C++线程库和POSIX线程库锁的区别
- C++线程库
- 代码段的互斥:mutex、recursive_mutex、timed_mutex、recursive_timed_mutex
- 互斥量mutex:直接进行lock()或者unlock()
- 递归互斥锁recursive_mutex:可以多次加锁,意味着加几次锁就需要解几次锁
- 定时互斥锁timed_mutex:可以定时加锁,规定什么时间让临界区代码实现互斥访问
- 递归定时互斥锁recursive_timed_mutex:在规定加锁时间的同时,还能实现递归的多次加锁要求
- lock_guard:RAII的方式封装了锁
- unique_lock:RAII方式+加锁/解锁
- 变量的原子性操作:atomic
- POSIX线程库
- 互斥锁:pthread_mutex
- 自旋锁:pthread_spin
- 读写锁:pthread_rwlock
C++线程库
C++线程库中提供了多种类型的原子性操作,主要分为变量的原子性操作和代码段的互斥加锁
代码段的互斥:mutex、recursive_mutex、timed_mutex、recursive_timed_mutex
如果一段代码是在多线程编程下执行的,那么必然要涉及到线程安全的问题,需要对该代码段进行加锁保护
#include <iostream>
#include <mutex>
#include <thread>
#include <vector>
std::mutex g_mutex;
int g_count = 0;
void Counter() {
g_mutex.lock();
int i = ++g_count;
std::cout << "count: " << i << std::endl;
// 前面代码如有异常,unlock 就调不到了。
g_mutex.unlock();
}
int main() {
const std::size_t SIZE = 4;
// 创建一组线程。
std::vector<std::thread> v;
v.reserve(SIZE);
for (std::size_t i = 0; i < SIZE; ++i) {
v.emplace_back(&Counter);
}
// 等待所有线程结束。
for (std::thread& t : v) {
t.join();
}
return 0;
}
互斥量mutex:直接进行lock()或者unlock()
上述例子中,使用了mutex这个锁,也就是c++中提出的锁,但是这样的方式导致一个线程执行g_count时,其他线程在进行阻塞等待,是有其自己的缺陷的
递归互斥锁recursive_mutex:可以多次加锁,意味着加几次锁就需要解几次锁
定时互斥锁timed_mutex:可以定时加锁,规定什么时间让临界区代码实现互斥访问
递归定时互斥锁recursive_timed_mutex:在规定加锁时间的同时,还能实现递归的多次加锁要求
lock_guard:RAII的方式封装了锁
使用了RAII的思想,让类对象1去管理锁资源,在创建对象的时候加锁,析构对象的时候解锁,以此来预防死锁
unique_lock:RAII方式+加锁/解锁
除了使用RAII的思想之外,还提供了加锁解锁修改锁的功能,比lock_guard增加了一些对锁的操作
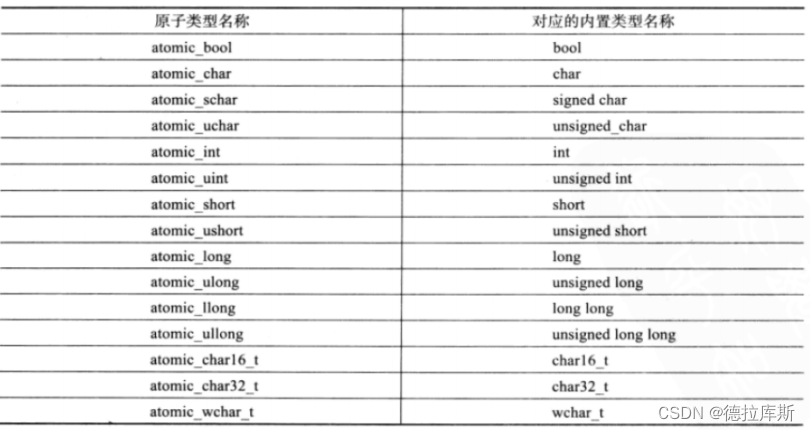
变量的原子性操作:atomic
int a
这个变量在整个多线程编程中如果是一个全局变量(局部变量也可以),那么当多个线程需要对其进行修改操作时,必然涉及到线程安全的问题,需要对这个变量加锁保护,但是使用上述的mutex类型会显得大炮打苍蝇,有点兴师动众了,同时如果使用mutex加锁的方式来实现互斥,会让其他线程处于阻塞等锁的状态,会影响程序的效率
c++11中提供了一系列原子操作
#include <iostream>
using namespace std;
#include <thread>
//需要包含对应的头文件
#include <atomic>
atomic_long sum{ 0 };
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum ++; // 原子操作
}
int main()
{
cout << "Before joining, sum = " << sum << std::endl;
thread t1(fun, 1000000);
thread t2(fun, 1000000);
t1.join();
t2.join();
cout << "After joining, sum = " << sum << std::endl;
return 0;
}
将普通变量修改为原子类型的变量,这样就无需进行加锁解锁操作了,会使代码的运行效率更高,线程自己就能够对这些原子类型的变量实现互斥访问了
POSIX线程库
互斥锁:pthread_mutex
有线程尝试加互斥锁时,如果没有加到锁,该线程会挂起并且切换,只有当其他线程将该互斥锁释放之后,该线程才会被唤醒继续加锁。
和C++中的mutex相似,可以对临界区代码进行加锁保护,但是需要对该互斥锁初始化,并且需要进行销毁
pthread_mutex_init()//初始化
pthread_mutex_lock()//加锁
pthread_mutex_unlock()//解锁
pthread_mutex_destroy()//销毁
自旋锁:pthread_spin
与互斥锁相比,它的效率更高,但是也更占CPU资源。
当有线程尝试加自旋锁时,如果该线程没有加到锁,那么会持续加锁,直到拿到锁为止,线程不会挂起也不会切换,因此加锁效率高,但也更加占用CPU资源
读写锁:pthread_rwlock
当存在这样的场景时:对数据的修改操作少,有大量的读数据操作,在这样的情况下对临界资源进行加锁会导致程序效率低下,那么就需要有一个读不加锁,而只有在写数据的时候才进行加锁来提高程序的效率,读写锁就是这样一个锁
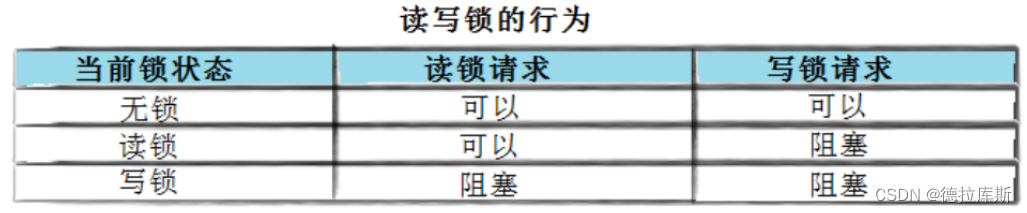
读共享,写独占,读锁优先级高