文章目录
- 前言
- 一、EfficientNet V2
- 1. 网络简介
- 2. EfficientNetV1弊端
- 🥇训练图像的尺寸很大时,训练速度非常慢
- 🥈在网络浅层中使用Depthwise convolutions速度会很慢
- 🥉同等的放大每个stage是次优的
- 3.NAS Search
- 4. Progressive Learning渐进学习策略
- 5.EfficientNetV2网络框架
- 二、网络实现
- 1.构建EfficientNetV2网络
- 2.加载数据集
- 3.训练和测试模型
- 三、实现图像分类
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
Google 在2021年4月份提出了 EfficientNet 的改进版 EfficientNet v2: Smaller Models and Faster Training。从论文题目上就可以看出 v2 版本相比 v1,模型参数量更小,训练速度更快。
一、EfficientNet V2
EfficientNet V2主要创新点:
⋆
\star
⋆引入Fused-MBConv模块,新的更高效的网络结构EfficientNet V2
⋆
\star
⋆提出了改进的渐进式学习方法,根据训练图片的尺寸动态的调节正则化方法,可以提升训练速度及准确率。
1. 网络简介
在 EfficientNet V1的基础上,引入了Fused-MBConv到搜索空间中,同时为 渐进式学习引入了自适应正则强度调整机制。两种改进的组合使得 EfficientNet v2 在多个基准数据集上取得了 SOTA 性能,且训练速度更快。比如 EfficientNet v2 取得了87.3%的 top1 精度且训练速度快5-11倍。
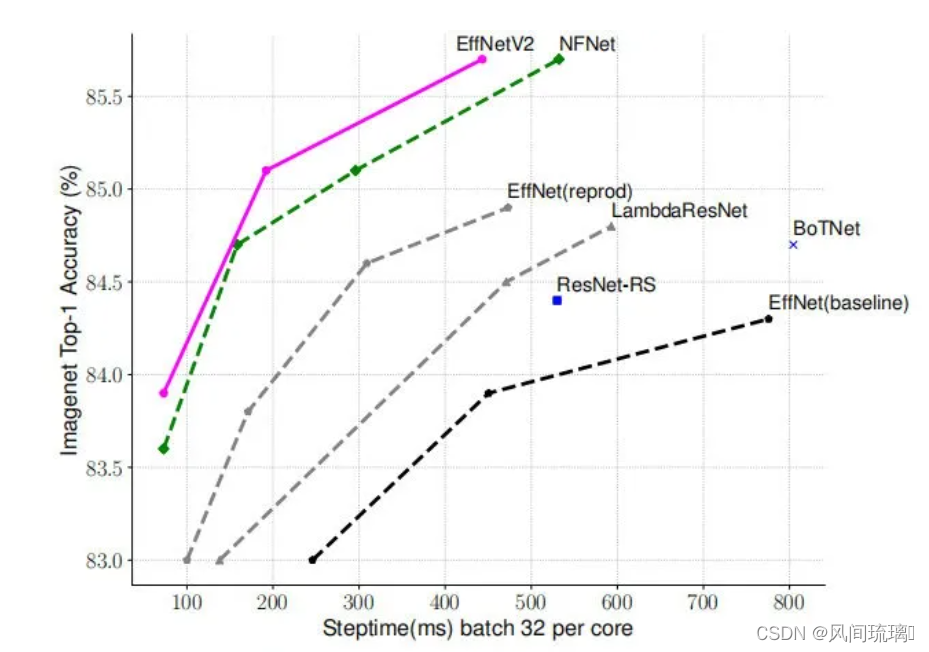
EfficientNet v2 与其他 SOTA 模型在训练速度、参数量以及精度方面的对比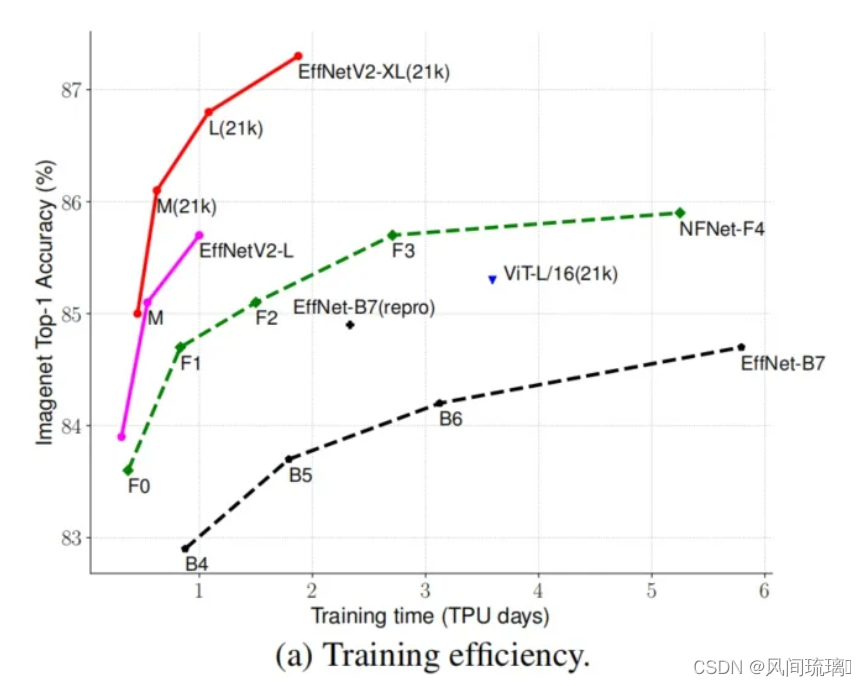
通过上图很明显能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少。EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
