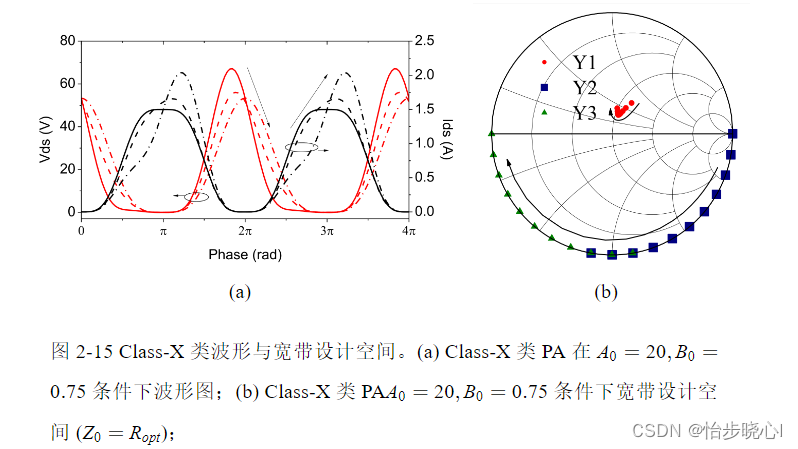
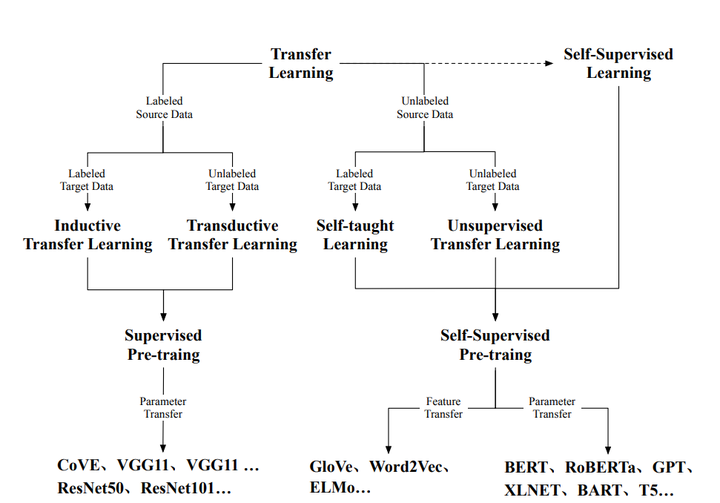
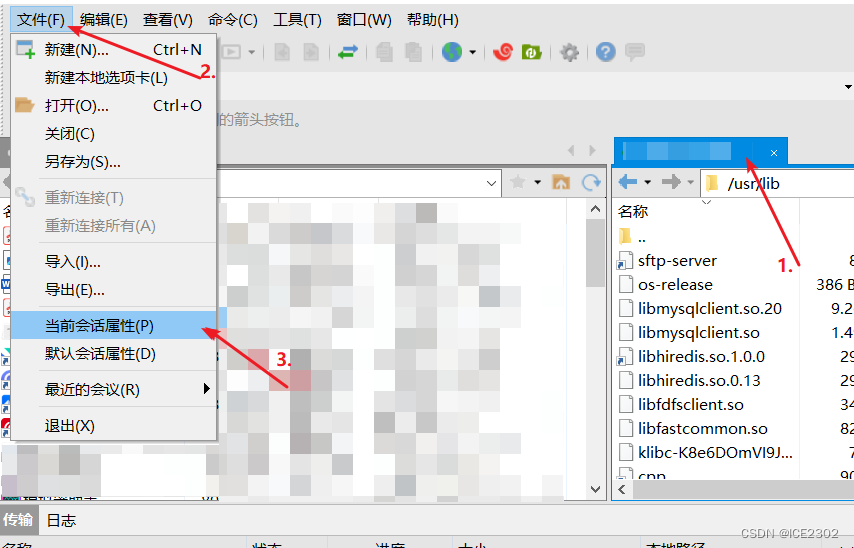
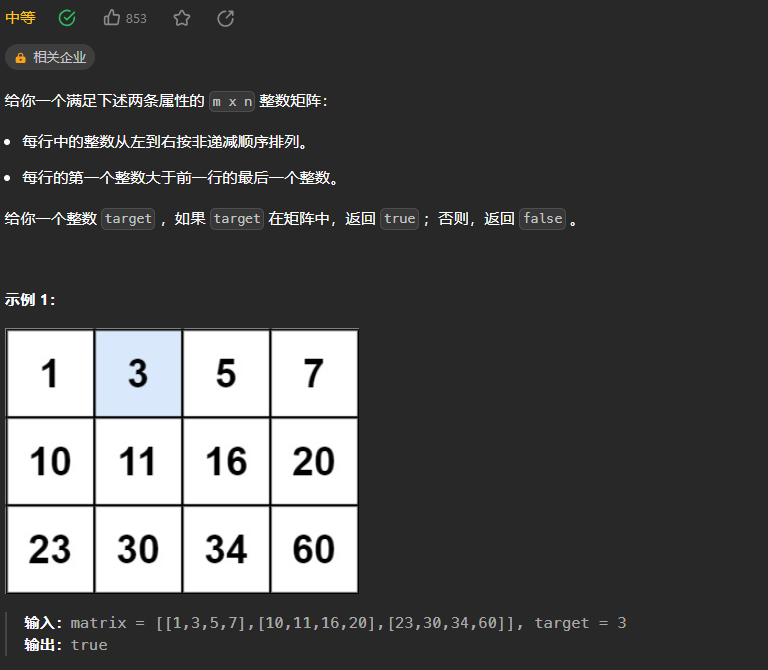
在这个阶段,您已经拥有了训练奖励模型所需的一切。虽然到目前为止,已经付出了相当多的人力,但在训练奖励模型完成后,您将不需要再涉及更多的人类。相反,奖励模型将在强化学习微调过程中代替人类标记者,自动选择首选的完成。这个奖励模型通常也是一个语言模型。例如,一个通过在来自人类标记者对提示的评估中准备的成对比较数据上使用监督学习方法进行训练的模型。