在上一篇文章“代码检查过程中为什么需要涉及到编译呢?”中,有提到SAST代码检查工具里编译过程会经历哪些阶段,里面有提到:
一般来说,完整的编译过程会经历:对源代码进行词法、语法、语义的分析,生成AST,接着转换为IR,生成CFG,对数据流进行分析、优化,生成目标代码。
总结一下就说是源码 > AST > IR > CFG 这么个逻辑顺序,那它们三之间是怎么个依赖关系呢?本文尝试来梳理下。
源码和AST的关系
- 源码就是程序员用JAVA, C, C++, Python等语言编写出来的代码。
- AST, Abstract Syntax Tree 抽象语法树,是用来表示程序代码结构的树形数据结构。
在讲AST之前,我们先解释下解析树(parse tree),它又被叫做具象语法树(CST,Concret Syntax Tree),会包含代码中所有的语法信息,可以说是代码的直接翻译。而AST既然被叫做抽象语法树,从名字上就可以看出来,它会剥离掉一些不重要的细节(忽略掉一些语法信息)。因此,AST可以说是解析树(parse tree)的一个精简版本。
源码和AST之间的转换是:
- 源码通过编译器或解析器进行词法分析、语法分析、语义分析等操作,生成AST。
- AST也可以通过代码生成器或反解析器进行优化、转换、翻译等操作,转换生成源码。
词法分析
词法分析, lexical analysis, 属于编译的第一个阶段,这其中会涉及到两个主要的工具:scanner和分词器。Scanner会从头到尾去扫描源代码文件,把文本拆成单词;之后这些单词会传入分词器,经过一些列识别器(关键字识别器、标识符识别器、常量识别器、操作符识别器等),识别确认单词的词性,生成一个<type, value>形式的二元组token序列(组合里的type指单词种类,value则是属性值)。
语法分析
词法分析完成之后,第二个阶段就是语法分析, syntax analysis。在这个阶段,token序列会传递给解析器,根据给定的语法规则,由其识别出代码中的各类短语并根据语言的文法规则来生成解析树。其主要目标是为了验证源代码是否符合语言的语法规范,同时创建源代码的解析树或抽象语法树(AST),用来表示源代码的层次和逻辑关系。
