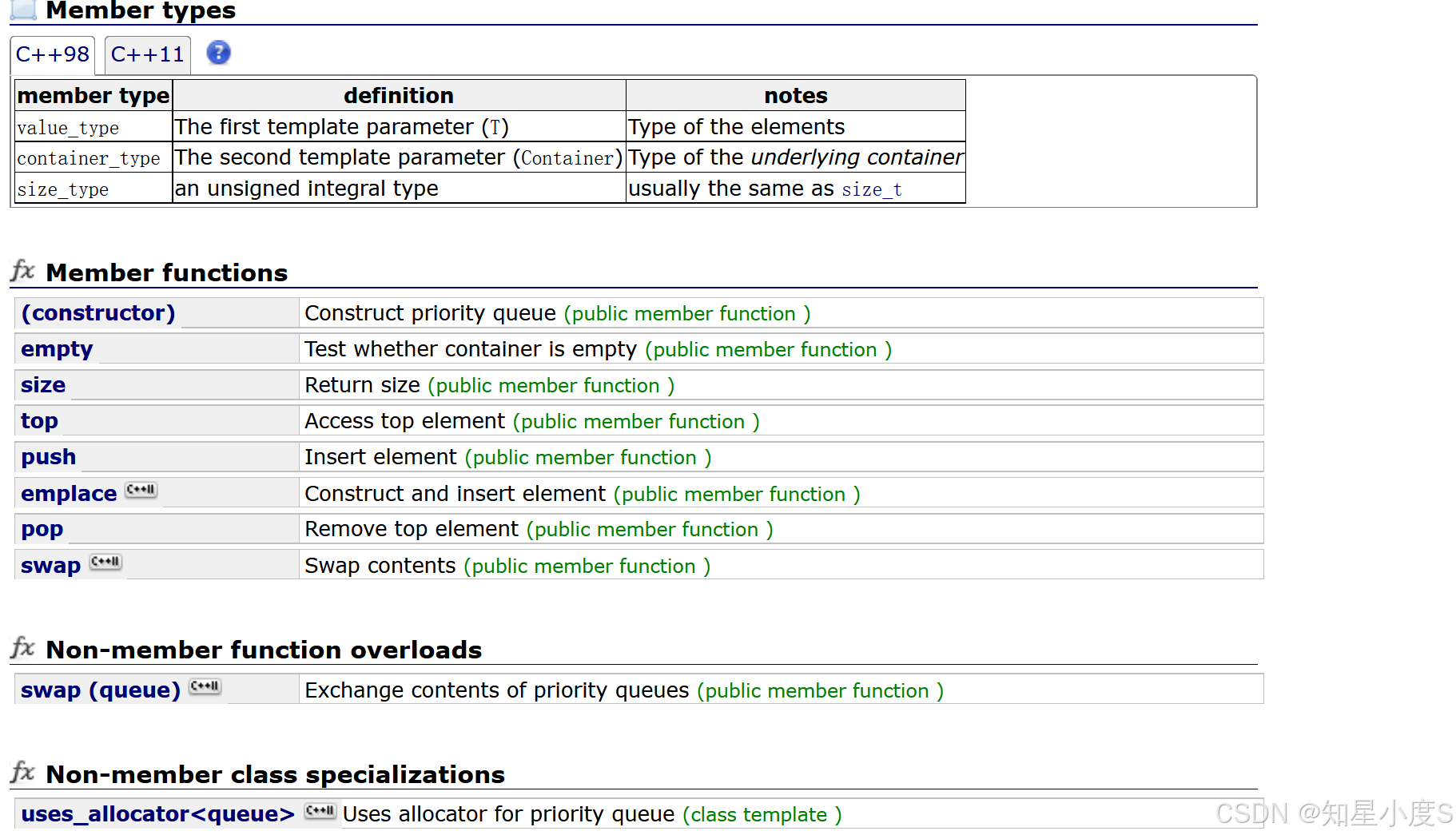
Auto-RAG:用于大型语言模型的自主检索增强生成
单位:中科院计算所
代码: https://github.com/ictnlp/Auto-RAG
拟解决问题:通过手动构建规则或者few-shot prompting产生的额外推理开销。
贡献:提出一种以LLM决策为中心的自主迭代检索模型
Abstract
迭代检索是指模型在生成过程中不断查询检索器,以增强检索到的知识的相关性,从而提高检索增强生成 (RAG) 的性能的过程。现有工作通常采用小样本提示或手动构建的规则来实现迭代检索。这引入了额外的推理开销,并忽视了大型语言模型 (LLM) 卓越的推理能力。在本文中,我们介绍了 Auto-RAG,这是一种以 LLM 强大的决策能力为中心的自主迭代检索模型。Auto-RAG 与检索器进行多轮对话,系统地规划检索并优化查询以获取有价值的知识。此过程一直持续,直到收集到足够的外部信息,此时结果将呈现给用户。为此,我们开发了一种在迭代检索中自主合成基于推理的决策指令的方法,并对最新的开源 LLM 进行了微调。实验结果表明,Auto-RAG 能够与检索器进行自主迭代交互,有效利用 LLM 卓越的推理和决策能力,从而在六个基准中取得优异的表现。进一步分析表明,Auto-RAG 可以根据问题的难度和检索到的知识的效用自主调整迭代次数,而无需任何人工干预。此外,Auto-RAG 以自然语言表达迭代检索过程,增强可解释性,同时为用户提供更直观的体验。
Introduction
为了解决检索内容中的噪声(回答中会有很多不相干的内容)以及复杂查询(问题简单,但却要检索很多内容。如:行军路线)。已经提出了迭代检索(Feng et al., 2023; Chen et al., 2024; Asai et al., 2023) (Yu 等, 2024, p. 1)。当前的迭代过程大多依赖few-shot prompting和人力构建规则,忽视了大语言模型的推理能力。
因此引入Auto-RAG,下图展示了其如何解决复杂多跳问题的一个具体示例。
Related Work
检索增强生成的引入是为了解决:
-
LLM对长尾知识保留不足;
-
模型参数中嵌入过时知识。
检索器缺陷(主要是检索内容的噪音)解决:
-
改进查询公式“(Ma et al., 2023)” (Yu 等, 2024, p. 3)
-
增强检索器“(Karpukhin et al., 2020; Chen et al., 2023)” (Yu 等, 2024, p. 3)
-
改进生成器“(Yoran et al., 2023; Yu et al., 2023)” (Yu 等, 2024, p. 3)
-
后检索优化“(Yu et al., 2024; Xu et al., 2023)” (Yu 等, 2024, p. 3)
任务复杂性的增加导致单词检索难度增大。
-
ITER-RETGEN将输入问题与上一次迭代生成的输出连接起来,以形成下一次迭代的新查询。(仅仅反映现有知识,没有明确LLM的信息需求)
-
FLARE使用下一个生成的句子作为查询,根据检索结果对前一个句子进行提炼。尽管这种方法更精确地识别了 LLM 的信息需求,但其有效性在很大程度上取决于精心制作的few-shot prompt,需要不断检索和改进,从而导致大量的人工工作和推理成本增加。
-
Self-RAG训练 LLM 反思检索和生成的内容。然而,Self-RAG 只在训练期间学会机械地预测反射标记,而没有培养推理能力,这进一步限制了这种方法的有效性。
与上述方法相比,Auto-RAG 充分释放了 LLM 在迭代检索过程中基于推理的自主决策的潜力。Auto-RAG 使 LLM 能够通过推理自主决定何时检索以及检索什么。与其他迭代检索方法相比,Auto-RAG 提供了卓越的性能和更高的效率。
Method
Reasoning-based iterative retrieval
$(X,Y)→[X,R_0,(Q_t,D_t,R_t)_{1≤t≤T},A]$
例子:
原始输入
X: "诸葛亮北伐时蜀军是如何行军的?"初始推理
R₀: 模型先根据已有知识进行第一步推理,例如:“诸葛亮北伐是三国时期蜀汉对曹魏的军事行动,总共有数次。这需要进一步确认是哪一次北伐。”
迭代过程(每一轮表示一次信息检索与推理)
在数据合成期间,2WikiMultihopQA 的 T 设置为 10,Natural Questions设置为 5。
第 1 次迭代:
Q₁: 从 R₀ 中抽取的信息需求,例如:“诸葛亮第一次北伐的时间、出发地和目标区域?”
