任何工作,没别的,就是苦练基本功,在篮球场上,我常用非常简单的基本功就可以克敌制胜,工作中也是如此
字符串
- 1:字符串拼接
a="'人民'"
b=123
print("我是"+a+""+str(b))
2:字符串格式化
year=1949
name='人民'
sport='站起来了'
print("%s中国%s从今以后%s "%(year,name,sport))
将数字进行了格式化,同时简单方便。
- 3:字符串的格式化精度控制

!](https://img-blog.csdnimg.cn/45d6102a84504abfb97735abb07c9156.png)
a=12.456
print("%5.1f" %a)
#快速占位符
适合对精度没有要求的可以快速进行格式化
year='新年'
price='123'
print(f"你好{year},挣了{price}钱")
- 对表达式格式化
数据输入
print("告诉我你是谁?")
name=input()
print(f"我知道了,你的名字是{name}")
name1=input("告诉我你的名字是什么?\n")
print(f"我知道了,你的名字是{name1}")

range

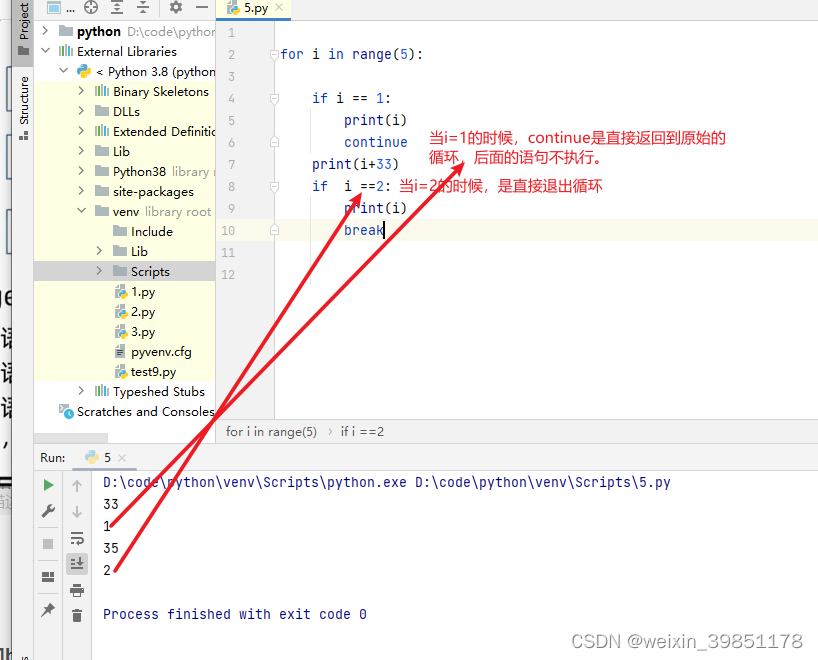
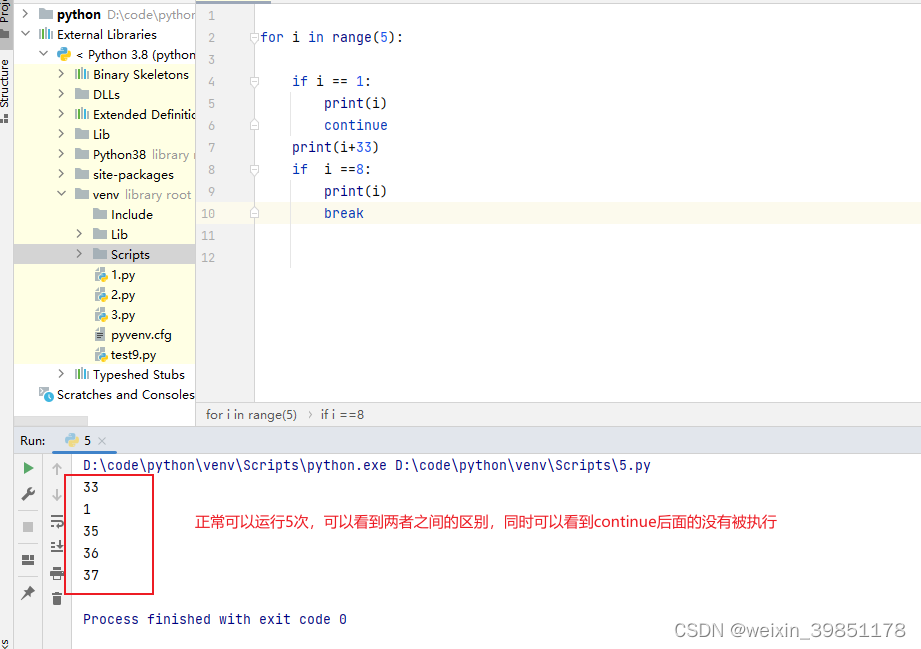
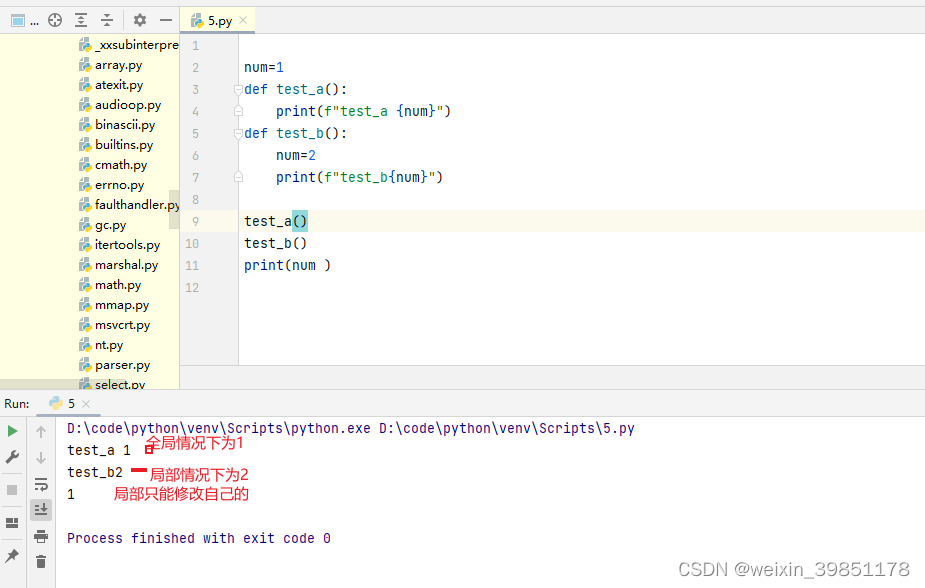
continue 和break的使用
break和continue生效范围是一样的,只是continue会继续执行
,详情可见下面两张图
Python函数
通过global关键字来修改
python数据容器
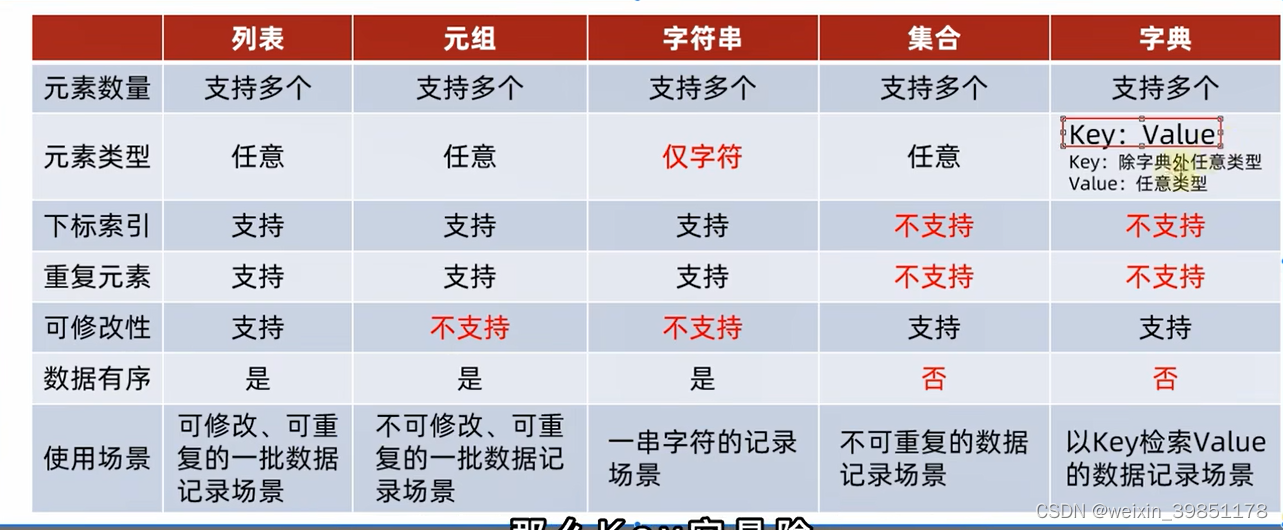
数据容器有以下特点
1:是否支持重复元素
2:是否可以修改
3:是否有序
分为5类,分别是list,元祖tuple,字符串str,集合set ,字典dict
容器的定义,一次性可以存储多个数据
list
1:存储的元素类型是不受限制的
2:列表里面再次嵌入列表叫作嵌套
如何取出数据
1:通过索引
正向下标,和反向下标
注意:不要超出索引范围。
列表的常用操作
name_list=['wang','liu']
print(name_list)
#查询
# 结果为0
print(name_list.index('wang'))
#输出异常,会断掉
#print(name_list.index('wan'))
#修改
name_list[0]='yao'
print(f"修改后的结果{name_list}")
#插入元素
#插入元素后,元素占据指定的位置
#['yao', 'ma', 'liu']
name_list.insert(1,'ma')
print(name_list)
#追加元素,是追加到元素的尾部
#['yao', 'ma', 'liu', 'xiao']
name_list.append('xiao')
print(name_list)
#第二种方法,使用extend将其他的列表追加到尾部
#['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian', 'sun', 'li']
name_list2=["zhao","qian","sun","li"]
name_list.extend(name_list2)
print(name_list)
#元素的删除
#li 被删除
#['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian', 'sun']
del name_list[7]
print(name_list)
#del仅仅能够删除元素,没法得到删除的值
name=name_list.pop(6)
#sun被删除
#['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian']
print(name_list)
#sun 可以得到一个返回值
print(name)
#删除元素的内容
#删除第一个元素
name_list.extend(name_list2)
#['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian', 'zhao', 'qian', 'sun', 'li']
print(name_list)
name_list.remove('zhao')
#['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian', 'zhao', 'qian', 'sun', 'li']
#第一个zhao被删除
#清空整个列表
name_list.clear()
#[] 得到了一个空列表
print(name_list)
#统计元素的数量
name_list=['yao', 'ma', 'liu', 'xiao', 'zhao', 'qian', 'zhao', 'qian', 'sun', 'li']
#1 得到了yao的数量
print(name_list.count('yao'))
#统计列表长度
#10
print(len(name_list))
#反转
name_list.reverse()
#['li', 'sun', 'qian', 'zhao', 'qian', 'zhao', 'xiao', 'liu', 'ma', 'yao']
print(name_list)
#列表的遍历
#两种方式可以获取到
def list_while_func():
index=0
while index < len(name_list):
print(f"{name_list[index]}")
index+=1
list_while_func()
def list_for_func():
for i in name_list:
print(i)
list_for_func()
元组,
列表可以被修改,元组不可以被修改,只读的list
t=('zhang','liu','li','zhang','liu','li')
print(len(t)) #6
print(t.count('zhang')) #2
print(t.index('zhang')) #0
#不可以修改,(增加或者删除元素)
#支持for循环
#元组里面如果嵌套了list,那么是可以修改的
字符串
#字符串的操作
#字符串是不可修改的
my_str="happy days everyday"
#如下开始证明
#my_str[2]='H'
"""
Traceback (most recent call last):
File "D:\code\python\venv\Scripts\5.py", line 5, in <module>
my_str[2]='H'
TypeError: 'str' object does not support item assignment
"""
#查找特定的数据
print(my_str.index('days'))
#结果为6
#字符串的替换
#replace方法是得到了一个新的字符串,而不是修改了原来的字符串。
my_replace_str=my_str.replace('h','H')
#结果为happy days everyday
print(my_str)
#结果为Happy days everyday
print(my_replace_str)
#字符串的分割
#按照指定的分割字符串,将字符串划分为多个字符串,并入列表中,
#字符串本身不会变,而是得到了一个列表对象
my_str_list=my_str.split(" ")
#得到了这样的一个list,原来的并没有被改变
#['happy', 'days', 'everyday']
print(my_str_list)
my_str_strip=my_str.strip("h")
#只能对头和尾部进行操作
#appy days everyday
print(my_str_strip)
#统计字符串某个字符出现的次数
print(my_str.count('ay'))
#2
#查看长度
print(len(my_str))
切片操作
其他的如str和列表以及元组都支持切片,在这里不一一练习了
#序列的切片操作
#起始下标,结束下标,步长
#切片后会得到一个新的序列,并不会改变原来的
my_list=[1,2,3,4,5,6,7,8]
my_new_list=my_list[0:8:2]
#输出结果为[1, 3, 5, 7]
print(my_new_list)
my_tuple=(0,1,2,3,4,5,6)
my_new_tuple=my_tuple[-1:-6:-1]
#输出结果为(6, 5, 4, 3, 2)
print(my_new_tuple)
集合
#集合
#集合不支持重复元素
my_set={3,1,2,3,2,3,3}
#{1, 2, 3}
#内容是无序的,不支持下标索引访问,因为一旦发生改变,下标就会全部改变。序列的操作不支持集合,集合是允许修改的。
print(my_set)
#添加新元素
my_set.add(4)
#结果为{1, 2, 3, 4}
print(f"{my_set}")
#移除元素
my_set.remove(1)
{2, 3, 4}
print(my_set)
element=my_set.pop()
#随机取出一个
print(element)
#my_set的值也会发生改变
print(my_set)
#清空方法
my_set.clear()
set()
print(my_set)
my_set={3,1,2,3,2,3,3}
#取出差集
set1={1,2,3}
set2={1,5,6}
set3=set1.difference(set2)
#查找到1里面有的,2里面没有的,set2和set1的结果不会发生变化
{2, 3}
print(set3)
#消除差集
#以集合1为标准,删除1和2里面相同的
print(f"取出集合1的值{set1}")
set1.difference_update(set2)
#将两者之间的1给删除掉{2, 3}
print(set1)
#集合2未发生变化{1, 5, 6}
print(set2)
#合并的功能
#{1, 2, 3, 5, 6}
print(set1.union(set2))
字典
#字典
#字典和集合非常像,集合不允许重复的。字典的key也是不允许重复的
my_dict1={"wang":"99","zhang":"66","gong":"77","liu":"44"}
#重复的key值只会存在一个
my_dict2={"wang":"79","wang":"99","zhang":"66","gong":"77","liu":"44"}
print(my_dict2) #新的值会替换掉旧的{'wang': '99', 'zhang': '66', 'gong': '77', 'liu': '44'}
#获取key后面的值
print(my_dict1['wang']) #99
#新增的key存在,就是新增,如果存在,就是更新
my_dict1['xiao']=78
print(my_dict1) #{'wang': '99', 'zhang': '66', 'gong': '77', 'liu': '44', 'xiao': 78}
#更新
my_dict1['xiao']=90
print(my_dict1) #{'wang': '99', 'zhang': '66', 'gong': '77', 'liu': '44', 'xiao': 90}
#删除
x=my_dict1.pop('xiao')
print(my_dict1) #{'wang': '99', 'zhang': '66', 'gong': '77', 'liu': '44'}
print(x) #90
#清空元素
my_dict1.clear()
print(my_dict1) #{}
#查看所有的key
