- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
ShuffleNet是Face++(旷视)在2017年发布的一个高效率可以运行在手机等移动设备的网络结构,论文发表在CVRP2018上。它是一种轻量级卷积神经网络架构,旨在在计算资源有限的情况下实现高效的模型推理。它是专门为计算能力有限的移动平台设计的。

通过逐点分组卷积(Pointwise Group Convolution) 和通道洗牌(Channel Shuffle) 两种新运算,在保持精度的同时大大降低了计算成本 。
ShuffleNet 比最近的 MobileNet 在 ImageNet 分类任务上的 top-1误差更低 (绝对7.8%) 。在基于ARM的移动设备上,ShuffleNet 比 AlexNet 实现了约13倍的实际加速,同时保持了相当的精度 。
一、ShuffleNet V1
2017年之前,最优的算法结构例如Xception、ResNext等因为大量使用1×1卷积,虽然会使模型变小,但导致计算效率降低。ShuffleNet中的pointwise group convolution可以降低1×1卷积的计算复杂度。但是group卷积也有一定缺点,为了解决组卷积带来的副作用,提出了channel shuffle来帮助信息在各通道之间流动。
与热门的VGG和ResNet相比,在限定的计算复杂度之内,ShuffleNet允许有更多的特征映射通道,这有助于编码更多的信息,并且这对非常小的网络的性能特别关键。
1.分组卷积(Group Convolution)
分组卷积(Group Convolution) 的概念首先是在 AlexNet 中引入,用于将模型分布到两块 GPU 上 。
Group convolution是将输入层的不同特征图进行分组,然后采用不同的卷积核再对各个组进行卷积,这样会降低卷积的计算量。因为一般的卷积都是在所有的输入特征图上做卷积,可以说是全通道卷积,这是一种通道密集连接方式(channel dense connection),而group convolution相比则是一种通道稀疏连接方式(channel sparse connection)。
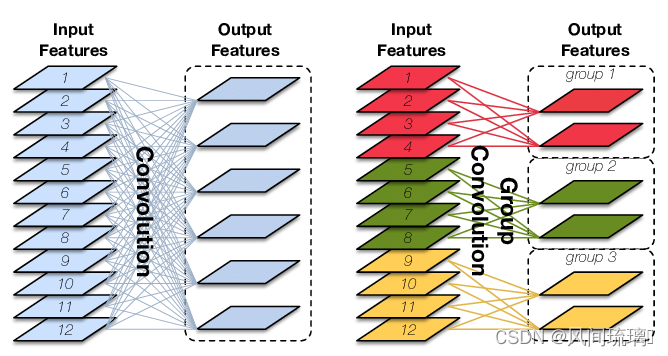
常规卷积 VS 分组卷积
如果输入feature map尺寸为C∗H∗W,卷积核有N个,输出feature map与卷积核的数量相同也是N,每个卷积核的尺寸为C∗K∗K,N个卷积核的总参数量为N∗C∗K∗K,输入map与输出map的连接方式如上图左所示。