2. EfficientNetV1弊端
要改进 EfficientNet,首先要分析存在的问题,本文共指出三个方面的训练瓶颈问题:
🥇训练图像的尺寸很大时,训练速度非常慢
EfficientNet 在较大的图像输入时会使用较多的显存,如果 GPU/TPU 总显存固定,此时就要降低训练的batch size,这会大大降低训练速度。

通过上表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24网络可以训练,当训练的图像尺寸为512x512时,batch_size=24时出现OOM(Out Of Memory)。而且增大了img_size,Acc并没有增加。所以,针对这个问题一个比较好想到的办法就是适当降低训练图像的尺寸。
一种解决方案就是采用较小的图像尺寸训练,采用更小的图像块会导致更小的计算量、更大的batch,可以加速训练(2.2x);与此同时,更小的图像块训练还会导致稍高的精度。
但在论文中提出了一种更高级的训练技巧:progressive Learning,通过渐进式调整图像尺寸和正则化因子达到训练加速的目的。
🥈在网络浅层中使用Depthwise convolutions速度会很慢
EfficientNet 中大量使用 depthwise conv,相比普通卷积,它的好处是参数量和 FLOPs 更小,但是它并不能较好地利用现代加速器(GPU/TPU)。 虽然理论上计算量很小,但是实际上使用起来并没有想象中的快。
Google 提出了 Fused-MBConv结构去更好的利用移动端或服务端的加速器,其结构是 把 MBconv 结构中的 depthwise conv3x3 和 expansion conv1x1 替换成一个普通的conv3x3,如下图所示。
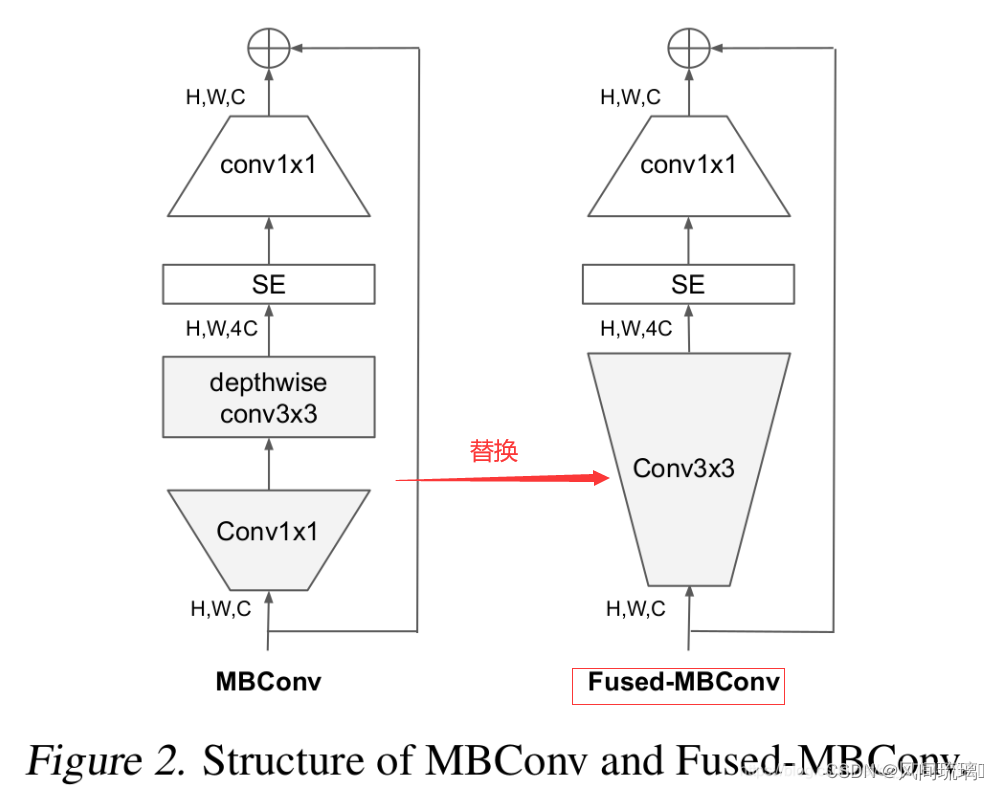
在 Edge TPU 测试发现虽然前者的参数量和计算量更少,但是由于常规的conv更能较好地利用TPU,反而后者的执行速度更快。
作者在EfficientNet-B4上进行测试,并发现 将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如下表所示。
