文章目录
- 一、基础知识点
- (1)逻辑回归表达式
- (2)sigmoid函数的导数
- 损失函数(Cross-entropy, 交叉熵损失函数)
- 交叉熵求导
- 准确率计算
- 评估指标
- 二、导入库和数据集
- 导入库
- 读取数据
- 三、分析与训练
- 四、模型评价
- ROC曲线
- KS值
- 再做特征筛选
- 生成报告
- 五、行为评分卡模型表现
- 总结
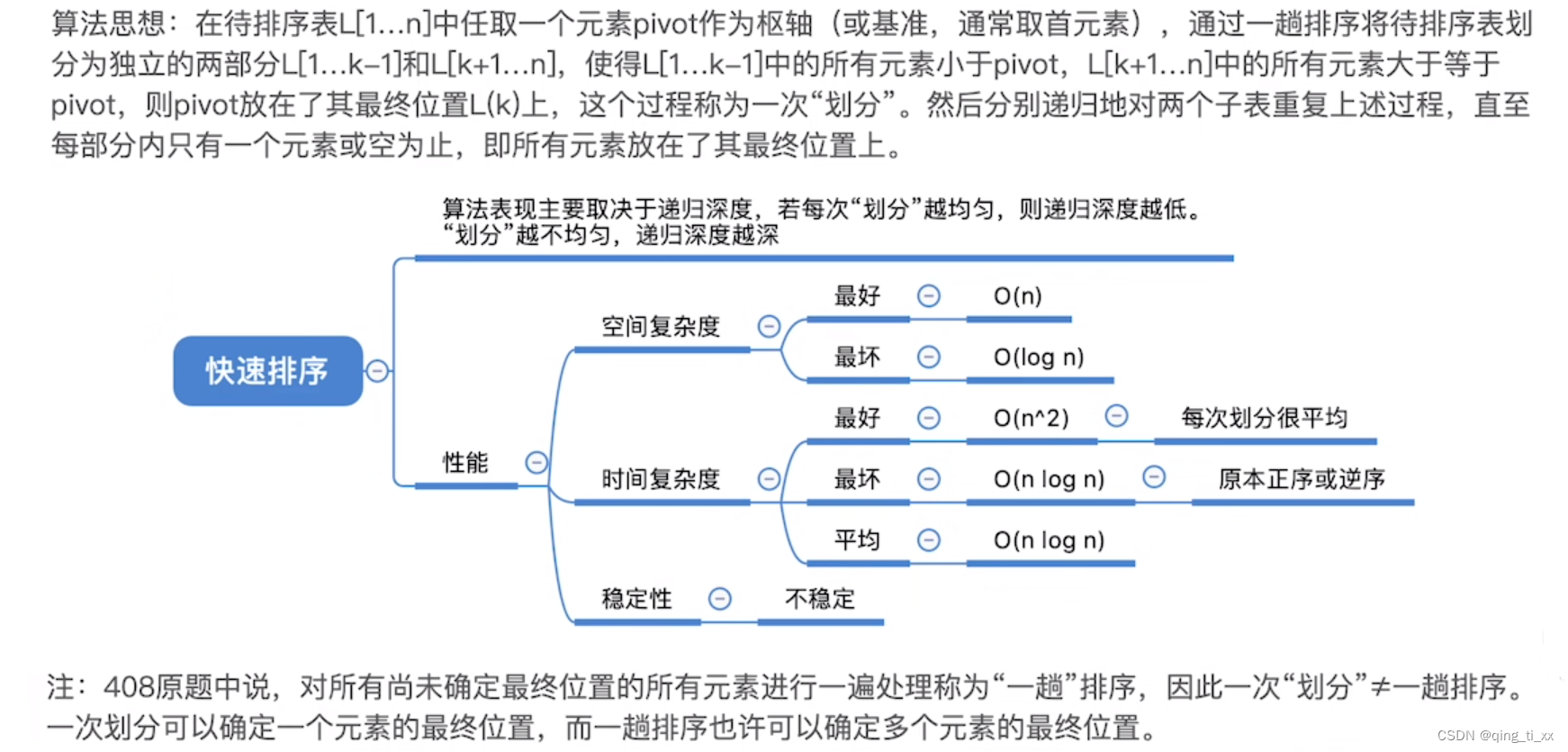
一、基础知识点
(1)逻辑回归表达式

in:
import numpy as np
import matplotlib.pyplot as plt
import tqdm
import os
file = 'testSet.txt'
if os.path.exists(file):
data = np.loadtxt(file)
features = data[:, :2]
labels = data[:, -1]
print(features.shape, labels.shape)
out:

in:
print('特征的维度: {0}'.format(features.shape[1]))
print('总共有{0}个类别'.format(len(np.unique(labels))))
out:
特征的维度: 2
总共有2个类别
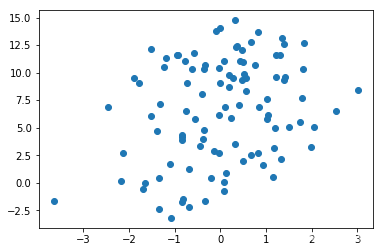
figure = plt.figure()
plt.scatter([x[0] for x in features], [x[1] for x in features])
plt.show()
(2)sigmoid函数的导数
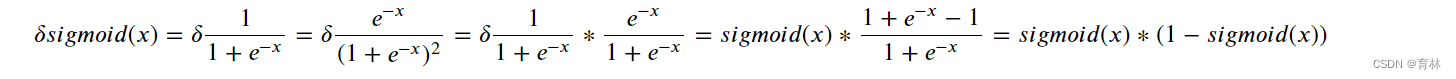
损失函数(Cross-entropy, 交叉熵损失函数)
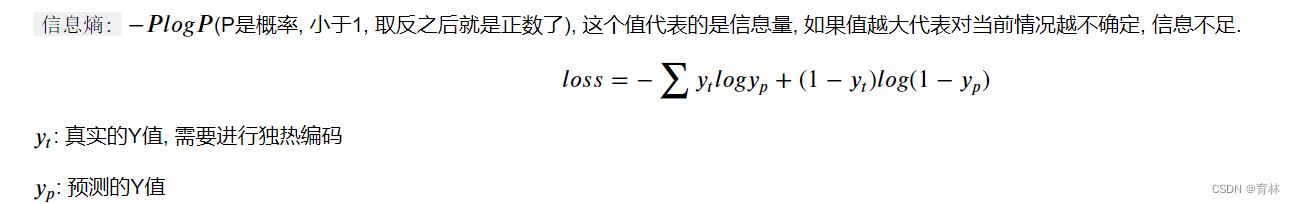
def loss(Y_t, Y_p):
'''
算交叉熵损失函数
Y_t: 独热编码之后的真实值向量
Y_p: 预测的值向量
'''
trans = np.zeros(shape=Y_t.shape)
for sample_idx in range(len(trans)):
