FaceChain写真开源项目插播:
最新 FaceChain支持多人合照写真、上百种单人写真风格,项目信息汇总:ModelScope 魔搭社区 。
github开源直达(觉得有趣的点个star哈。):https://github.com/modelscope/facechain
摘要: 伴随着持续不断的AIGC浪潮,越来越多的AI生成玩法正在被广大爱好者定义和提出,图像卡通化(动漫化)基于其还原效果高,风格种类丰富等特点而备受青睐。早在几年前,伴随着GAN网络的兴起,卡通化就曾经风靡一时。而今,伴随着AIGC技术的兴起和不断发展,扩散生成模型为卡通化风格和提供了更多的创意和生成的可能性。本文就将详细介绍阿里开放视觉团队的卡通化技术实践。
GAN or 大模型?
当前的卡通化技术大多都以生成对抗网络(GAN)或者扩散模型作为基础的技术路线。而两者在卡通化生成任务上又各有优劣。GAN的最大优势在于速度和效率以及对原图的保真度,其毫秒级别的出图时间能够满足大部分端侧用户的需求,生成效果也相对稳定可控,相关技术总结见https://developer.aliyun.com/article/1308610。而扩散模型基于其庞大的参数规模和训练数据量,具有更强的生成和重绘能力,出图质量高,细节更为丰富,场景和内容的可拓展性也更强。本文接下来将着重介绍在大模型领域的卡通化实践。
用大量数据精调卡通化大模型
