一、直接插入排序
直接插入排序:直接插入排序就是像打扑克牌一样,每张牌依次与前面的牌比较,遇到比自己大的就将大的牌挪到后面,遇到比自己小的就把自己放在它后面(如果自己最小就放在第一位),所有牌排一遍后就完成了排序。

代码如下:
// 插入排序
void InsertSort(int* a, int n)
{
for (int i = 0; i < n; ++i)
{
int tmp = a[i];
int end = i - 1;
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}总结:直接插入排序的时间复杂度为O(n^2),空间复杂度为O(1),具有稳定性(相对位置不变),在接近升序的情况下效果最好,接近O(n)。
二、希尔排序
希尔排序:直接插入排序在接近有序的情况下很快,所以就想到在直接插入排序之前先预排序,让数据接近有序,再用直接插入排序,效果就会提升,这就是希尔排序。
预排序: 先将数据分成 gap 组,每组里面使用直接插入排序。
当gap为1时,就是直接插入排序。
 代码如下:
代码如下:
// 希尔排序
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//控制gap,最后一次是1
for (int i = 0; i < n; i++)
{
int tmp = a[i];
int end = i - gap;
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}总结:希尔排序时间复杂度不好计算,根据教科书,为O(n^1.3),空间复杂度为O(1),因为预排序,希尔排序不稳定,也因为预排序,希尔排序在接近有序(无论升序或降序)时,速度最快。
三、选择排序
选择排序:类似打牌,选择排序就是在 所有牌中选出最小的放在最左边,选出最大的放在最右边,然后再从剩余的牌中重复此操作。
需要注意的是当最大的牌在最左边时,若先与最小的牌交换位置,则会造成错误,只要加个判断调整即可。
代码如下:
// 选择排序
void SelectSort(int* a, int n)
{
int begin = 0, end = n - 1;
while (begin < end)
{
int min = begin, max = begin;
for (int i = begin; i <= end; ++i)
{
if (a[min] > a[i])
min = i;
if (a[max] < a[i])
max = i;
}
swap(&a[min], &a[begin]);
if (a[begin] == a[max])
max = min;
swap(&a[max], &a[end]);
begin++;
end--;
}
}总结:时间复杂度为O(n^2),空间复杂度为O(n),不具有稳定性(因为与第一张牌交换时可能会改变相对位置)。
四、冒泡排序
冒泡排序: 遇到比自己小的就交换,每趟冒泡都可以把最大的值放到后面,次大的值放到倒数第二位.....然后结束。
代码如下:
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n - 1; ++i)
{
int flag = 0;
for (int j = 0; j < n - i - 1; ++j)
{
if (a[j] > a[j + 1])
{
swap(&a[j], &a[j + 1]);
flag = 1;
}
}
if (flag == 0)
break;
}
}总结:时间复杂度为O(n^2),空间复杂度为O(n),具有稳定性。
五、堆排序
请看这里(づ ̄ 3 ̄)づ:堆排序与TopK问题-CSDN博客
六、快速排序
快速排序:选一个key,将小于key的排在左边,大于key的排在右边,排完后key就在有序时的对应位置。
然后递归左区间和右区间,每个数都在对应位置就能使整体有序。
让 key 在有序时的对应位置,有三种方法。(小指的是比key小,大就是比key大)
hoare版本:最老的版本,右边找小,左边找大,找到交换,重复操作到 left >= right 再将 left 与 key 位置的值交换
挖坑法:key看作坑,右边找小,找到交换,右边看作坑,左边找大,找到交换,左边再看作坑,依次循环,最后坑就在相应位置。
双指针法:一个cur指针,一个prev指针,cur遇到小就与++prev位置交换,遇到大就cur++,
使prev位置是小的最后一个。
代码如下:
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{
int key = left;
while (left < right)
{
//必须先右再左,若先左再右则要交换left+1的位置
//前面加一个left<right防止越界,后面不加等号可能会导致死循环
while (left < right && a[right] >= a[key])
right--;
while (left < right && a[left] <= a[key])
left++;
swap(&a[left], &a[right]);
}
swap(&a[key], &a[left]);
return left;
}/ 快速排序挖坑法
int PartSort2(int* a, int left, int right)