# print(trans[sample_idx], [Y_p[sample_idx], 1.0 - Y_p[sample_idx]])
# 避免出现0
trans[sample_idx] = [Y_p[0][sample_idx] , 1.0 - Y_p[0][sample_idx] + 1e-5]
log_y_p = np.log(trans)
return -np.sum(np.multiply(Y_t, log_y_p))
Y_t = np.array([[0, 1], [1, 0]])
Y_p = np.array([[0.8, 1]])
loss(Y_t=Y_t, Y_p=Y_p)
交叉熵求导
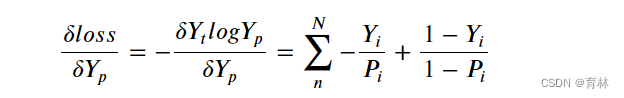
def delta_cross_entropy(Y_t, Y_p):
trans = np.zeros(shape=Y_t.shape)
for sample_idx in range(len(trans)):
trans[sample_idx] = [Y_p[0][sample_idx] + 1e-8, 1.0 - Y_p[0][sample_idx] + 1e-8]
Y_t[Y_t == 0] += 1e-8
error = Y_t * (1 / trans)
error[:, 0] = -error[:, 0]
return np.sum(error, axis=1, keepdims=True)
Y_t = np.array([[0, 1], [1, 0]], dtype=np.float)
Y_p = np.array([[0.8, 1]])
delta_cross_entropy(Y_t=Y_t, Y_p=Y_p)
准确率计算
def accuracy(Y_p, Y_t):
Y_p[Y_p >= 0.5] = 1
Y_p[Y_p < 0.5] = 0
predict = np.sum(Y_p == Y_t)
return predict / len(Y_t)
评估指标

def recall(Y_p, Y_t):
return np.sum(np.argmax(Y_p) == np.argmax(Y_t)) / np.sum(Y_p == 1)
二、导入库和数据集
导入库
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
import numpy as np
import random
import math
读取数据
data = pd.read_csv('Acard.txt')
data.head()


三、分析与训练
#这是我们全部的变量,info结尾的是自己做的无监督系统输出的个人表现,score结尾的是收费的外部征信数据
feature_lst = ['person_info','finance_info','credit_info','act_info','td_score','jxl_score','mj_score','rh_score']
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1)
lr_model.fit(x,y)
四、模型评价
ROC曲线
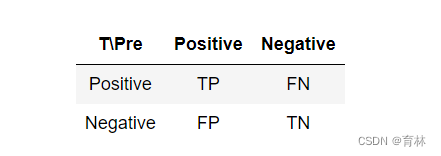
描绘的是不同的截断点时,并以FPR和TPR为横纵坐标轴,描述随着截断点的变小,TPR随着FPR的变化。
纵轴:TPR=正例分对的概率 = TP/(TP+FN),其实就是查全率
横轴:FPR=负例分错的概率 = FP/(FP+TN)
作图步骤:
根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)-----这就是截断点依次选取的顺序 按顺序选取截断点,并计算TPR和FPR—也可以只选取n个截断点,分别在1/n,2/n,3/n等位置 连接所有的点(TPR,FPR)即为ROC图
在这里插入代码片
KS值
作图步骤:
根据学习器的预测结果(注意,是正例的概率值,非0/1变量)对样本进行排序(从大到小)-----这就是截断点依次选取的顺序
按顺序选取截断点,并计算TPR和FPR —也可以只选取n个截断点,分别在1/n,2/n,3/n等位置
横轴为样本的占比百分比(最大100%),纵轴分别为TPR和FPR,可以得到KS曲线
TPR和FPR曲线分隔最开的位置就是最好的”截断点“,最大间隔距离就是KS值,通常>0.2即可认为模型有比较好偶的预测准确性。
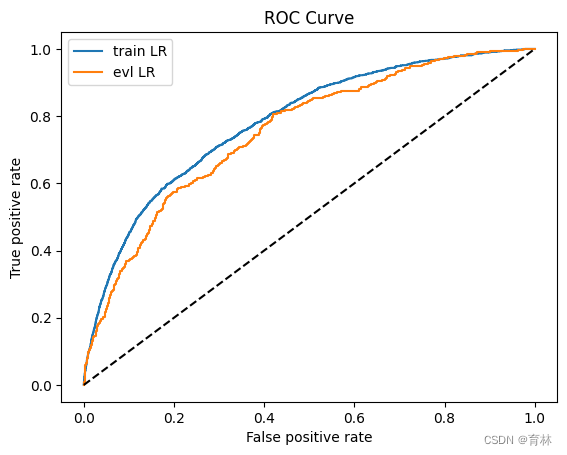
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
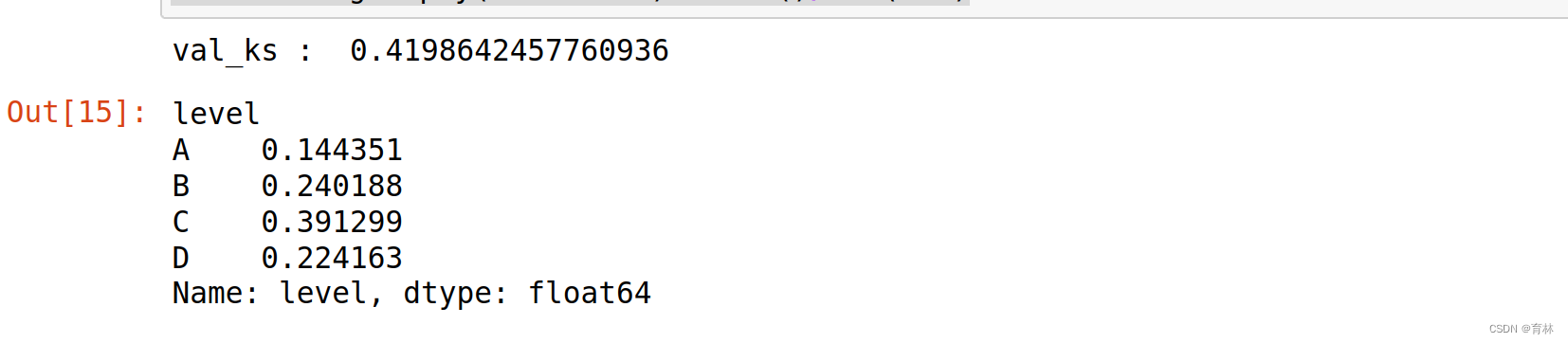
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