Group Convolution,则是对输入feature map进行分组,然后每组分别卷积。
假设输入feature map的尺寸仍为C∗H∗W,输出feature map的数量为N个,如果设定要分成G个groups,则每组的输入feature map数量为C/G,每组的输出feature map数量为N/G,每个卷积核的尺寸为C/G∗K∗K,卷积核的总数仍为N个,每组的卷积核数量为N/G,卷积核只与其同组的输入map进行卷积,卷积核的总参数量为N∗C/G∗K∗K。
可见,总参数量减少为原来的 1/G,其连接方式如上图右所示,group1输出map数为2,有2个卷积核,每个卷积核的channel数为4,与group1的输入map的channel数相同,卷积核只与同组的输入map卷积,而不与其他组的输入map卷积。
在小型网络中,逐点卷积会导致满足复杂度约束的通道数量有限,从而严重的影响精度 ;最直接的解决方案是:采用通道稀疏连接( channel sparse connections ),例如分组卷积可以大大降低计算成本 。但是,这样就会出现一个 问题 :某个通道的输出只能来自一小部分输入通道,这样阻止了通道之间的信息流,也就削弱了神经网络表达能力 ;
为此作者进一步将分组卷积和深度可分离卷积推广为一种新的形式:通道洗牌操作( Channel Shuffle Operation )。
2.通道洗牌(Channel Shuffle)
为达到特征通信目的,采用Channel Shuffle操作,其含义是对Group Convolution后的特征图进行重组,这样可以保证接下了采用的Group Convolution其输入来自不同的组,因此信息可以在不同组之间流转。进一步的展示了这一过程并随机,其实是均匀地打乱。
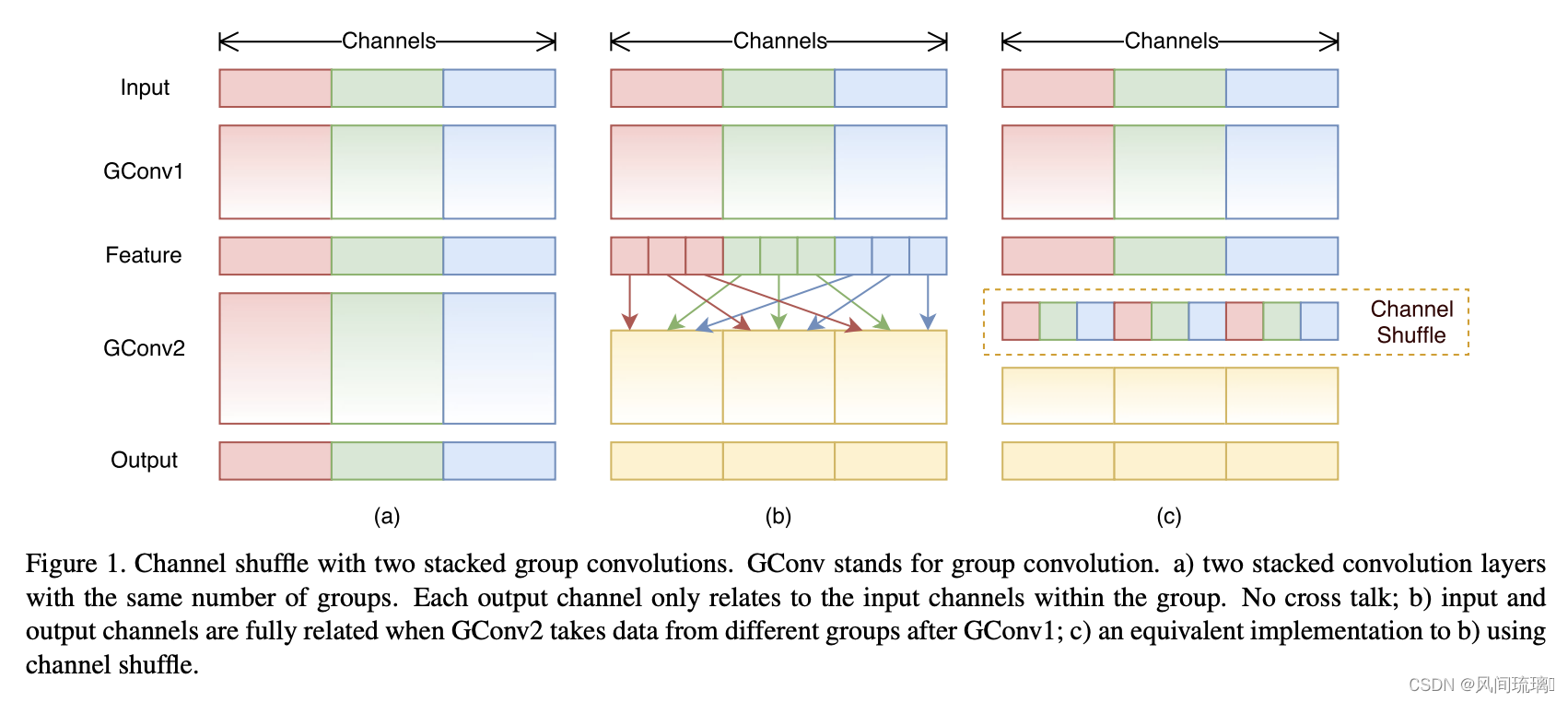
对于普通分组卷积,如上图 a 所示,都是针对该组内的 channel 信息进行卷积操作,如果简单串联的话,则一直对同一个组内的信息进行处理,组与组之间是没有信息交流的,阻止了通道之间的信息流,也就削弱了神经网络表达能力。
当加入channel shuffle 操作,首先还是进行分组卷积得到特征矩阵,假设使用三个 group,如上图 b 所示。然后对特征矩阵原来的 group 再进行更细粒度的划分成三个 sub-group,将每个组中的第一个 sub-group 放到一起,将每个组中的第二个 sub-group 放到一起…,就能形成新的特征矩阵,如(c)中的Channel Shuffle。然后再进行分组卷积,就使得组与组之间的信息可以得到交流。