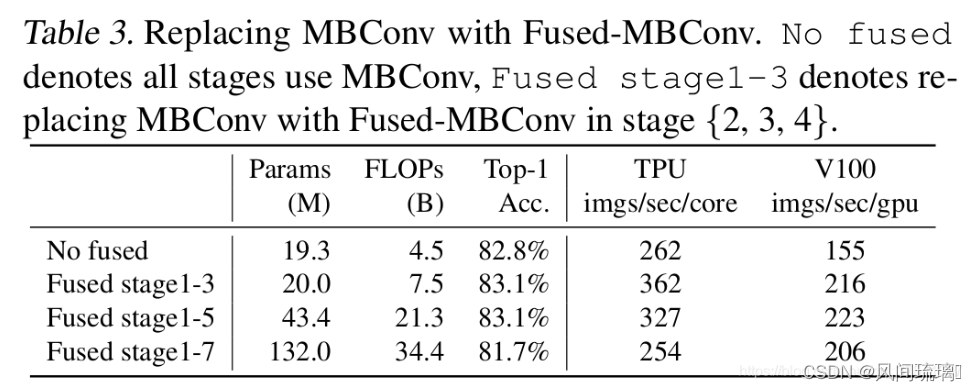
这里逐渐将 EfficientNet-B4 的 MBConv 替换成 Fused-MBConv,发现如果将 stage1~3 替换为 Fused-MBConv 可以加速训练并带来少量的参数量与 FLOPs 提升;但如果将全部 stage 替换,此时参数量和 FLOPs 大幅度提升,但是训练速度反而下降。这说明适当地组合 MBConv 和 Fused-MBConv 才能取得最佳效果,所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。
🥉同等的放大每个stage是次优的
EfficientNetV1 的各个 stage 均采用一个复合缩放策略,每个stage的深度和宽度都是同等放大的。比如 depth 系数为2时,各个 stage 的层数均加倍。
但是不同stage在训练速度和参数量的影响并不一致,同等缩放所有stage会得到次优结果。此外,针对 EfficientNet 的采用大尺寸图像导致大计算量、训练速度降低问题,作者对缩放规则进行了轻微调整并设定了最大图像size的限制,用了非均匀的缩放策略来缩放模型。
3.NAS Search
基于上述的三个问题分析,为了提升训练速度,EfficientNet v2 采用training-aware NAS来设计,优化目标包括 accuracy,parameter efficiency 和 training efficiency,搜索的卷积单元包括 MBConv 和 Fused MBConv。
这里是以EfficientNet作为backbone,设计空间包含:
⋆
\star
⋆ convolutional operation type : {MBConv, Fused-MBConv}
⋆
\star
⋆ number of layer
⋆
\star
⋆ kernel size : {3x3, 5x5}
⋆
\star
⋆ expansion ratio (MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3): {1, 4, 6}
