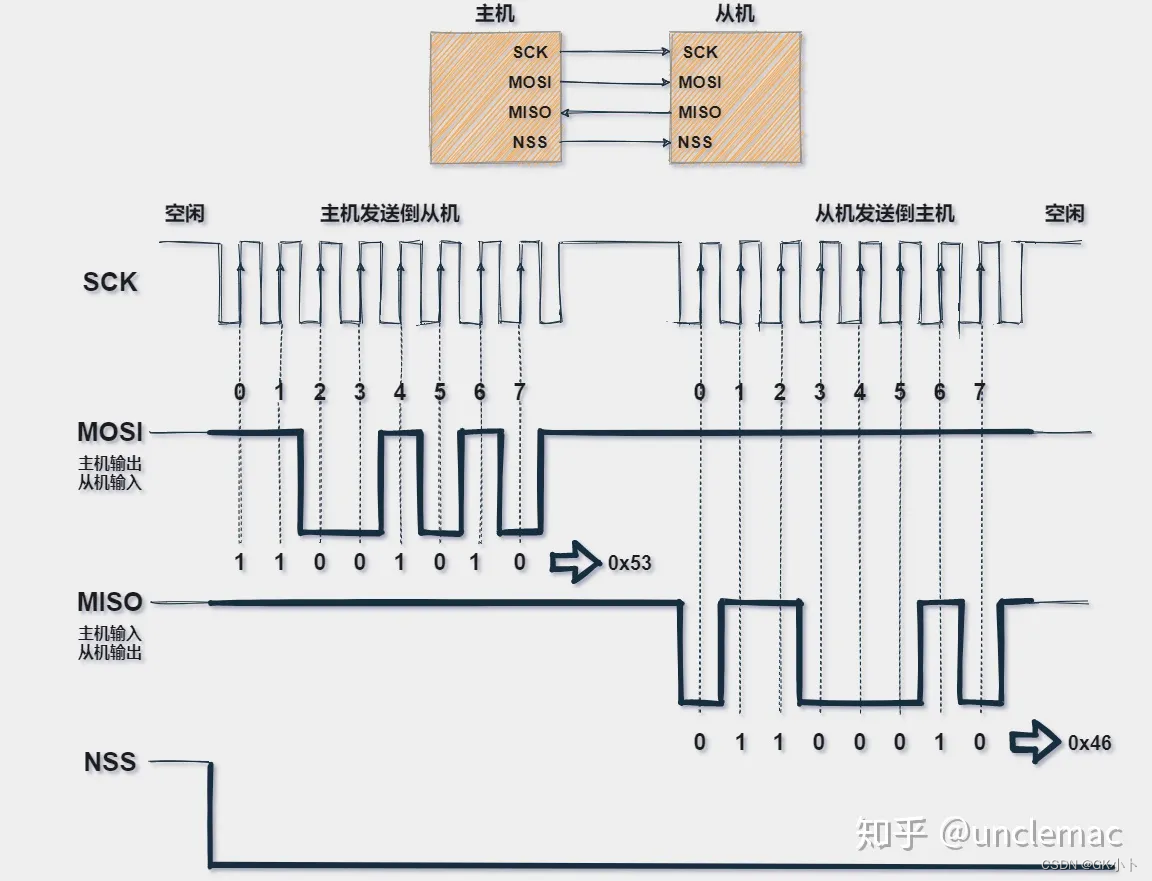
在使用RLHF进行微调的第一步是选择要使用的模型,并使用它准备一个人工反馈数据集。
您选择的模型应该具备执行您感兴趣的任务的一定能力,无论这是文本摘要、问答还是其他任务。通常情况下,您可能会发现,从已经在许多任务上进行了微调并具备一定通用能力的预训练模型开始会更容易一些。然后,您将使用这个LLM(大型语言模型),以及一个提示数据集,为每个提示生成多个不同的响应。提示数据集由多个提示组成,每个提示都会经过LLM处理,生成一组完成。
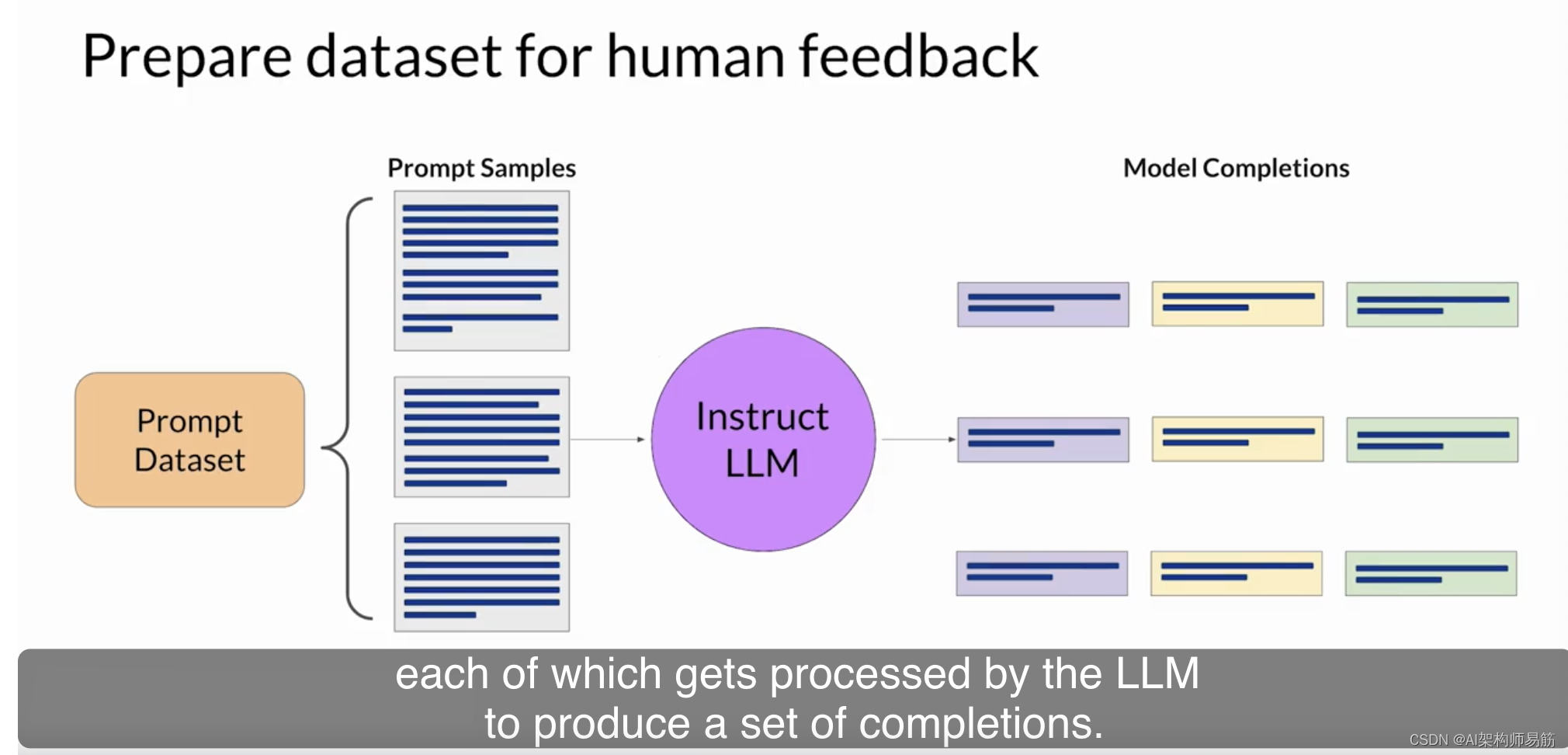
接下来的步骤是从人工标记者那里收集有关LLM生成的完成的反馈。这是RLHF(强化学习与人工反馈)中的人工反馈部分。首先,您必须决定您希望人们根据什么标准来评估完成。这可以是前面讨论过的任何问题,比如帮助性或有害性等。一旦您决定了,您将要求标记者根据该标准对数据集中的每个完成进行评估。让我们来看一个例子。在这种情况下,提示是"My house is too hot."(我的房子太热了)。您将此提示传递给LLM,然后LLM会生成三个不同的完成。标记者的任务是根据帮助性对这三个完成进行排名,从最有帮助到最不帮助。因此,在这里,标记者可能会决定完成二是最有帮助的。它告诉用户一些可以真正冷却他们的房子的东西,并排名为第一。