通过 通道洗牌(Channel Shuffle) 允许分组卷积从不同的组中获取输入数据,从而实现输入通道和输出通道相关联 。
3. ShuffleNet Unit
ShuffleNet Unit是基于残差块(residual block)、Group convolution和Channel Shuffle设计。
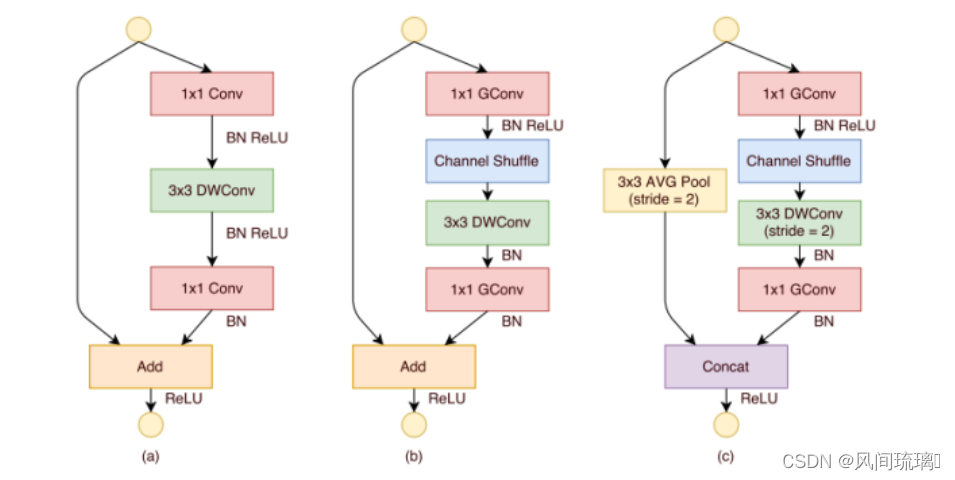
图(a)是Resdual block
①1×1卷积(降维)+3×3深度卷积+1×1卷积(升维)
②之间有BN和ReLU
③最后通过add相加
图(b)为输入输出特征图大小不变的ShuffleNet Unit
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 + Channel Shuffle
②去掉原3×3深度卷积后的ReLU
③ 将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
(b)展示了改进思路:将密集的1x1卷积替换成1x1的Group Convolution(因为主要计算量较大的地方是密集的1x1的卷积操作),然后在之后增加了一个Channel Shuffle操作。第二个逐点群卷积的目的是恢复通道维数以匹配shortcut路径。为了简单起见,不在第二个逐点层之后应用额外的channel shuffle操作,因为它产生的结果变化不大。这里是stride为1的情况。
图(c)为输出特征图大小为输入特征图大小一半的ShuffleNet Unit
①将第一个用于降低通道数的1×1卷积改为1×1分组卷积 +Channel Shuffle
②令原3×3深度卷积的步长stride=2, 并且去掉深度卷积后的ReLU
③将第二个用于扩增通道数的1×1卷积改为1×1分组卷积
④shortcut上添加一个3×3平均池化层(stride=2)用于匹配特征图大小
⑤对于块的输出,将原来的add方式改为concat方式
(c)降采样操作,对于使用stride>1(stride=2)的情况,只需做两个修改:
(1)在shortcut路径上添加3×3平均池化
(2)将逐元素相加ADD替换为通道级联Concat,这使得可以在不增加额外计算成本的情况下轻松地扩大通道维数。
ResNet、ResNeXt和ShuffleNet网络的参数使用对比
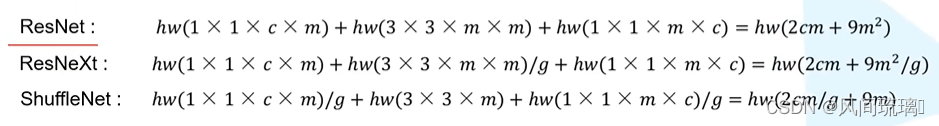