train_ks : 0.4151676259891534
val_ks : 0.3856283523530577
再做特征筛选
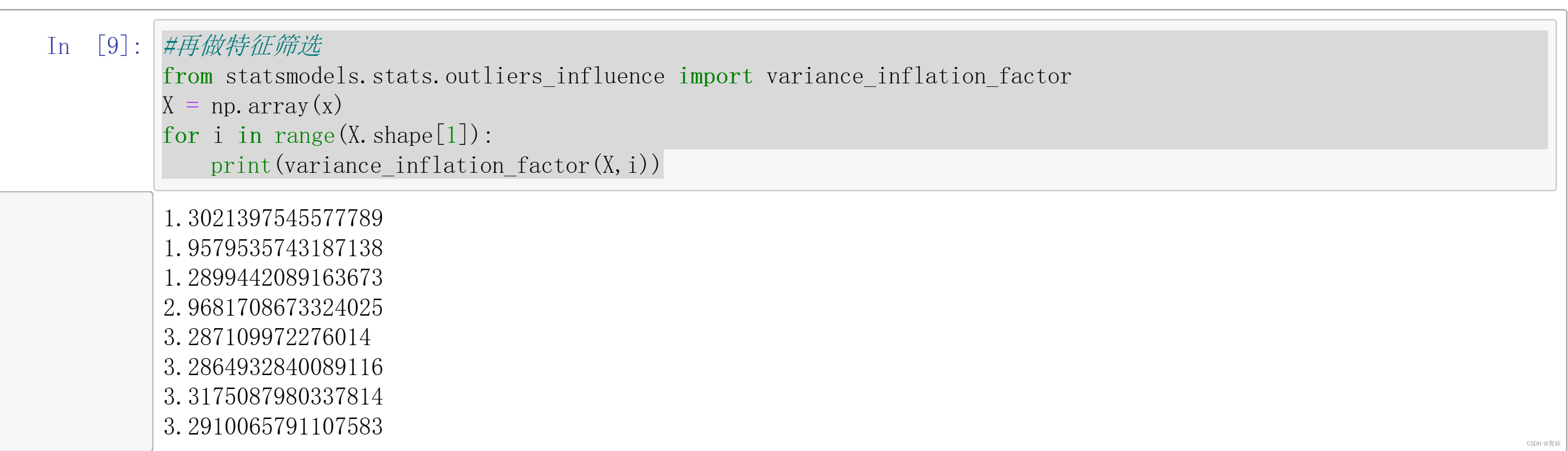
#再做特征筛选
from statsmodels.stats.outliers_influence import variance_inflation_factor
X = np.array(x)
for i in range(X.shape[1]):
print(variance_inflation_factor(X,i))
import lightgbm as lgb
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y = train_test_split(x,y,random_state=0,test_size=0.2)
def lgb_test(train_x,train_y,test_x,test_y):
clf =lgb.LGBMClassifier(boosting_type = 'gbdt',
objective = 'binary',
metric = 'auc',
learning_rate = 0.1,
n_estimators = 24,
max_depth = 5,
num_leaves = 20,
max_bin = 45,
min_data_in_leaf = 6,
bagging_fraction = 0.6,
bagging_freq = 0,
feature_fraction = 0.8,
)
clf.fit(train_x,train_y,eval_set = [(train_x,train_y),(test_x,test_y)],eval_metric = 'auc')
return clf,clf.best_score_['valid_1']['auc'],
lgb_model , lgb_auc = lgb_test(train_x,train_y,test_x,test_y)
feature_importance = pd.DataFrame({'name':lgb_model.booster_.feature_name(),
'importance':lgb_model.feature_importances_}).sort_values(by=['importance'],ascending=False)
