- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
由于传统卷积神经网络, 内存需求大、 运算量大导致无法在移动设备以及嵌入式设备上运行。VGG16的权重大小有450M,而ResNet中152层的模型,其权重模型644M,这么大的内存需求是明显无法在嵌入式设备上进行运行的。而网络应该服务于生活,所以轻量级网络的很重要的。
MobileNet 模型是 google 在 2017 年针对手机或者嵌入式提出轻量级模型。MobileNet是一系列的轻量化神经网络,包括MobileNet v1、MobileNet v2和MobileNet v3。
MobileNet v1是在VGG网络的基础上引入了深度可分离卷积(Depthwise Separable Convolutions),从而使得卷积参数大大减少,达到轻量化的效果。
MobileNet v2在v1的基础上引入了倒残差结构(Bottleneck Residual Block),并加入了shortcut连接,以进一步提高网络的性能。
MobileNet v3使用了 NAS 和 NetAdapt 算法搜索最优的模型结构,同时对模型一些结构进行了改进,例如在 MobileNet v2 的 Bottleneck Residual Block 基础上引入 Squeeze-and-Excitation
一、MobileNet v1
Mobilenet v1是一种轻量级的神经网络结构,用于图像分类和目标检测任务。它的设计目标是在保持较高准确率的同时,减少了模型的计算复杂度和参数量。
Mobilenet v1使用了深度可分离卷积(depthwise separable convolution)来减少计算量。深度可分离卷积将标准卷积分为深度卷积和逐点卷积两个步骤,从而降低了计算量和参数量。此外,Mobilenet v1还使用了全局平均池化来减少全连接层的数量,进一步减小了模型的规模。
介绍MobileNet v1可以使用一句话概括,MobileNet v1只要将把VGG中的标准卷积层换成深度可分离卷积即可。
1.深度可分离卷积
MobileNet模型是基于深度可分离卷积,这是一种分解卷积的形式。这种形式将标准卷积分解为一个深度卷积和一个称为逐点卷积的1x1的卷积。
所以深度可分离卷积应该由两个部分组成,即深度卷积和逐点卷积。用下图直观进行表示:

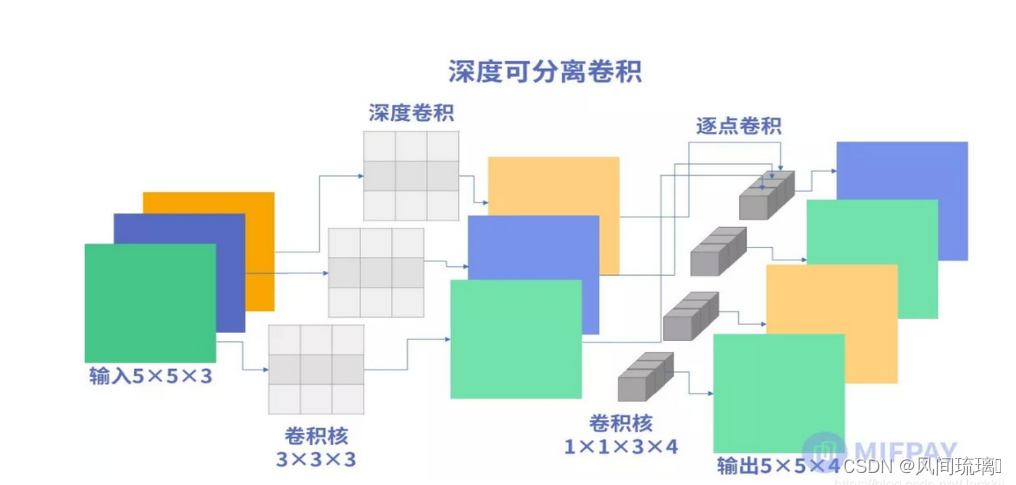
先了解标准卷积的计算过程:对所有输入通道用相同的卷积核得到不同通道特征,将不同通道特征组合起来使得输出特征包含每个输入的特征。