计算可以知道,ShuffleNet V1的参数使用量比ResNet和ResNeXt网络的参数都要少。在给定的有限的计算资源下,ShuffleNet 能够使用更宽的特征图。 作者发现这对于小型网络来说至关重要,因为通常小型网络通常有很少的通道数来处理信息。
4.网络结构
基于ShuffleNet Unit,如下表中展示了整个ShuffleNet V1结构,首先使用的普通的3x3的卷积和max pool层,接着网络主要由为三个阶段的ShuffleNetUnit单元的堆栈组成(stage2/3/4),每个stage第一层stride=2,从而实现降采样的功能,每个stage中的其他超参数保持不变,从上一个stage到下一stage中的输出通道数加倍。与ResNet类似,每个ShuffleNet Unit中bottleneck中的通道数设置为输出通道数的1/4。
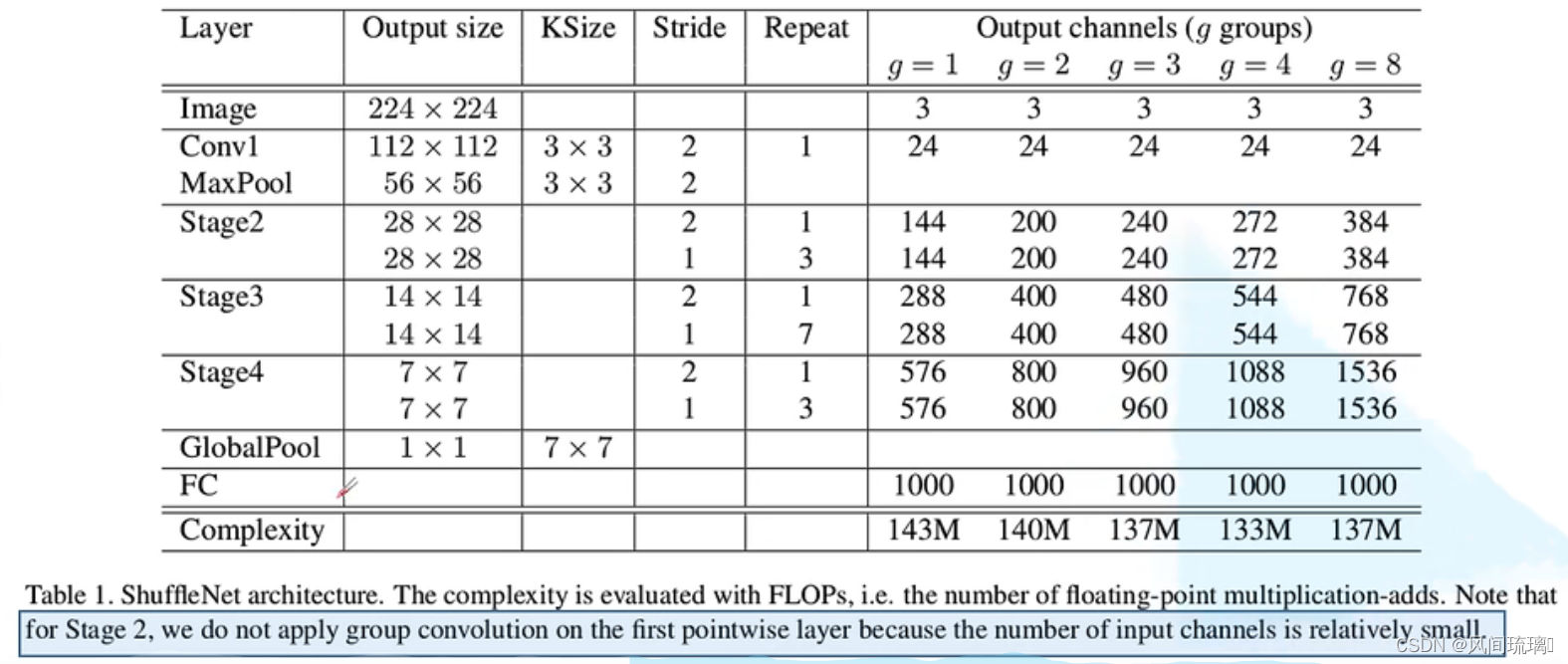
在ShuffleNet unit 中,组个数g代表着逐点卷积的连接稀疏程度。在上图中展示了不同的组数量的方案,同时通过调整输出通道数(网络的宽窄),来使得整体的计算量大致相同。那么对于一个给定的计算量约束,g越大,则可以设置越多的卷积核,产生越多的输出通道,从而帮助编码更多的信息,其中较多论文使用的是g=3的版本。
创新点
①使用分组逐点卷积(Group Convolution)来降低1×1卷积的计算复杂度
②使用通道重排(Channel Shuffle)操作来帮助信息在特征通道间流动
二、ShuffleNet V2
ShuffleNet v2是一种深度神经网络架构,与ShuffleNet v1和MobileNet v2相比,在计算复杂度为40M FLOPs的情况下,精度分别比ShuffleNet v1和MobileNet v2高3.5%和3.7%。ShuffleNet v2的框架与ShuffleNet v1基本相同,都包括Conv1、Maxpool、Stage 2~5、Global pool和FC等部分。唯一的不同是ShuffleNet v2比ShuffleNet v1多了一个1x1 Conv5。ShuffleNet v2还提供了四个不同版本,即ShuffleNet v2 0.5x、ShuffleNet v2 1x、ShuffleNet v2 1.5x和ShuffleNet v2 2x。
ShuffleNetV2中提出了一个关键点,之前的轻量级网络都是通过计算网络复杂度的一个间接度量,即FLOPs,通过计算浮点运算量来描述轻量级网络的快慢。
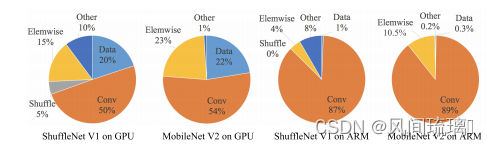