feature_importance

feature_lst = ['person_info','finance_info','credit_info','act_info']
x = train[feature_lst]
y = train['bad_ind']
val_x = val[feature_lst]
val_y = val['bad_ind']
lr_model = LogisticRegression(C=0.1,class_weight='balanced')
lr_model.fit(x,y)
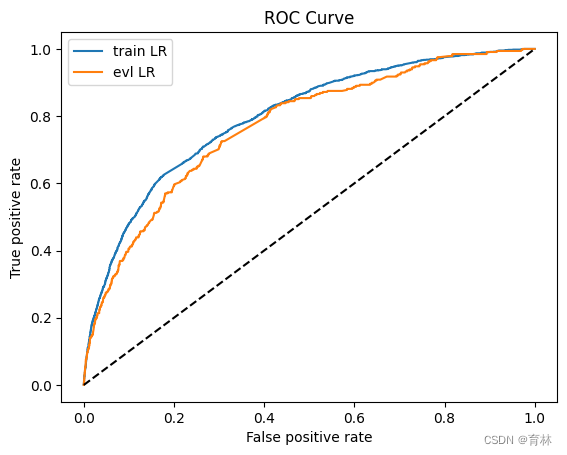
y_pred = lr_model.predict_proba(x)[:,1]
fpr_lr_train,tpr_lr_train,_ = roc_curve(y,y_pred)
train_ks = abs(fpr_lr_train - tpr_lr_train).max()
print('train_ks : ',train_ks)
y_pred = lr_model.predict_proba(val_x)[:,1]
fpr_lr,tpr_lr,_ = roc_curve(val_y,y_pred)
val_ks = abs(fpr_lr - tpr_lr).max()
print('val_ks : ',val_ks)
from matplotlib import pyplot as plt
plt.plot(fpr_lr_train,tpr_lr_train,label = 'train LR')
plt.plot(fpr_lr,tpr_lr,label = 'evl LR')
plt.plot([0,1],[0,1],'k--')
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC Curve')
plt.legend(loc = 'best')
plt.show()
# 系数
print('变量名单:',feature_lst)
print('系数:',lr_model.coef_)
print('截距:',lr_model.intercept_)

生成报告
#生成报告
model = lr_model
row_num, col_num = 0, 0