扩散生成模型常常在广泛的图像数据进行训练,使其能够生成各种风格和类型的图像,如写实人像和风景等。而我们希望卡通化的基础模型能够更专注于各种卡通类型的图像生成。因此,在扩散生成模型中使用精美的卡通领域数据进行模型的精细调整,不仅可以提高卡通化效果的贴近感和还原度,还可以生成更加精美的卡通图像。通过精调训练,扩散生成模型能够对特定域数据进行更加深入的研究和理解,可以更好地模拟和再现卡通画风的细节和风格。例如,对于人物卡通化,通过对特定域数据中的卡通角色特征的训练,可以更好地保留并突出人物的个性特点和表情。而对于场景卡通化,可以根据特定域数据中的卡通场景细节,提升色彩、线条、纹理等细节,使卡通化效果更加贴合目标画面。经过大量数据的精调,可以获得能够生成更贴切卡通化图像的基础图生图扩散大模型,为专属风格的定制以及原图ID的保持建立基础,从而带来更加真实的卡通化体验。
用少量数据定义自己的卡通化专属风格
在卡通化的技术实践中,为了突出风格的鲜明程度和不同风格间的差异性,往往需要为每一种风格定制专属的模型,而完整训练或者finetune扩散模型往往需要上万量级的数据量和较大的GPU资源。为了实现这一点,LoRA模型的训练成为了最佳选择[1]。训练LoRA模型仅需要几十到上百张的相同风格图片作为训练数据,而finetune的参数也仅仅包括CLIP text encoder和UNet中的cross attention层,极大地减少了训练所需成本。