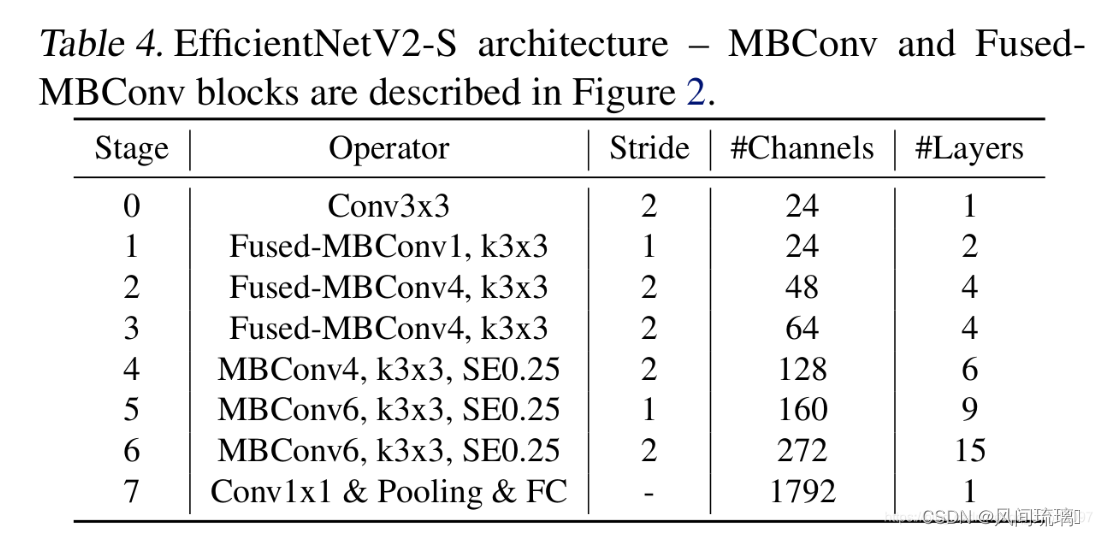
搜索得到的 EfficientNetV2-S 模型,如下表
EfficientNet-B0的网络结构,如下表所示
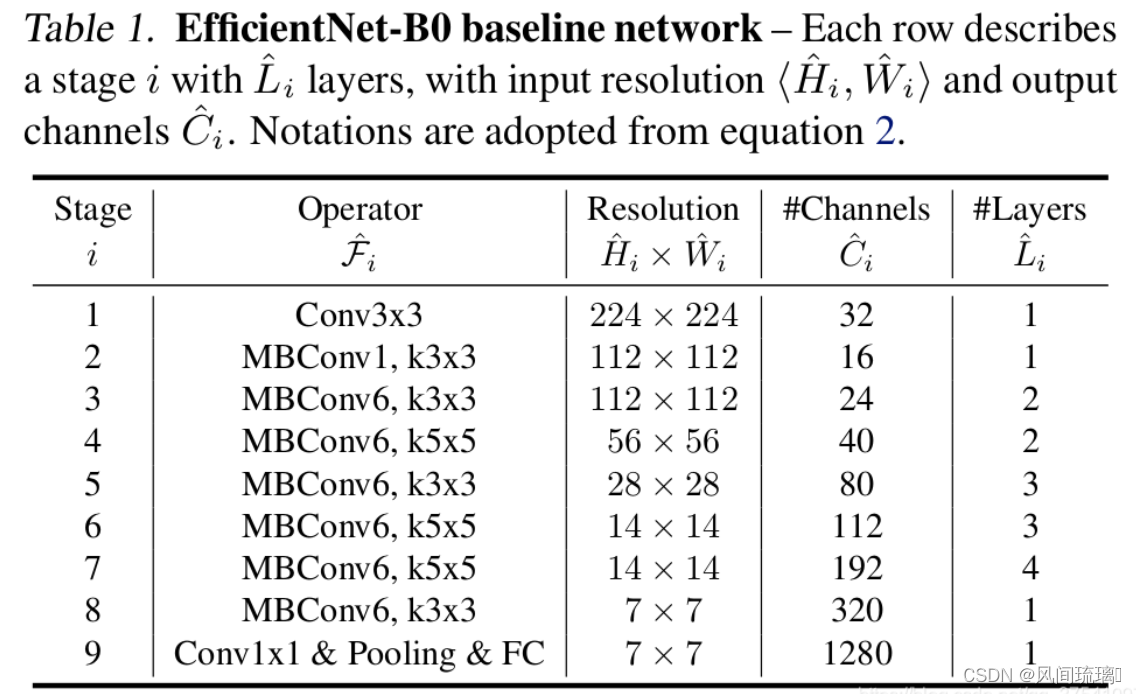
相比v1结构,v2在前1~3个 stage 采用 Fused MBConv;另外可以看出前面stage的MBConv的 expansion ratio 较小,而v1的各个 stage 的 expansion ratio 几乎都是6;V1部分 stage 采用了5x5卷积核,而V2只采用了3x3卷积核,但包含更多 layers 来弥补感受野;V2中也没有V1中的最后的 stride-1的stage。这些区别让 EfficientNet v2 参数量更少,显存消耗也更少。
对 EfficientNetV2-S 进行缩放,可以进一步得到另外两个更大的模型: EfficientNetV2-M 和 EfficientNetV2-L。v2 缩放规则相比 v1 增加两个额外的约束,一个是限制图像最大size(最大480),二是后面的stage的layers更大, 后两个较大的模型的输入size均为480。
下图给出了 EfficientNetv2 模型在 ImageNet 上 top-1 acc 和 train step time,这里的训练采用固定的图像大小,不过比推理时图像大小降低30%,而图中的 EffNet(reprod) 也是采用这样的训练策略,比 baseline 训练速度和效果均有明显提升,而 EfficientNet v2 在训练速度和效果上有进一步地提升。
4. Progressive Learning渐进学习策略
除了模型设计优化,论文还提出了一种 progressive learning 策略来进一步提升 EfficientNet v2 的训练速度,即训练过程渐进地增大图像大小,但在增大图像同时也采用更强的正则化策略,训练的正则化策略包括数据增强和 dropout 等。
在V1中作者研究了训练图像尺寸、网络深度、网络宽度对Acc的影响。训练图像的尺寸对训练模型的效率有很大的影响。在之前的一些工作中很多人尝试使用动态的图像尺寸,一开始用很小的图像尺寸,后面再增大来加速网络的训练,但通常会导致Accuracy降低。