但是从来不直接考虑运行的速度。在移动设备中的运行速度不仅仅需要考虑FLOPs,还需要考虑其他的因素,比如内存访问成本(memory access cost)和平台特点(platform characterics)。
所以,ShuffleNet v2通过控制不同的环境来测试网络在设备上运行速度的快慢,而不是通过FLOPs来判断性能指标。
因此,ShuffleNetv2提出了设计应该考虑两个原则:
①应该使用直接度量(如速度)而不是间接度量(如FLOPs)。
②这些指标应该在目标平台上进行评估。
然后,ShuffleNetv2根据这两个原则,提出了四种有效的网络设计原则:
G1: Equal channel width minimizes memory access cost (MAC)
G2: Excessive group convolution increases MAC
G3: Network fragmentation reduces degree of parallelism
G4: Element-wise operations are non-negligible
1.高效网络设计的实用准则
(1) Equal channel width minimizes memory access cost (MAC)
当保持FLOPs不变时,卷积层的输入特征矩阵与输出特征矩阵相等时,MAC最小,这里针对1x1的卷积层。
相同的channel可最大限度地降低内存访问成本(MAC):轻量化网络通常采用深度可分离卷积,其中逐点卷积(即1×1卷积)占了绝大部分的计算量。我们研究了1×1卷积的核心形状,其由两个参数指定:输入通道的数量c1和输出通道的数量c2。设h和w为feature map的空间大小,1×1卷积的FLOPs为B = h * w * c1 * c2。内存访问成本(MAC),即内存访问操作数,为
这个公式分别对应于输入/输出特性映射的内存访问和卷积核权重。其实这条公式可以看成由三个部分组成:第一部分是,对应的是输入特征矩阵的内存消耗;第二部分是
,对应的是输出特征矩阵的内存消耗。第三部分是
。
然后根据均值不等式得出:
因此理论上MAC的下界由FLOPs决定,当且仅当c1 = c2 时取得最小值。
在实验中,由于内存的限制,加上卷积库对于卷积使用的模块优化,真实情况会略有差异,因此作者在现实情况中做了实验结果如图:
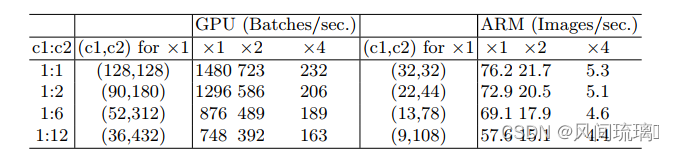
通过改变比率c1: c2显示了在固定总FLOPs时的运行速度。可见,当c1: c2接近1:1时,MAC变小,网络评估速度加快。
(2) Excessive group convolution increases MAC
