文章目录
- 0 前言
- 1 实现方法
- 1.1 原理
- 1.1.1 字符定位
- 1.1.2 字符识别
- 1.1.3 深度学习算法介绍
- 1.1.4 模型选择
- 2 算法流程
- 3 部分关键代码
- 4 效果展示
- 5 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 毕业设计 图像识别 深度学习 身份证识别系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 实现方法
1.1 原理
1.1.1 字符定位
在Android移动端摄像头拍摄的图片是彩色图像,上传到服务器后为了读取到身份证上的主要信息,就要去除其他无关的元素,因此对身份证图像取得它的灰度图并得到二值化图。
对身份证图像的的二值化有利于对图像内的信息的进一步处理,可以将待识别的信息更加突出。在OpenCV中,提供了读入图像接口函数imread,
首先通过imread将身份证图像读入内存中:
id_card_img = cv2.imread(path_img)
之后再调用转化为灰度图的接口函数cvtColor并给它传入参数COLOR_BGR2GRAY,它就可以实现彩色图到灰度图的转换,代码如下
gray_id_card_img = cv2.cvtColor(color_img, cv2.COLOR_BGR2GRAY)
preprocess_bg_mask = PreprocessBackgroundMask(boundary)
转化为二值化的灰度图后图像如图所示:

转换成灰度图之后要进行字符定位,通过每一行进行垂直投影,就可以找到所有字段的位置,具体如下:

然后根据像素点起始位置,确定字符区域,然后将字符区域一一对应放入存放字符的列表中:
vertical_peek_ranges = extract_peek_ranges_from_array(
vertical_sum,
minimun_val=40,
minimun_range=1)
vertical_peek_ranges2d.append(vertical_peek_ranges)
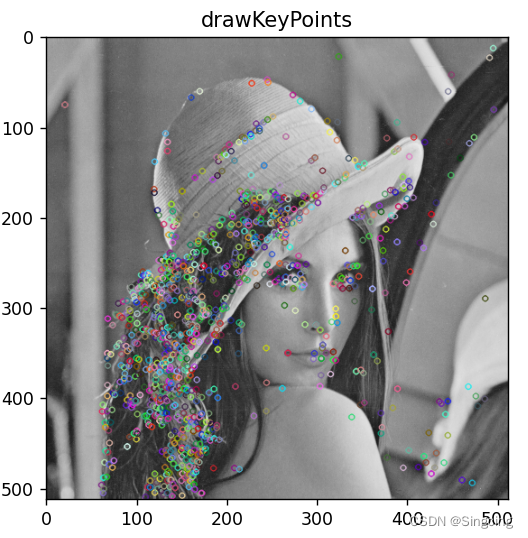
最后的效果图如图所示:

1.1.2 字符识别
身份证识别中,最重要的是能够识别身份证图像中的中文文字(包括数字和英文字母),这里学长采用深度学习的方式来做:
1)身份证图像涉及个人隐私,很难获取其数据训练集。针对此问题,我采用获取身份证上印刷体汉字和数字的数据训练集的方法,利用Python图像库(PIL)将13类汉字印刷体字体转换成6492个类别,建立了较大的字符训练集;
2)如何获取身份证图片上的字符是在设计中一个重要问题。我采用水平和垂直投影技术,首先对身份证图像进行预处理,然后对图片在水平和垂直方向上像素求和,区分字符与空白区域,完成了身份证图像中字符定位与分割工作,有很好的切分效果;
3)在模型训练中模型的选择与设计是一个重要的环节,本文选择Lenet模型,发现模型层次太浅,然后增加卷积层和池化层,设计出了改进的深层Lenet模型,然后采用Caffe深度学习工具对模型进行训练,并在训练好的模型上进行测试,实验表明,模型的测试精度达到96.2%。
1.1.3 深度学习算法介绍
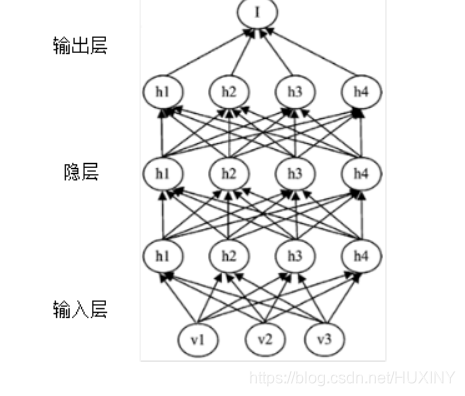
