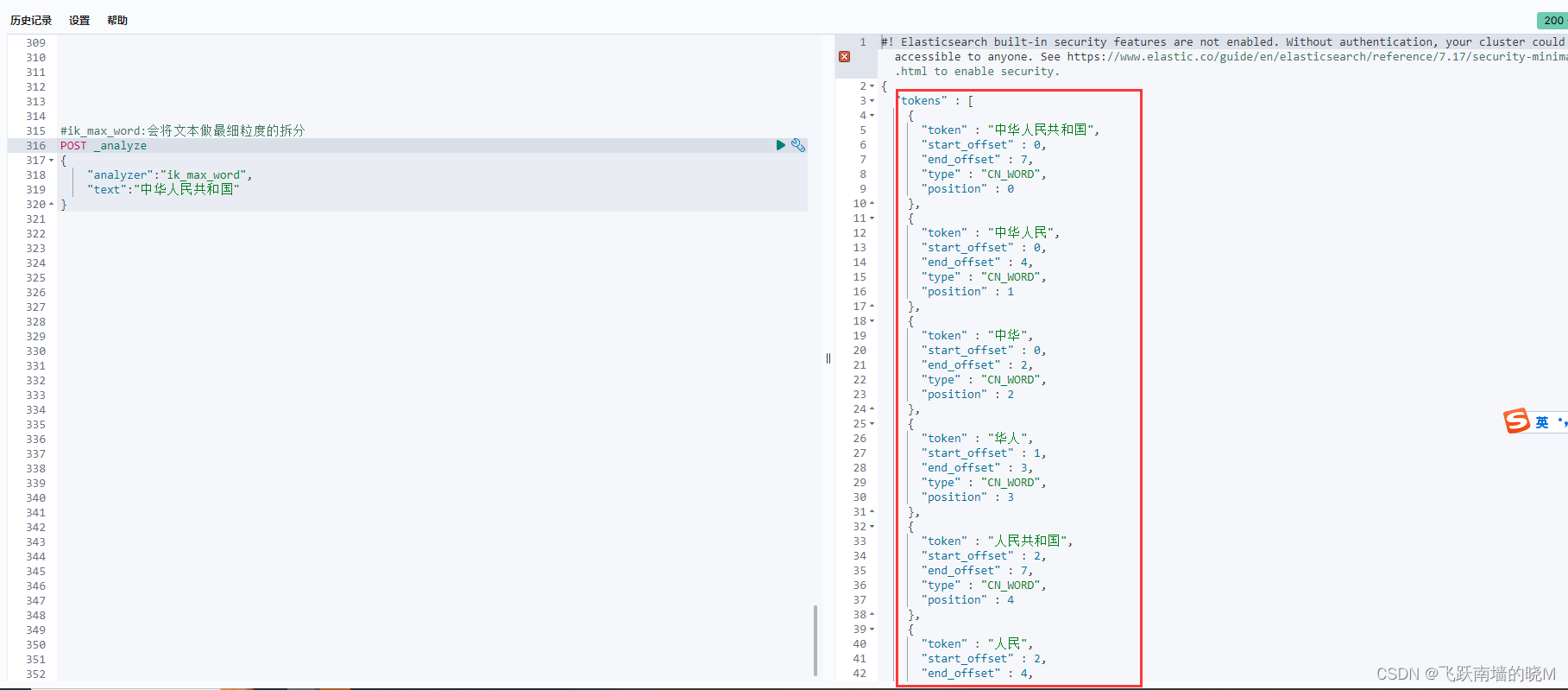
1、RDB持久化
Redis是一个键值对数据库服务器,服务器中通常包含着任意个非空数据库,而每个非空数据库中又可以包含任意个键值对,通常情况下将服务器中的非空数据库以及它们的键值对统称为数据库状态
Redis是内存数据库,它将自己的数据库状态储存在内存里面,如果不想办法将存储在内存中的数据库状态保存到磁盘中,那么一旦服务器进程退出,服务器中的数据库状态也会消失不见。
为了解决持久化相关的问题,Redis提供了RDB持久化功能,这个功能可以将Redis在内存中的数据库状态保存到磁盘里面,避免上述数据意外丢失的情况。
RDB持久化既可以手动执行,也可以根据服务器配置选项定期执行,该功能可以将某个时间点上的数据库状态保存到一个RDB文件中,如下图所示:
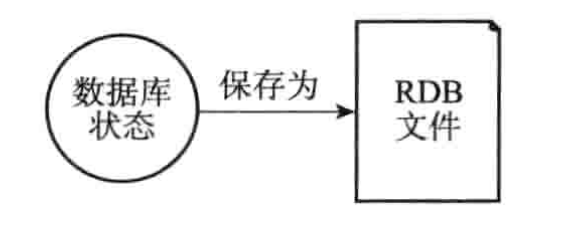
RDB持久化功能所生成的RDB文件是一个经过压缩的二进制文件,通过该文件可以还原成RDB文件中保存某个时间点的数据库状态,如下图所示:
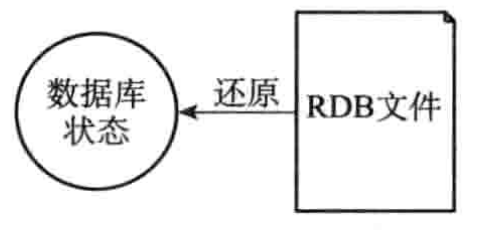
因为RDB文件是保存在硬盘里面的,所以即使Redis服务器进程退出,甚至运行Redis服务器的计算机停机,但只要RDB文件仍然存在,Redis服务器就可以用RDB文件来还原数据库状态。
1.1、RDB文件的创建与载入
在Redis服务器中,有两个Redis命令可以用于生产RDB文件,一个是SAVE,另外一个是BGSAVE
SAVE命令会阻塞Redis服务器进程,直到RDB文件创建完毕为止,在服务区进程阻塞期间,服务器不能处理任何命令请求:
127.0.0.1:6379 > SAVE // 等待RDB文件创建完毕,才会处理其他命令
OK
BGSAVE命令会派生出一个子进程,然后由子进程负责创建RDB文件,服务器进程(父进程)继续处理命令请求:
127.0.0.1:6379> BGSAVE // 派生子进程,并由子进程创建RDB文件
Background saving started
上述两个创建RDB文件的工作,是由rdb.c/rdbSave函数完成的,SAVE命令和BGSAVE命令会以不同的方式调用这个函数:
def SAVE() :
# 创建RDB文件
rdbSave();
