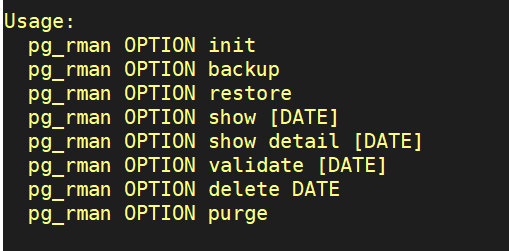
1 定义
布隆过滤器(Bloom Filter, BF)是由Howrad Bloom在1970年提出的一种具有高效时间和空间效率的二进制向量数据结构,用来检测一个元素是不是属于这个集合。注意,布隆过滤器只判断是否出现在集合中,无法给出元素在集合中的具体位置。
1.1 构造布隆过滤器
关于如何构造布隆过滤器,下面以集合
S
=
{
S
1
,
S
2
,
S
3
}
S=\{S_{1},S_{2},S_{3}\}
S={S1,S2,S3}为例进行说明。首先要说明一点,虽然布隆过滤器也需要利用哈希查询算法,但与传统的哈希查询算法不同,布隆过滤器并不存储集合中的具体元素,而是通过多次哈希函数将集合中的元素映射到二进制位串中。一旦集合元素被映射到对应的二进制位,则将对应位置改为1。

上述布隆过滤器中,每个位置占1个比特位。如果每个位置改为多个比特位,这样就能表达出的信息。比如如下图所示的计数布隆过滤器。

注意:一般不对布隆过滤器执行删除元素的操作。
1.2 布隆过滤器查询过程
在查询过程中,需要计算出相关元素 S i S_{i} Si对应的多个哈希地址,然后检查布隆过滤器中对应的位置上是否全部为1,若全都为1,则 S i S_{i} Si可能在布隆过滤器上(被称为假阳性问题);若不全为1,那么元素 S i S_{i} Si一定不在布隆过滤器上。
1.3 优点
布隆过滤器的优点主要有以下几点:
- 时间复杂低。无论是插入还是查询操作,布隆过滤器的时间复杂度均为 O ( k ) O(k) O(k),其中, k k k为哈希函数的数量。
- 保密性好。布隆过滤器中并不保存元素的具体数值。
- 占用空间小。
而布隆过滤器的缺点主要为:存在误判率。当两个不同的值却能产生相同的哈希值时,布隆过滤器无法确定查询元素是否真的存在集合中。为了尽量降低误判率,布隆过滤器中一般都设置多个哈希函数。
2 python中使用布隆过滤器
2.1 安装包
python中实现布隆过滤器的第三方包很多,这里使用的是pybloom-live (pybloomfiltermmap等包在Windows上安装遇到报错,无法解决)。
pip install pybloom_live
2.2 简单使用案例
from pybloom_live import BloomFilter
bf=BloomFilter(capacity=100000,error_rate=0.001)
#构建布隆过滤器
for i in range(100000):
bf.add(i)
#查询元素
for i in [1,200,345,100323,3233232,'hello']:
print(i in bf)
其结果如下:
True
True
True
False
False
False
补充
- 什么是缓存穿透?
缓存穿透是指在高并发场景下,缓存中(包括本地缓存和Redis缓存)的某一个Key被高并发的访问没有命中,此时会回数据库中访问数据,导致数据库并发的执行大量查询操作,对其造成巨大的压力。
使用布隆过滤器可以解决缓存穿透的问题。比如在redis数据库中,先将所有的key都存到布隆过滤器中,当请求进来时,先去过滤器中校验key是否存在,如果不存在直接返回null。


![2023年中国建筑安装行业市场现状分析:占比建筑业总产值8.4%[图]](https://img-blog.csdnimg.cn/img_convert/1f185911d1797ca1d4beca22e26a04e1.png)