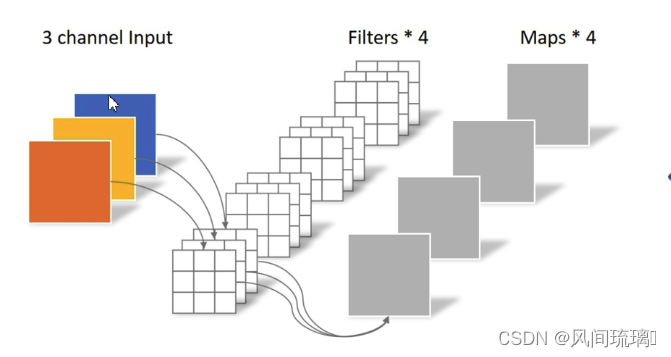
特点:
- 输入特征矩阵channel = 卷积核channel
- 卷积核个数 = 输出特征矩阵channel
(1)深度卷积(Depthwise convolution)
深度卷积对每一个输入通道应用一个单独的卷积核(与标准卷积不同,标准卷积对每一个输入通道应用同一个卷积核)得到特征图,此时,每张特征图仅与一个输入通道和其对应卷积核相关,各个通道之间特征图不关联。
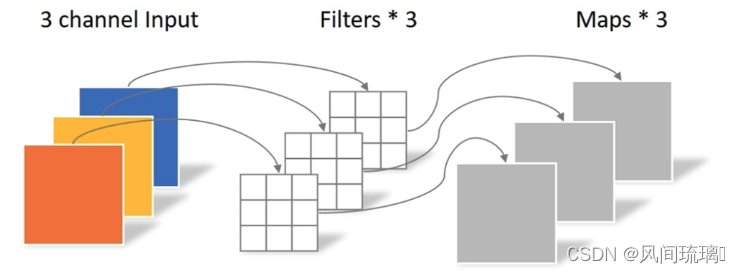
DW卷积中的每一个卷积核,只会和输入特征矩阵的一个channel进行卷积计算,所以输出的特征矩阵就等于输入的特征矩阵。
特点:
- 卷积核channel=1
- 输入特征矩阵channel=卷积核个数=输出特征矩阵channel
(2)逐点卷积(Pointwise convolution)
点卷积(1x1卷积)将深度卷积的输出特征图进行线性组合后再输出,使得最后的输出特征都包含每个输入特征,即将深度卷积输出的不关联的特征图关联起来。
点卷积将标准卷积层中卷积核大小换成1x1即可得到,其主要作用就是对特征图进行升维和降维。
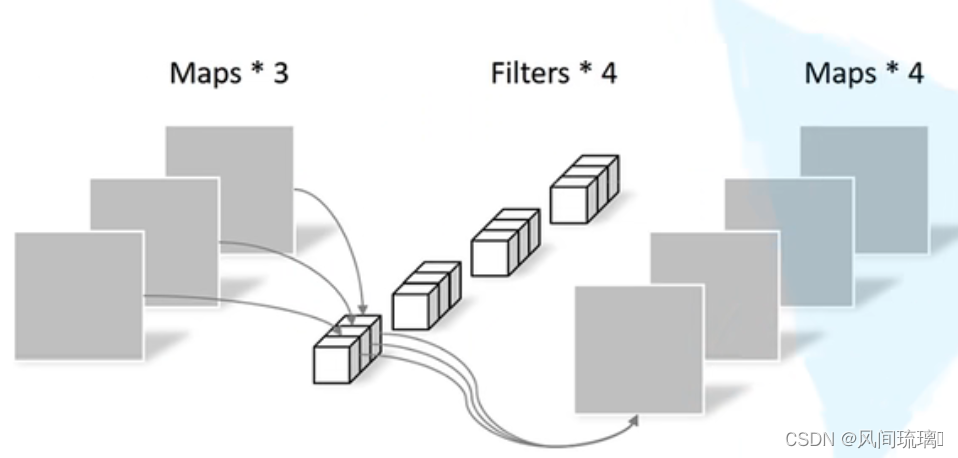
(3)计算量对比
图为标准卷积与深度可分离卷积对应的计算量

其中 为输入Feature Map的宽度和高度(假设输入特征图与使用的卷积核均为正方形),
M为输入通道数 / 输入Feature Map深度),N为输出通道数,为卷积核大小。
然后引入计算量的定义:
参数数量(params):关系到模型大小,单位通常为M,通常参数用 float32 表示,所以模型大小是参数数量的 4 倍。
FLOPS(floating point operations per second):注意全大写,指每秒浮点运算次数,理解为计算速度,是一个衡量硬件性能的指标。
FLOPs(floating point operations):注意s小写(s表复数),指浮点运算数,理解为计算量。
可以用来衡量算法/模型的复杂度。这关系到算法速度,大模型的单位通常为 G,小模型单位通常为 M。
注意在深度学习中,我们用FLOPs,也就是计算量,用来衡量算法/模型的复杂度。
不同神经网络层的参数数量和计算量估计方法:
Conv2d标准卷积层:
Input: H ∗ W ∗ N
Output:H ∗ W ∗ M
Filters: K ∗ K
==>
Params: K ∗ K ∗ M ∗ N
FLOPs: H ∗ W ∗ K ∗ K ∗ M ∗ N