D₁: 检索到的文档段落,比如:“第一次北伐发生在建兴六年(228年),诸葛亮从汉中出发,经由祁山攻打陈仓。”
R₁: 新的推理内容:“第一次北伐路线是从汉中出发,经祁山,目标是陈仓。”
🔄 第 2 次迭代:
Q₂: 进一步需要的信息:“蜀军途径哪些地点?是否有记载他们在哪些地方驻扎或作战?”
D₂: 检索到的新段落:“北伐军在途中经过武都、阴平,派遣马谡驻守街亭,街亭失守导致退兵。”
R₂: 新的推理内容:“行军路线包括汉中 → 祁山 → 武都 → 阴平 → 街亭,但因街亭失守,北伐失败。”
注:如果前一次迭代的推理 Rt−1 包含信息需求4,则查询 Qt 将被采纳(标准:预定义了 “however”、“no information”、“find” 和 “refine” 等术语来表示模型的信息需求。如果输出中出现任何上述内容,则表示需要额外信息),检索器将为 Qt 提供文档 Dt。
🎯 最终答案:
A: 综合所有推理得出最终结论:“诸葛亮第一次北伐时,蜀军从汉中出发,沿祁山、武都、阴平一线北上,目标是陈仓,派遣马谡驻守街亭,但因街亭失守导致北伐失败。”
Reasoning based planning and query refinement
推理范式
-
Retrieval Planning
-
Information Extraction
-
Answer Inference
需要注意的是,在最初收到用户的问题时,通常会省略步骤 2和 3。此外,如果发现检索到的信息完全不相关,则步骤2也被排除在外。这种调整使 LLM 能够根据实际情况做出明智的判断,而不仅仅是模仿演示和产生幻觉。用于引出推理的提示在附录 C.1 中给出。


通过适当的推理过程,LLM 可以根据用户输入和以前的检索计划迭代优化查询,不断适应新的信息要求。为了生成足够多样化的查询集,而不受 few-shot prompt中出现的查询样式的限制,我们采用了更灵活的提示方法,如附录 C.5 所示(这个模板很合适)。

Data Filtering & Formatting
Data Filtering(Algorithm 1)
🔁 执行 Algorithm 1:
第 1 步:初始化
DInst = []
第 2 步:对数据集 D 中每对 (X, Y) 遍历,这里我们只有一对。
第 3 步:语言模型 M 进行首次推理
R0 = M.predict_reasoning(X)
输出示例:
“诸葛亮北伐多次,需要先明确是第几次,才能判断路线。”
第 4 步:设置轮次计数
t = 1
第 5~18 步:迭代推理和检索(最多 T 次)
我们设 T = 2,进行两轮迭代。
🔁 第一次迭代(t = 1)
Step 6:生成多个查询 Qgen
Qgen = M.generate_queries(X, R0)
输出示例:
["诸葛亮第一次北伐发生在哪一年?", "诸葛亮北伐是从哪里出发的?"]
Step 7~11:尝试找一个 query 能检索出包含“部分答案”的文档
-
设
R.retrieve()找到:
d = "第一次北伐发生在建兴六年(228年),从汉中出发,经祁山攻魏。"
识别出包含部分答案(“汉中 → 祁山”),满足条件:
Qt = "诸葛亮北伐是从哪里出发的?" Dt = d
Step 15:语言模型根据前面内容生成本轮推理
R1 = M.reason(X, R0, [(Qt, Dt)], Qt, Dt)
输出:
“诸葛亮第一次北伐是从汉中出发,经祁山北上,这是行军的初始部分。”
Step 16:判断是否还有信息需求
模型发现还需知道是否经过其他地点,所以继续迭代。
t = 2
🔁 第二次迭代(t = 2)
Step 6:基于前一轮推理生成新 query
Qgen = M.generate_queries(X, R1)
输出:
["诸葛亮北伐过程中是否经过街亭?", "蜀军在哪些地方战斗或驻扎?"]
