
Dr. Ehsan Kamalinejad,通常简称为EK,是一位机器学习应用科学家。他目前是亚马逊NLP开发中的精英科学家。以前,他共同创办了Visual One,一家Y Combinator计算机视觉初创公司。在此之前,他曾担任苹果的首席机器学习工程师,参与了诸如“回忆”等项目。EK还是加州州立大学东湾分校的数学副教授。EK,感谢您今天加入我们讨论PPO强化学习算法。谢谢您的邀请。
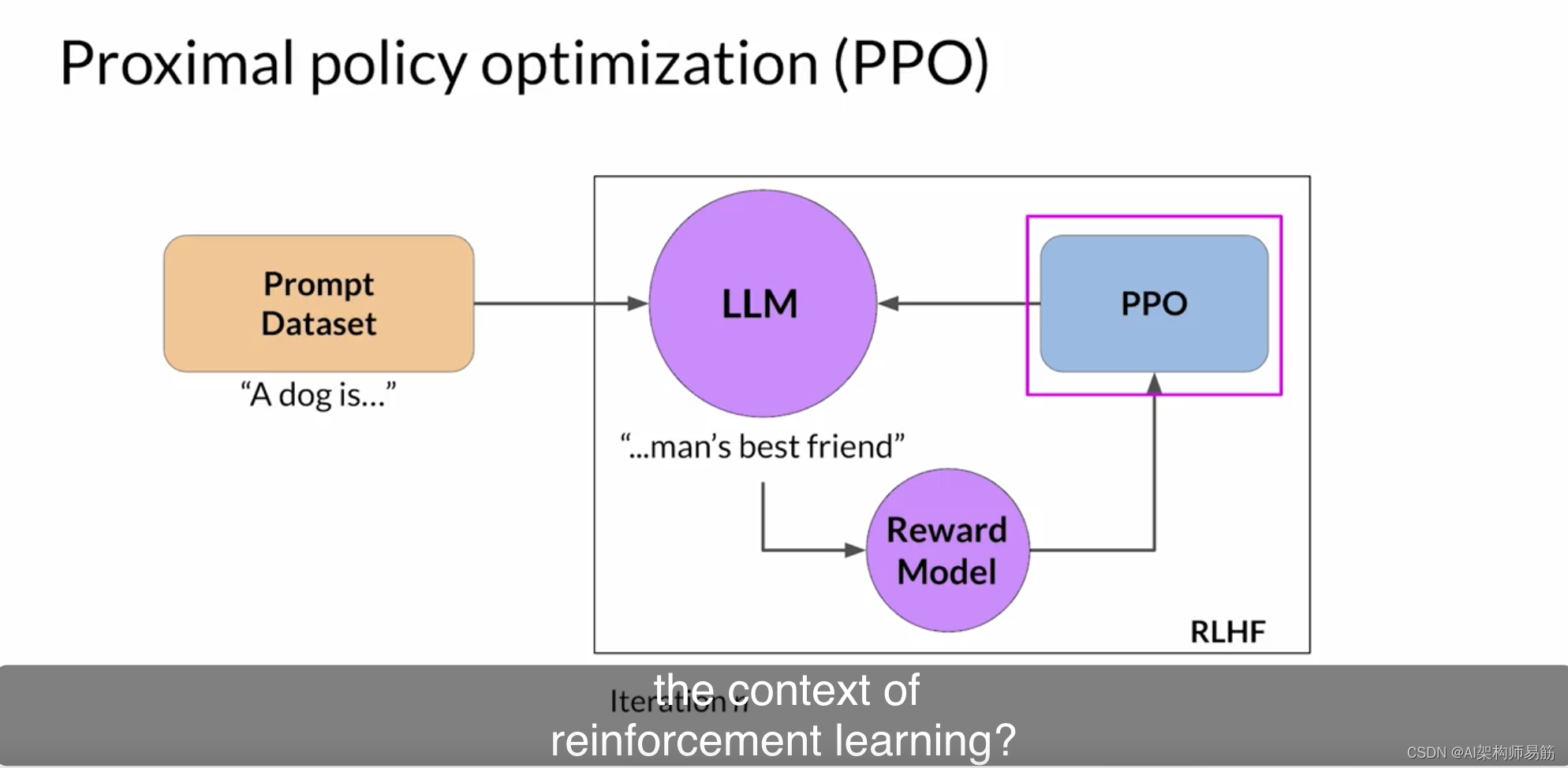
PPO代表什么,这些术语在强化学习的背景下是什么意思?PPO代表近端策略优化,这是一种解决强化学习问题的强大算法。正如名称所示,PPO优化策略,在这种情况下是LLM,以更符合人类偏好。在许多迭代中,PPO对LLM进行更新。这些更新很小,并且在有界区域内,导致更新的LLM接近先前版本,因此得名为近端策略优化。将更改保持在这个小区域内可以实现更稳定的学习。