对于Accuracy降低的原因,作者提出了一个猜想:Accuracy的降低是不平衡的正则化unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。
为了验证这个猜想,作者接着做了一些实验。在前面提到的搜索空间中采样并训练模型,训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强data augmentations。当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。
不同的图像输入采用不同的正则化策略,这不难理解,在早期的训练阶段,用更小的图像和较弱的正则化来训练网络,这样网络就可以轻松、快速地学习简单的表示。然后,逐渐增加图像的大小,但也通过增加更强的正则化,使学习更加困难。
如下表所示,当Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好:

在训练过程中,作者将整个训练划分为4个阶段,每个阶段87个 epoch:在训练的早期采用小图像块+弱化正则;在训练的后期采用更大的图像块+增强的正则,每进入一个阶段,图像大小以及数据增强均线性提升。

如上图图所示,在训练早期使用较小的训练尺寸以及较弱的正则方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法adding stronger regularization。
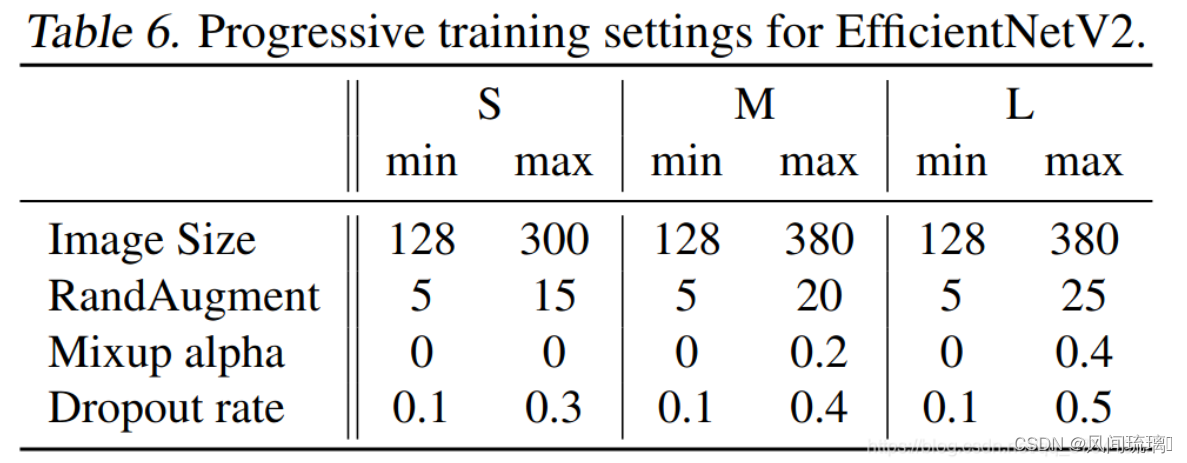
表格中给出了不同模型训练过程的输入图像大小以及数据增强的范围(输入图像尺寸和正则强度的最大、最小值),这里的训练最大 image size 大约比推理时小30%:380 vs 480。z作者主要研究了以下三种正则:Dropout、RandAugment 以及 Mixup。
作者将渐进式学习策略抽象成了一个公式来设置不同训练阶段使用的训练尺寸以及正则化强度。对于不同阶段直接使用线性插值的方法递增。具体流程如下:

假设整个训练过程有N步,目标训练尺寸(最终训练尺度)是
S
e
S_e
Se,正则化列表(最终正则强度)
ϕ
e
=
[
ϕ
e
k
]
\phi_e = {[ \phi_e^k ]}
ϕe=[ϕek],其中k代表k种正则方法(三种正则:Dropout、RandAugment 以及 Mixup。)。初始化训练尺寸
S
0
S_0
S0,初始化正则化强度为
ϕ
0
=
[
ϕ
0
k
]
\phi_0 = [{\phi_0^k}]
ϕ0=[ϕ0k]。
然后将整个训练过程划分成M个阶段,对于第i个阶段(1 ≤ \leq ≤ i ≤ \leq ≤ M),模型的训练尺寸为 S i S_i Si,正则化强度为 ϕ i = [ ϕ i k ] \phi_i = [{\phi_i^k}] ϕi=[ϕik],对于不同阶段直接使用线性插值的方法递增。具体流程如上所示。
5.EfficientNetV2网络框架
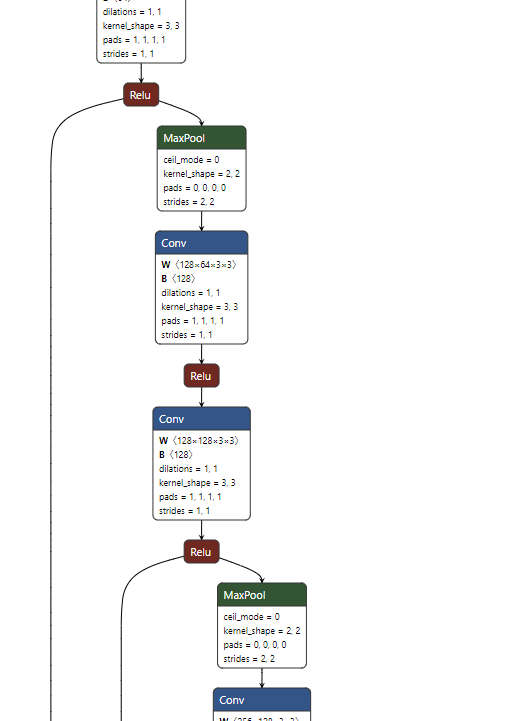
如下图是EfficientNetV2-S的网络结构,需要注意的是:
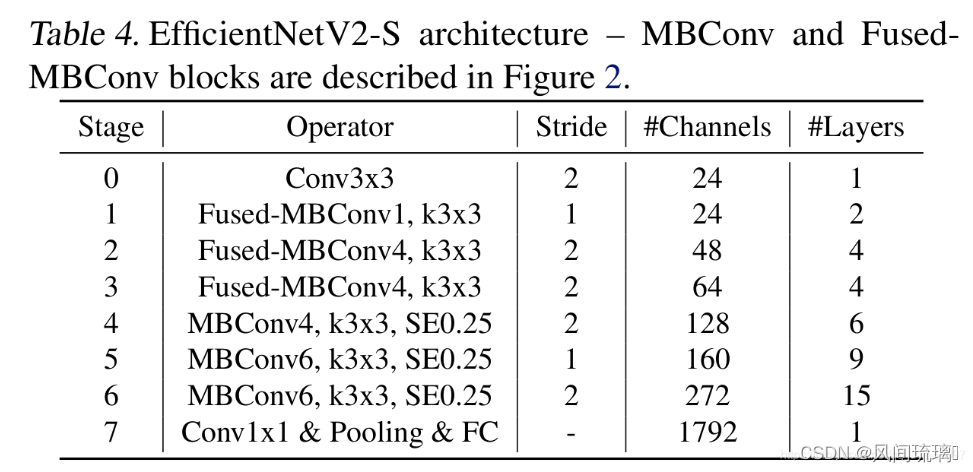 通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
通过上表可以看到EfficientNetV2-S分为Stage0到Stage7(EfficientNetV1中是Stage1到Stage9)。Operator表示在当前Stage中使用的模块:
⋆
\star
⋆ Conv3x3: 普通的3x3卷积 + 激活函数(SiLU)+ BN
⋆
\star
⋆ Fused-MBConv模块:模块名称后的1,4表示expansion ratio,k3x3表示kenel_size为3x3。如下图所示
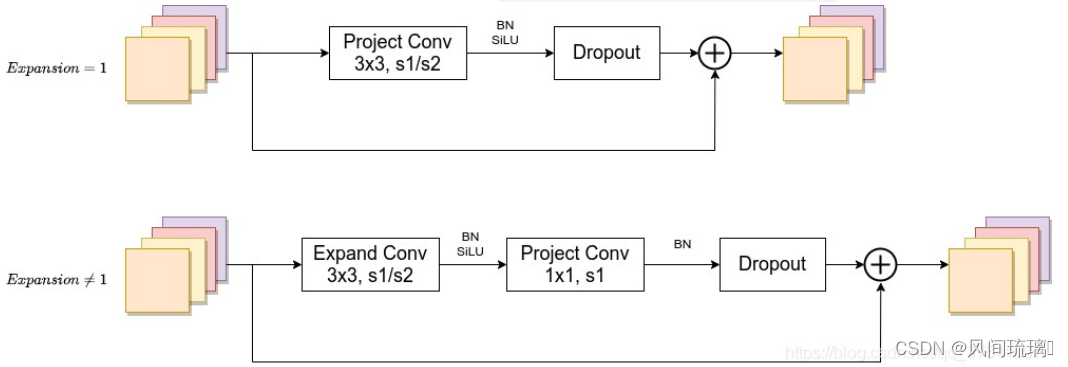
当expansion ratio =1时,模块中没有expand conv的,这里也没有SE(原论文图中有SE)。
当stride=1且输入输出Channels相等时才有shortcut连接。当有shortcut连接时才有Dropout层,而且这里的Dropout层是Stochastic Depth,即会随机丢掉整个block的主分支,只shortcut分支,减少了网络的深度。
⋆
\star
