车规级芯片、手机芯片、电脑芯片比较_汽车芯片和电脑芯片的区别-CSDN博客
全文资源来源网络。
电脑:

图片引用。
CPU 基准测试性能层次结构根据性能对当前和上一代英特尔和 AMD 处理器进行排名,包括所有最适合游戏的 CPU。在 CPU 排名图表和表格下方,本指南还为您提供了 CPU 基准测试的基本介绍,并包括常用 CPU 基准测试的列表。我们对 CPU 进行了超过 25 年的基准测试,因此我们在本文的第二页上保留了许多传统的历史 CPU 排名。
CPU 被认为是计算机最重要的组件。CPU基准测试比较有助于我们理清芯片之间的差异,但您会发现英特尔和AMD的型号和规格令人眼花缭乱。我们列出了最便宜的CPU和最好的工作站CPU,甚至在其他文章中涵盖了英特尔与AMD功能辩论,但如果您想了解CPU排名以及如何运行自己的CPU基准测试,此CPU基准测试层次结构适合您。
AMD 锐龙 5 5600X3D 已被证明是一款真正出色的芯片。只有Micro Center拥有这种芯片,并且仅在其商店中销售,这标志着我们在最近的内存中看到的唯一真正独家的CPU发布。7600X3D 是 AM4 升级者获得的 CPU,或者如果您正在购买功能强大的预算游戏装备。然而,与AMD所有游戏专用X3D部件一样,该芯片在生产力应用程序中的性能较低,而其较旧的Zen 3架构加剧了这种情况。也就是说,这是我们基准测试过的最好的每美元游戏CPU,因此请查看评论以了解详细信息。
售价449美元的Ryzen 7 7800X3D现在是金钱可以买到的最快的游戏芯片。这款八核 16 线程芯片使用 AMD 的 3D V-Cache 技术来加速游戏性能,但该技术并不能加速所有游戏,并导致某些应用程序的性能降低。然而,对于游戏来说,AMD的3D V-Cache技术是无可争议的领导者。对于以游戏为中心的超高端装备,售价 699 美元的 Ryzen 9 7950X3D 是无可争议的领导者,拥有 16 个内核和 32 个线程,它们既擅长处理最繁重的生产力工作负载,也擅长处理最新的游戏。我们最近还回顾了具有相同技术的Ryzen 9 7900X3D,但其定价太高。
该芯片与英特尔酷睿i9-13900KS对峙,这是有史以来最快的台式PC芯片之一,但它的价格为699美元,对功率的贪婪需求需要昂贵的支持组件才能提供个位数百分比的CPU基准测试改进标准酷睿i9-13900K。总体而言,13900KS 的小幅性能提升对普通用户来说没有意义。
M1/2……
手机:

图片引用。

图片引用。
汽车:
8155/8255/8295参数对比-CSDN博客
高通骁龙8295车规级芯片
高通再次在科技行业掀起波澜,宣布推出专为汽车行业设计的Snapdragon 8295芯片。这款第四代汽车驾驶舱平台芯片设置了我们与汽车交互的方式,提供了改进的性能和先进的功能。
骁龙 8295 采用 5nm 工艺,AI 计算能力为 30TOPS,与之前的骁龙 8155(7nm)相比,GPU 性能和 3D 渲染性能分别提高了 3 倍。此外,骁龙 8295 在单个芯片上集成了电子后视镜、机器学习视觉(后视、环视)、乘客监控和信息安全功能,使其成为汽车制造商的出色选择。
在汽车技术与合作峰会期间,高通还推出了其ADAS智能驾驶芯片8650和座舱集成芯片骁龙8775。该公司展示了其汽车生态系统合作解决方案的全景展示,展示了其为汽车制造商提供全方位选择的承诺。
随着向更小的5nm工艺的转变,8295拥有每秒30万亿次AI肌肉的操作,图形性能是其前身Snapdragon 8155的两倍,3D渲染能力是其三倍。谈论一个主要的发光!提升的性能使芯片能够同时为多达 11 个高分辨率触摸屏显示器供电,从而提供超身临其境的体验。
8295 还包含一些下一代功能,如集成电子后视镜、机器学习驱动的环视监控、乘客情绪跟踪和增强的安全性。凭借所有这些未来主义功能,后座驾驶体验正在得到巨大升级。
机器人:
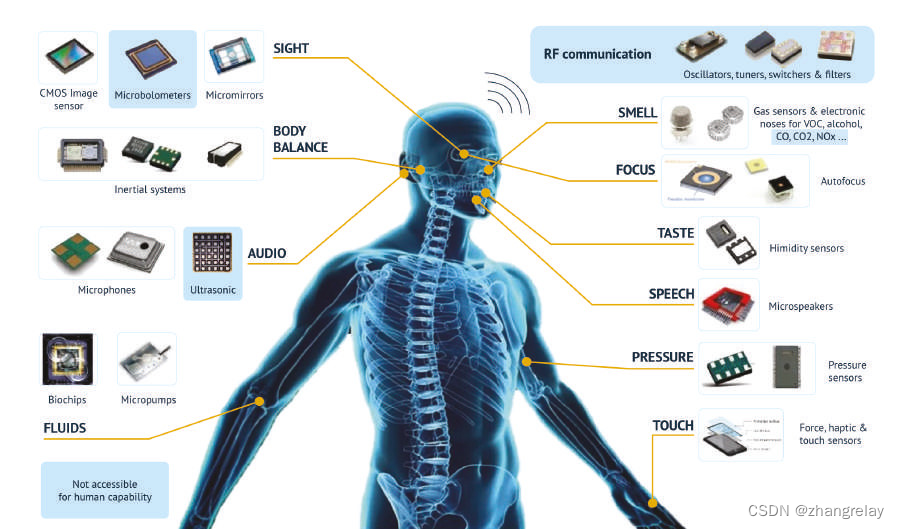
QRB5165处理器旨在帮助您构建更智能、更强大的消费者、企业或工业机器人,并具有设备上的AI和5G连接等功能。
QRB5165在高度集成的芯片组中带来了最新的物联网技术,为下一代高计算、人工智能、低功耗机器人和无人机提供动力,适用于可通过 5G 连接的消费者、企业、国防、工业和专业服务部门。QRB5165处理器专为机器人应用定制,提供强大的异构计算架构,结合领先的第五代-第五代高通®人工智能 (AI) 引擎,提供每秒 15 万亿次操作 (TOPS) 的 AI 性能,以高效运行复杂的 AI 和深度学习工作负载以及设备上的边缘推理,同时使用低功耗。该处理器还提供强大的图像信号处理器(ISP),支持七个并发摄像头,用于增强视频分析(EVA)的专用计算机视觉引擎,以及新的高通海克斯康™张量加速器(HTA)和强大的高通®® Adreno™ 650 GPU。该QRB5165通过配套模块支持4G和5G连接速度,有助于为5G在机器人和智能系统中的普及铺平道路。
超算:
NVIDIA宣布推出NVIDIA DGX GH200,这标志着GPU加速计算的又一突破,为最苛刻的巨型人工智能工作负载提供动力。
GPU的统一内存编程模型是过去7年来复杂加速计算应用取得各种突破的基石。2016年,NVIDIA引入了NVLink技术和CUDA-6的统一内存编程模型,旨在增加GPU加速工作负载的可用内存。
从那时起,每个DGX系统的核心都是与NVLink互连的基板上的GPU复合体,其中每个GPU可以以NVLink的速度访问另一个GPU的内存。许多具有GPU复合体的DGX通过高速网络互连,形成更大的超级计算机。
Dojo将能够每秒进行exaflop或1万亿(1018)浮点运算