为了达到理想的finetune效果,LoRA模型的训练也有需多值得注意的训练技巧:
-
训练数据除了需要具有相同的风格类型,还需要保持尽可能丰富的语义信息。例如训练二次元人物的LoRA,数据需要尽量覆盖不同性别、年龄段、角度和姿势的二次元人物。
-
训练数据需要精细化的文字打标。当前较为流行的自动化标注模型包括了BLIP、BLIP2、DeepDanbooru等。需要注意的是,除了打标模型对画面内容的描述外,添加目标风格或者ID的关键词会对风格属性的强化有较大的帮助。
-
LoRA模型的训练需要搭配相近风格的基模,同时训练迭代次数不宜过大,一般根据训练数据量设置在10-100epoch。
-
多个LoRA模型的权重混合往往会有出其不意的效果。例如将人物和背景LoRA进行混合可以实现人物和背景的完美融合。人物和面部LoRA的混合则可以提升任务面部的美观和精致程度。
利用可控生成技术保留人物ID
可控生成图像技术近期取得了巨大的突破,而可控生成技术对卡通化而言也具有不可或缺的意义。为了保留原图的一些细节(如人物的相似性、场景的相似性等),并使用户感受到“这是『我』的卡通化照片”而非仅仅是一张无关的卡通化图像,我们就需要使用可控图像生成技术来保证卡通化前后的图像之间的相似性。本文使用Prompt-to-Prompt、ControlNet、T2I Adapter等技术进一步提升了生成图像的可控性。下面将介绍这些技术的原理和应用,以及如何使用它们来生成个性化和可控的图像。