⋆ MBConv模块: EfficientNetV1中是一样的,如下图所示,

其中模块名称后跟的4,6表示expansion ratio
⋆
\star
⋆ SE0.25表示使用了SE模块,0.25表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的 1/4;
⋆
\star
⋆ stride表示每个stage中第一个MBConv中的stride,其余的MBConv的stride=1;注意当stride=1且输入输出Channels相等且有Dropout时才有shortcut连接;
⋆ \star ⋆ channels表示该Stage输出的特征矩阵的;
⋆ \star ⋆ Layers表示每一个stage中Operator的重复次数;
EfficientNet-V1和EfficientNet-V2的网络结构对比:
①EfficientNetV2中除了使用到MBConv模块外,还使用了Fused-MBConv模块(主要是在网络浅层中使用)。
②EfficientNetV2使用较小的expansion ratio,比如4。在EfficientNetV1中基本是6,这样能够减少内存访问开销。
③EfficientNetV2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。通过上表可以看到使用的kernel_size全是3x3的,由于3x3的感受野是要比5x5小的,所以需要堆叠更多的层结构以增加感受野。
④移除了EfficientNetV1中最后一个步距为1的stage,可能是因为它的参数数量过多并且内存访问开销过大。
二、网络实现
1.构建EfficientNetV2网络
2.加载数据集
3.训练和测试模型
三、实现图像分类
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。




![[ICCV-23] DeformToon3D: Deformable Neural Radiance Fields for 3D Toonification](https://img-blog.csdnimg.cn/7e380c05d6b44621b4e0e93b7d7abc06.png)