目标是更新策略,使奖励最大化。您可以讨论一下在大语言模型的特定背景下,这是如何工作的吗?是的,很高兴。您首先使用初始指导Instruct LLM启动PPO,然后从高层次来看,PPO的每个周期都经历两个阶段。
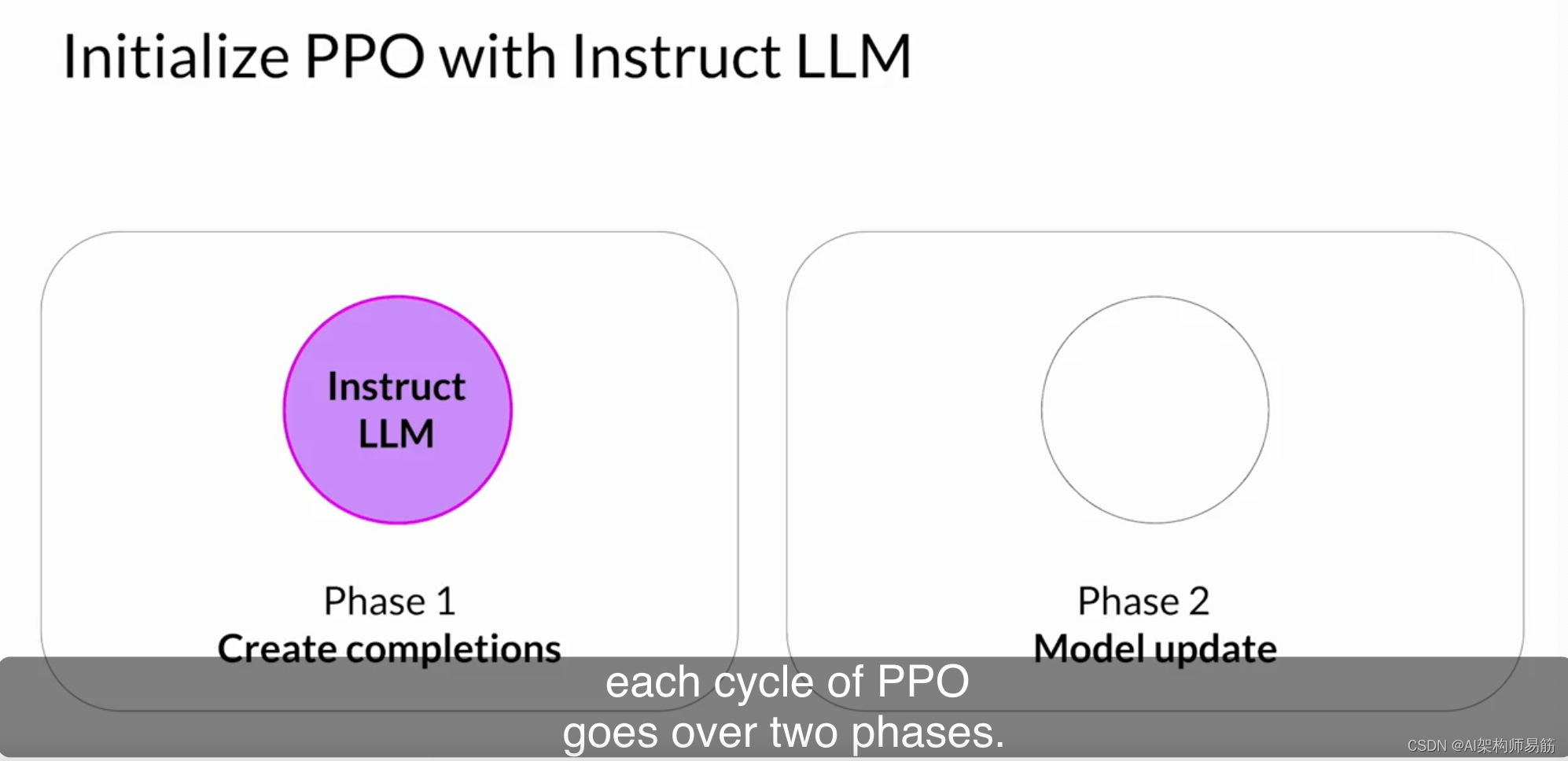
在第一阶段中,LLM用于执行多个实验,完成给定的提示。
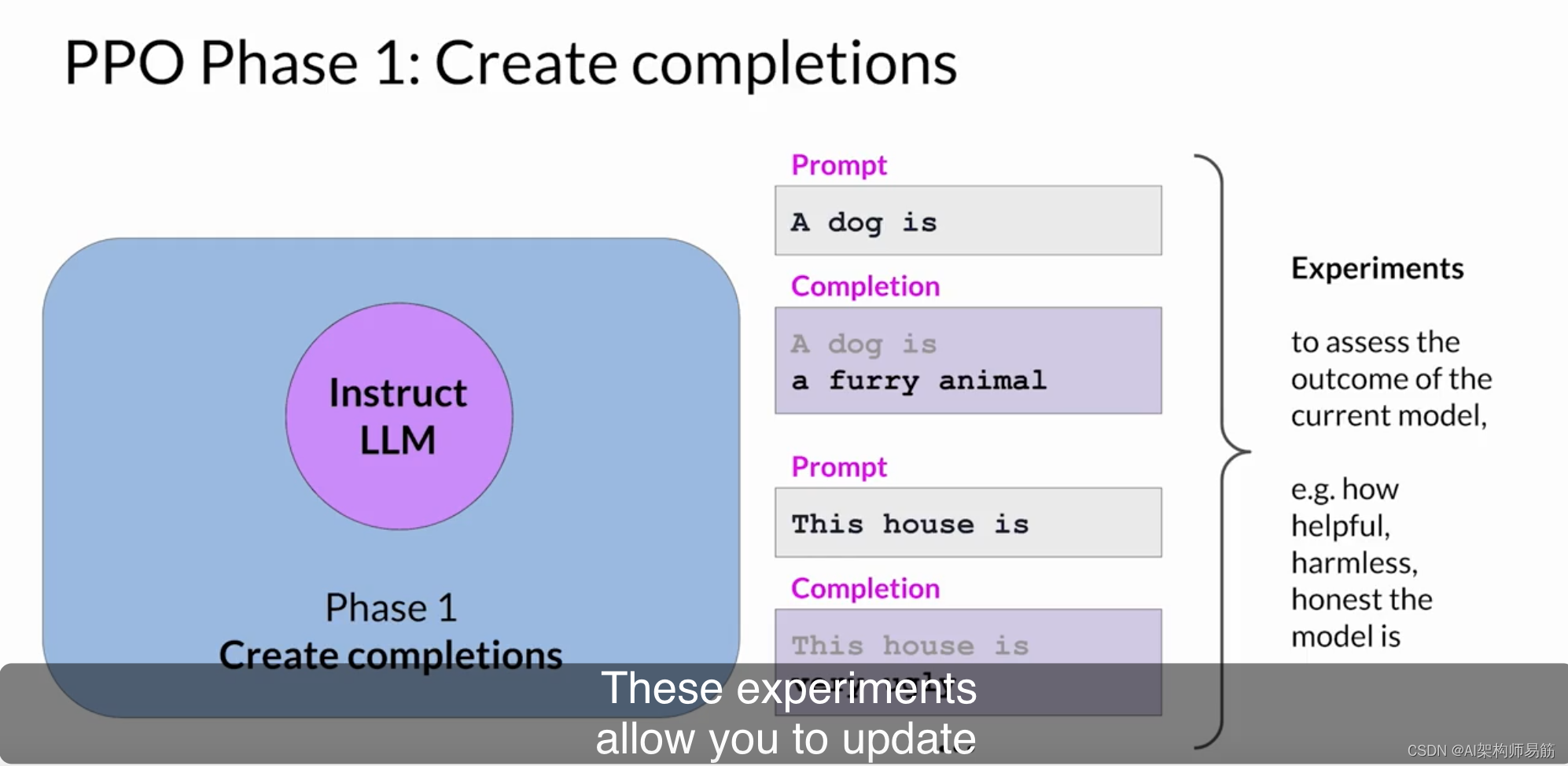
这些实验允许您根据第二阶段的奖励模型更新LLM。请记住,奖励模型捕捉了人类的偏好。例如,奖励可以定义响应的有用性、无害性和诚实性。完成的预期奖励是PPO目标中使用的重要数量。我们通过LLM的一个称为价值函数的独立头部来估计这个数量。
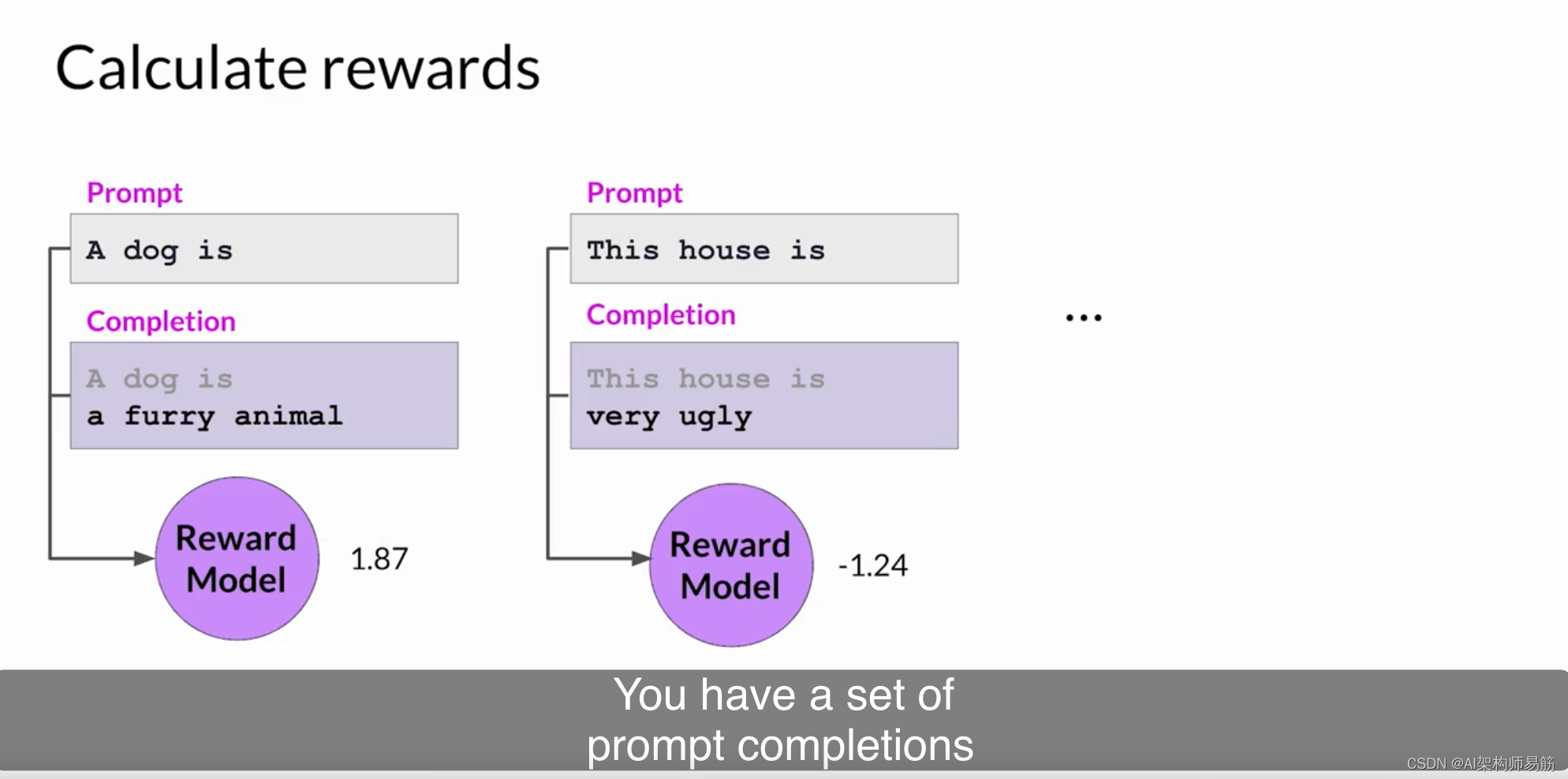