Prompt-to-Prompt
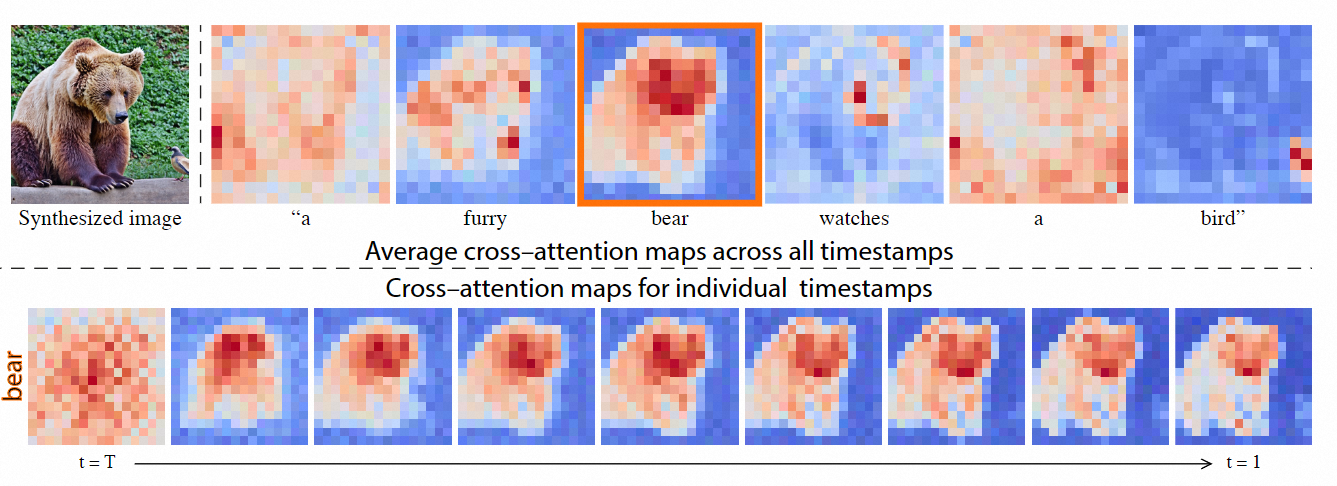
该方法发现了文本到图像扩散模型中交叉注意力层的强大功能。下图展示了这些高维层具有可解释的空间映射。这些空间映射在将文本提示单词与合成图像的空间布局联系起来方面发挥了关键作用[2]。因此,通过在注入源注意力图的同时向提示文本中添加卡通化风格描述,我们可以以新的卡通化风格创建各种图像,而保留原始图像的结构和ID。
提示文本与注意力图的关系:
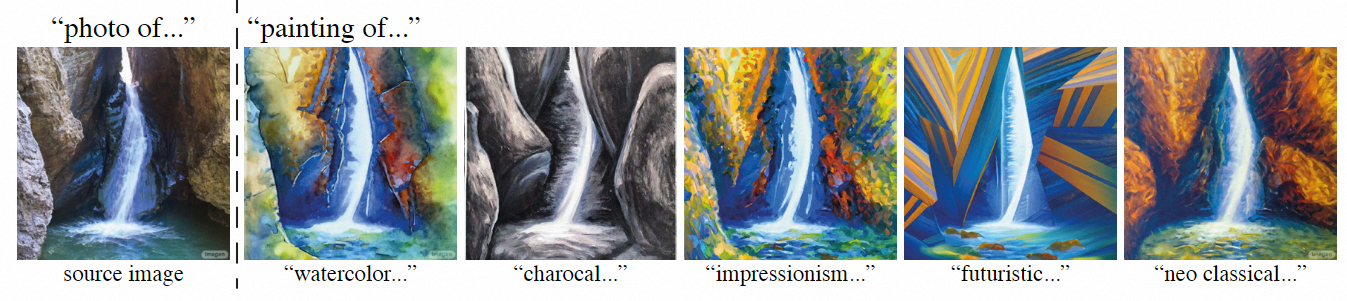
用Prompt-to-Prompt进行卡通化:
ControlNet
ControlNet可以用于控制预训练的大型扩散模型以支持额外的输入条件,这将使得我们在生成卡通化图像的同时能够以原图的某些信息(如深度信息、边缘信息等)作为控制条件以引导图像的生成过程。ControlNet的结构如下图所示,ControlNet将大型扩散模型的权重克隆为“可训练副本”和“锁定副本”:锁定副本保留了从数十亿张图像中学习到的网络能力,而可训练副本可在特定任务的数据集上进行训练以学习条件控制[3]。
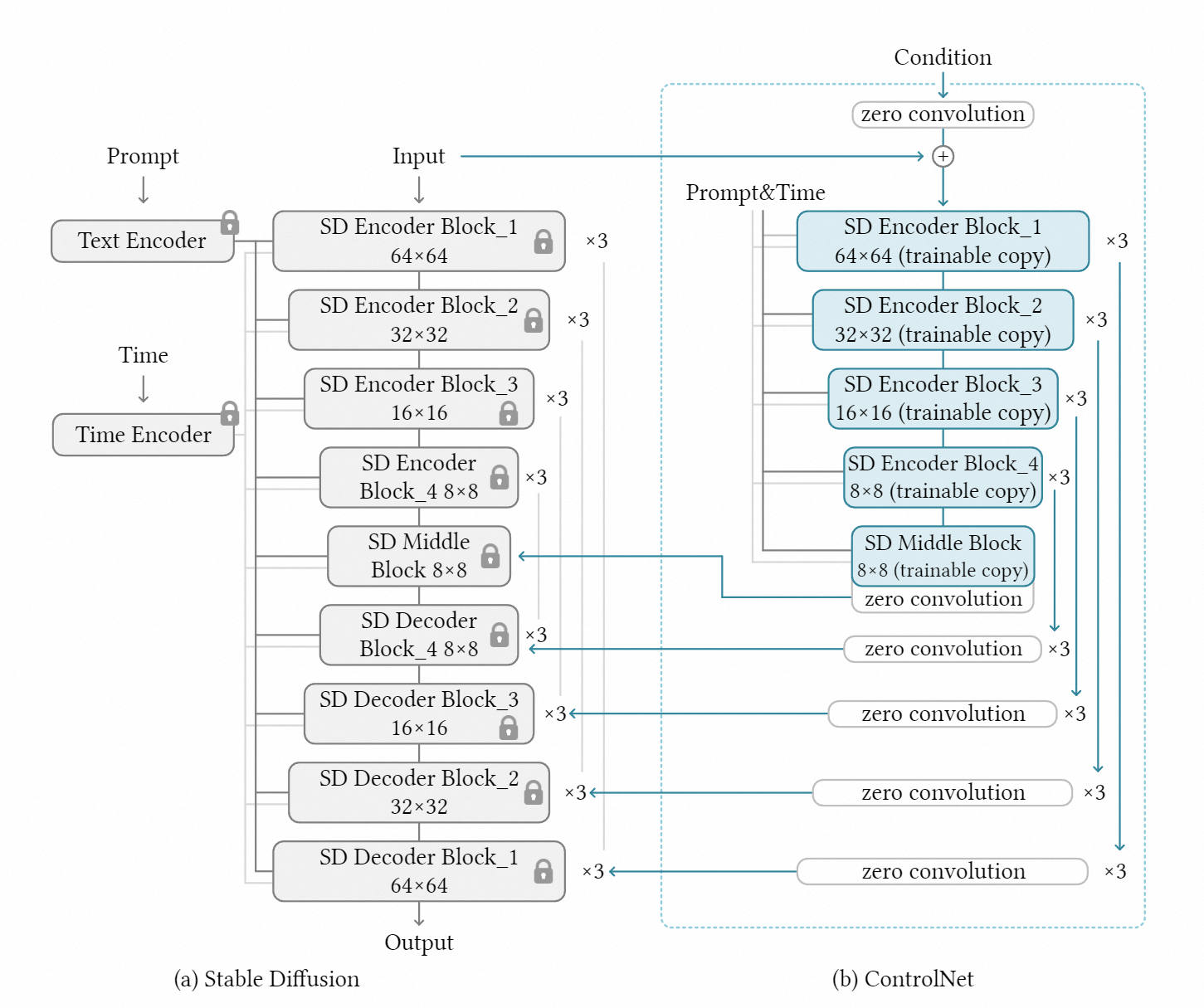