def BGSAVE() :
# 创建子进程
pid = fork()
if pid = 0 :
# 子进程负责创建RDB文件
rdbSave()
# 完成之后向父进程发送信号
signal_parent()
elif pid > 0 :
# 父进程继续处理命令请求,并通过轮训等待子进程的信号
handle_request_and_wait_signal()
else :
# 处理出错情况
handle_fork_error()
RDB文件的载入工作是在服务器启动时自动执行的,Redis服务器在启动时检测到RDB文件存在,就会自动载入RDB文件
1.2、自动间隔性保存
SAVE命令与BGSAVE命令的实现方式主要有以下区别:
-
SAVE命令由服务器进程执行保存工作,SAVE会阻塞服务器
-
BGSAVE命令则由子进程执行保存工作,BGSAVE不会阻塞服务器
由于BGSAVE命令可以在不阻塞服务器进程的情况下执行,所以Redis允许用户通过设置服务器配置的save选项,让服务器每隔一段时间自动执行一次BGSAVE命令
服务器状态中会保存所有用save选项设置的保存条件,当任意一个保存条件被满足时,服务器会自动执行BGSAVE命令
配置案例如下:
# 服务器在900秒之内,对数据库进行了至少1次修改
save 900 1
# 服务器在300秒之内,对数据库进行了至少10次修改
save 300 10
# 服务器在60秒之内,对数据库进行了至少10000次修改
save 60 10000
1.3、RDB文件结构
RDB文件是一个经过压缩的二进制文件,由多个部分组成。
RDB的文件结构如下:

全大写单词表示常量,全小写单词表示变量和数据
-
REDIS
-
这是RDB文件最开头的部分
-
该部分长度为5字节
-
保存着“REDIS”五个字符
-
通过该部分保存的五个字符,程序可以在载入文件时,快速检查所载入的文件是否是RDB文件
-
-
db_version
-
长度为4字节
-
它的值是一个字符串表示的整数
-
记录了RDB文件的版本号
-
-
databases
-
包含着零个或者任意多个数据库(非空数据库)
-
以及各个数据库中的键值对数据
-
-
EOF
-
这个常量长度为1字节
-
标志着RDB文件正文内容的结束
-
当读取程序遇到这个值的时候,表示数据库的所有键值对都已经载入完毕了
