优先队列+哈希集合+反向思维(或自定义排序)
模拟,请直接看算法思路:
两个哈希集合S1和S2, S1存正面词汇,S2存负面词汇;一个优先队列pq,pq存{score, id}键值对,即学生分数-学生id。
算法流程:
- 初始化S1和S2
- 遍历report,report里存的是句子,每个句子report[i]对应一个学生student_id[i]的评价,抠出句子的每个单词report[i][j],将单词分数(对照哈希集合)加给学生。上述流程确定了学生student_id[i]的分数,将学生分数加入优先队列。
- 记录前k个学生id,存入答案数组ans,ans即为所求。
请注意:优先队列默认大根堆,按fisrt成员从大到小排序;在first成员相等时,按照second成员从大到小排序。score是first成员,id是second成员,出现矛盾:当score相同时,题目要求id从小到大排序。解决方法:1. 将score变为负数,或将id变为负数。2. 自定义排序规则(优先队列);本题解将score变为负数,解决了矛盾。
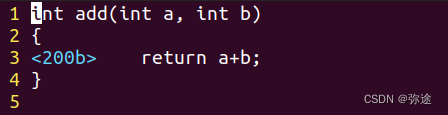
class Solution {
public:
vector<int> topStudents(vector<string>& positive_feedback, vector<string>& negative_feedback, vector<string>& report, vector<int>& student_id, int k) {
// 哈希集合
unordered_set<string> S1, S2;
vector<int> ans = vector<int> (k, 0); // 保存答案的ans顺序
priority_queue <pair<int, int>, vector<pair<int,int>>> pq; // 存{score, id}键值对。
for (int i = 0; i < positive_feedback.size(); i ++) {
S1.insert(positive_feedback[i]);
}
for (int i = 0; i < negative_feedback.size(); i ++) {
S2.insert(negative_feedback[i]);
}
for (int i = 0; i < report.size(); i ++) {
int j = 0; // 遍历report[i];
int score = 0, id = student_id[i];
while (j < report[i].size()) {
string t = "";
while (j < report[i].size() && report[i][j] != ' ') {
t += report[i][j ++];
}
j ++;
if (S1.count(t)) score -= 3; // 得分,数值变小
else if (S2.count(t)) score ++; // 扣分,数值变大
}
pq.push({score, id});
if (pq.size() > k) pq.pop();
}
int i = k - 1;
while (i >= 0) { // while (pq.size() && i >= 0) {
int id = pq.top().second;
pq.pop();
ans[i --] = id;
}
return ans;
}
};
时间复杂度
O
(
n
l
o
g
k
)
O(nlogk)
O(nlogk) :
n
n
n是
r
e
p
o
r
t
report
report的长度,
k
k
k 是常数(奖励最顶尖的前k名学生),优先队列内部最多维护
k
+
1
k+1
k+1名学生,一共
n
n
n名学生进一次优先队列,最多
n
n
n名学生出一次优先队列,时间复杂度
O
(
n
l
o
g
k
)
O(nlogk)
O(nlogk)。
空间复杂度
O
(
n
)
O(n)
O(n) : 两个哈希集合/ans数组的空间复杂度
O
(
n
)
O(n)
O(n),优先队列的最坏空间复杂度
O
(
k
)
O(k)
O(k),总体空间复杂度
O
(
n
)
O(n)
O(n) 。
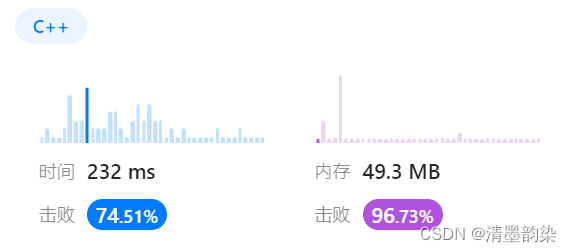
AC
致语
- 理解思路很重要。
- 请读者放心留言,可以是疑惑的点,或者感谢/夸奖也可以!!墨染看到会回复的。