Ai的绝对数据量还不大(PB级),千亿级参数
Ai训练的数据集规模通常在数TB级别,就当下的实践而言,采用基于NVMe SSD的高性能分布式文件系统就能满足Ai工作负载要求。我们方案中采用的
BeeGFS是为HPC专门设计的并行文件系统,经过优化后也能很好的满足当前的需求。
观察和思考
AI存储应该是怎么样的?
AI存储专为满足AI独特的工作负载而设计和优化,这些工作负载通常包括大规模数据集、高吞吐低延迟数据访问以及复杂的数据处理。结合自身实践经验及观察,AI存储应在以下方面对AI工作负载进行优化:
- 高吞吐:AI工作负载通常需要快速处理大规模的数据集,存储系统具备高吞吐能力,可以高效的在存储和计算间传输数据,确保计算效率最大化
- 低延迟:快速的数据访问对AI应用至关重要,存储系统应以最小的延迟,提供最快速的数据检索和存储
- 并行性:AI工作负载高度并行化,存储系统支持并行数据访问,可以实现AI算法的高效并行处理
- 扩展性:AI项目通常需要存储和处理大规模的数据,存储系统必须能够轻松扩展以满足不对增长的容量和性能需求
- 数据分层:AI项目通常会沉淀海量的数据,AI存储可以采用分层技术将经常访问的数据放置在高性能存储层上,而不经常访问的数据放置在容量层上,这有助于平衡性能和成本
- 数据安全:AI工作负载通常涉及敏感数据,AI存储应考虑数据安全和隐私措施,如:访问控制,法规遵从,加密等
- 易用性:AI存储应与主流的AI框架易于集成,方便AI研究员及科学家的协作与使用