让我们更仔细地看看价值函数和价值损失。假设给出了一些提示。首先,您生成提示的LLM响应,然后使用奖励模型计算提示完成的奖励。例如,这里显示的第一个提示完成可能会获得1.87的奖励。接下来的提示可能会获得-1.24的奖励,依此类推。
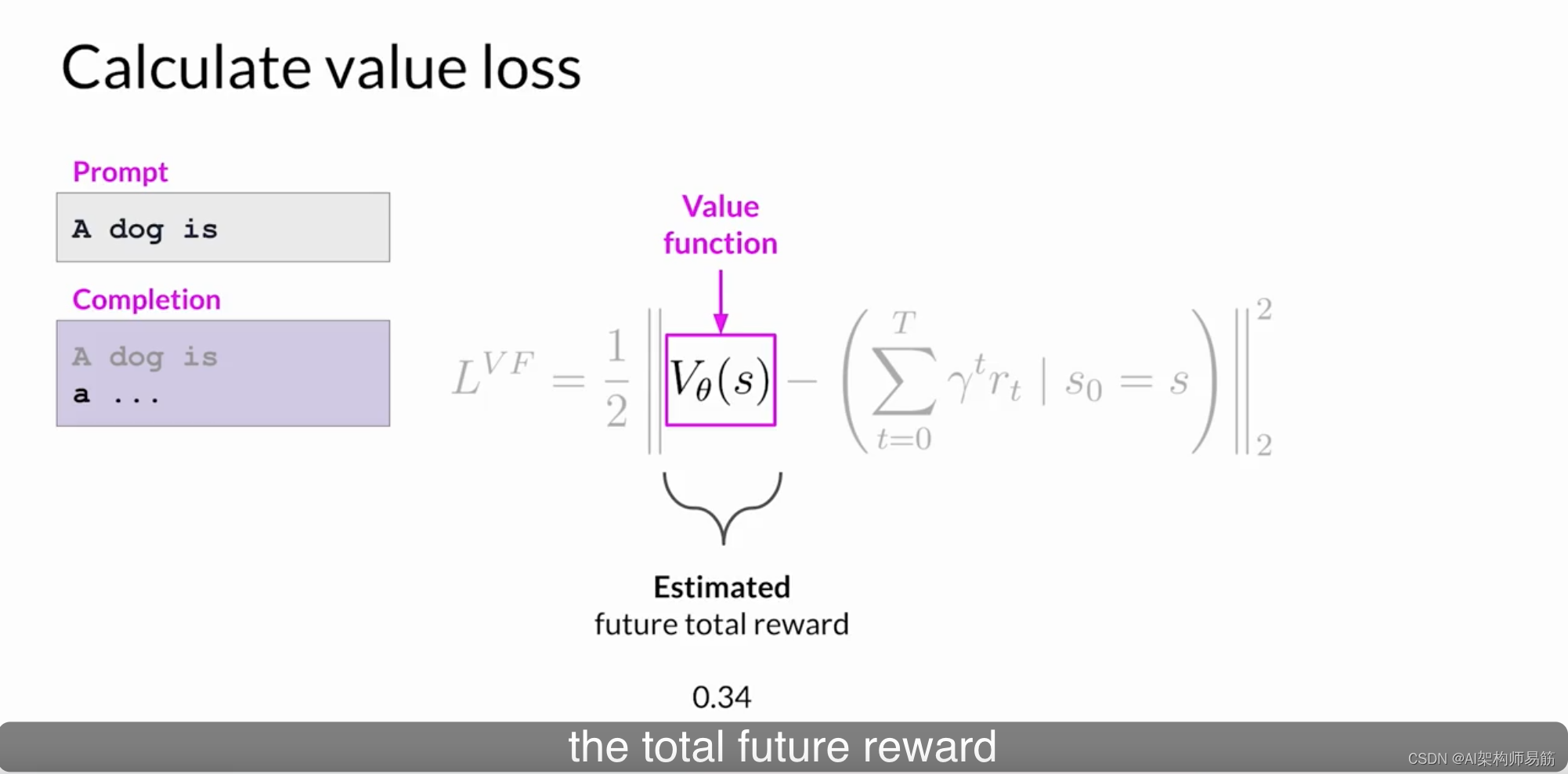
您有一组提示完成和相应的奖励。价值函数估计了给定状态S的预期总奖励。换句话说,当LLM生成完成的每个令牌时,您希望根据当前的令牌序列来估计未来的总奖励。您可以将其视为根据对齐标准评估完成的质量的基线。假设在完成的这一步,估计的未来总奖励是0.34。通过下一个生成的令牌,估计的未来总奖励增加到1.23。目标是最小化价值损失,即实际未来总奖励(在本例中为1.87)与其对价值函数的近似(在本例中为1.23)之间的差异。