FC全连接层:
Input: N
Output: M
==>
Params: M ∗ N
FLOPs: M ∗ N
Depthwise conv2d深度卷积:
Input: H ∗ W ∗ M
Output: H ∗ W ∗ M
Filters: K ∗ K
==>
Params: K ∗ K ∗ M
FLOPs: H ∗ W ∗ K ∗ K ∗ M
Pointwise conv2d点卷积:
将标准卷积层中卷积核大小换成1x1即可得到
Params: M ∗ N
FLOPs: H ∗ W ∗ M ∗ N
从上面我们可以得到,使用深度可分离卷积后得到的总计算量为DF*DF*DK*DK + DF*DF*M*N。
将深度可分离卷积的总计算量与标准卷积相比较,可以得到下面式子,

深度可分离卷积的计算量是标准卷积 的 1/N +1/( Dk * Dk)倍。通常情况下,N (输出通道)远大于卷积核尺寸,故1/N +1/( Dk * Dk) 近似等于 1/( Dk * Dk)。
当卷积核的大小为Dk =3 时,深度可分离卷积的计算量约为标准卷积的1/9倍。
2.MobileNet v1网络结构
(1)核心层(深度可分离卷积层)
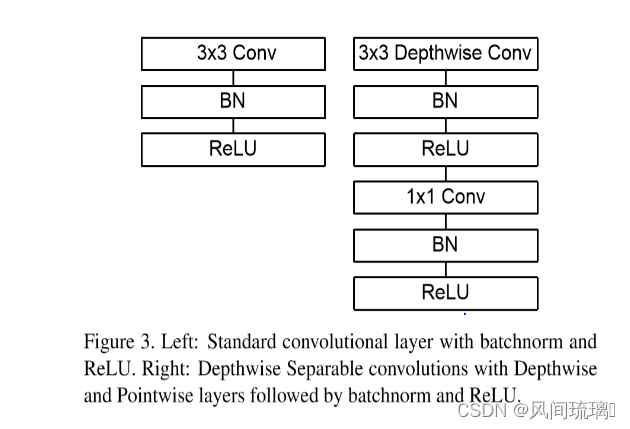
上图左边是标准卷积层,右边是V1的卷积层。V1的卷积层,首先使用3×3的深度卷积提取特征,接着是BN层、ReLU层,这里的第一个ReLU是指的ReLU6,在之后是逐点卷积,BN和ReLU。这也很符合深度可分离卷积,将左边的标准卷积拆分成右边的一个深度卷积和一个逐点卷积。
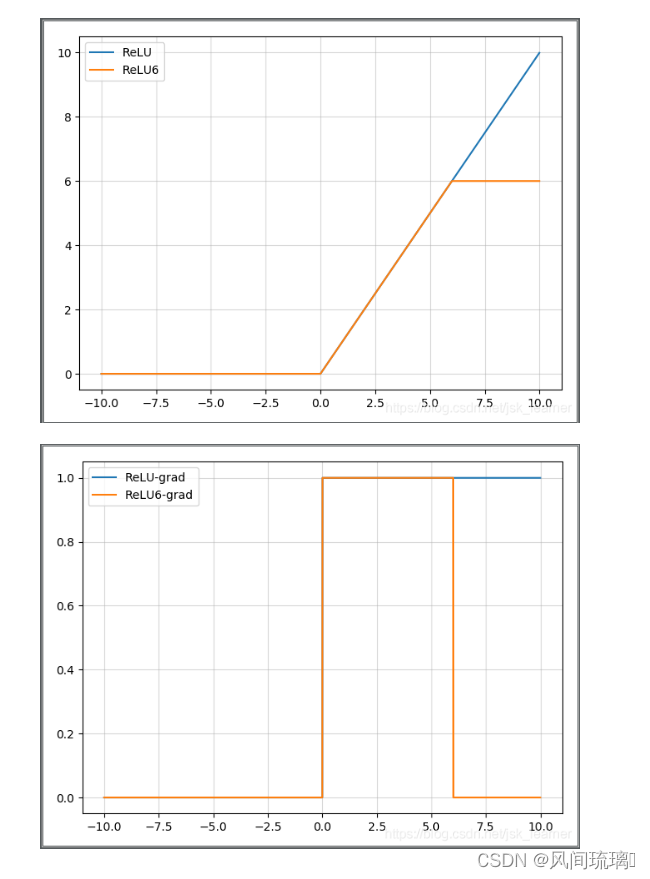
Relu6(抑制其最大值):
公式:当 x > 6时,其导数也为0。

主要是为了在移动端float16的低精度的时候,也能有很好的数值分辨率,如果对ReLu的输出值不加限制,那么输出范围就是0到正无穷,而低精度的float16无法精确描述其数值,带来精度损失。
ReLU和ReLU6图表对比:
(2)宽度因子和分辨率因子
MobileNetV1还使用宽度因子和分辨率因子进一步减小模型参数数量和计算量,当然,在一定程度上会降低模型精确度。
宽度因子Width Multiplier(α):
α ∈ ( 0 , 1 ]作用于通道数量上,通常取1, 0.75, 0.5和0.25
![]()
由上式可得,模型计算量和参数量大约降低
分辨率因子Resolution Multiplier(ρ)
ρ ∈ ( 0 , 1 ] 作用于输入图像上,通常取为224,192,160和128(常隐式表示),作用后模型大小,参数量不变,计算量降低为