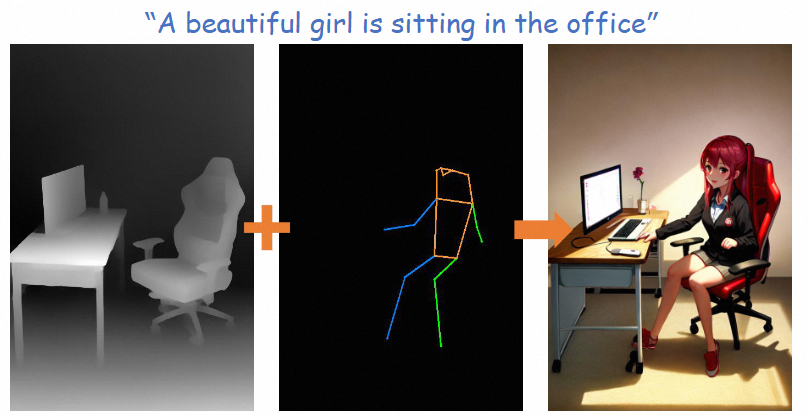
示例:使用ControlNet中的深度图控制生成卡通化图像[3]:

T2I Adapter
与ControlNet相似,T2I Adapter是一个简单而小型的模型,其可以在不影响原始网络拓扑结构和生成能力的情况下,为预训练的文本到图像模型提供额外的指导,其网络结构如下图所示[4]。
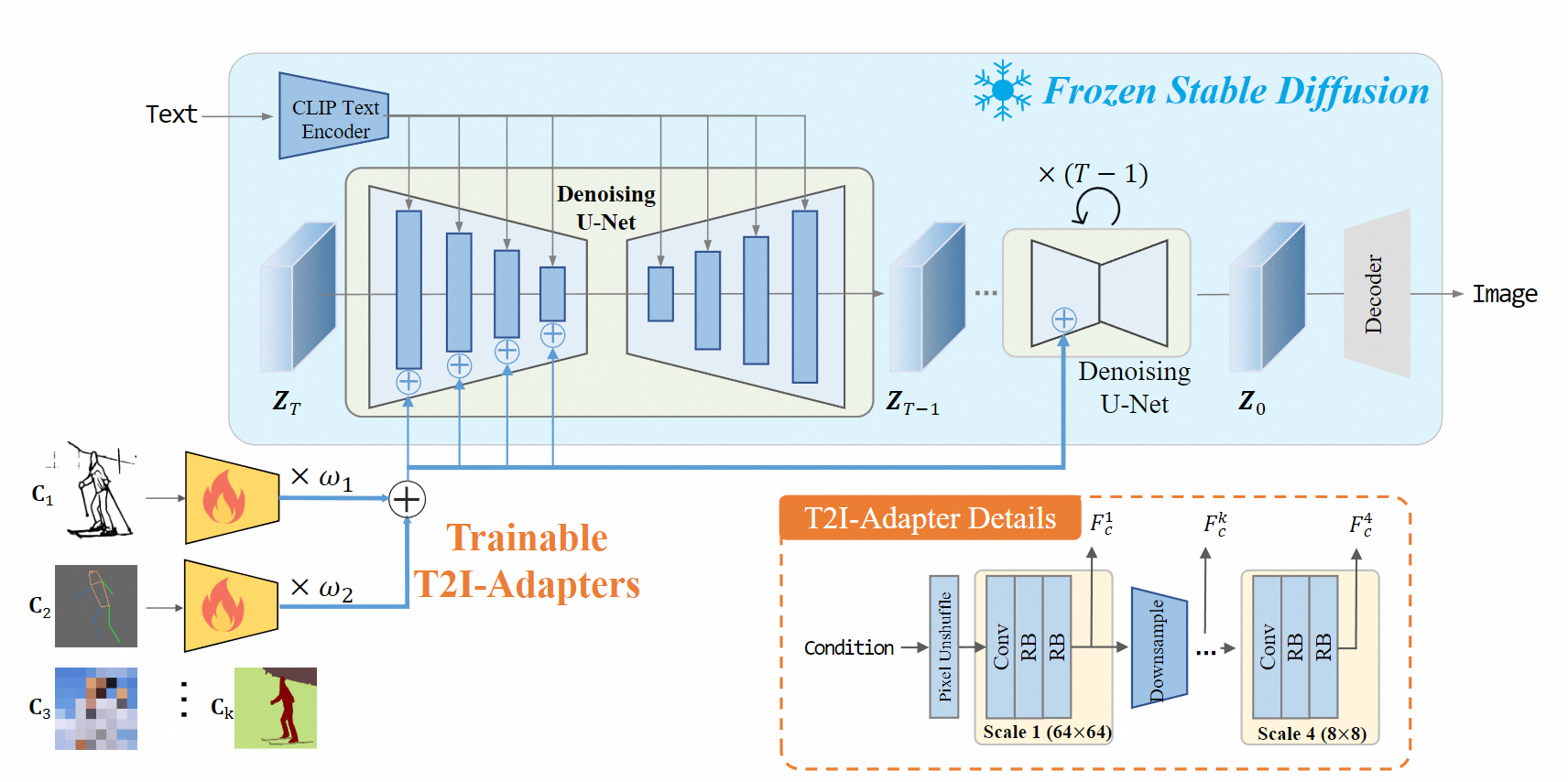
利用T2I Adapter进行卡通化实践[4]:
从技术研发到应用实践
当前,得益于以webui为代表的大模型可视化编辑工具,每个人都可以完成简单的卡通化上手实践,通过不断的调参和尝试,生成让自己满意的卡通图像。然而从模型推理出图到标准化产品的落地,仍然有很长一段路要走:
-
标准化产品不可能要求用户自己做精细化的prompt定制和参数调节。这就要求需要在算法内部形成一套有效的参数和prompt生成系统,来覆盖不同类型的输入。
-
标准化产品需要保证生成结果的下限,stable diffusion虽然可以生成诸多具有惊艳效果的图片,但其始终具有生成效果不稳定的特点。在一些小人脸、脸部遮挡、手指等场景下很容易出现瑕疵。因此必须要对生成过程加以约束来提升出图率。
-
stable diffusion的出图效率目前基本是秒级,提升推理效率,降低成本同样是产品落地过程中极为重要的一环。