当GConv的groups增大时(保持FLOPs不变时),MAC也会增大。
组卷积的组数越大,MAC越大,组卷积是轻量化网络的核心,它通过将所有channel之间的密集卷积改变为稀疏(仅在同一组内)来降低计算复杂度(FLOP)。
一方面,因为组卷积相比普通卷积降低了计算量,因此在给定FLOP的情况下使用组卷积可以使用更多的channel,增加了网络的容量(从而提高了精度)。然而,另一方面,增加的channel数导致更多的MAC。
假设 g 是1x1组卷积的组数,则有:
给定固定的输入形状c1× h × w,计算代价B, MAC随着g的增长而增加(线性函数)。
实验结果如下,

通过保持FLOPs一定的情况下,改变g的数值,以GPU x1 与CPU x1为例进行说明,当g=1的时候,每秒能推理2451个batches;当g=2,每秒能推理1725个batches;当g=8,每秒能推理634个batches;当g有1到8,它的推理速度下降到原来的1/4还是非常明显的。但在cpu上我们发现它下降的连一半都不到。
(3)Network fragmentation reduces degree of parallelism
网络设计的碎片化程度越高,速度越慢。这里所说的碎片化可以理解为网络的分支的程度,大多数网络在设计的时分支比较多。
分支可以是串联,可以是并联,在GoogLeNet系列中,它就并行了有3x3的卷积层,5x5的卷积层,还有池化层等等,他们就很喜欢采用多分支的结构来进行网络的搭建。
在GoogLeNet系列和自动生成的体系结构中,每个网络块都广泛采用了一种多路径结构。许多小型操作,这里称为碎片操作,被用来代替几个大的操作。
虽然这种碎片化结构已经被证明有利于提高准确性,但它可能会降低效率,因为它对GPU等具有强大并行计算能力的设备不友好。它还引入了额外的开销,比如内核启动和同步。
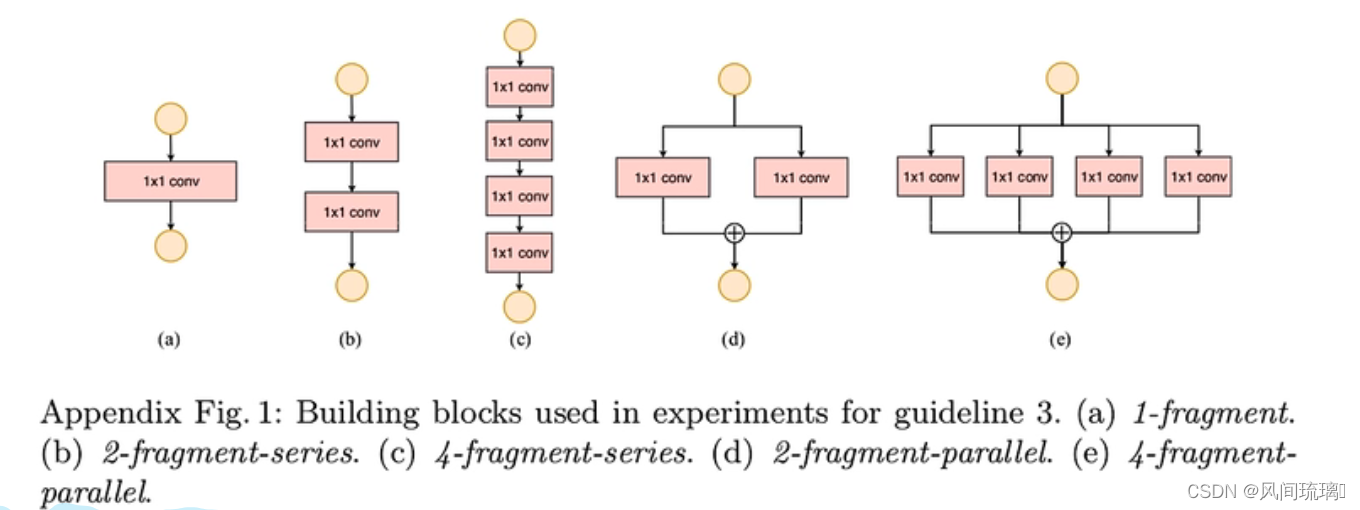
对于(e)块结构,有4个并行的分支,对于每个卷积层都需要有kernel的启动,如果四个并行结构计算时间差不多,影响较小。如果相差很大,运算快的分支运算完成之后就会一直等着运算比较慢的分支,只有等到所有分支全部计算完成后,才能进行下一步计算,因此效率是比较低的。
为了量化网络分片如何影响效率,作者评估了一系列不同分片程度的网络块。每个构造块由1到4个1 × 1的卷积组成,这些卷积是按顺序或平行排列的,每个块重复堆叠10次,块结构上图所示。
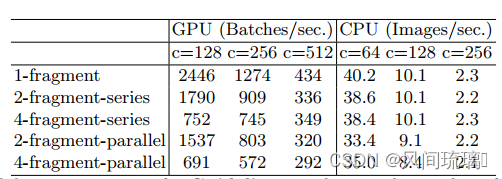