print(my_dict2.keys()) #dict_keys(['wang', 'zhang', 'gong', 'liu'])
#遍历字典
for key in my_dict2.keys():
print(my_dict2[key]) # 99
#66
#77
#44
#统计字典内的所有信息
print(my_dict2.items()) #dict_items([('wang', '99'), ('zhang', '66'), ('gong', '77'), ('liu', '44')])
print(len(my_dict2)) #4个元素
数据类型分类

数据容器的通用操作
#数据容器的通用操作-遍历
#都支持遍历操作,都支持len,max,min
#支持排序操作
my_list=[9,1,2,3,4,5,6,7]
my_set={9,1,2,3,4,5,6,7}
my_tuple=(3,1,2,5,4)
my_list.sort()
sorted(my_list)
sorted(my_tuple,reverse=True)
sorted(my_set)
print(my_set)
print(sorted(my_tuple))
#sorted是对内容进行排序,返回一个列表
#tuple因为具有不被修改的特性,所以不会被改变
函数的参数传递
#函数
#设置默认值参数得放在最后面
'''
def user_info(name,age,gender="男"):
print(f"姓名是{name},年龄是{age},性别是{gender}")
user_info('wang',14)
#不定长, 位置不定长 *号
#不定长参数也叫可变参数,用于不确定调用的时候会传递多少个参数,
#作用:当调用参数时不确定参数个数时,可以使用不定长参数
'''
#不定长参数的类型
#位置传递,关键字传递
'''
'''
#第一种位置传递
def user_info(*args):
print(args)
return args
#当使用不定长时,args默认会标记为元组,传递参数的时候会传递到元组里面去
a=user_info(18)
b=user_info('wang',18)
print(type(b)) #<class 'tuple'>
#关键字传递的不定长
#数量也是不受限的,但同时也必须满足key=value的形式来让keyargs来接受
def user_info1(**kwargs):
print(kwargs)
return kwargs
a=user_info1(name='wang',id=112,age=18) #{'name': 'wang', 'id': 112, 'age': 18}
print(type(a)) #<class 'dict'>
lambda函数
#关键字传递的不定长
#数量也是不受限的,但同时也必须满足key=value的形式来让keyargs来接受
def user_info1(**kwargs):
print(kwargs)
return kwargs
a=user_info1(name='wang',id=112,age=18) #{'name': 'wang', 'id': 112, 'age': 18}
print(type(a)) #<class 'dict'>
#匿名函数 就是没有名称
#有名称的函数,可以基于名称重复使用。无名称的函数,只能临时使用一次
#使用场景见如下
#lambda 传入参数:函数体
my_list=[1,2,3,4]
def test(x):
result=x(2)
return result
#print(test(my_list[2]))TypeError: 'int' object is not callable
print(test(lambda x:x*2))#test里面的参数必须得是一个函数的地址 #总结lamdba使用的本质为将函数的地址传递给另外一个函数。非常简单好用
#lambad函数提升了一些应用场景,简洁明了
#如果该函数如果需要使用多次,那么就用def,只使用一次就用lambda