-
-
check_sum
-
8字节长度的无符号整数
-
保存着一个校验和
-
这个校验和是程序通过对REDIS、db_version、databases、EOF四个部分的内容进行计算得出的
-
服务器在载入RDB文件时,会将载入数据所计算出的校验和与check_sum所记录的校验和进行对比,以此来检查RDB文件是否出错或者损坏的情况出现
-
2、AOF持久化
除了上述提及的RDB持久化功能之外,Redis还提供了AOF(Append Only File)持久化功能。
AOF持久化是通过保存Redis服务器所执行的写命令来记录数据库状态的,如下图所示:
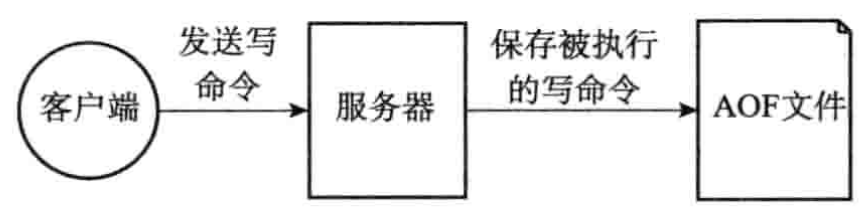
例如,我们对空白的数据库执行以下写命令,那么数据库中将包含三个键值对:
127.0.0.1:6379[1]> SET msg "hello"
OK
127.0.0.1:6379[1]> SADD fruits "apple" "banana" "cherry"
(integer) 3
127.0.0.1:6379[1]> RPUSH numbers 128 256 512
(integer) 3
AOF持久化保存数据库状态的方法是将服务器执行的SET、SADD、RPUSH三个命令保存到AOF文件中。
被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,因为Redis的命令请求协议都是纯文本格式的,所以我们可以直接打开一个AOF文件
例如,上述所执行的三个命令,服务器将产生包含以下内容的AOF文件:

服务器在启动时,可以通过载入和执行AOF文件中保存的命令来还原服务器关闭之前的数据库状态
2.1、AOF实现原理
AOF持久化功能的实现可以分为命令追加(append)、文件写入、文件同步(sync)三个步骤
2.1.1、命令追加
当AOF持久化功能处于打开状态时,服务器在执行一个写命令之后,会以协议格式将被执行的写命令追加到服务器状态的aof_buf缓冲区的末尾
struct redisServer{
// AOF 缓冲区
sds aof_buf;
}
2.1.2、文件写入&同步