价值损失使未来奖励的估计更加准确。然后,价值函数在第二阶段的优势估计中使用,我们稍后会讨论。这类似于当您开始写一篇文章时,甚至在撰写之前就对其最终形式有了大致的想法。
您提到了第1阶段确定的损失和奖励在第2阶段用于更新权重,从而生成更新的LLM。您能更详细地解释一下这个过程吗?当然。在第2阶段,您对模型进行小的更新,并评估这些更新对模型的对齐目标的影响。
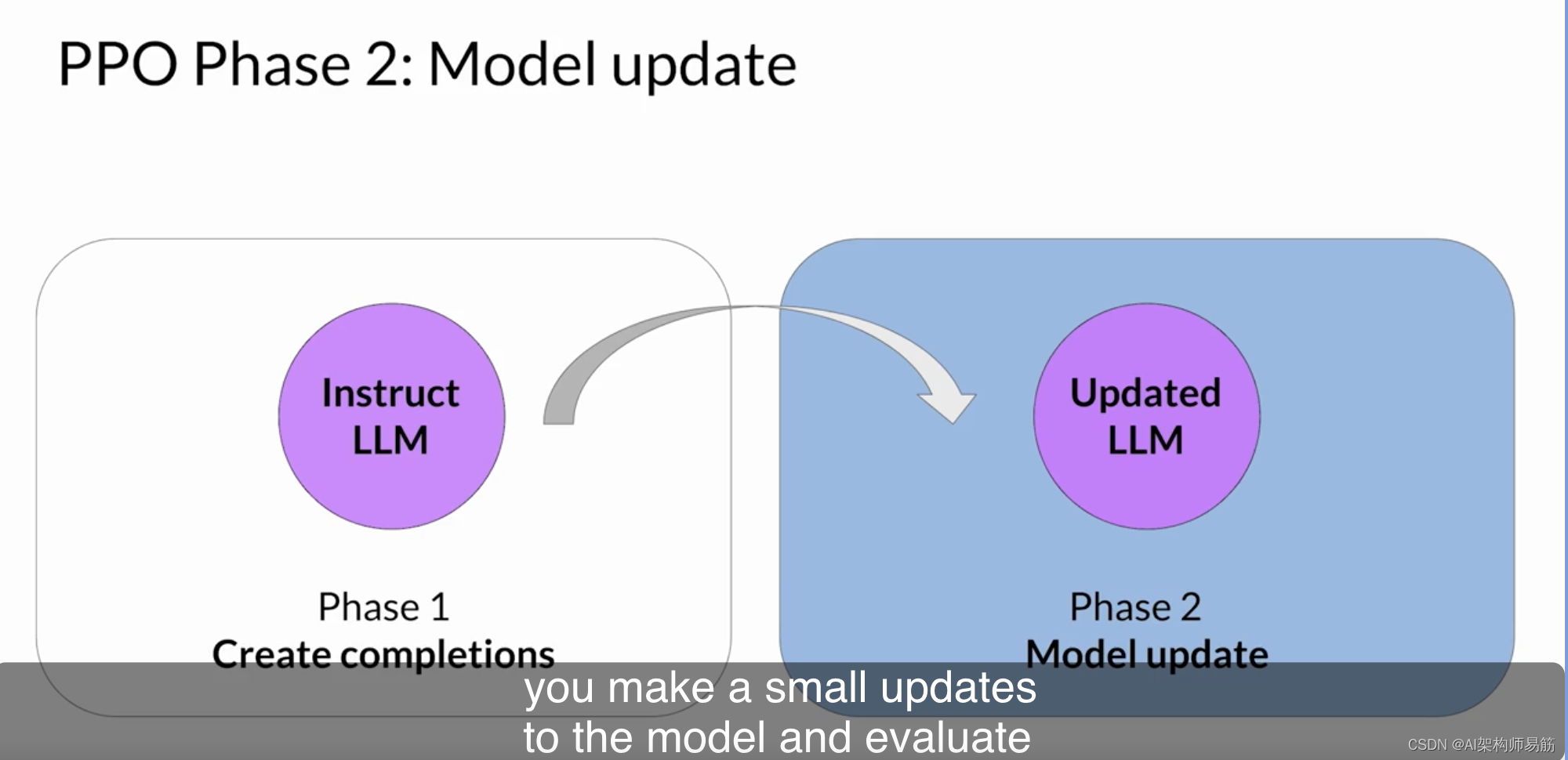
模型权重的更新受提示完成、损失和奖励的指导。PPO还确保将模型更新保持在称为信任区域的某个小区域内。这是PPO近端方面的地方。理想情况下,一系列小的更新将使模型朝着更高的奖励方向前进。PPO策略目标是这种方法的主要组成部分。请记住,目标是找到一个期望奖励很高的策略。换句话说,您试图对LLM权重进行更新,以便生成更符合人类偏好且因此获得更高奖励的完成。
策略损失是PPO算法在培训过程中试图优化的主要目标。我知道数学看起来很复杂,但实际上比看起来简单。让我们逐步分解。