Step 8~11:检索文档
例如:
d = "蜀军派马谡驻守街亭,街亭失守导致全军撤退。"
识别出是部分答案(街亭事件)。
Qt = "诸葛亮北伐过程中是否经过街亭?" Dt = d
Step 15:生成新的推理
R2 = M.reason(X, R0, [(Q1, D1, R1)], Qt, Dt)
输出:
“街亭是北伐途中的关键战役地点,蜀军在此失败,决定了整个北伐的结局。”
Step 16:判断是否还需检索
此时 R2 包含完整的信息,模型判断无需再提问,跳出循环。
Step 19:生成最终回答
A = M.answer(X, R0, [(Q1, D1, R1), (Q2, D2, R2)])
输出:
“诸葛亮第一次北伐路线为汉中 → 祁山 → 街亭。街亭失守后,北伐失败撤退。”
Step 20:验证是否和真实答案匹配
if A == Y: # 或通过相似度度量近似判断
✅ 匹配,加入训练集。
最终输出:
DInst.append([X, R0, (Q1, D1, R1), (Q2, D2, R2), A])
🧾 总结输出结果格式:
{ "X": "诸葛亮北伐时蜀军是如何行军的?", "R0": "诸葛亮北伐多次,需要明确是哪次。", "Iterations": [ { "Q": "诸葛亮北伐是从哪里出发的?", "D": "第一次北伐发生在建兴六年(228年),从汉中出发,经祁山攻魏。", "R": "北伐路线从汉中出发,经祁山北上。" }, { "Q": "诸葛亮北伐过程中是否经过街亭?", "D": "蜀军派马谡驻守街亭,街亭失守导致全军撤退。", "R": "街亭是北伐途中的关键战役地点,蜀军在此失败后撤退。" } ], "A": "诸葛亮第一次北伐路线为汉中 → 祁山 → 街亭。街亭失守后,北伐失败撤退。" }
Data Formatting
类似于一个多轮对话生成
Training
有监督

Inference
为了避免无休止的推理而无法生成答案采用Algorithm2,在到达一定迭代次数的时候获取参数知识
Experiment
数据集:Natural Questions & 2WikiMultihopQA
推理过程:Qwen1.5-32B-Chat
重写查询:Llama-3-8B-Instruct
没有Baseline,选取zero-shot模型的Naive RAG作为Baseline。对比结果见
“Table 1: Main results on six benchmarks. Auto-RAG consistently outperforms all baselines.” (Yu 等, 2024, p. 7)
Analysis
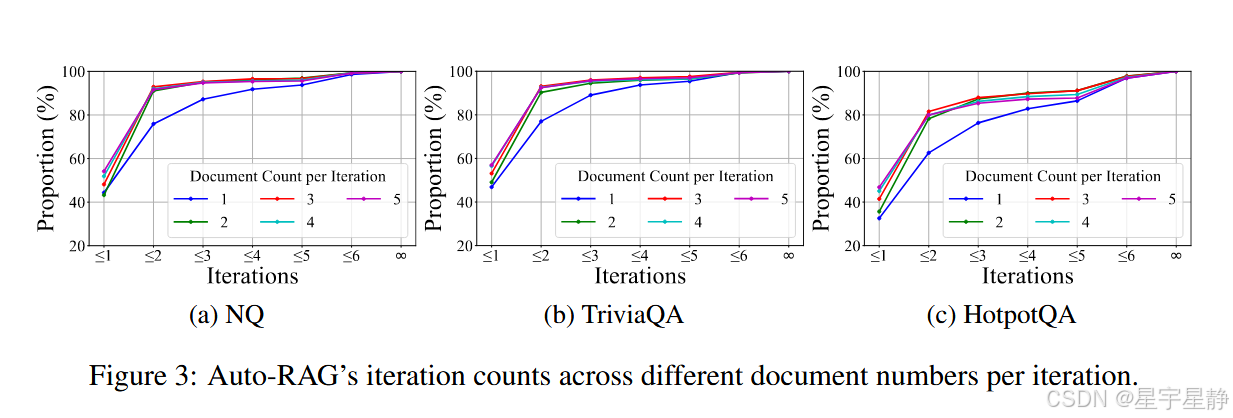
不同数量文档和不同迭代次数上AutoRAG的表现。可以看出(a)(b)数据集是单跳数据集终止的轮数较快,而Hotpot问题终止的轮数叫慢,体现模型的自适应性很强。
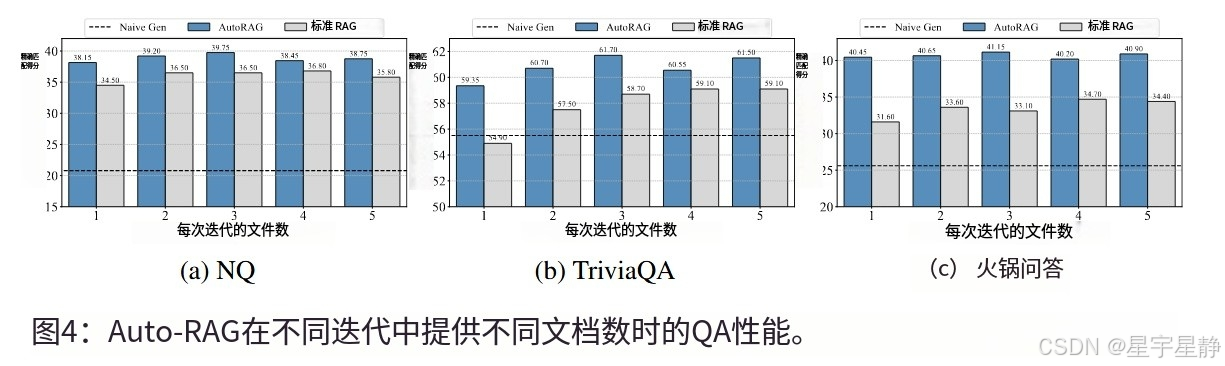
如图 4 所示,在每次迭代中提供不同数量的文档对整体 QA 性能有一定的影响。在这三项任务中,每次迭代提供三个文档会产生出色的结果,这表明为 Auto-RAG 提供适当大小的文档是有益的。我们还将 AutoRAG 与无检索方法 (Naive Gen) 和标准 RAG 进行了比较。Auto-RAG 在每次迭代的不同文档计数上始终优于它们。值得注意的是,Auto-RAG 表现出比 Standard RAG 更小的性能波动,证明了其对猎犬的卓越稳健性。
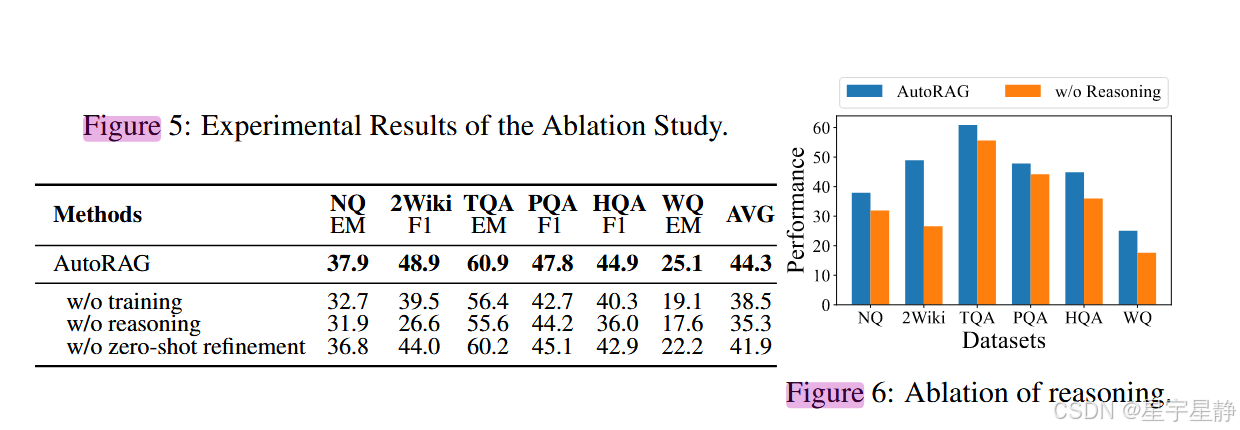
消融实验表明推理模块确实有用,few-shot也要比zero-shot要好
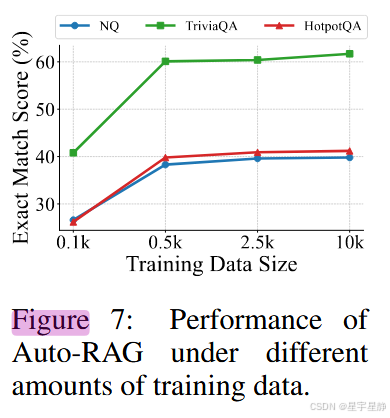
数据规模越大越好,收敛也更快。
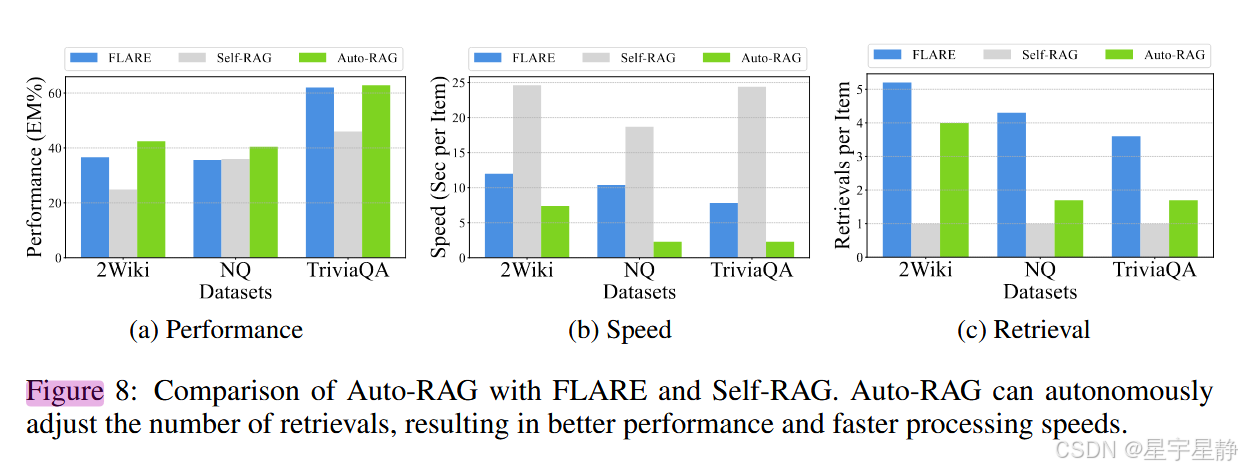
表现整体更好,检索速度较慢,轮数也适中。
Conclusion
在本文中,我们介绍了 Auto-RAG,这是一种以 LLM 强大的决策能力为中心的自主迭代检索模型。Auto-RAG 通过多轮对话与检索器交互,系统地规划检索和优化查询以获取有价值的知识,直到获得足够的外部信息,此时结果将呈现给用户。为此,我们开发了一种在迭代检索中自主合成基于推理的决策指令的方法,并对最新的开源 LLM 进行了微调。分析结果表明,Auto-RAG 不仅取得了出色的性能,而且保留了高度的可解释性,为用户提供了更直观的体验。