![]()
(3)网络结构
MobileNetV1 网络结构如下图所示,其中 Conv 表示普通卷积,Conv dw 表示 DW 卷积操作。
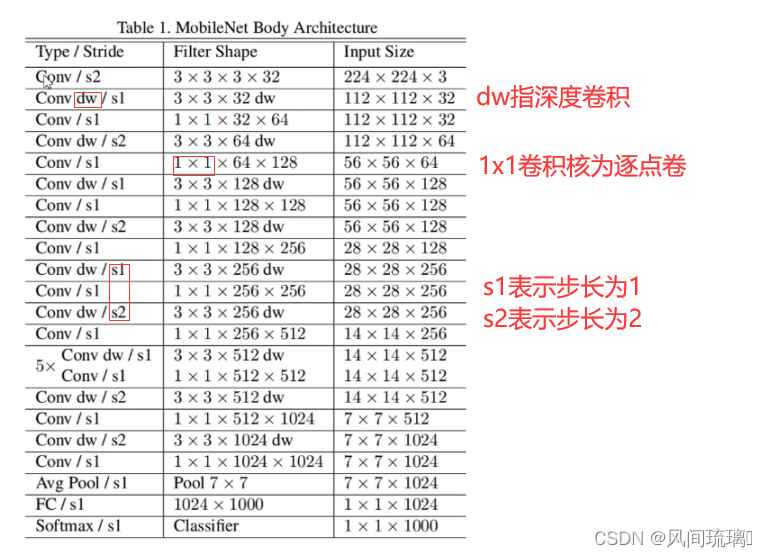
整个MobileNet v1网络除了平均池化层和softmax输出层外,共28层,其中深度卷积层有13层。
第1层为3x3的标准卷积,s2进行下采样。接下来26层为核心层结构(深度可分离卷积层),并且其中的部分深度卷积会利用s2进行下采样。最后采用平均池化层将feature变成1x1,根据预测类别大小全连接层加softmax层输出
除全连接层不使用激活函数,而使用softmax进行分类之外,其他所有层都使用BatchNorm和ReLU。
MobileNet v1网络有一个缺点:DW 卷积核很容易废掉,即卷积核参数大部分为 0。
3.创新点
(1)MobileNetV1提出了深度可分离卷积的概念,替代了标准卷积操作,大大减少了参数数量和计算量。
(2)提出两个超参数宽度因子和分辨率因子,可根据现实情况需求,调整输入输出通道数量和输入图像尺寸,可自由权衡精度与参数数量,计算量。
(3)使用BN加快模型收敛速度,提高模型精度和泛化能力。
二、MobileNet v2
在MobileNet v1的实际训练过程中,深度卷积时卷积核特别容易废掉,即训练完成后卷积核参数是大部分为0。
在 2018 年 googleNet 提出了 v2 版本的 mobileNet,v2认为是Relu函数造成这样的原因:在输入维度是2,3时,输出和输入相比丢失了较多信息;但是在输入维度是15到30时,输出则保留了输入的较多信息。如下图所示,

所以在使用Relu函数时,当输入的维度较低时,会丢失较多信息,因此我们这里可以想到两种思路,一是把Relu激活函数替换成别的,二是通过升维将输入的维度变高。
1.Linear Bottlenecks
从v1可知,深度可分离卷积层的构成:首先是一个3x3的深度卷积,其次是BN、Relu层,接下来是1x1的逐点卷积,最后又是BN和Relu层。
既然是ReLU导致的信息损耗,将ReLU替换成线性激活函数。但是需要注意的是,并不是将所有的Relu激活都换成了线性激活,而是将最后一个ReLU6变成线性激活函数,如下图。变换后的模块称为Linear Bottlenecks。
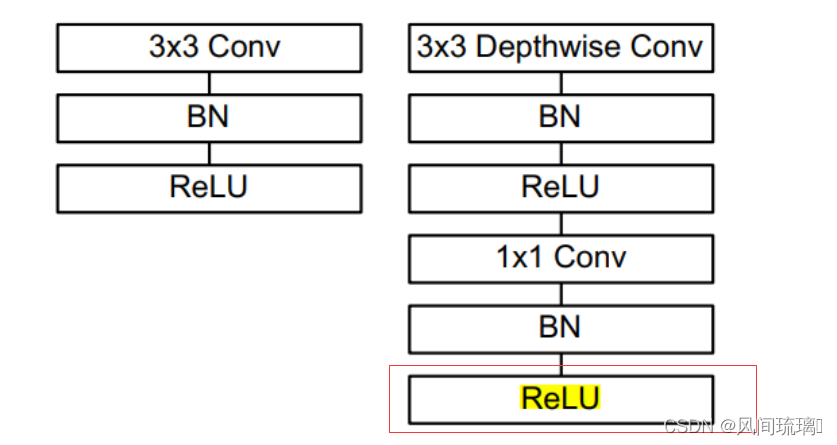
线性瓶颈(Linear Bottlenecks) 在高维空间上,如 ReLU 这种激活函数能有效增加特征的非线性表达,但是仅限于高维空间中,如果降低维度,再使用 ReLU 则会破坏特征。