其中上图(a),(b),(c)对应的与1-fragement,2-fragement-series,4-fragement_series,他们是简单的串行,同样是保持FLOPs不变的情况下,串行的层数越多,碎片化程度越高我们的推理速度也是越来越慢的。
对于图(d),(e),对应的是2-fragement-parallel,4-fragement-parallel,也同样是碎片化程度越高,推理速度越慢。但是在cpu上其实变化是不大的,GPU变化非常明显。
(4)Element-wise operations are non-negligible
逐元素操作的执行时间是不可忽略的。

在像ShuffleNet V1和MobileNet V2这样的轻量级模型中,逐元素操作占用了相当多的时间,尤其是在GPU上。逐元素运算包括激活函数比如ReLU,AddTensor比如shortcut分支与主分支的输出进行Add操作,AddBias比如卷积运算过程中偏置相加等。
对于每一个元素型操作的都叫Element-wise operation,这些操作的特点都是它的FLOPs很小,但是他们的MAC很大。作者也说了像depthwise convolution也可以看做为element-wise operator。因为它也具有较高的MAC / FLOP比。
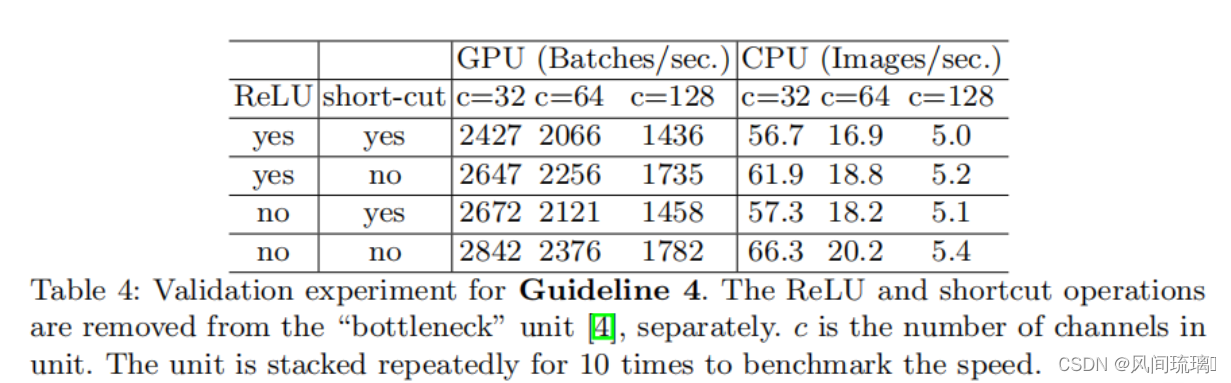
可以看见上表中报告了不同变体的运行时间。观察到,在移除ReLU和shortcut后,GPU和ARM都获得了大约20%的加速。这里主要突出的是,这些操作会比我们想象当中的要耗时。
总结:基于上述准则和实证研究,作者总结出一个高效的网络架构应该:
①要使用“平衡”卷积,使输入特征矩阵和输出矩阵的channel相等或者接近
②注意分组卷积的计算成本,增大组数能降低参数,但是它会增加计算成本
③降低网络的碎片程度,不要涉及多分支结构
④尽可能减少使逐元素操作(element-wise operator)
2. 网络结构
如下图所示,图(a)和图(b)是shuffleNet V1,其中(a)是DW卷积步距为1时的block,(b)是DW卷积步距为2时的 block。右边的图(c)和图(d),是shuffleNet V2中对应步距为1和2的block。

ShuffleNetV2在V1上做出了一些改进,如图( c )所示,在每个单元的开始,通过一个Channel Split操作将输入特征矩阵划分为两部分,一部分是shortcut分支,另一部分对应于主分支(在ShuffleNetV2中这里是对channels均分成两半)。根据G3,不能使用太多的分支,所以其中一个分支不作改变,另外的一个分支由三个卷积组成,它们具有相同的输入和输出通道以满足G1。