完成一和三都不是很有帮助,但也许标记者会决定三是两者中较差的,因为模型实际上与用户的输入意见不一致。所以标记者将顶部完成排在第二位,最后一个完成排在第三位。然后,这个过程将在许多提示完成集上重复进行,建立一个可用于训练奖励模型的数据集,该模型最终将在代替人类进行此工作时使用。通常情况下,相同的提示完成集通常会分配给多个人类标记者,以建立共识并减小组内差标记者的影响。就像这里的第三个标记者一样,他的回答与其他人不一致,可能表示他误解了说明,这实际上是一个非常重要的观点。您的说明的清晰度可以对您获得的人工反馈的质量产生很大影响。标记者通常来自代表多元和全球思维的人群样本。
在这里,您可以看到一组为人类标记者编写的示例指令。这将在标记者开始任务之前呈现给标记者阅读,并在他们处理数据集时提供供参考。说明从标记者应该执行的整体任务开始。在这种情况下,选择最佳完成提示。

说明继续提供额外的详细信息,以指导标记者如何完成任务。通常情况下,您使这些说明越详细,标记者理解他们必须完成的任务并完全按照您的要求完成任务的可能性就越高。例如,在第二个指令项中,告诉标记者他们应该根据对响应的正确性和信息性的感知来做出决策。他们被告知可以使用互联网进行事实检查和查找其他信息。

他们还明确指示了如果发现并列的情况,即他们认为有两个同样正确和信息丰富的完成,他们应该怎么做。
标记者被告知可以将两个完成排名相同,但他们应该谨慎地这样做。

在这里需要强调的最后一项指令是在回答荒谬、令人困惑或不相关的情况下应该怎么办。在这种情况下,标记者应选择"F"而不是排名,以便轻松删除质量差的答案。

提供这样详细的指令可以增加回答的质量,并确保个别人会以与其他人相似的方式执行任务。这有助于确保标记的完成集将代表共识观点。
当您的人工标记者完成了他们对提示完成集的评估后,您将拥有训练奖励模型所需的所有数据,该模型将在强化学习微调过程中用于分类模型的完成,而不是人类。然而,在开始训练奖励模型之前,您需要将排名数据转换为完成的成对比较。

换句话说,应该对每个提示的可用选择中的所有可能成对完成进行0或1分的分类。在示例中,有三个完成提示,由人工标记者分配的排名为2、1、3,其中1是最高排名,对应于最受欢迎的响应。对于三种不同的完成,存在三种可能的配对:紫色-黄色、紫色-绿色和黄色-绿色。对于每一对,您将为首选响应分配1分,对于较不喜欢的响应分配0分。然后,您将重新排列提示,以使首选选项首先出现。这是一个重要的步骤,因为奖励模型期望首选完成,也就是称为Yj的完成,首先出现。
一旦完成了这个数据的重构,人类的响应将以正确的格式呈现,以用于训练奖励模型。请注意,虽然拇指指向上、拇指指向下的反馈通常比排名反馈更容易收集,但排名反馈可以为您提供更多的完成数据,以训练您的奖励模型。如您所见,在这里,每个人类排名都可以获得三个提示完成对。
参考
https://www.coursera.org/learn/generative-ai-with-llms/lecture/lQBGW/rlhf-obtaining-feedback-from-humans