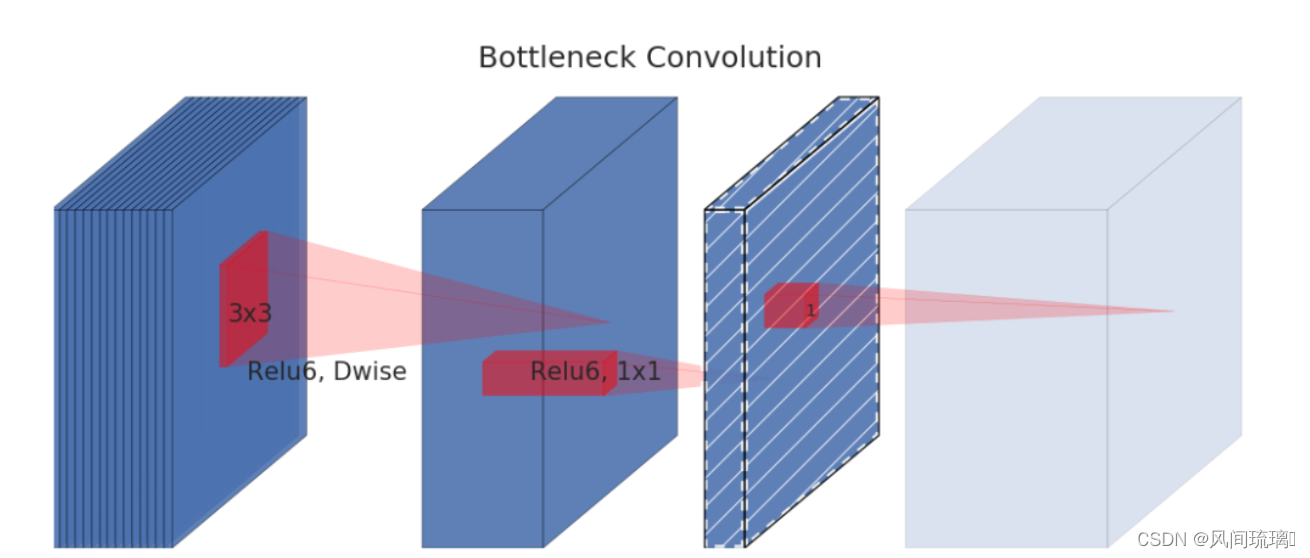
因此在 mobileNets V2 中提出了 Linear Bottlenecks 结构,在执行了降维的卷积层后面,不再加入类似 ReLU 等的激活函数进行非线性转化,这样做的目的是尽可能的不造成信息的丢失。
2.Inverted Residuals
Inverted Residuals(倒残差结构),通过下图可以看出,左侧为ResNet中的残差结构,其结构为1x1卷积降维--->3x3卷积--->1x1卷积升维;右侧为MobileNetV2中的倒残差结构,其结构为1x1卷积升维--->3x3DW卷积--->1x1卷积降维。V2先使用1x1卷积进行升维的原因是高维信息通过ReLU激活函数后丢失的信息更少。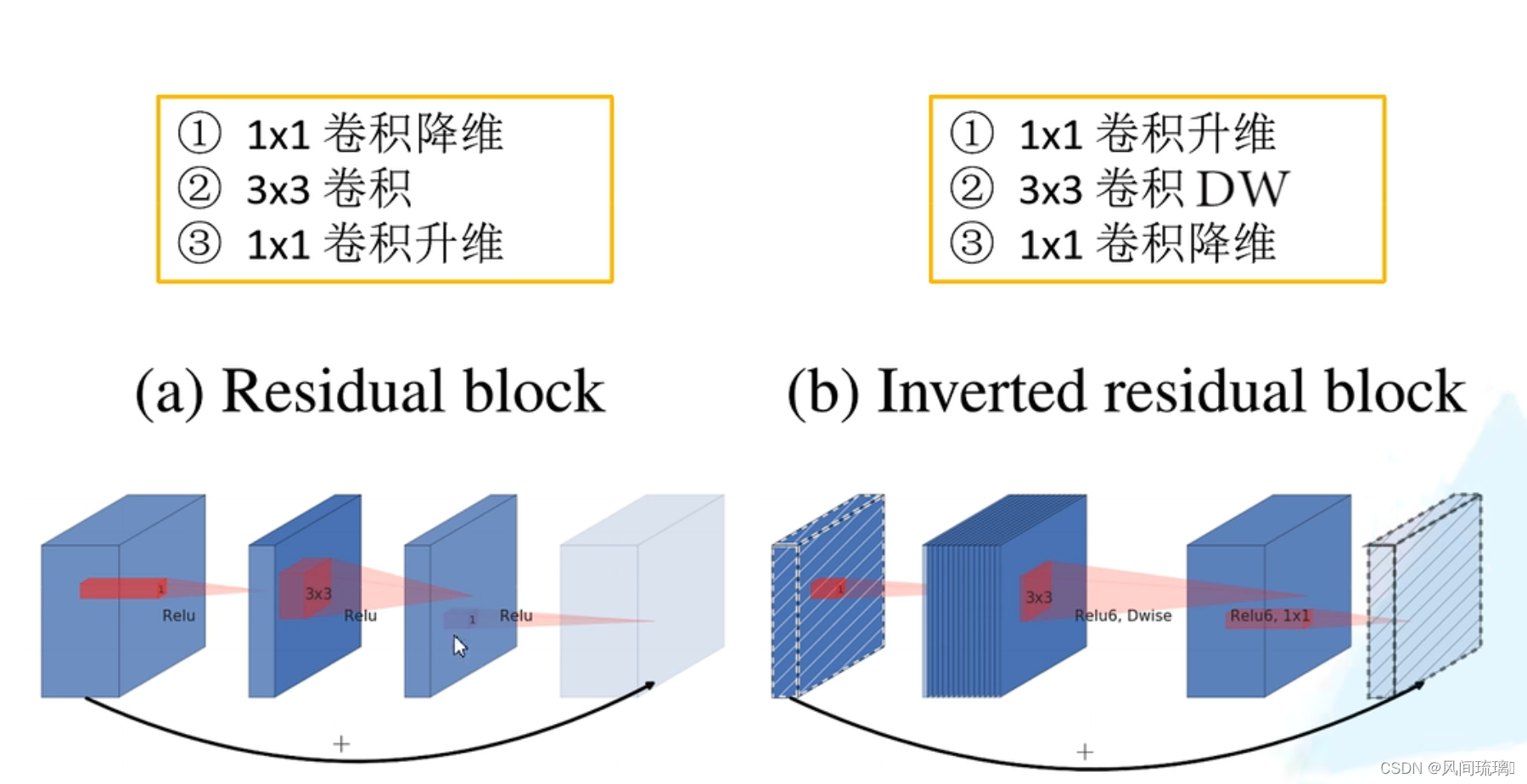
倒残差结构(Inverted residual) 在 ResNet 为了构建更深的网络,提出了 ResNet 的另一种形式,一个 bottleneck 由一个 1 x 1 卷积(降维),3 x 3 卷积和 1 x 1 卷积(升维)构成。
在 MobileNet 中,DW 卷积的层数是输入通道数,本身就比较少,如果跟残差网络中 bottleneck 一样,先压缩,后卷积提取,可得到特征就太少了。采取了一种逆向的方法—先升维,卷积,再降维。
ResNet网络:残差结构是先用1*1卷积降维,3x3卷积,1x1卷积升维,两头大中间小。
MobileNet v2:残差结构是先用1*1卷积升维,dw卷积,1x1卷积降维,两头小中间大。
所以MobileNet v1和v2的block如下:
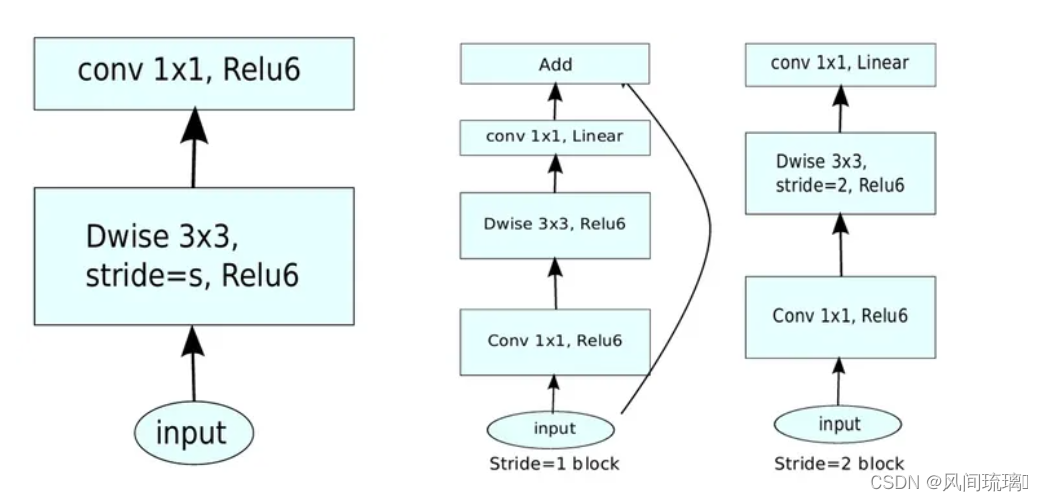
左边是v1的block,没有Shortcut并且带最后的ReLU6。
右边是v2的加入了1×1升维,引入Shortcut并且将最后的ReLU改为Linear。步长为1时,先进行1×1卷积升维,再进行深度卷积提取特征,再通过Linear的逐点卷积降维。将input与output相加,形成残差结构。
步长为2时,因为input与output的尺寸不符,因此不添加shortcut结构,其余均一致。当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut链接。
3.MobileNet v2网络结构
MobileNet v2网络结构如下图所示,其中 conv2d表示普通卷积,bottleneck表示右边的block。