效果展示
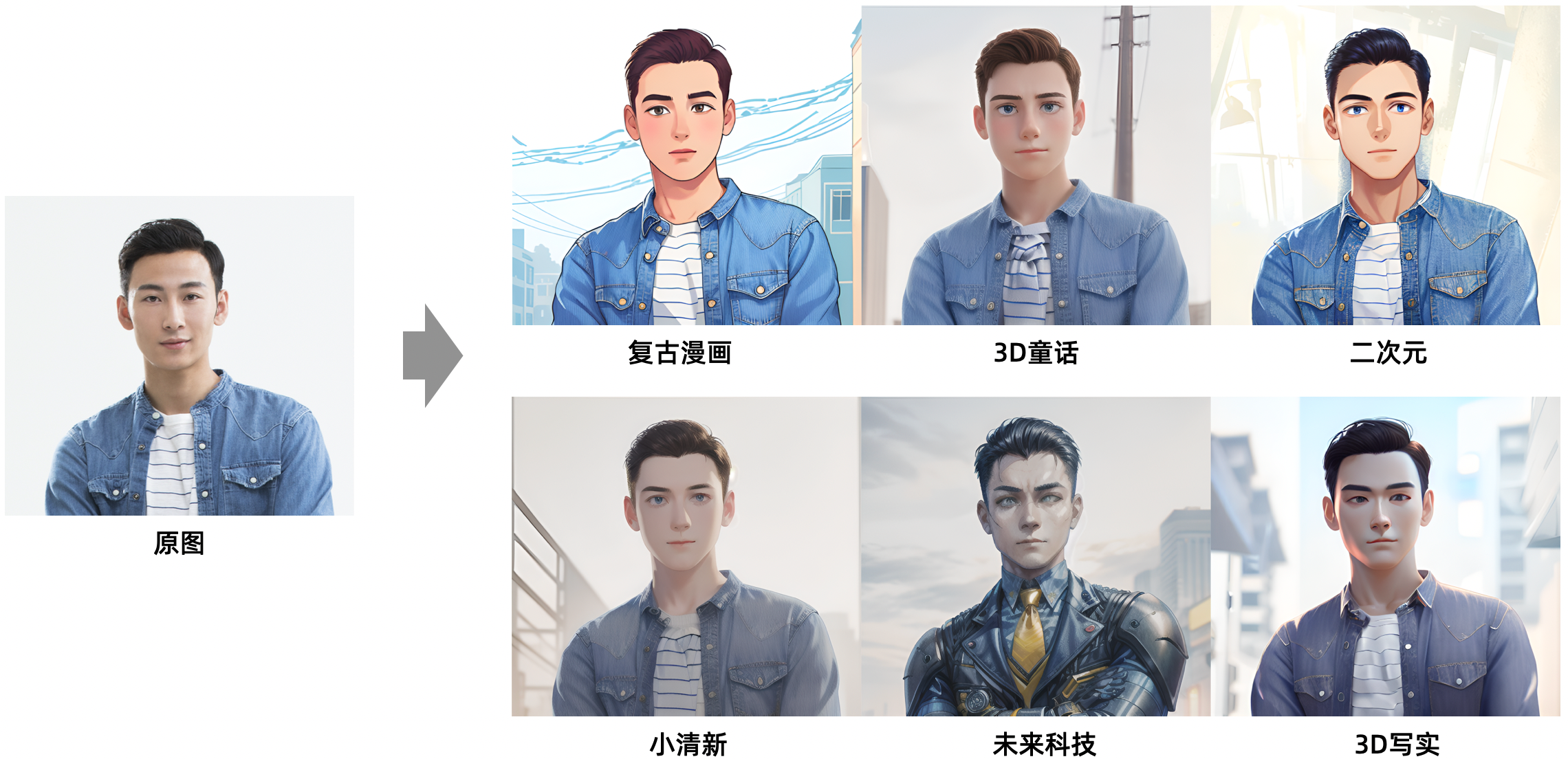
更多风格试用及快速接入
视觉智能开放平台—生成式图像卡通化
NEW: 人像风格重绘API详情
参考文献
[1]. Hu, Edward J., et al. "Lora: Low-rank adaptation of large language models." arXiv preprint arXiv:2106.09685 (2021).
[2]. Hertz, Amir, et al. "Prompt-to-prompt image editing with cross attention control." arXiv preprint arXiv:2208.01626 (2022).
[3]. Zhang, Lvmin, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." arXiv preprint arXiv:2302.05543 (2023).
[4]. Mou, Chong, et al. "T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models." arXiv preprint arXiv:2302.08453 (2023).