语义分析
词法分析和语法分析两个阶段中相关的操作都是上下文无关的。而语义分析的本质,就是针对上下文相关情况去做处理。
语义分析,Semantic Analysis,对抽象语法树进行下一步的检查和处理。其主要目的是为了确定源码是否有意义,同时也可以对源代码进行一些优化和转换。
常用的AST在线工具
在线转换代码为AST的工具地址:https://astexplorer.net/
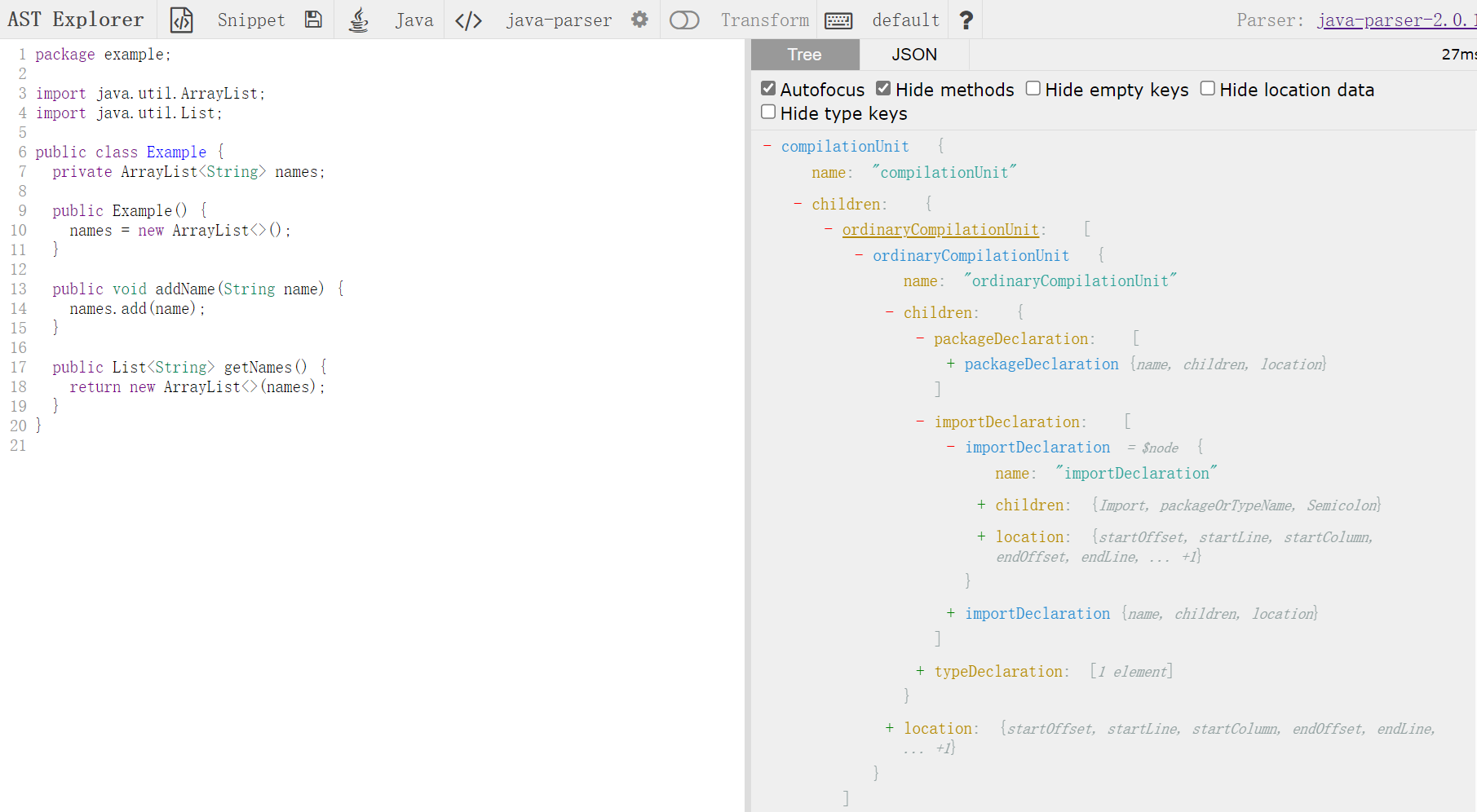
AST和IR的关系
当从源码生成了AST之后,IR也可以从AST转换/变形而来。
两者都可以被SAST工具用于检查,区别在于:AST更接近与源代码的语法结构,依赖于编程语言种类,扫描分析效率更快,但缺少控制流信息,即AST更关注代码的表面特征和规范性,更适合做一些简单的模式匹配和规则检查;IR则更接近于机器码的语义结构,不依赖于编程语言种类,包含了控制流信息,更关注于代码的深层含义和安全性,更适合做一些复杂的数据流分析和漏洞检测。
IR和CFG的关系
CFG是从IR生成来的,是一种用来表示程序代码执行流程的图形数据结构;可以这么说,CFG是IR的一种变形,它把代码分给为基本块,并用边表示基本块之间的跳转关系。
IR和CFG之间的区别是:IR接近于机器码的语义结构,不依赖于编程语言种类,包含了控制流信息,更关注于代码的深层含义和安全性;CFG则带有控制流(专注于从Source到Sink的过程),可以更直观地展示代码的执行路径和分支条件,便于进行控制流分析和路径敏感的分析。
参考链接
- https://en.wikipedia.org/wiki/Lexical_analysis
- https://zhuanlan.zhihu.com/p/102385477
- https://www.geeksforgeeks.org/introduction-to-syntax-analysis-in-compiler-design/
- https://en.wikipedia.org/wiki/Semantic_analysis_(linguistics)