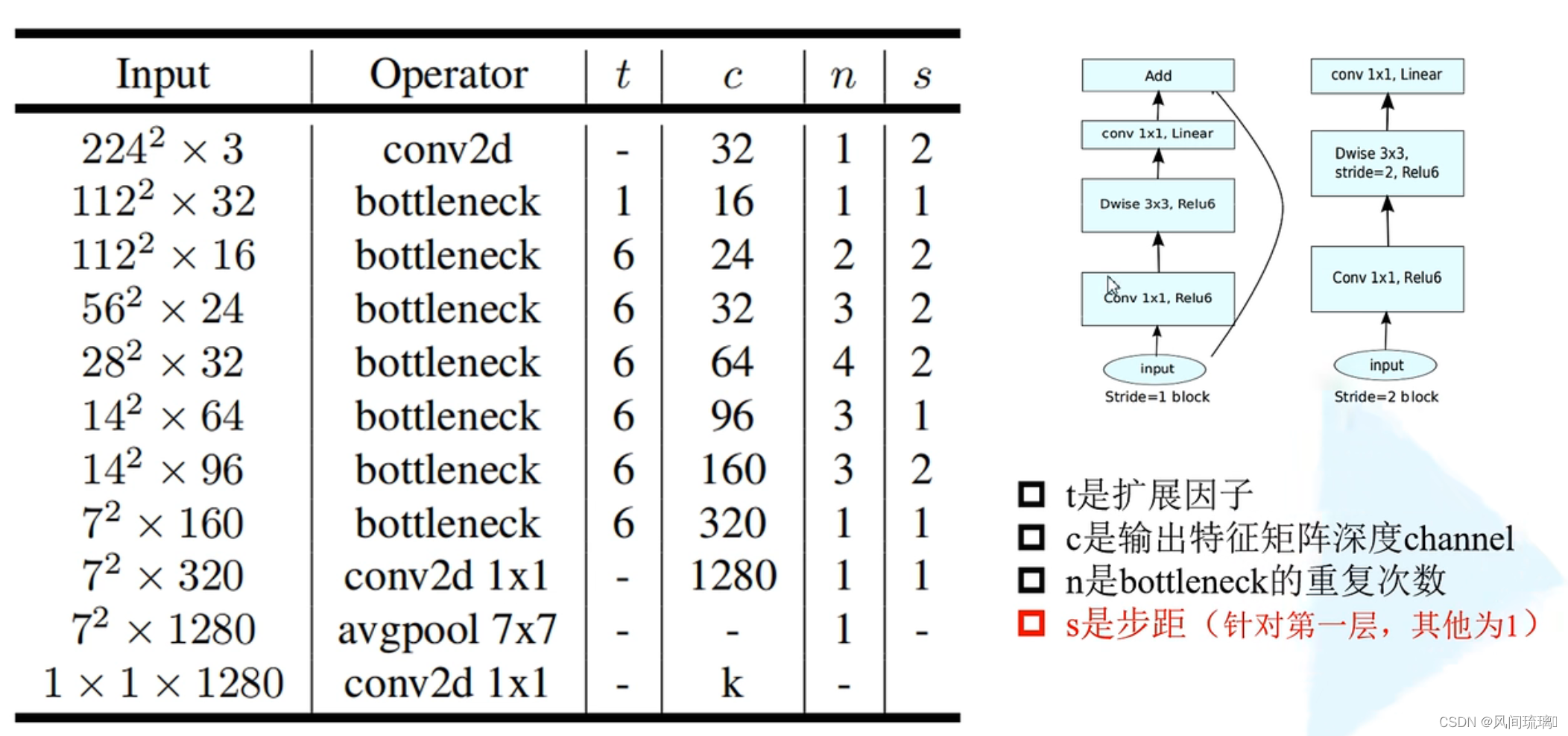
上图是MobileNet v2网络的结构表,其中t代表的是扩展因子(倒残差结构中第一个1x1卷积的扩展因子),c代表输出特征矩阵的channel,n代表倒残差结构重复的次数,s代表步距(注意:当有多个bottleneck, s只针对第一个bottleneck这里的步距只是针对重复n次的第一层倒残差结构,后面的都默认为1)。
三、MobileNet v3
MobileNetV3,是谷歌在2019年3月21日提出的网络架构。首先,引入眼帘的是这篇文章的标题"Searching for MobileNetV3",“searching”一词就把V3的论文的核心观点展示了出来——用神经结构搜索(NAS)来完成V3参数的设计。
想较于之前的网络,不管是VGG、ResNet、MobileNetV1、MobileNetV2,网络结构都是我们自己手动去设计的,如网络的层数、卷积核大小、步长等等参数都需要自己设置。而NAS通过计算机来实现最优的参数设定,通过比较不同参数的网络模型效果,从而选择最优的参数设置。但是这也对计算机的性能要求也特别的高。
主要特点:
①论文推出两个版本:Large 和 Small,分别适用于不同的场景。
②使用NetAdapt算法获得卷积核和通道的最佳数量。
③继承V1的深度可分离卷积。
④继承V2的具有线性瓶颈的残差结构。
⑤引入SE通道注意力结构。
⑥使用了一种新的激活函数h-swish(x)代替Relu6,h的意思表示hard。
⑦使用了Relu6(x + 3)/6来近似SE模块中的sigmoid。
⑧修改了MobileNetV2后端输出head。
1.SE模块
引入SE模块,主要为了利用结合特征通道的关系来加强网络的学习能力。它首先是将特征图的每个通道都进行平均池化,然后进行两个全连接层得到一个输出结果,这个结果会和原始的特征图进行相乘,得到新的特征图。
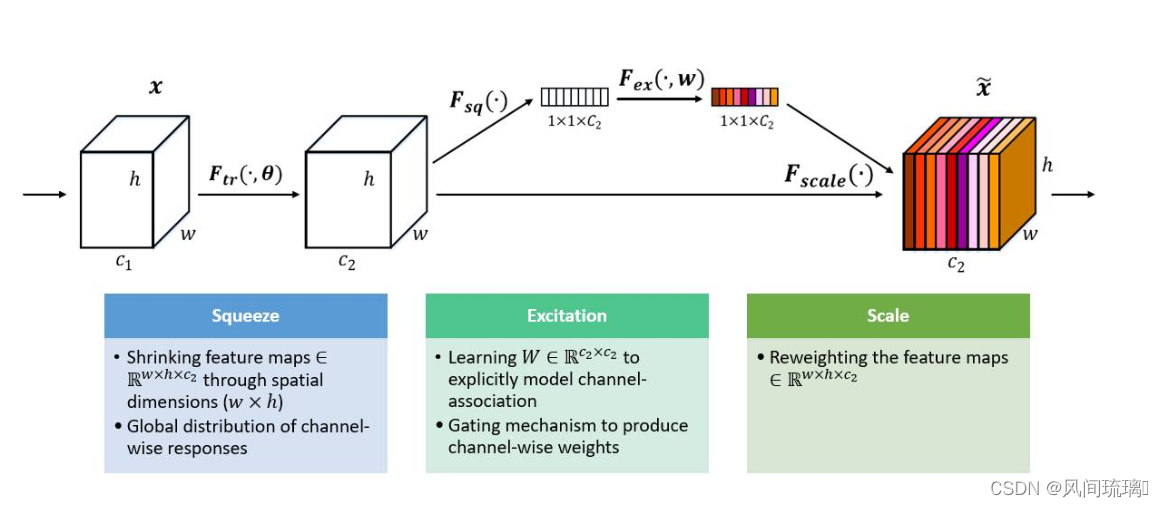
网络的左半部分是一个传统的卷积变换,忽略掉这一部分并不会影响我们的SE模块的理解。直接看一下后半部分,其中 U 是一个 W×H×C 的Feature Map, (W,H) 是图像的尺寸, C是图像的通道数。
首先是Fsq(⋅) (Squeeze操作),顺着空间维度来进行特征压缩,将每个二维的特征通道变成一个 1×1×C 的特征向量,特征向量的值由U确定。这个实数某种程度上具有全局的感受野,并且输出的维度和输入的特征通道数相匹配。它表征着在特征通道上响应的全局分布,而且使得靠近输入的层也可以获得全局的感受野,这一点在很多任务中都是非常有用的。