bins = 20
Y_predict = [s[1] for s in model.predict_proba(val_x)]
Y = val_y
nrows = Y.shape[0]
lis = [(Y_predict[i], Y[i]) for i in range(nrows)]
ks_lis = sorted(lis, key=lambda x: x[0], reverse=True)
bin_num = int(nrows/bins+1)
bad = sum([1 for (p, y) in ks_lis if y > 0.5])
good = sum([1 for (p, y) in ks_lis if y <= 0.5])
bad_cnt, good_cnt = 0, 0
KS = []
BAD = []
GOOD = []
BAD_CNT = []
GOOD_CNT = []
BAD_PCTG = []
BADRATE = []
dct_report = {}
for j in range(bins):
ds = ks_lis[j*bin_num: min((j+1)*bin_num, nrows)]
bad1 = sum([1 for (p, y) in ds if y > 0.5])
good1 = sum([1 for (p, y) in ds if y <= 0.5])
bad_cnt += bad1
good_cnt += good1
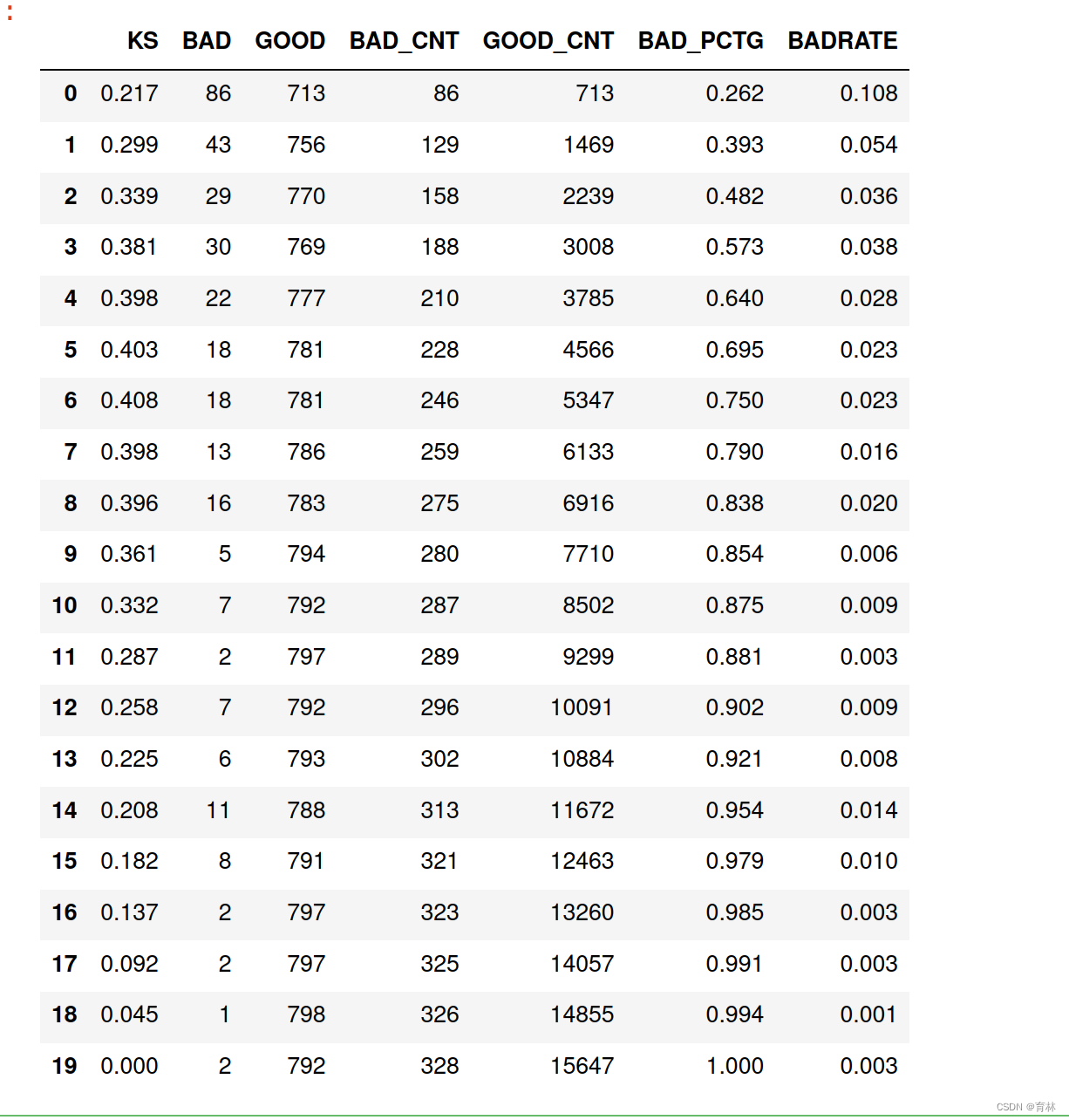
bad_pctg = round(bad_cnt/sum(val_y),3)
badrate = round(bad1/(bad1+good1),3)
ks = round(math.fabs((bad_cnt / bad) - (good_cnt / good)),3)
KS.append(ks)
BAD.append(bad1)
GOOD.append(good1)
BAD_CNT.append(bad_cnt)
GOOD_CNT.append(good_cnt)
BAD_PCTG.append(bad_pctg)
BADRATE.append(badrate)
dct_report['KS'] = KS
dct_report['BAD'] = BAD
dct_report['GOOD'] = GOOD