在主分支上,两个1 × 1卷积不再是组卷积,而改变为普通的1x1卷积操作,这是为了遵循G2(需要考虑组的代价)。卷积后,两个分支被拼接,而不是相加(G4)。因此,通道的数量保持不变(G1)。
然后使用与ShuffleNet V1中相同的Channels Shuffle操作来启用两个分支之间的信息通信。需要注意,ShuffleNet v1中的“Add”操作不再存在。ReLU和depthwise convolutions 这样的元素操作只存在于一个分支中。
对于三个连续的element-wise操作,Concat,Channel Shuffle以及下一个block的Channel Split,这三个操作可以合并为一个element-wise operation,这样减少了element-wise操作的个数,这就满足G4准则。
对于stride为2降采样图(d),ShuffleNet v1使用了3x3的平均池化,而ShuffleNet v2使用了一个3x3 DW卷积和一个1x1的普通卷积。不存在channel split操作,移除通道分离操作符,输出通道的数量增加了一倍。
所提出的block( c )( d )以及由此产生的网络称为ShuffleNet V2。基于上述分析,该体系结构设计是高效的,因为它遵循了所有的指导原则。积木重复堆叠,构建整个网络。ShuffleNet V2网络结构如下表所示。
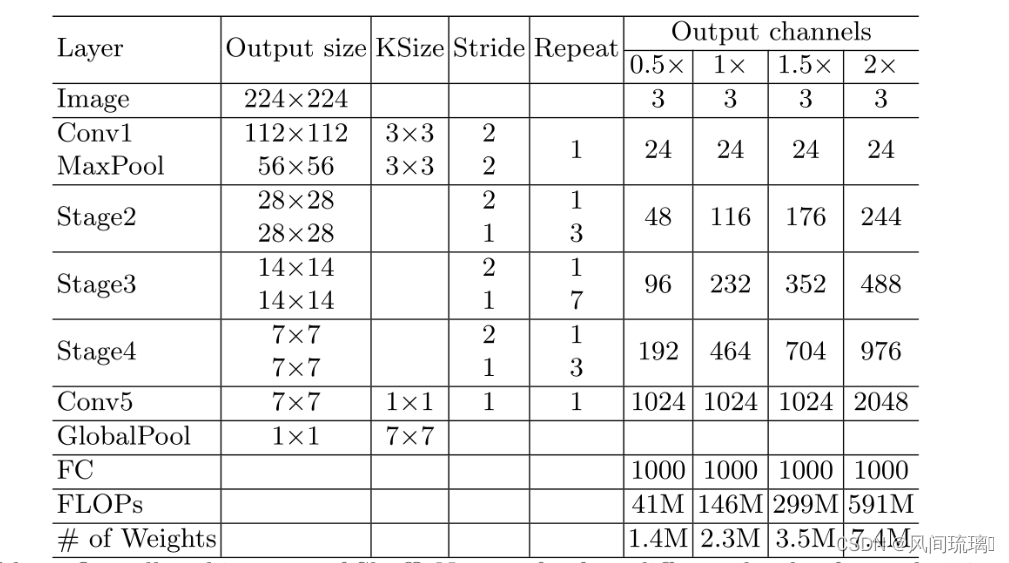
总体网络结构类似于ShuffleNet v1,唯一的区别是在全局平均池化前增加了一个1 × 1的卷积层来混合特性。每个block中的通道数量被缩放,生成不同复杂度的网络,标记为0.5x,1x,1.5x,2x。对于每个stage,它的第一个block是需要进行翻倍的,步距strip都是等于2的。
ShuffleNet v2不仅高效,而且准确,主要有两个原因:
①每个block的高效率使使用更多的特征通道和更大的网络容量成为可能
②在每个block中,有一半的特征通道直接穿过该块并加入下一个块, 可以看作是一种特性复用,与DenseNet和CondenseNet的思想一样
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。






![[unity]保存文件的路径设置](https://img-blog.csdnimg.cn/02fc94df4ae44579b0051ad8b21e4bca.png)