Squeeze部分的作用是获得Feature Map U的每个通道的全局信息嵌入(特征向量)。在SE block中,这一步通过VGG中引入的Global Average Pooling(GAP)实现的,即通过求每个通道C Feature Map的平均值。
其次是 Excitation 操作,它是一个类似于循环神经网络中门的机制。通过参数 w 来为每个特征通道生成权重,其中参数 w 被学习用来显式地建模特征通道间的相关性。
最后是一个 Reweight 的操作,将 Excitation 的输出的权重看做是经过特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。
以在Mobilenetv3中的应用为例进行理解,

首先下图左上角表示为四个通道的特质图,经平均池化后得到左下角的图;再次经过两次全连接层后,转化成了右下角的图,最后用右下角的0.5、0.3,0.1,0.2(Conv1每个channel的权值系数)分别乘原始的特质图,则得到最终的右上角的图。
2.耗时层结构
在MobileNet v3中,作者重新设计耗时层结构,首先减少第一个卷积层卷积核个数,从原来的32个变为16个,使用ReLU或者swich,其准确率几乎相同,并且节省了2ms和1000万madds。
其次,精简了Last Stage。Original Last Stage是通过NAS算出来的,但最后实际测试发现Efficient Last Stage结构可以在不损失精度情况下去除一些多余的层,如下图所示,
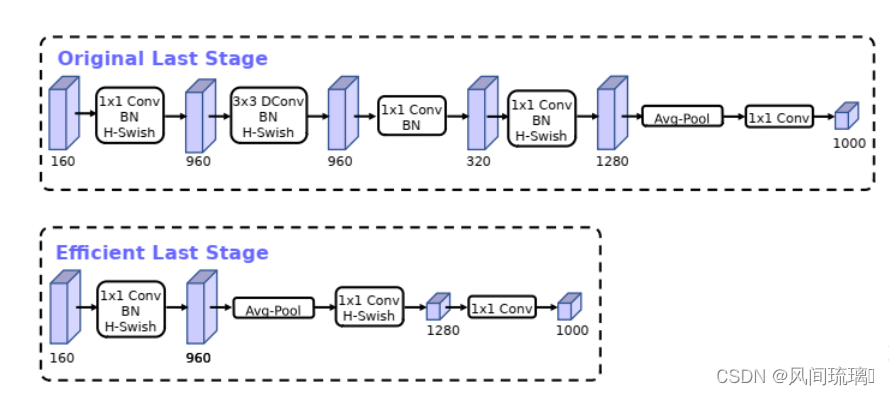
移除之前的瓶颈层连接,进一步降低网络参数。可以有效降低11%的推理耗时,而性能几乎没有损失。
3.ReLu6和h-swish激活函数
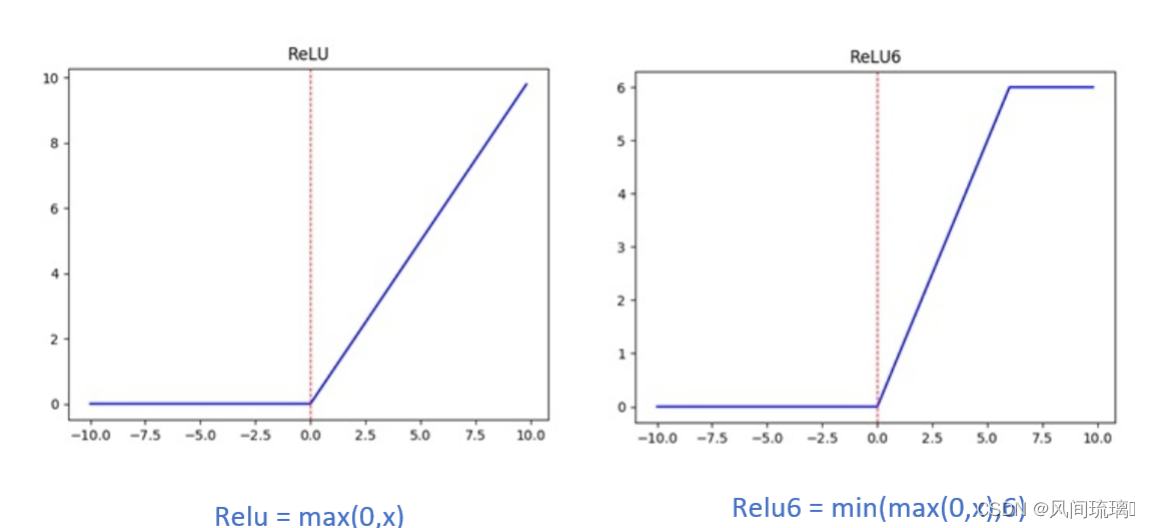
在v1和v2版本中用到的Relu激活函数是Relu6激活函数,ReLu6激活函数如下图所示,在ReLU的基础上加了最大值6进行限制。
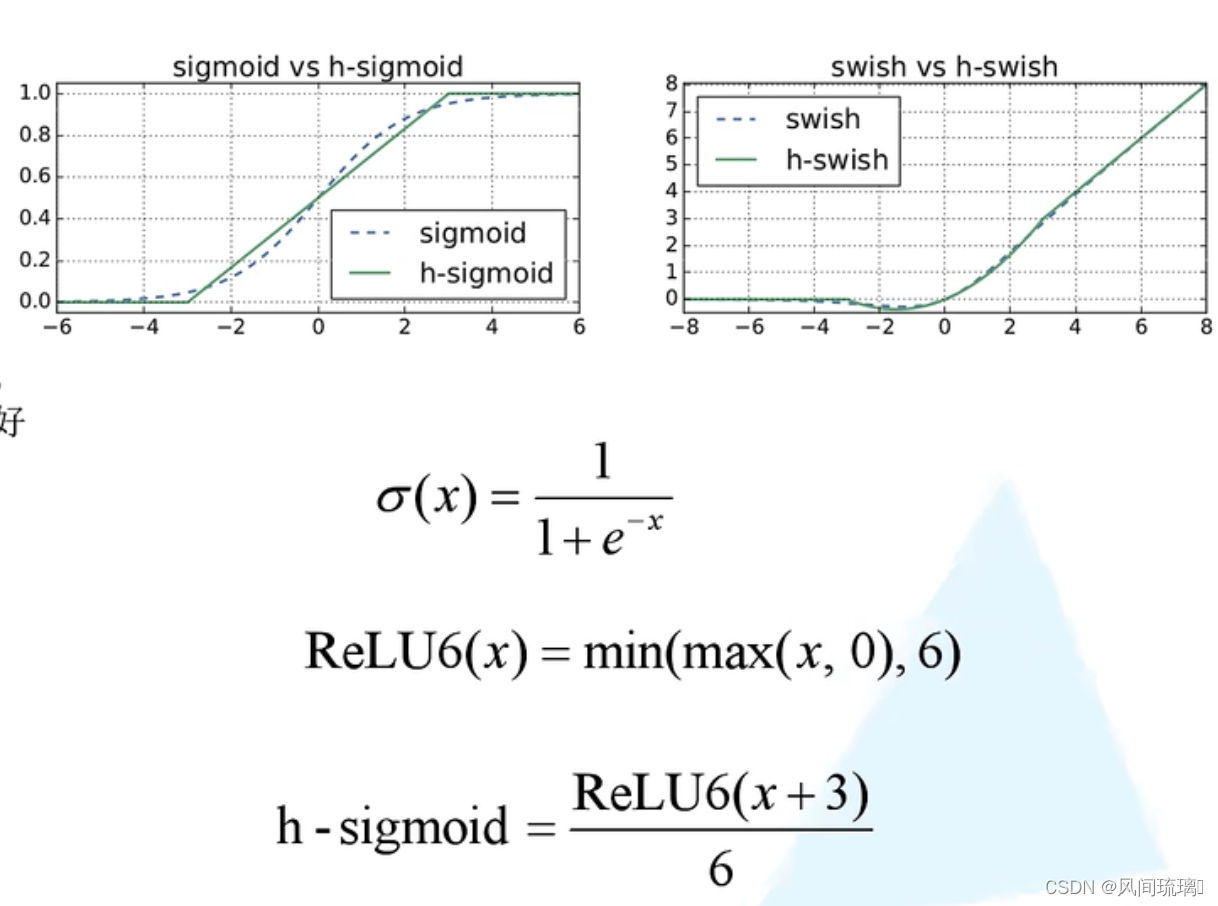
v3版本使用的激活函数为h-swish,其图像和表达式如下图所示:图中包括了一些其他相关的一些函数表达式及图像。
采用h-swish(hardswish),计算速度相对较快,有利于量化 。
h-swish是基于swish的改进,swish最早是在谷歌大脑2017的论文Searching for Activation functions所提出 。