对于给定的提示X,奖励模型学习偏好人类首选的完成y_j,同时最小化奖励差异r_j-r_k的lock sigmoid。
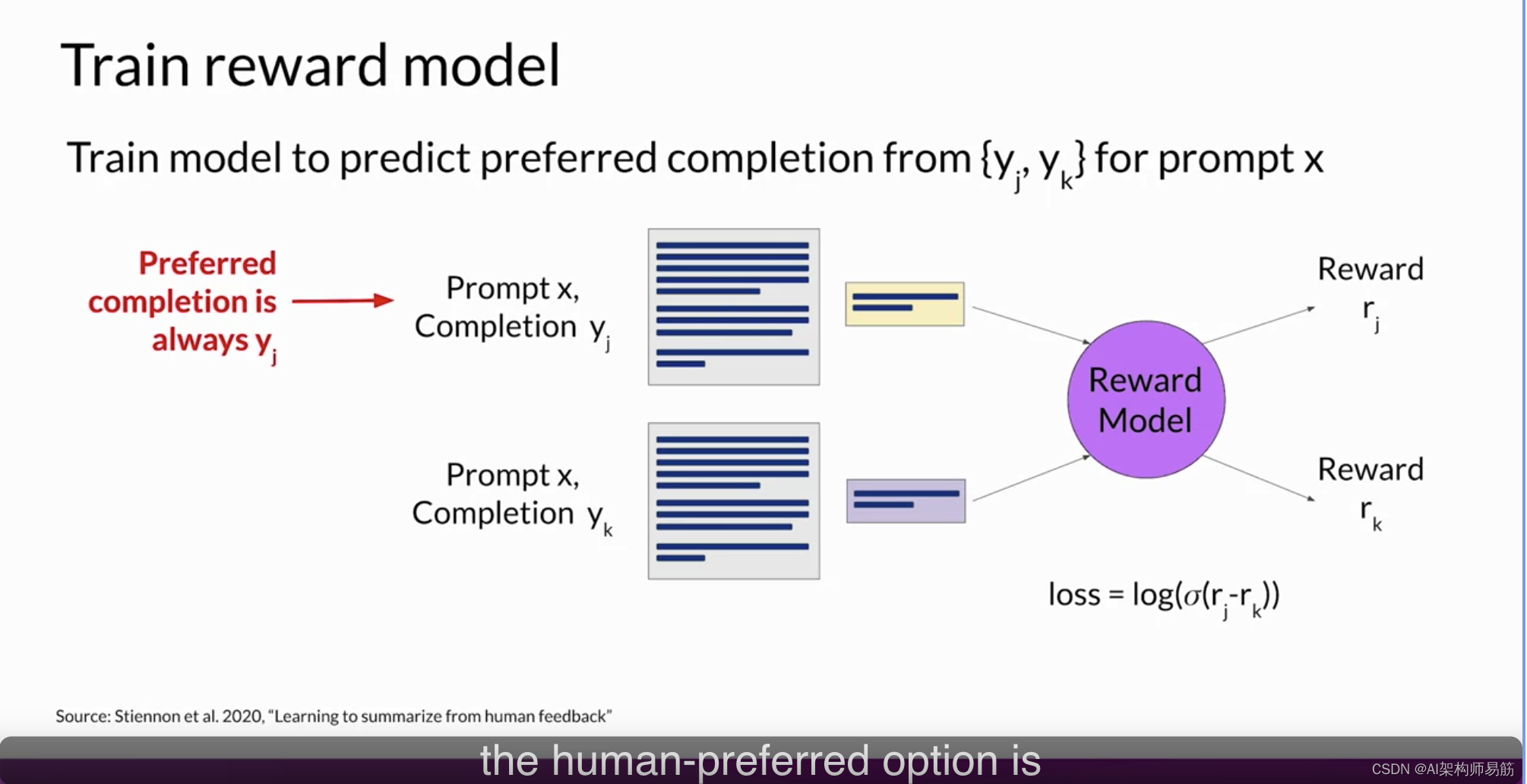
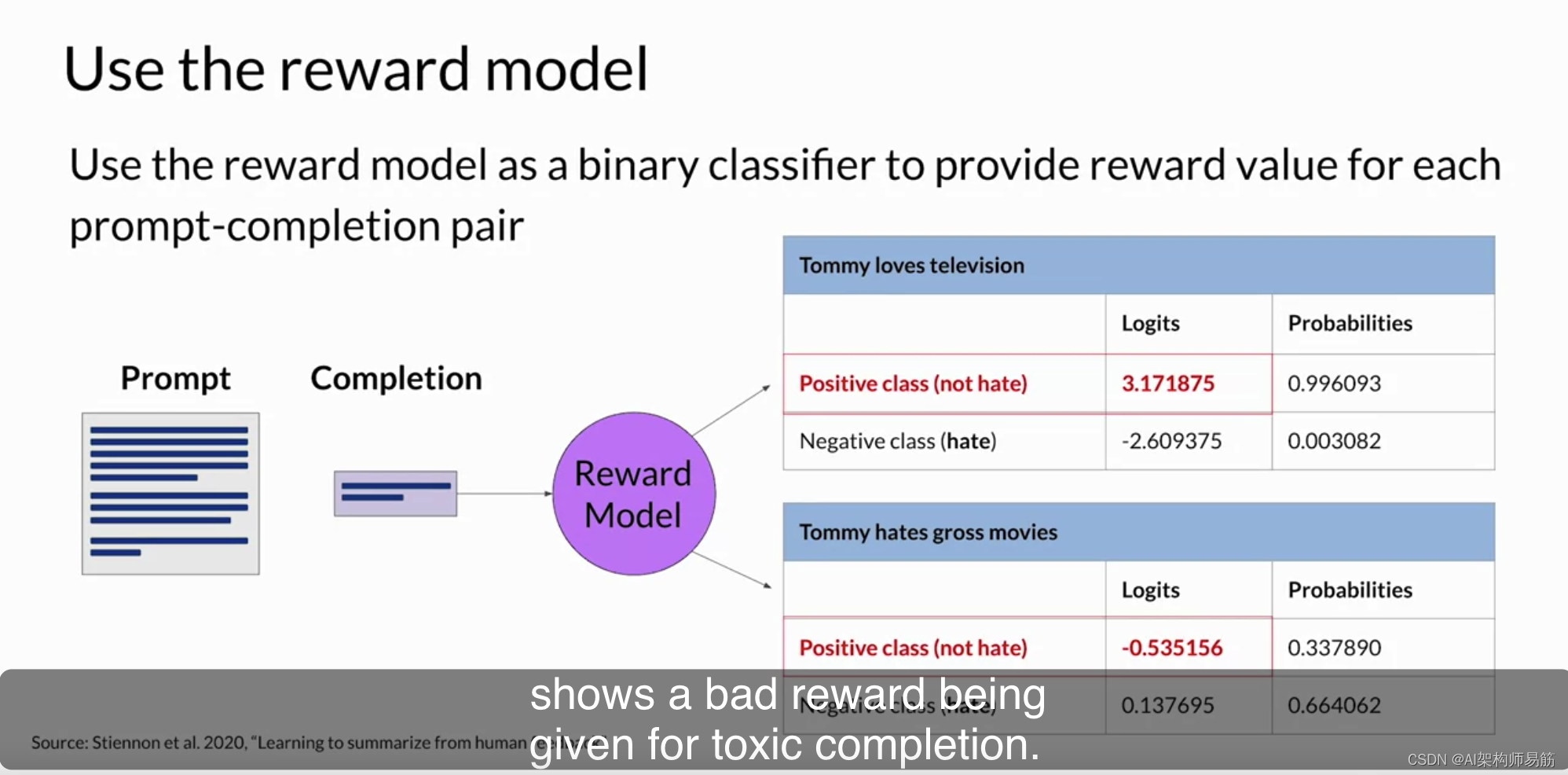
正如您在上一张幻灯片上看到的,人类首选项始终是标记为y_j的第一个选项。一旦模型在人类排名提示完成对上进行了训练,您可以使用奖励模型作为二元分类器,提供一组对正类和负类的logits。logits是应用任何激活函数之前的未规范化模型输出。假设您想要对您的LLM进行去毒操作,奖励模型需要识别完成是否包含仇恨言论。

在这种情况下,这两个类别将是非仇恨(notate),即您最终希望进行优化的正类别,和仇恨(hate),即您希望避免的负类别。正类别的最大值是您在LLHF中用作奖励值的值。只是为了提醒您,如果对logits应用Softmax函数,您将得到概率。

这里的示例显示了对非有毒完成的良好奖励,第二个示例显示了对有毒完成的差奖励。
我知道这节课到目前为止涵盖了很多内容。但在这一点上,您已经拥有了一个强大的工具,即用于调整您的LLM的奖励模型。下一步是探讨奖励模型如何在强化学习过程中用于训练与人类对齐的LLM。请在下一个视频中加入我,了解这是如何运作的。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/Wf1jL/rlhf-reward-model