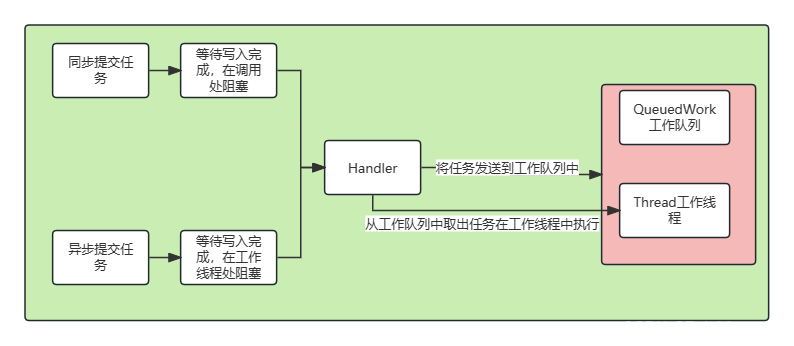
在讲 segment 之前,我们先用一张图了解下 ES 的整体存储架构图,方便后面内容的理解:

一、segment文件的合并流程:
当我们往 ElasticSearch 写入数据时,数据是先写入 memory buffer,然后定时(默认每隔1s)将 memory buffer 中的数据写入一个新的 segment 文件中,并进入 Filesystem cache(同时清空 memory buffer),这个过程就叫做 refresh;每个 Segment 事实上是一些倒排索引的集合, 只有经历了 refresh 操作之后,数据才能变成可检索的。
ElasticSearch 每次 refresh 一次都会生成一个新的 segment 文件,这样下来 segment 文件会越来越多。那这样会导致什么问题呢?因为每一个 segment 都会占用文件句柄、内存、cpu资源,更加重要的是,每个搜索请求都必须访问每一个segment,这就意味着存在的 segment 越多,搜索请求就会变的更慢。
每个 segment 是一个包含正排(空间占比90~95%)+ 倒排(空间占比5~10%)的完整索引文件,每次搜索请求会将所有 segment 中的倒排索引部分加载到内存,进行查询和打分,然后将命中的文档号拿到正排中召回完整数据记录。如果不对segment做配置,就会导致查询性能下降
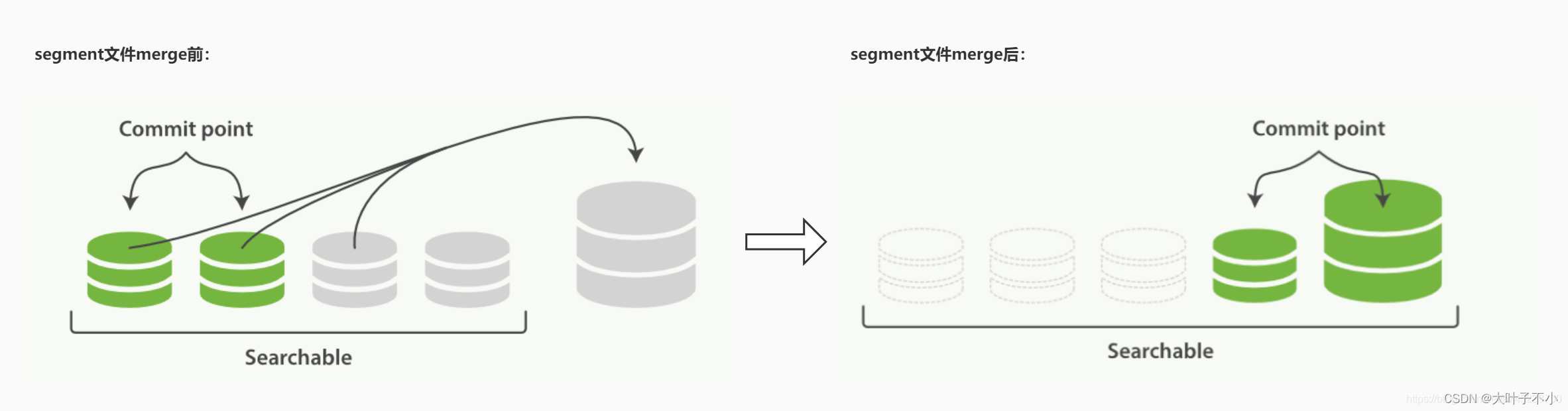
那么 ElasticSearch 是如何解决这个问题呢? ElasticSearch 有一个后台进程专门负责 segment 的合并,定期执行 merge 操作,将多个小 segment 文件合并成一个 segment,在合并时被标识为 deleted 的 doc(或被更新文档的旧版本)不会被写入到新的 segment 中。合并完成后,然后将新的 segment 文件 flush 写入磁盘;然后创建一个新的 commit point 文件,标识所有新的 segment 文件,并排除掉旧的 segement 和已经被合并的小 segment;然后打开新 segment 文件用于搜索使用,等所有的检索请求都从小的 segment 转到 大 segment 上以后,删除旧的 segment 文件,这时候,索引里 segment 数量就下降了。如下面两张图:
所有的过程都不需要我们干涉,es会自动在索引和搜索的过程中完成,合并的segment可以是磁盘上已经commit过的索引,也可以在内存中还未commit的segment:合并的过程中,不会打断当前的索引和搜索功能。
二、segment 的 merge 对性能的影响:
segment 合并的过程,需要先读取小的 segment,归并计算,再写一遍 segment,最后还要保证刷到磁盘。可以说,合并大的 segment 需要消耗大量的 I/O 和 CPU 资源,同时也会对搜索性能造成影响。所以 Elasticsearch 在默认情况下会对合并线程进行资源限制,确保它不会对搜索性能造成太大影响。
默认情况下,归并线程的限速配置 indices.store.throttle.max_bytes_per_sec 是 20MB。对于写入量较大,磁盘转速较高,甚至使用 SSD 盘的服务器来说,这个限速是明显过低的。对于 ELK Stack 应用,建议可以适当调大到 100MB或者更高。设置方式如下:
PUT /_cluster/settings
{
"persistent" : {
"indices.store.throttle.max_bytes_per_sec" : "100mb"
}
}
或者不限制:
PUT /_cluster/settings
{
"transient" : {
"indices.store.throttle.type" : "none"
}
}
三、手动强制合并 segment:
ES 的 API 也提供了命令来支持强制合并 segment,即 optimize 命令,它可以强制一个分片 shard 合并成 max_num_segments 参数指定的段数量,一个索引它的segment数量越少,它的搜索性能就越高,通常会optimize 成一个 segment。
但需要注意的是,optimize 命令是没有限制资源的,也就是你系统有多少IO资源就会使用多少IO资源,这样可能导致一段时间内搜索没有任何响应,所以,optimize命令不要用在一个频繁更新的索引上面,针对频繁更新的索引es默认的合并进程就是最优的策略。如果你计划要 optimize 一个超大的索引,你应该使用 shard allocation(分片分配)功能将这份索引给移动到一个指定的 node 机器上,以确保合并操作不会影响其他的业务或者es本身的性能。
但是在特定场景下,optimize 也颇有益处,比如在一个静态索引上(即索引没有写入操作只有查询操作)是非常适合用optimize来优化的。比如日志的场景下,日志基本都是按天,周,或者月来索引的,旧索引实质上是只读的,只要过了今天、这周或这个月就基本没有写入操作了,这个时候我们就可以通过 optimize 命令,来强制合并每个shard上索引只有一个segment,这样既可以节省资源,也可以大大提升查询性能。
optimize 的 API 如下:
POST /logstash-2014-10/_optimize?max_num_segments=1
四、segment 性能相关设置:
1、查看某个索引中所有 segment 的驻留内存情况:
curl -XGET ‘http://host地址:port端口/_cat/segments/索引节点名称?v&h=shard,segment,size,size.memory’
2、性能优化:
(1)合并策略:
合并线程是按照一定的运行策略来挑选 segment 进行归并的。主要有以下几条:
① index.merge.policy.floor_segment:默认 2MB,小于该值的 segment 会优先被归并。
② index.merge.policy.max_merge_at_once:默认一次最多归并 10 个 segment
③ index.merge.policy.max_merge_at_once_explicit:默认 forcemerge 时一次最多归并 30 个 segment
④ index.merge.policy.max_merged_segment:默认 5 GB,大于该值的 segment,不用参与归并,forcemerge 除外
(2)设置延迟提交:
根据上面的策略,我们也可以从另一个角度考虑如何减少 segment 归并的消耗以及提高响应的办法:加大 refresh 间隔,尽量让每次新生成的 segment 本身大小就比较大。这种方式主要通过延迟提交实现,延迟提交意味着数据从提交到搜索可见有延迟,具体需要结合业务配置,默认值1s;
针对索引节点粒度的配置如下:
curl -XPUT http://host地址:port端口/索引节点名称/_settings -d ‘{“index.refresh_interval”:“10s”}’
(3)对特定字段field禁用 norms 和 doc_values 和 stored:
norms、doc_values 和 stored 字段的存储机制类似,每个 field 有一个全量的存储,对存储浪费很大。如果一个 field 不需要考虑其相关度分数,那么可以禁用 norms,减少倒排索引内存占用量,字段粒度配置 omit_norms=true;如果不需要对 field 进行排序或者聚合,那么可以禁用 doc_values 字段;如果 field 只需要提供搜索,不需要返回则将 stored 设为 false;
————————————————
版权声明:本文为CSDN博主「张维鹏」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/a745233700/article/details/117953198