swish论文的作者认为,Swish具备无上界有下界、平滑、非单调的特性。并且Swish在深层模型上的效果优于ReLU。仅仅使用Swish单元替换ReLU就能把MobileNet,NASNetA在 ImageNet上的top-1分类准确率提高0.9%,Inception-ResNet-v的分类准确率提高0.6%。
v3也利用swish当作为ReLU的替代时,它可以显著提高神经网络的精度。但是呢,作者认为这种非线性激活函数虽然提高了精度,但在嵌入式环境中,是有不少的成本的。原因就是在移动设备上计算sigmoid函数是非常明智的选择。所以提出了h-swish。
可以用一个近似函数来逼近swish,作者选择的是基于ReLU6,作者认为几乎所有的软件和硬件框架上都可以使用ReLU6的优化实现。其次,它能在特定模式下消除了由于近似sigmoid的不同实现而带来的潜在的数值精度损失。
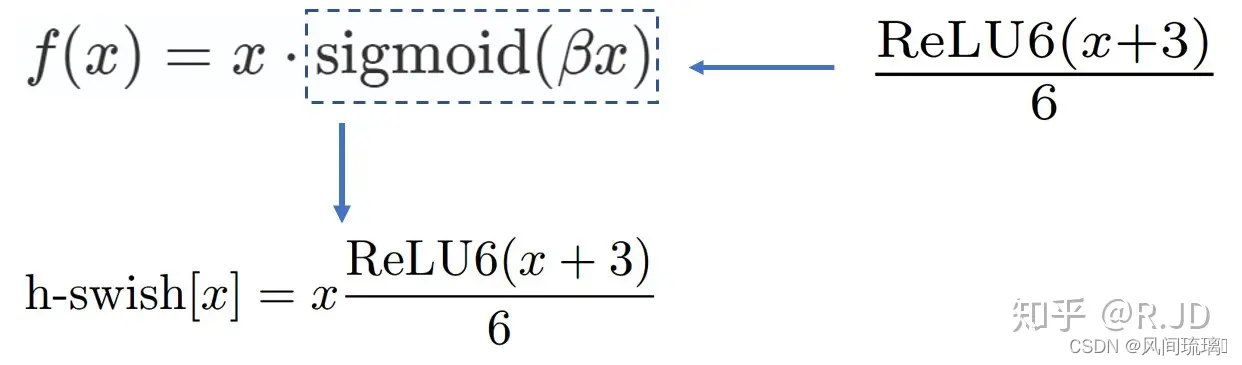
作者认为随着网络的深入,应用非线性激活函数的成本会降低,能够更好的减少参数量。作者发现swish的大多数好处都是通过在更深的层中使用它们实现的。因此,在V3的架构中,只在模型的后半部分使用h-swish(HS)。
4.网络总体结构
MobileNet v3特有的block结构如下,
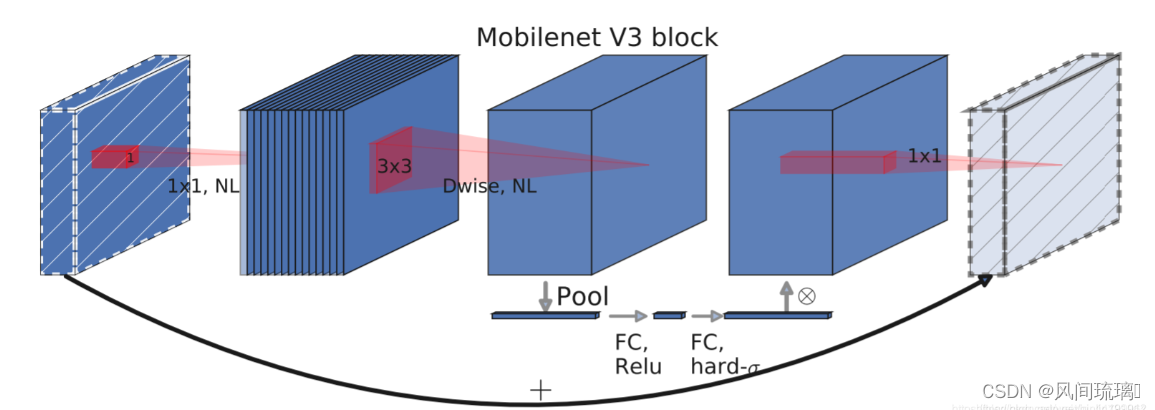
当stride=1且输入特征矩阵与输出特征矩阵shape相同时才有shortcut链接。
作者针对不同需求,通过NAS得到两种结构,一个是MobilenetV3-Large,结构如下图:
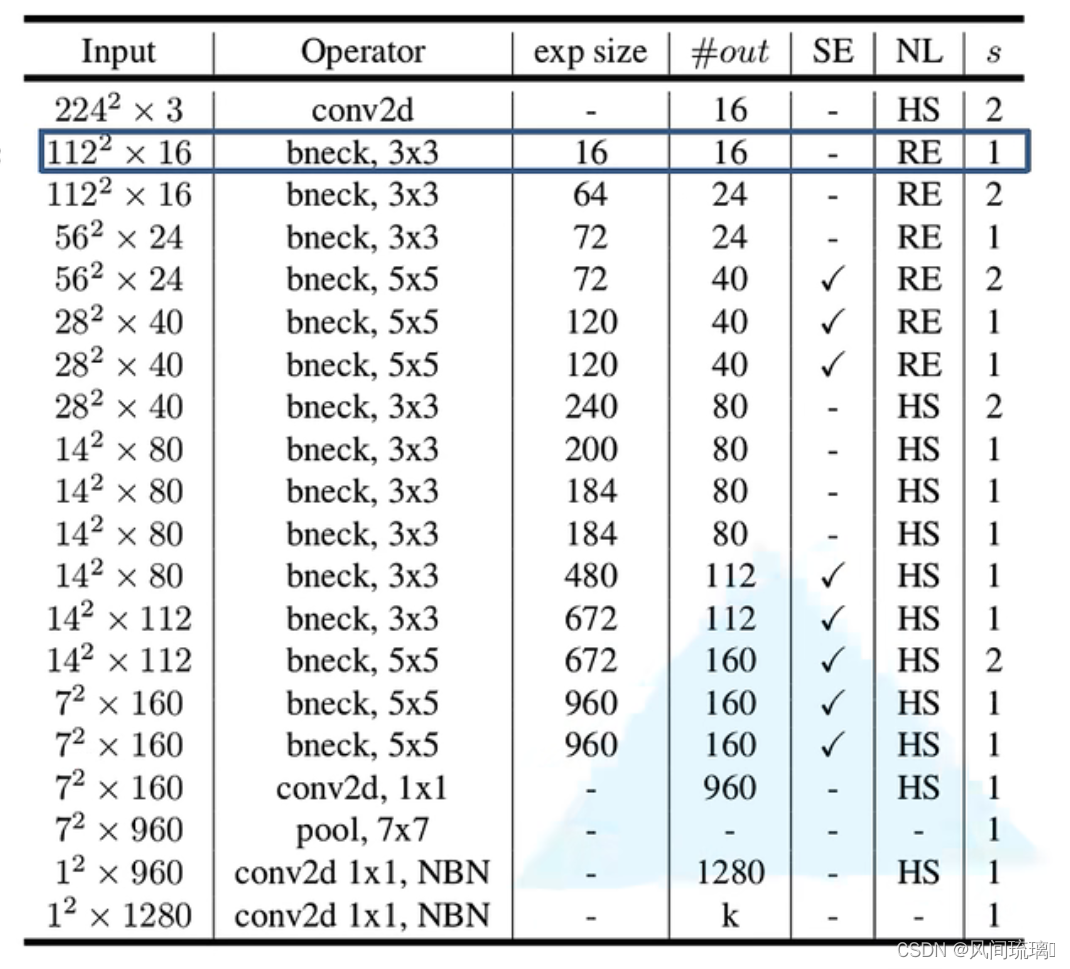
①Input表示输入尺寸
②Operator中的NBN表示不使用BN,最后的conv2d 1x1相当于全连接层的作用
③exp size表示bottleneck中的第一层1x1卷积升维,维度升到多少(第一个bottleneck没有1x1卷积升维操作)
④out表示bottleneck输出的channel个数
⑤SE表示是否使用SE模块⑥NL表示使用何种激活函数,HS表示HardSwish,RE表示ReLu
⑦s表示步长(s=2,长宽变为原来一半)
四、网络实现
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。

![[unity]保存文件的路径设置](https://img-blog.csdnimg.cn/02fc94df4ae44579b0051ad8b21e4bca.png)