Redis服务器进程就是一个事件循环(loop),这个循环中的文件事件负责接收客户端的命令请求,以及向客户端发送命令回复,而时间事件则负责执行像serverCron函数这样定时运行的函数
服务器在处理文件事件时会执行写命令,使得一些内容被追加到aof_buf缓冲区里面。
所以在服务器每次结束一个事件循环之前,都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件中,伪代码如下:
def eventLoop() :
while True :
# 处理文件事件,接收命令请求以及发送命令回复
# 处理命令请求时可能会有新内容被追加到aof_buf 缓冲区中
processFileEvents()
# 处理时间事件
processTimeEvents()
# 考虑是否要将 aof_buf 中的内容写入和保存到 AOF 文件中
flushAppendOnlyFile()
flushAppendOnlyFile函数行为由服务器配置的appendfsync选项来决定:
默认选项为everysec

2.2、AOF文件的载入与数据还原
因为AOF文件里面包含了重建数据库状态所需的所有写命令,所以服务器只要读入并重新执行一遍AOF文件里面保存的写命令,就可以还原服务器关闭之前的数据库状态。
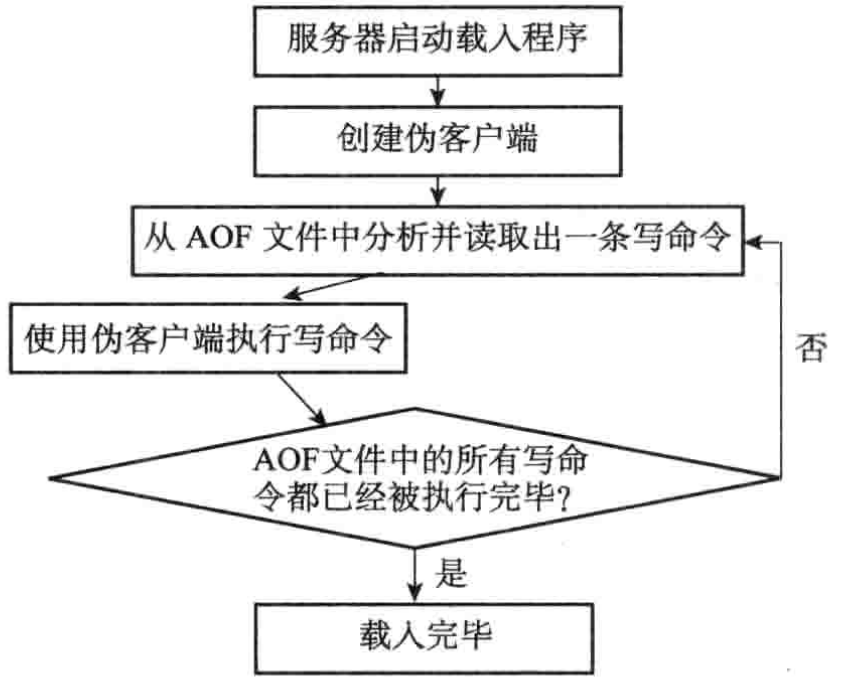
还原数据库状态的步骤:
-
创建一个不带网络连接的伪客户端(fake client)
-
从AOF文件中分析并读出一条写命令
-
使用伪客户端执行被读出的写命令
-
一直执行步骤2和步骤3,直到AOF文件中的所有写命令都被处理完毕为止
2.3、AOF重写
因为AOF持久化时通过保存被执行的写命令来记录数据库状态的,所以随着服务器运行时间的流逝,AOF文件中的内容会越来越多,文件的体积也会越来越大,如果不加以控制的话,体积过大的AOF文件很可能对Redis服务器、甚至整个宿主机造成影响,并且AOF文件的体积越大,使用AOF文件来进行数据还原所需的时间就越多。
为了解决AOF文件体积膨胀的问题,Redis提供了AOF文件重写(rewrite)功能。
通过文件重写,Redis服务器可以创建一个新的AOF文件来替代现有的AOF文件,新旧两个AOF文件所保存的数据库状态相同,但新的AOF文件不会包含任何浪费空间的冗余命令,所以新AOF文件的体积通常会比旧AOF文件的体积要小得多。