{
int hole = left;
while (left < right)
{
while (left < right && a[right] >= a[hole])
right--;
swap(&a[hole], &a[right]);
hole = right;
while (left < right && a[left] <= a[hole])
left++;
swap(&a[hole], &a[left]);
hole = left;
}
return hole;
}// 快速排序前后指针法
int PartSort3(int* a, int left, int right)
{
int key = left;
int prev = left, cur = prev + 1;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
{
swap(&a[cur], &a[prev]);
}
cur++;
}
swap(&a[key], &a[prev]);
return prev;
}
排好一个位置,然后递归左右区间排剩余位置,最终使所有数据有序。
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
//int key = PartSort1(a, left, right);
//int key = PartSort2(a, left, right);
int key = PartSort3(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}
快排在数据接近有序时会出现剩余数据全在右区间的情况,此时最慢,时间复杂度为O(n^2)
所以我们可以加一个优化:三数取中。就可以极大地规避这种可能性。
三数取中:加一个三数取中的函数,在left,right,(left+right)/2 这三个位置中选出中间那个位置做key.
以hoare版本为例
int GetMid(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] > a[right])
{
if (a[right] > a[mid])
return right;
else
{
if (a[left] > a[mid])
return mid;
else
return left;
}
}
else
{
if (a[left] > a[mid])
return left;
else
{
if (a[mid] > a[right])
return right;
else
return mid;
}
}
}
// 快速排序hoare版本
int PartSort1(int* a, int left, int right)
{
int mid = GetMid(a, left, right);
swap(&a[mid], &a[left]);
int key = left;
while (left < right)
{
//必须先右再左,若先左再右则要交换left+1的位置
//前面加一个left<right防止越界,后面不加等号可能会导致死循环
while (left < right && a[right] >= a[key])
right--;
while (left < right && a[left] <= a[key])
left++;
swap(&a[left], &a[right]);
}
swap(&a[key], &a[left]);
return left;
}在递归左右区间时,根据我们学过的满二叉树知识,最后一层的结点几乎占全部的 50% ,倒数第二层大概占 25% 依次类推,而且最后的小区间是接近有序的,所以我们可以判断区间里的数据个数,若小于10,则用直接插入排序直接排完,可以减少80%多栈的调用。
void QuickSort(int* a, int left, int right)
{
if (left >= right)
return;
if (right - left + 1 <= 10)
{
InsertSort(a + left, right - left + 1);
return;
}
//int key = PartSort1(a, left, right);
//int key = PartSort2(a, left, right);
int key = PartSort3(a, left, right);
QuickSort(a, left, key - 1);
QuickSort(a, key + 1, right);
}非递归版 :用栈模拟函数栈帧的调用过程
// 快速排序 非递归实现
void QuickSortNonR(int* a, int left, int right)
{
stack<int> st;
st.push(right);
st.push(left);
while (!st.empty())
{
int begin = st.top();
st.pop();
int end = st.top();
st.pop();
int key = PartSort3(a, begin, end);
if (key - 1 < begin)//区间有效入栈
{
st.push(key - 1);
st.push(begin);
}