深度学习技术被提出后,发展迅速,在人工智能领域取得了很好的成绩,越来越多优秀的神经网络也应运而生。深度学习通过建立多个隐层的深层次网络结构,比如卷积神经网络,可以用来研究并处理目前计算机视觉领域的一些热门的问题,如图像识别和图像检索。
深度学习建立从输入数据层到高层输出层语义的映射关系,免去了人工提取特征的步骤,建立了类似人脑神经网的分层模型结构。深度学习的示意图如图所示
1.1.4 模型选择
在进行网络训练前另一项关键的任务是模型的选择与配置,因为要保证模型的精度,要选一个适合本文身份证信息识别的网络模型。
首先因为汉字识别相当于一个类别很多的图片分类系统,所以先考虑深层的网络模型,优先采用Alexnet网络模型,对于汉字识别这种千分类的问题很合适,但是在具体实施时发现本文获取到的数据训练集每张图片都是6464大小的一通道的灰度图,而Alexnet的输入规格是224224三通道的RGB图像,在输入上不匹配,并且Alexnet在处理像素较高的图片时效果好,用在本文的训练中显然不合适。
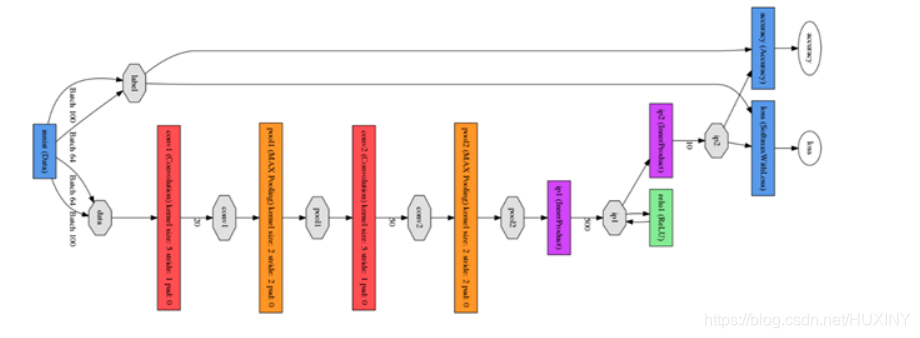
其次是Lenet模型,没有改进的Lenet是一个浅层网络模型,如今利用这个模型对手写数字识别精度达到99%以上,效果很好,在实验时我利用在Caffe下的draw_net.py脚本并且用到pydot库来绘制Lenet的网络模型图,实验中绘制的原始Lenet网络模型图如图所示,图中有两个卷积层和两个池化层,网络层次比较浅。
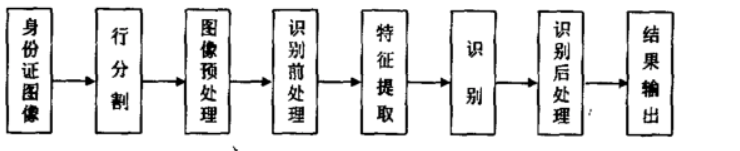
2 算法流程
3 部分关键代码
cv2_color_img = cv2.imread(test_image)
##放大图片
resize_keep_ratio = PreprocessResizeKeepRatio(1024, 1024)
cv2_color_img = resize_keep_ratio.do(cv2_color_img)
##转换成灰度图
cv2_img = cv2.cvtColor(cv2_color_img, cv2.COLOR_RGB2GRAY)
height, width = cv2_img.shape
##二值化 调整自适应阈值 使得图像的像素值更单一、图像更简单
adaptive_threshold = cv2.adaptiveThreshold(
cv2_img, ##原始图像
255, ##像素值上限
cv2.ADAPTIVE_THRESH_GAUSSIAN_C, ##指定自适应方法Adaptive Method,这里表示领域内像素点加权和
cv2.THRESH_BINARY, ##赋值方法(二值化)
11, ## 规定领域大小(一个正方形的领域)
2) ## 常数C,阈值等于均值或者加权值减去这个常数
adaptive_threshold = 255 - adaptive_threshold
## 水平方向求和,找到行间隙和字符所在行(numpy)
horizontal_sum = np.sum(adaptive_threshold, axis=1)
## 根据求和结果获取字符行范围
peek_ranges = extract_peek_ranges_from_array(horizontal_sum)
vertical_peek_ranges2d = []