dct_report['BAD_CNT'] = BAD_CNT
dct_report['GOOD_CNT'] = GOOD_CNT
dct_report['BAD_PCTG'] = BAD_PCTG
dct_report['BADRATE'] = BADRATE
val_repot = pd.DataFrame(dct_report)
val_repot
五、行为评分卡模型表现
from pyecharts.charts import *
from pyecharts import options as opts
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
np.set_printoptions(suppress=True)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
line = (
Line()
.add_xaxis(list(val_repot.index))
.add_yaxis(
"分组坏人占比",
list(val_repot.BADRATE),
yaxis_index=0,
color="red",
)
.set_global_opts(
title_opts=opts.TitleOpts(title="行为评分卡模型表现"),
)
.extend_axis(
yaxis=opts.AxisOpts(
name="累计坏人占比",
type_="value",
min_=0,
max_=0.5,
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="red")
),
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
.add_xaxis(list(val_repot.index))
.add_yaxis(
"KS",
list(val_repot['KS']),
yaxis_index=1,
color="blue",
label_opts=opts.LabelOpts(is_show=False),
)
)
line.render_notebook()

from pyecharts.charts import *
from pyecharts import options as opts
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
np.set_printoptions(suppress=True)
pd.set_option('display.unicode.ambiguous_as_wide', True)
pd.set_option('display.unicode.east_asian_width', True)
line = (
Line()
.add_xaxis(list(val_repot.index))
.add_yaxis(
"分组坏人占比",
list(val_repot.BADRATE),
yaxis_index=0,
color="red",
)
.set_global_opts(
title_opts=opts.TitleOpts(title="行为评分卡模型表现"),
)
.extend_axis(
yaxis=opts.AxisOpts(
name="累计坏人占比",
type_="value",
min_=0,
max_=0.5,
position="right",
axisline_opts=opts.AxisLineOpts(
linestyle_opts=opts.LineStyleOpts(color="red")
),
axislabel_opts=opts.LabelOpts(formatter="{value}"),
)
)
.add_xaxis(list(val_repot.index))
.add_yaxis(
"KS",
list(val_repot['KS']),
yaxis_index=1,
color="blue",
label_opts=opts.LabelOpts(is_show=False),
)
)
line.render_notebook()
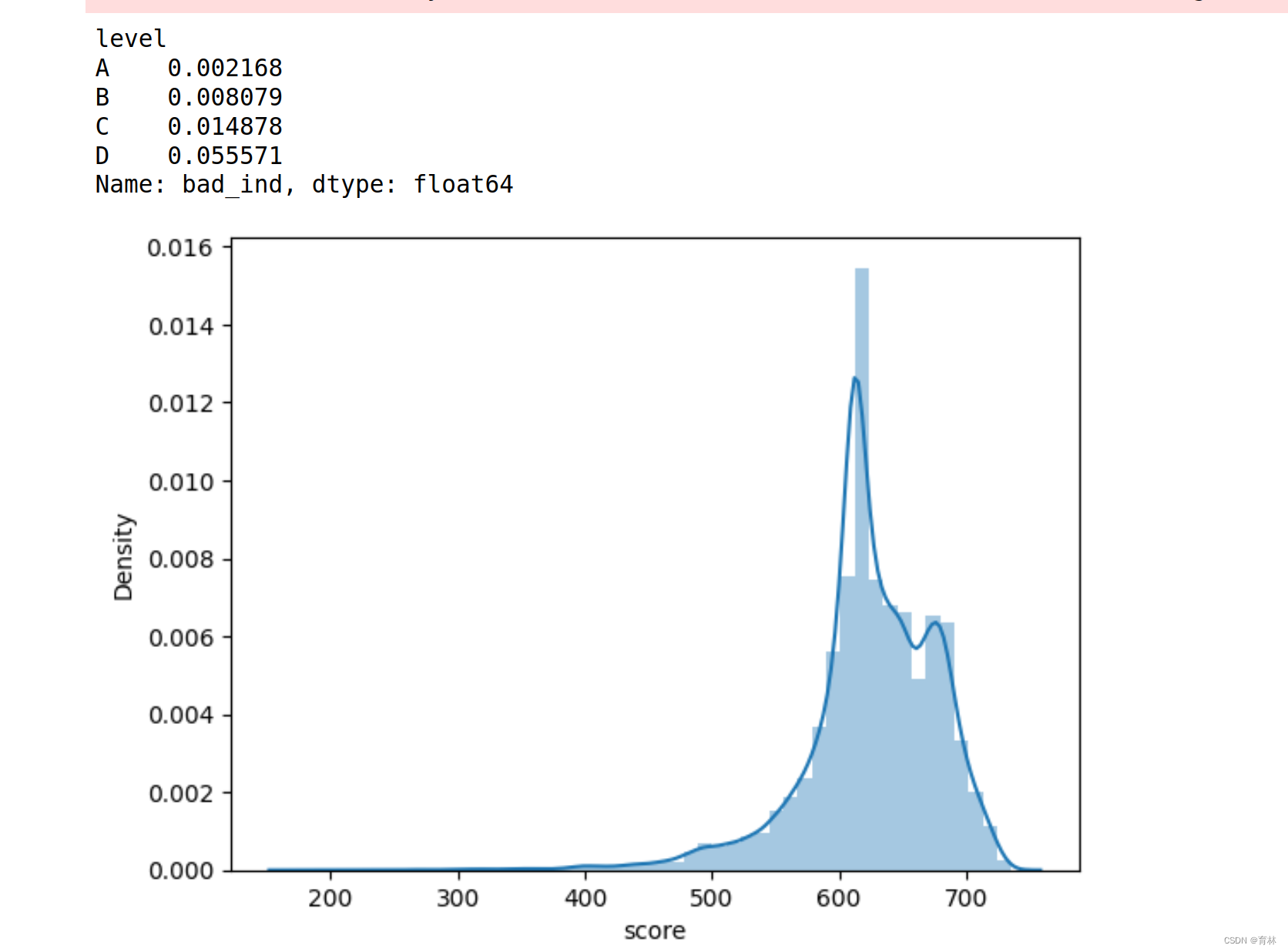
import seaborn as sns
sns.distplot(val.score,kde=True)
val = val.sort_values('score',ascending=True).reset_index(drop=True)
df2=val.bad_ind.groupby(val['level']).sum()
df3=val.bad_ind.groupby(val['level']).count()
print(df2/df3)