首先,将重点放在最重要的表达式上,现在忽略其余部分。

在LLM的这种情况下,Pi(At | St)是给定当前提示St的情况下下一个令牌At的概率。行动At是下一个令牌,状态St是截止到令牌t的完成提示。

分母是使用初始版本的LLM(已冻结)的下一个令牌的概率。

分子是通过更新的LLM(我们可以改进奖励)计算的下一个令牌的概率。

A-hat_t被称为给定一种行动选择的估计优势项。优势项估计当前行动与数据状态下所有可能行动相比更好或更差的程度。

我们查看了完成后的新令牌的未来奖励的预期值,并估计了这个完成相对于其他完成的优势。有一个用于基于我们之前讨论的价值函数估计这个数量的递归公式。在这里,我们关注直观的理解。
这是我刚才所描述的内容的可视化表示。您有一个提示S,有不同的路径来完成它,由图上的不同路径表示。优势项告诉您当前令牌A_t与所有可能令牌相比是更好还是更差。在这个可视化中,向上走的顶部路径是更好的完成,获得更高的奖励。底部路径下降,这是最差的完成。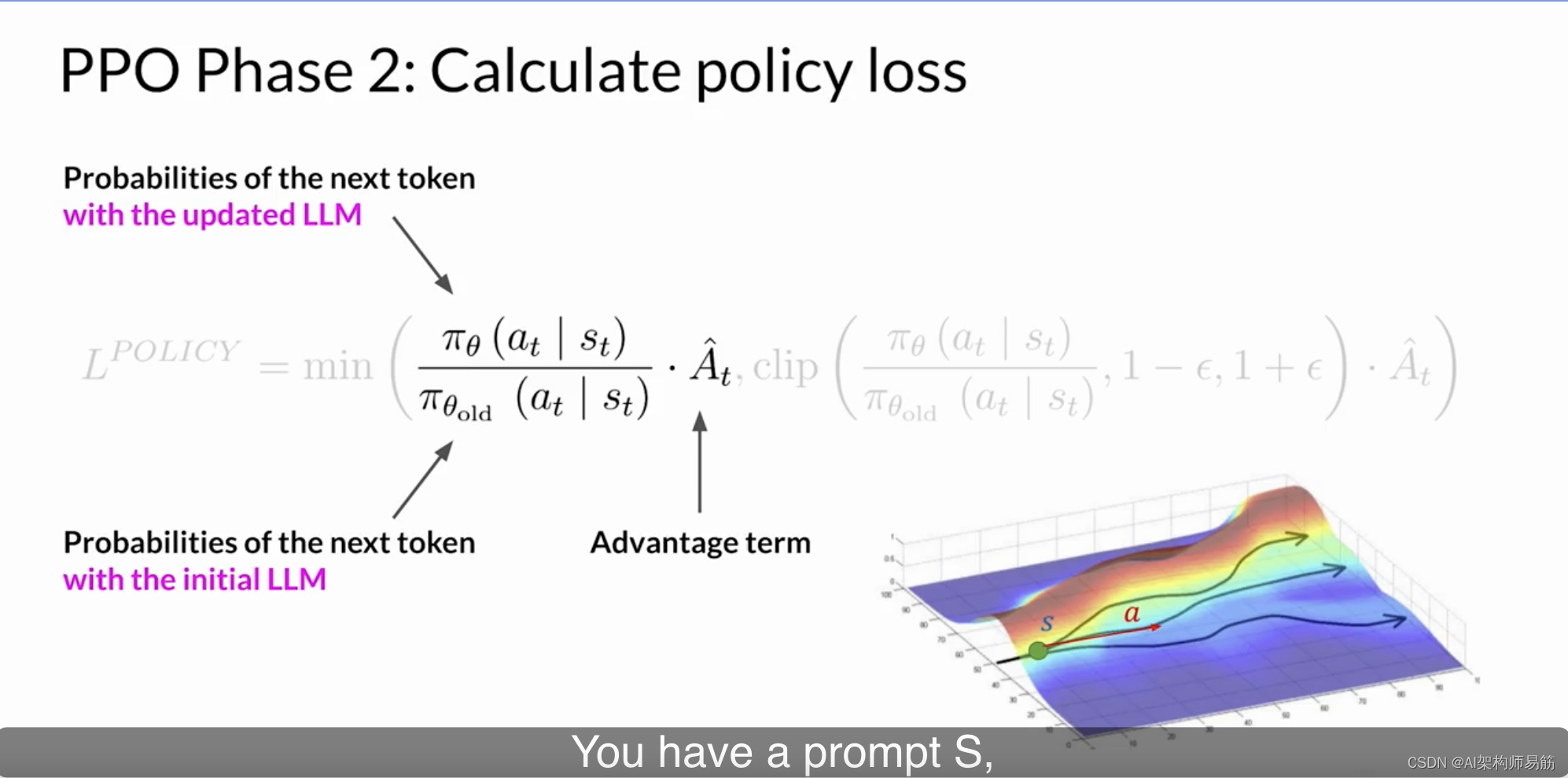
所以我有一个问题EK,为什么最大化这个项会导致更高的奖励?让我们考虑一下,如果建议的令牌的优势是正的情况。正的优势意味着建议的令牌比平均水平更好。因此,增加当前令牌的概率似乎是一种导致更高奖励的好策略。这意味着最大化我们这里的表达式。如果建议的令牌比平均水平差,优势将为负。同样,最大化表达式将降低令牌,这是正确的策略。因此,总的结论是最大化这个表达式会导致更好对齐的LLM。
太好了。那么我们就直接最大化这个表达式吧。直接最大化表达式会导致问题,因为我们的计算是在优势估计有效的假设下可靠的。只有当旧策略和新策略彼此接近时,优势估计才有效。这就是其余术语发挥作用的地方。因此,回过头来再看整个方程,这里发生的情况是选择两个术语中较小的那个。

我们刚刚讨论过的一个术语

和它的第二个修改版本。

请注意,第二个表达式定义了一个区域,在这个区域内,两个策略彼此接近。这些额外的术语是防护栏,只是定义了一个在LLM附近的区域,我们的估计有小误差。这称为信任区域。

这些额外的术语确保我们不太可能离开信任区域。

总之,优化PPO策略目标可以在稳定的方式下更新模型,使其符合人类偏好。
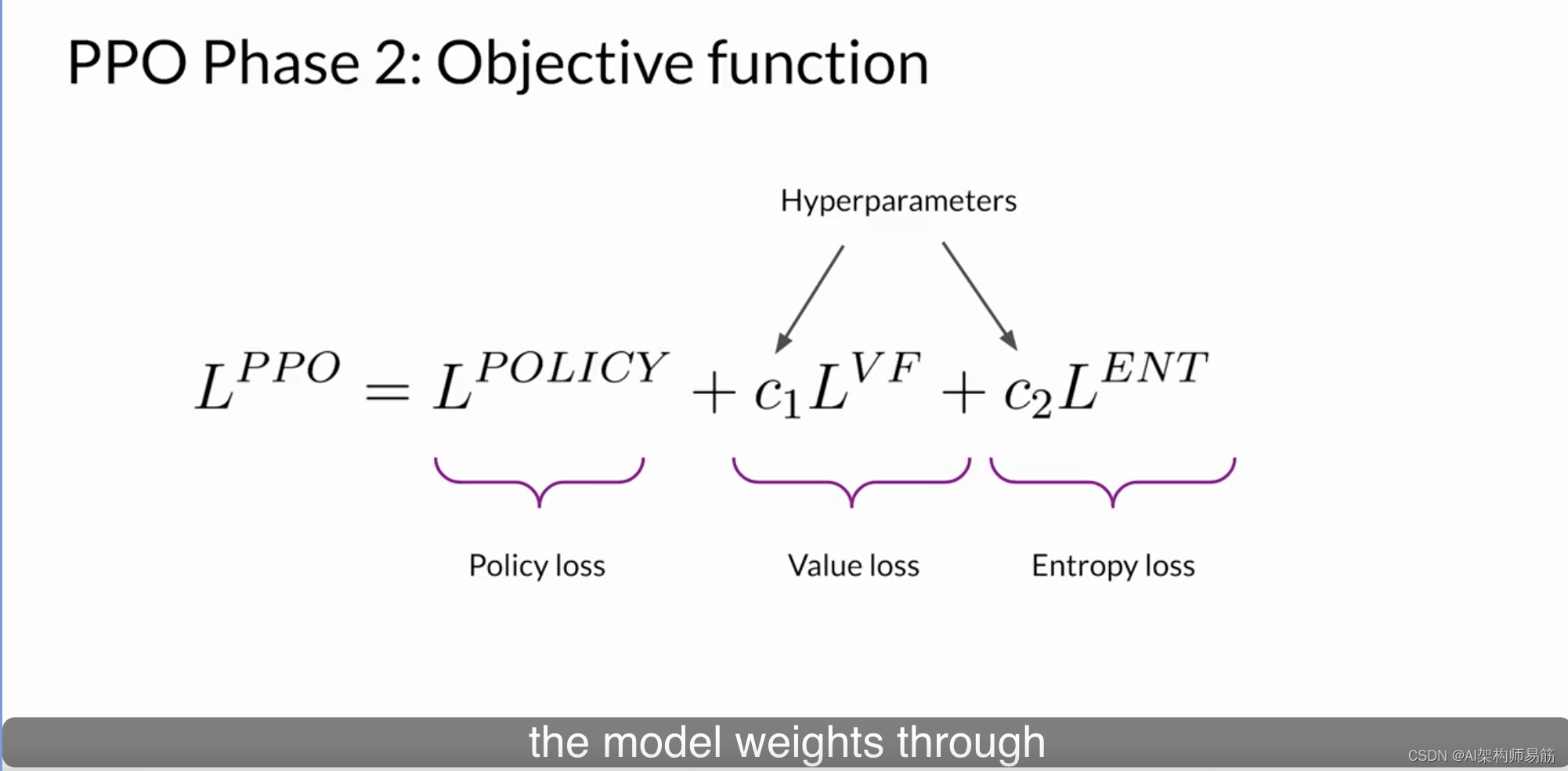
还有其他附加组件吗?是的。还有熵损失。虽然策略损失将模型推向对齐目标,熵允许模型保持创造力。如果您保持熵低,可能最终会像这里所示一样总是以相同的方式完成提示。更高的熵引导LLM朝着更富创造力的方向发展。

这类似于您在第1周中看到的LLM的温度设置。不同之处在于,温度影响模型在推理时的创造力,而熵则影响模型在培训期间的创造力。
将所有术语作为加权总和放在一起,我们得到了我们的PPO目标,它以稳定的方式更新模型以符合人类的偏好。这是整体的PPO目标。

C1和C2系数是超参数。
PPO目标通过反向传播在多个步骤上更新模型权重。一旦模型权重被更新,PPO开始一个新的周期。
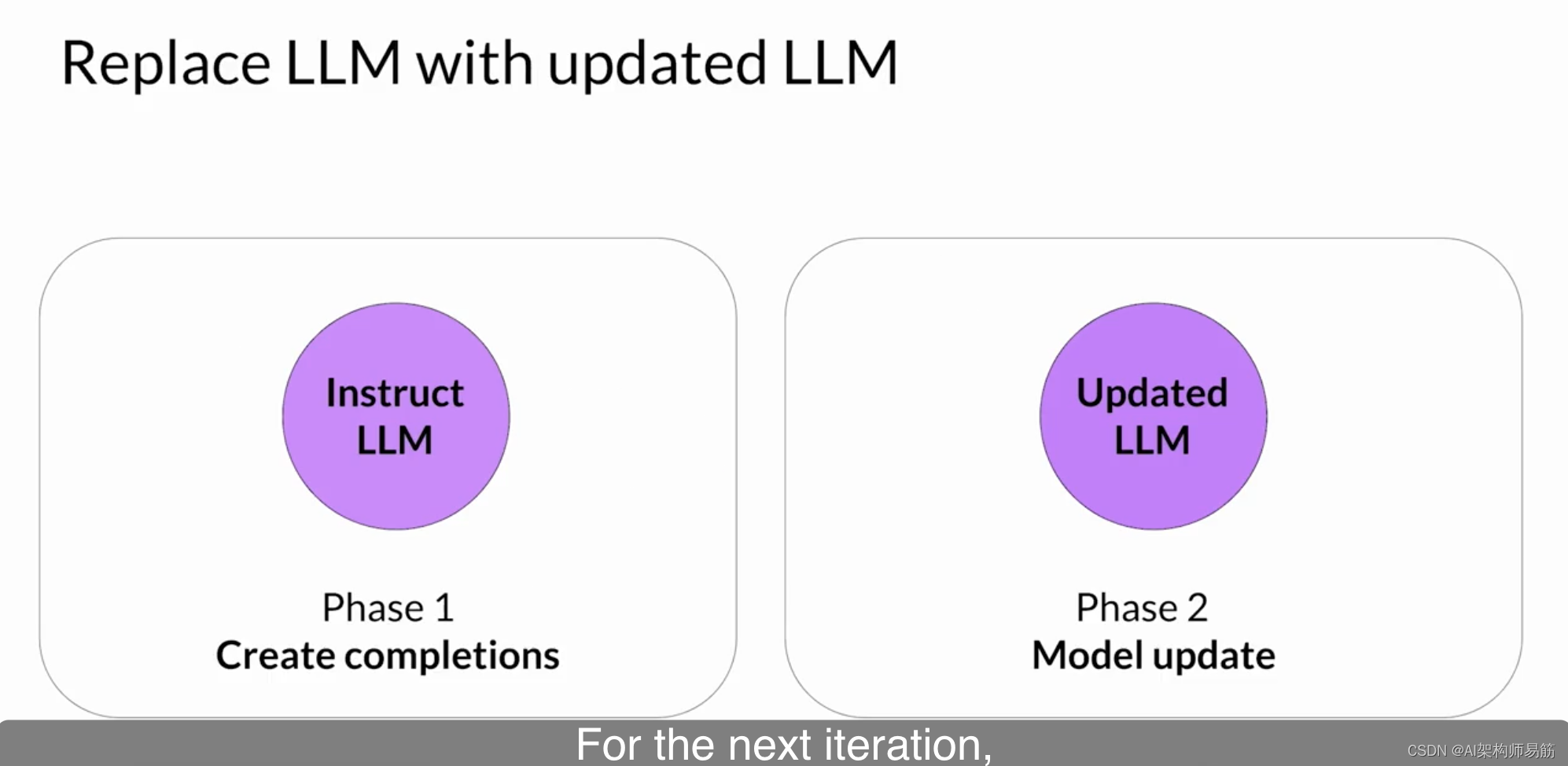
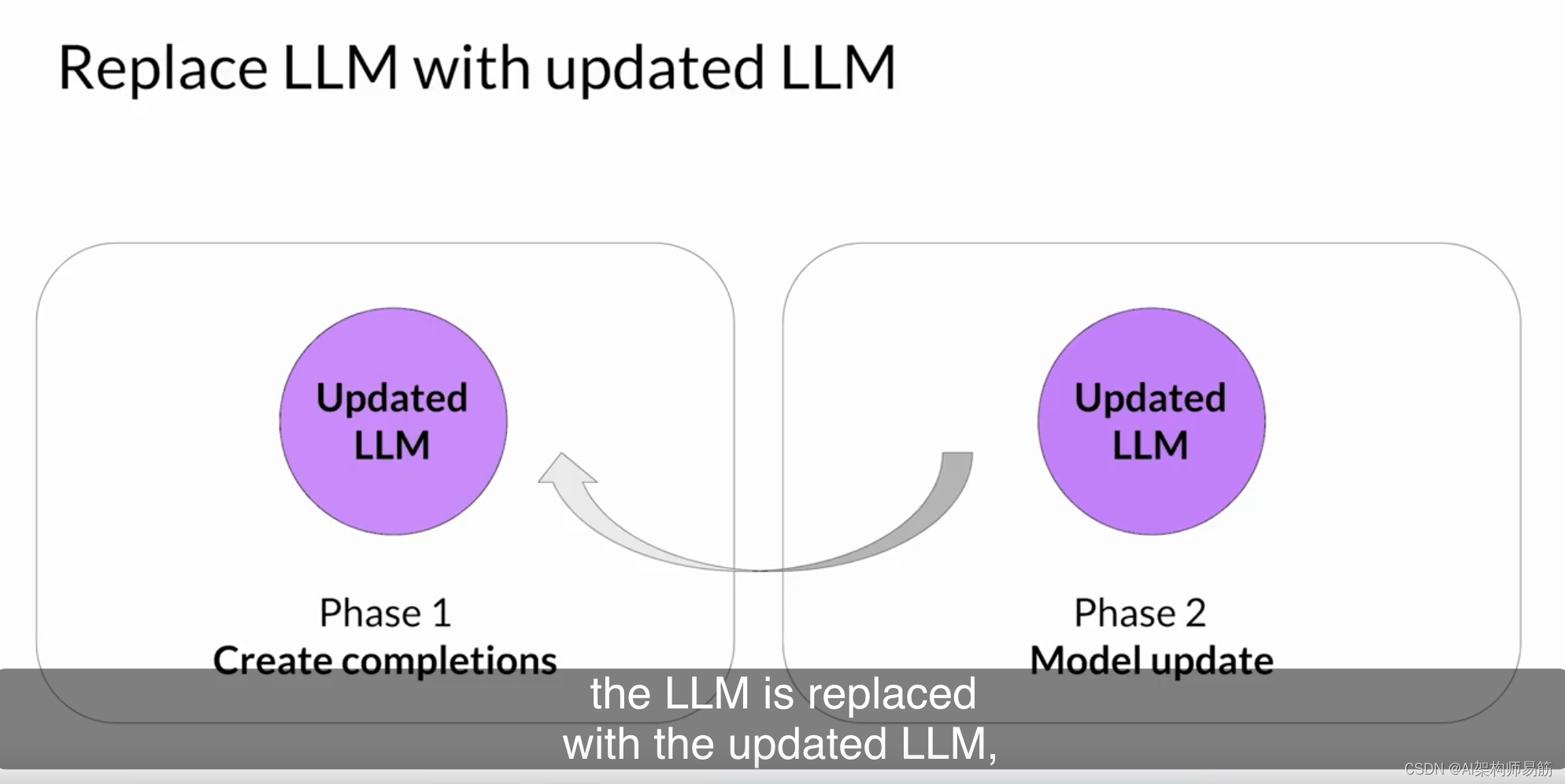
对于下一次迭代,LLM将替换为更新的LLM,并开始一个新的PPO周期。
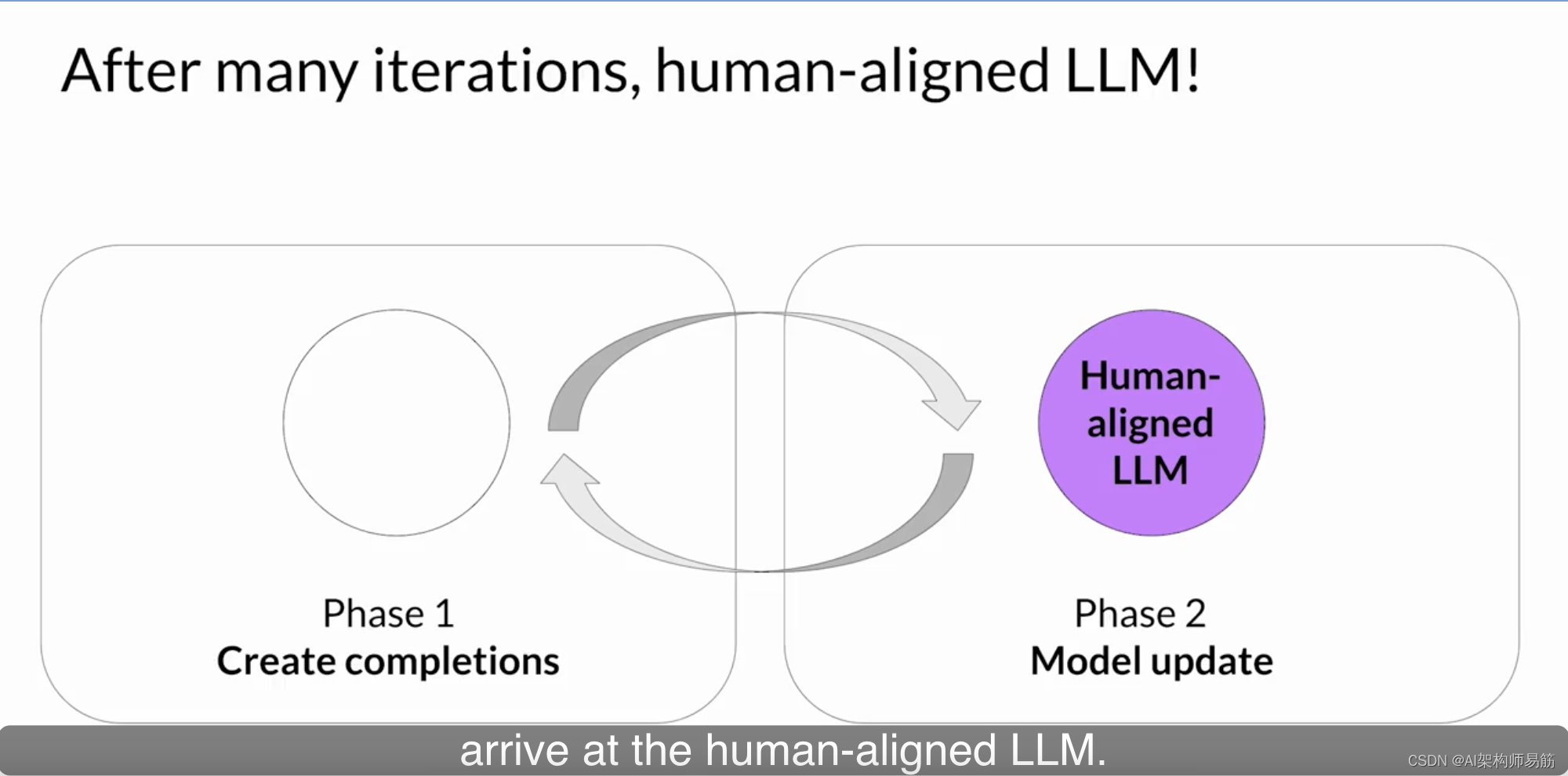
经过多次迭代,您将获得与人对齐的LLM。
那么,还有其他用于RLHF的强化学习技术吗?是的。例如,Q-Learning是一种通过RL微调LLM的替代技术,但目前PPO是最流行的方法。在我看来,PPO之所以流行,是因为它在复杂性和性能之间有着适当的平衡。尽管如此,通过人类或AI反馈微调LLM仍然是一个活跃的研究领域。在不久的将来,我们可以预期在这个领域会有更多的发展。
例如,在录制这段视频之前不久,斯坦福的研究人员发表了一篇论文,描述了一种称为直接偏好优化的技术,这是RLHF的一个更简单的替代方法。像这样的新方法仍在积极开发中,还需要更多的工作来更好地了解它们的好处,但我认为这是一个非常令人兴奋的研究领域。
同意。非常感谢EK分享有关PPO和强化学习的见解。谢谢,安德烈亚。感谢您。
Reference
https://www.coursera.org/learn/generative-ai-with-llms/lecture/1iZJO/optional-video-proximal-policy-optimization





![[C]嵌入式中变量存储方案](https://img-blog.csdnimg.cn/045f9ad988bd412cab38dd54d17b2070.png)


![练[BJDCTF2020]Easy MD5](https://img-blog.csdnimg.cn/img_convert/d5c2510729c57050dfc24f222d34ba01.png)