for peek_range in peek_ranges:
start_y = peek_range[0] ##起始位置
end_y = peek_range[1] ##结束位置
line_img = adaptive_threshold[start_y:end_y, :]
## 垂直方向求和,分割每一行的每个字符
vertical_sum = np.sum(line_img, axis=0)
## 根据求和结果获取字符行范围
vertical_peek_ranges = extract_peek_ranges_from_array(
vertical_sum,
minimun_val=40, ## 设最小和为40
minimun_range=1) ## 字符最小范围为1
## 开始切割字符
vertical_peek_ranges = median_split_ranges(vertical_peek_ranges)
## 存放入数组中
vertical_peek_ranges2d.append(vertical_peek_ranges)
## 去除噪音,主要排除杂质,小的曝光点不是字符的部分
filtered_vertical_peek_ranges2d = []
for i, peek_range in enumerate(peek_ranges):
new_peek_range = []
median_w = compute_median_w_from_ranges(vertical_peek_ranges2d[i])
for vertical_range in vertical_peek_ranges2d[i]:
## 选取水平区域内的字符,当字符与字符间的间距大于0.7倍的median_w,说明是字符
if vertical_range[1] - vertical_range[0] > median_w*0.7:
new_peek_range.append(vertical_range)
filtered_vertical_peek_ranges2d.append(new_peek_range)
vertical_peek_ranges2d = filtered_vertical_peek_ranges2d
char_imgs = []
crop_zeros = PreprocessCropZeros()
resize_keep_ratio = PreprocessResizeKeepRatioFillBG(
norm_width, norm_height, fill_bg=False, margin=4)
for i, peek_range in enumerate(peek_ranges):
for vertical_range in vertical_peek_ranges2d[i]:
## 划定字符的上下左右边界区域
x = vertical_range[0]
y = peek_range[0]
w = vertical_range[1] - x
h = peek_range[1] - y
## 生成二值化图
char_img = adaptive_threshold[y:y+h+1, x:x+w+1]
## 输出二值化图
char_img = crop_zeros.do(char_img)
char_img = resize_keep_ratio.do(char_img)
