打开这个网页,想爬取网页上的内容:
https://toppsta.com/books/series/29278/national-geographic-kids-readers-level-1
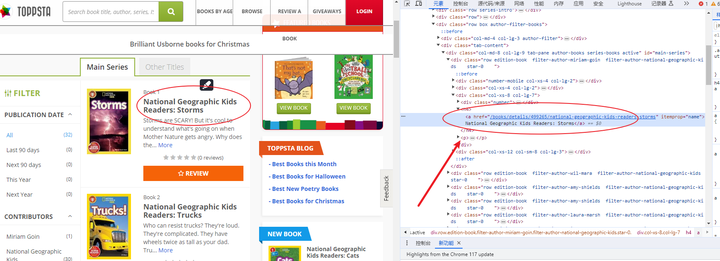
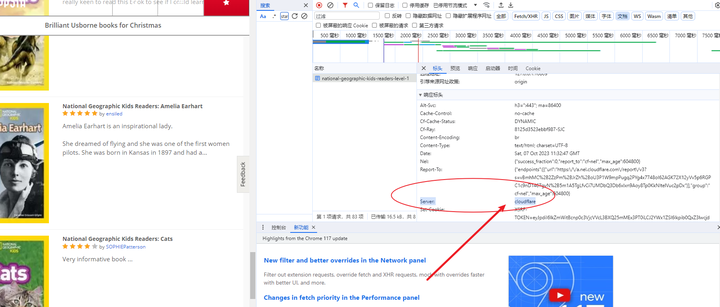
这个网页看起来很简单,但是一般手段根本无法获取源代码,因为网站使用了Cloudflare服务器进行防护。
可以使用Cloudscraper库来获取网页源代码,从而爬取网页数据,在ChatGPT中输入提示词:
你是一个Python编程专家,要完成一个网页爬取的任务,具体步骤如下:
打开网页:https://toppsta.com/books/series/29278/national-geographic-kids-readers-level-1
这个网页使用了Cloudflare服务器,要使用 Cloudscraper 绕过 Cloudflare的防护;
Cloudscraper 的使用示例:
import cloudscraper
scraper = cloudscraper.create_scraper()
url = "http://exampleofyourtargetwebsite.com"
info = scraper.get(url)
print(info.status_code)
soup = BeautifulSoup(info.text, "html.parser")
print(soup.find(class_ = "classgoeshere").get_text())
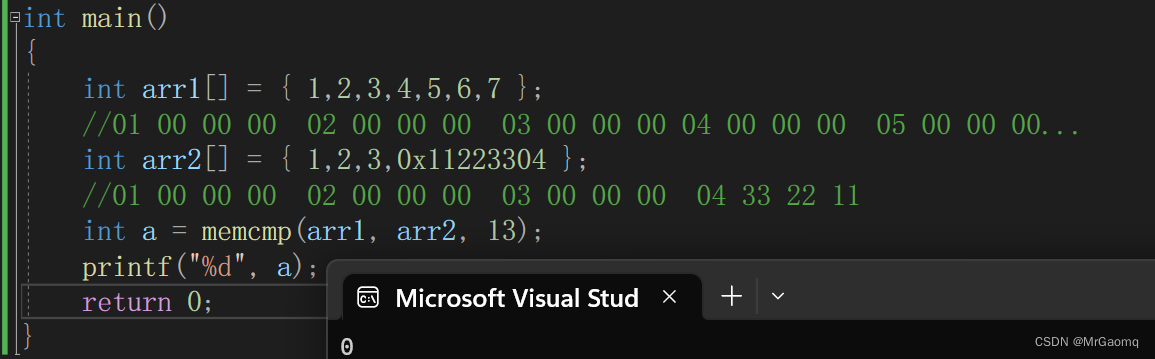
使用 Cloudscraper 获取网页源代码后,查找定位所有的h4标签,打印出所有的h4内容;
然后定位h4标签中的a标签,提取a标签的内容,打印出a标签的内容;
保存所有a标签内容到本地电脑E盘的Excel表格:name.xlsx;
打开本地电脑E盘的Excel表格:name.xlsx,删除其中所有的字符“National Geographic Kids Readers:”
注意:每一步都要输出信息
ChatGPT给出的源代码:
import cloudscraper
from bs4 import BeautifulSoup
import pandas as pd
print("创建 Cloudscraper 对象...")
scraper = cloudscraper.create_scraper()
url = "https://toppsta.com/books/series/29278/national-geographic-kids-readers-level-1"
print(f"获取网页:{url}...")
response = scraper.get(url)
print("状态码:", response.status_code)
soup = BeautifulSoup(response.text, "html.parser")
print("查找所有的h4标签...")
h4_tags = soup.find_all('h4')
h4_texts = [tag.get_text().strip() for tag in h4_tags]
print("所有的h4内容:")
print("\n".join(h4_texts))
print("查找h4标签中的a标签...")
a_texts = [tag.find('a').get_text().strip() for tag in h4_tags if tag.find('a')]
print("所有的a标签内容:")
print("\n".join(a_texts))
print("保存a标签内容到Excel表格...")
df = pd.DataFrame(a_texts, columns=["Title"])
df.to_excel('E:\\name.xlsx', index=False)
print("打开Excel表格,删除指定字符...")
df = pd.read_excel('E:\\name.xlsx')
df['Title'] = df['Title'].str.replace('National Geographic Kids Readers:', '')
df.to_excel('E:\\name.xlsx', index=False)
print("完成!")
程序运行后,生成的Excel表内容:






![2023年中国建筑安装行业市场现状分析:占比建筑业总产值8.4%[图]](https://img-blog.csdnimg.cn/img_convert/1f185911d1797ca1d4beca22e26a04e1.png)