if (key + 1 < end)//区间有效入栈
{
st.push(end);
st.push(key + 1);
}
}
}总结:时间复杂度O(nlogn),空间复杂度O(logn),不稳定(找到key合适的位置后要交换)
七、归并排序
归并排序:大家都做过两个有序数组归并到一起然后整体有序的题目吧,这就是归并排序的核心思路,它先将整个数组递归成一个一个的,然后再不断归并,最后整体有序。就相当于后序遍历的思路,左边有序,右边有序,归并自己,然后自己就有序。
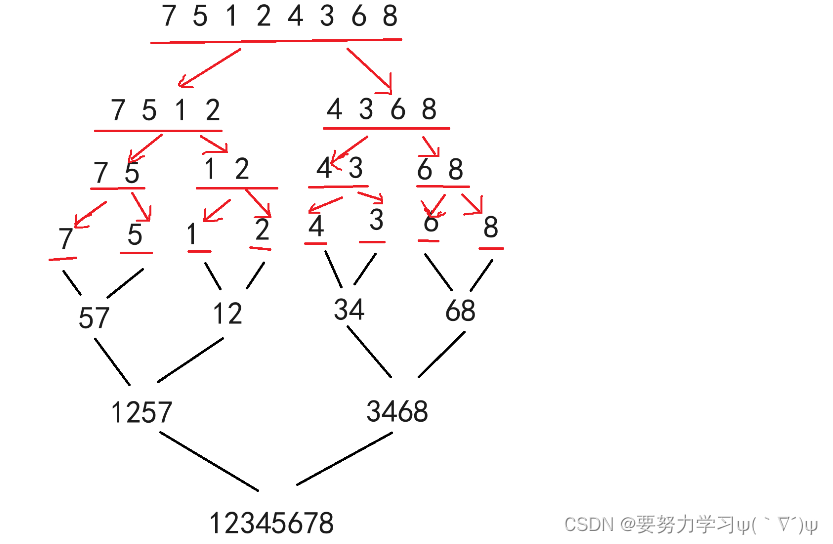
void _MergeSort(int* a, int* tmp, int left, int right)
{
//只有一个数就返回
if (left >= right)
return;
int mid = (left + right) / 2;
_MergeSort(a, tmp, left, mid);
_MergeSort(a, tmp, mid+1, right);
//两个数组有序,归并到整体有序
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int j = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1];
begin1++;
}
else
{
tmp[j++] = a[begin2];
begin2++;
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1];
begin1++;
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2];
begin2++;
}
//拷贝回对应位置
memcpy(a+left, tmp+left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
_MergeSort(a, tmp, 0, n - 1);
}非递归版本: 这个思路就是两两归并,四四归并,八八归并....最后整体有序,所以就可以设置一个gap从1到n,让数据模拟上述过程,循环归并。注意的是要考虑数据不足越界情况。
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(n * sizeof(int));
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2*gap)
{
//利用gap设置区间
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
//考虑越界情况
if (begin2 >= n)//第二组越界就没必要归并了
break;
if (end2 >= n)//begin2没越,end2越界,修正end2
end2 = n - 1;
//归并
int j = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[j++] = a[begin1];
begin1++;
}
else
{
tmp[j++] = a[begin2];
begin2++;
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1];
begin1++;
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2];
begin2++;
}
memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));
}
gap *= 2;
}
}总结: 时间复杂度O(nlogn),空间复杂度O(n),稳定。缺点是空间复杂度过高,优势是可以在磁盘中排序(外排序)
八、计数排序
计数排序:计数排序是类似哈希表,先开一个数组,让每个值都有一个对应位置,遍历数据,遇到就在对应位置++,最后遍历数组输出。
代码如下:
void CountSort(int* a, int n)
{
//assert(n>0);
//找到最大值与最小值,为映射做准备
int max = a[0], min = a[0];
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
min = a[i];
if (a[i] > max)
max = a[i];
}
int range = max - min + 1;
int* Count = (int*)calloc(range, sizeof(int));
if (Count == NULL)
{
perror("calloc fail");
exit(-1);
}
//对应位置++
for (int i = 0; i < n; ++i)
{
Count[a[i] - min]++;
}
int j = 0;
for (int i = 0; i < range; ++i)
{
//把对应位置写回原数组
while (Count[i]--)
{
a[j++] = i + min;
}
}
}总结 :计数排序的时间复杂度为O(max(range, n)),空间复杂度为O(range),稳定。适用于数据集中在某一范围的时候。
感谢大家观看,欢迎指出错误(๑•̀ㅂ•́)و✧