## 加入字符图片列表中
char_imgs.append(char_img)
## 将列表转换为数组
np_char_imgs = np.asarray(char_imgs)
## 放入模型中识别并返回结果
output_tag_to_max_proba = caffe_cls.predict_cv2_imgs(np_char_imgs)
ocr_res = ""
## 读取结果并展示
for item in output_tag_to_max_proba:
ocr_res += item[0][0]
print(ocr_res.encode("utf-8"))
## 生成一些Debug过程产生的图片
if debug_dir is not None:
path_adaptive_threshold = os.path.join(debug_dir,
"adaptive_threshold.jpg")
cv2.imwrite(path_adaptive_threshold, adaptive_threshold)
seg_adaptive_threshold = cv2_color_img
# color = (255, 0, 0)
# for rect in rects:
# x, y, w, h = rect
# pt1 = (x, y)
# pt2 = (x + w, y + h)
# cv2.rectangle(seg_adaptive_threshold, pt1, pt2, color)
color = (0, 255, 0)
for i, peek_range in enumerate(peek_ranges):
for vertical_range in vertical_peek_ranges2d[i]:
x = vertical_range[0]
y = peek_range[0]
w = vertical_range[1] - x
h = peek_range[1] - y
pt1 = (x, y)
pt2 = (x + w, y + h)
cv2.rectangle(seg_adaptive_threshold, pt1, pt2, color)
path_seg_adaptive_threshold = os.path.join(debug_dir,
"seg_adaptive_threshold.jpg")
cv2.imwrite(path_seg_adaptive_threshold, seg_adaptive_threshold)
debug_dir_chars = os.path.join(debug_dir, "chars")
os.makedirs(debug_dir_chars)
for i, char_img in enumerate(char_imgs):
path_char = os.path.join(debug_dir_chars, "%d.jpg" % i)
cv2.imwrite(path_char, char_img)
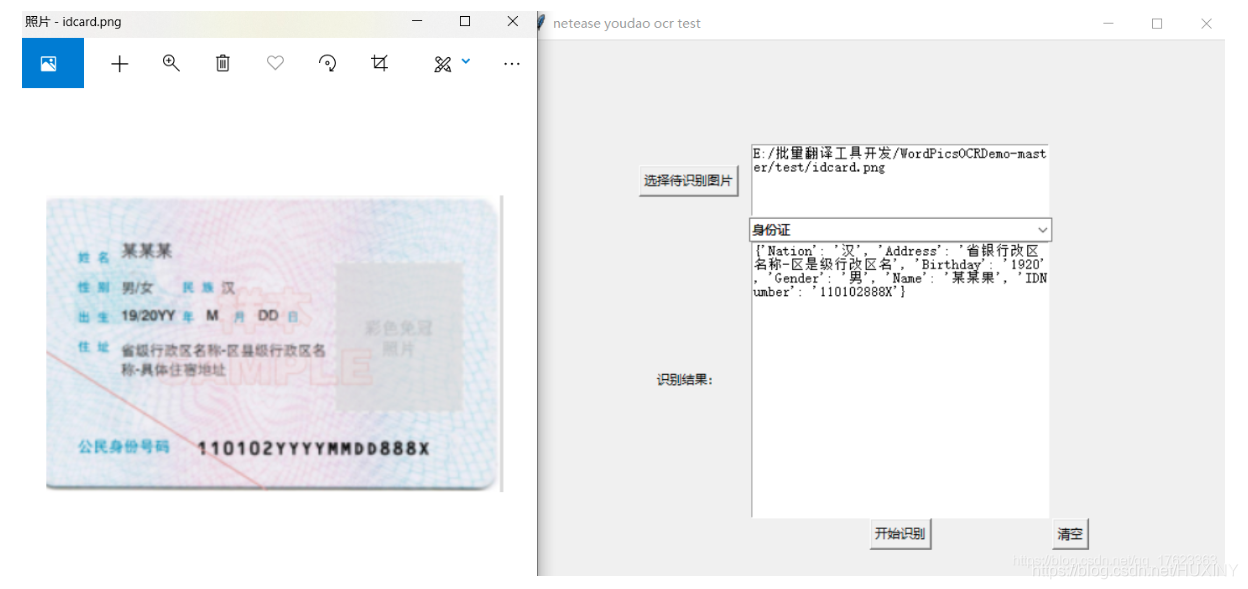
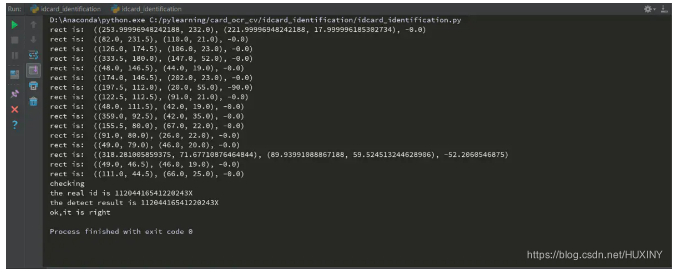
4 效果展示

5 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate