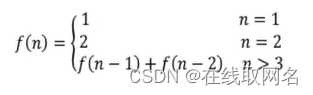文章目录
- 前言
- 一、分布式版本控制系统的理解
- 1.1 什么是分布式版本控制系统?
- 1.2 工作原理
- 1.3 分布式版本控制系统的优势
- 二、初识 Git 远程仓库
- 2.1 远程仓库的概念
- 2.2 Git 远程操作
- 2.3 远程仓库托管服务
- 三、新建远程仓库
- 四、克隆远程仓库到本地
- 4.1 使用 HTTPS 方式克隆
- 4.2 使用 SSH 方式克隆
- 4.3 查看克隆的仓库信息
- 五、向远程仓库推送
- 5.1 在本地仓库新增文件
- 5.2 推送本地文件至远程仓库
- 六、从远程仓库拉取
- 6.1 修改远程仓库的内容
- 6.2 从远程仓库上拉取
- 七、gitignore 文件
- 7.1 配置 gitignore 文件
- 7.2 推送忽略的文件
- 八、标签管理
- 8.1 什么是标签
- 8.2 标签的创建
- 8.3 查看标签信息
- 8.3 本地标签的删除
- 8.4 标签的推送
- 8.5 远程标签的删除
前言
版本控制系统是现代软件开发中不可或缺的工具,它有助于团队协作、代码管理和跟踪项目的演变历史。在版本控制系统中,分布式版本控制系统(DVCS)以其强大而灵活的特性成为开发者们的首选。本文将深入探讨分布式版本控制系统的工作原理和优势,帮助我们更好地理解和应用 Git,成为一名 Git 高手。
希望通过阅读本文的内容,将能够帮助我们更好地掌握 Git,轻松应对团队协作和版本控制的各种需求。
一、分布式版本控制系统的理解
版本控制系统是软件开发中至关重要的一部分,它有助于团队协作、代码管理和跟踪项目的演变历史。在版本控制系统中,分布式版本控制系统(DVCS)是一种强大而灵活的方法。本文将深入探讨分布式版本控制系统的工作原理和优势。
1.1 什么是分布式版本控制系统?
分布式版本控制系统(DVCS)是一种版本控制系统,与传统的集中式版本控制系统不同。在集中式版本控制系统中,所有的代码存储在一个中央服务器上,开发者通过与该服务器通信来获取和提交代码。而在DVCS中,每个开发者的本地环境都包含完整的代码版本库,不再依赖于中央服务器的实时连接。这意味着每个开发者都可以在本地独立工作,无需持续的网络连接。

1.2 工作原理
分布式版本控制系统的工作原理可以简单概括如下:
-
本地版本库: 每个开发者都在自己的计算机上拥有一个完整的版本库,包含项目的所有历史记录和文件。
-
独立工作: 开发者可以在本地工作区进行修改,添加新文件,删除文件等操作,而无需与中央服务器交互。
-
提交变更: 当开发者完成一部分工作,他们将其变更提交到自己的本地版本库中,形成一个新的版本。
-
分支和合并: 开发者可以创建分支(branch)来独立开发某个功能或修复某个 bug。分支的合并(merge)操作允许将不同分支的更改合并到主分支或其他分支中。
-
远程协作: 开发者可以选择与其他开发者分享自己的代码变更。这可以通过将本地版本库的更改推送(push)到远程仓库来实现。远程仓库通常位于中央服务器上,但也可以是其他开发者的计算机。
-
同步更新: 开发者可以从远程仓库获取(pull)其他人的更改并将其合并到自己的本地版本库中,以保持代码的最新状态。
1.3 分布式版本控制系统的优势
使用分布式版本控制系统带来了许多优势:
-
离线工作: 开发者可以在没有网络连接的情况下继续工作,因为每个人都拥有本地版本库。
-
安全性: 每个本地版本库都是完整的,即使某个开发者的计算机损坏,其他人仍然可以保持其代码的完整性。
-
高效分支管理: 分支和合并操作变得更加容易和灵活,支持并行开发多个功能或修复多个 bug。
-
协作灵活性: 开发者之间可以直接交换更改,无需依赖中央服务器。这对于开源项目和分散的团队尤其有用。
-
备份和恢复: 每个本地版本库都可以被视为一个备份,如果需要,可以轻松恢复历史版本。
总之,分布式版本控制系统是现代软件开发的不可或缺的工具之一,它提供了更强大的版本控制和协作能力,使开发团队更加灵活和高效。通过理解其工作原理和优势,开发者可以更好地利用分布式版本控制系统来管理和跟踪项目的代码。
二、初识 Git 远程仓库
Git 是一款强大的分布式版本控制系统,它允许同一个 Git 仓库分布到不同的机器上。但是,你可能会问,我只有一台电脑,如何体验远程仓库呢?实际上,即使只有一台电脑,你也可以克隆多个版本库,只要它们不在同一个目录下。但这在实际应用中很少见,因为没有必要在一台电脑上创建多个远程库,而且存在硬盘挂了导致所有库丢失的风险。因此,让我们来了解如何使用远程库,即在多台机器上协同工作。
2.1 远程仓库的概念
远程仓库是位于其他地方的 Git 仓库,它可以在不同的机器上,不同的位置上,甚至在不同的网络上。远程仓库的存在让多人协同开发成为可能,它是代码共享和协作的基础。
2.2 Git 远程操作
Git 远程操作包括以下关键概念:
-
克隆(Clone): 克隆操作允许你将远程仓库的内容复制到本地计算机上,创建一个本地版本库。这个本地版本库是远程库的副本,可以用于本地开发和修改。
-
推送(Push): 推送操作允许你将本地版本库的更改上传到远程库中,以便其他开发者可以访问和合并这些更改。
-
拉取(Pull): 拉取操作允许你从远程库中获取最新的更改并将它们合并到本地版本库中,保持本地代码与远程代码同步。
2.3 远程仓库托管服务
要搭建自己的 Git 远程仓库服务器是可行的,但通常不是必要的,尤其在学习阶段。幸运的是,有许多在线托管服务可以免费提供 Git 远程仓库。其中,GitHub 是最知名的国际服务,而 码云(Gitee)则是国内用户常用的选择。
这些托管服务允许我们轻松创建远程仓库,与其他开发者协作,跟踪项目的进展,并提供一系列工具和功能来管理代码。只需注册一个账号,就可以在这些平台上创建自己的远程仓库,无需担心搭建服务器或复杂的配置。
在接下来的博客中,我将以 码云(Gitee) 为例,从零开始学习如何使用远程仓库,包括创建远程仓库、克隆远程仓库到本地、推送更改到远程仓库以及从远程仓库拉取更新。
三、新建远程仓库
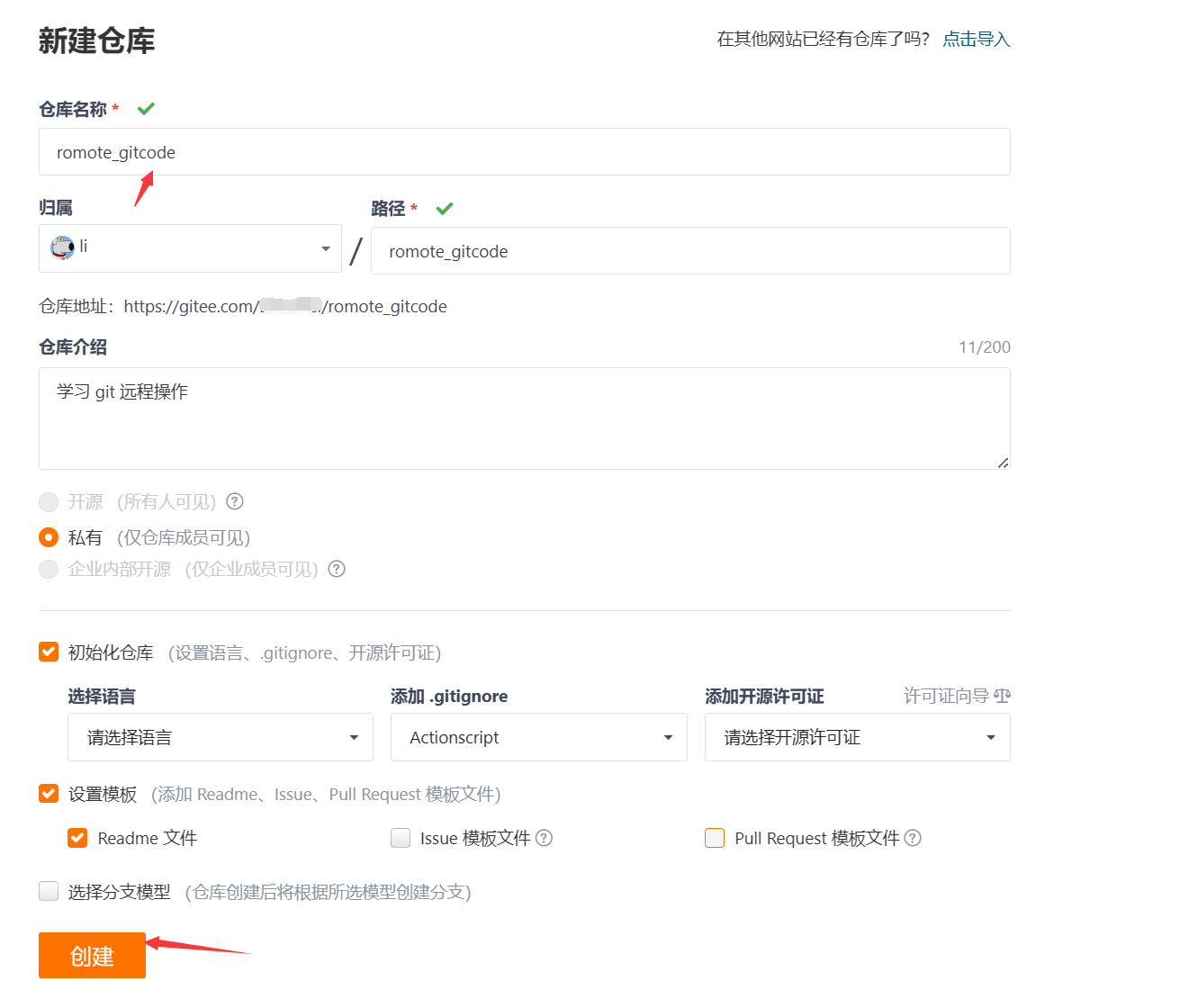
要在码云上新建远程仓库,首先我们需要注册一个账号,这点是毋庸置疑的,当有了账号之后,就可以新建远程仓库了。
填写仓库的基本信息:
创建成功:

从创建好的远程仓库中我们便能看到,之前在本地学习过的分支,也存在于远程仓库中并被管理起来了。刚创建的仓库有且只有一个默认的master分支。

四、克隆远程仓库到本地
克隆远端仓库到本地,需要使用 git clone 命令,后面跟上我们的远端仓库的链接地址,远端仓库的链接可以从仓库中找到:选择“克隆/下载”获取远程仓库链接。

可以发现有多种不同协议的克隆/下载地址,其中 SSH 协议和 HTTPS 协议是 Git 最常使用的两种数据传输协议。
- SSH 协议使用了公钥加密和公钥登陆机制,体现了实用性和安全性,使用此协议需要将公钥放到服务器上,由 Git 服务器进行管理。
- 而使用 HTTPS 的方式时,没有要求,可以直接克隆下来,因此更加简单。
下面是使用两种不同协议进行克隆的演示。
4.1 使用 HTTPS 方式克隆

注意,此处克隆是叫我们输入的 Username 一般是填注册码云时的邮箱地址。
4.2 使用 SSH 方式克隆
如果尝试直接进行克隆:

可以发现,使用 SSH 方式克隆仓库,由于我们没有添加公钥到远端库中,服务器拒绝了我们的 clone 请求。因此,首先需要我们设置一下公钥:
第一步:创建 SSH Key
在当前用户的主目录下,看看有没有 .ssh目录,如果有,再看看这个目录下有没有 id_rsa(私钥) 和 id_rsa.pub(公钥) 这两个文件,如果已经有了,可直接跳到下一步。如果没有,需要创建 SSH Key,使用到了命令是 ssh-keygen -t rsa -C "注册码云的邮箱":
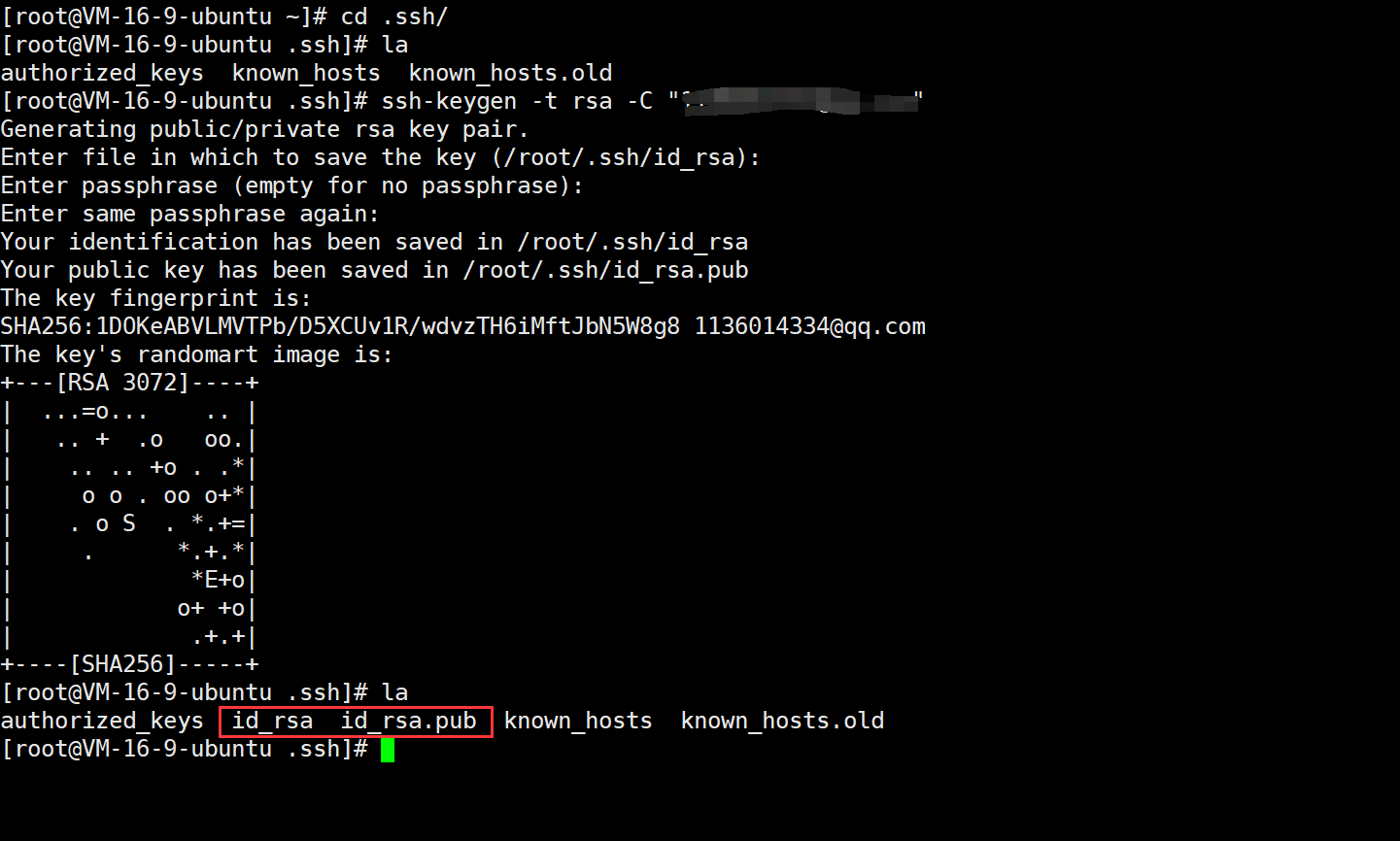
此时创建成功了,可以在.ssh 目录下看到有了 id_rsa 和 id_rsa.pub 两个文件,这两个就是 SSH Key 的秘钥对,id_rsa 是私钥,不能泄露出去, id_rsa.pub 是公钥,可以放心地告诉任何人。
第二步:添加自己的公钥到远端仓库
进入码云的设置:
选择安全设置中的 SSH 公钥:

将上面生成的 id_rsa.pub 中的内容一字不落的复制粘贴进去即可,此时就完成了远端公钥的配置了。
此时,再次进行克隆操作,发现就能成功克隆远程仓库到本地了。

如果有多个人协作开发,GitHub/Gitee 都允许添加多个公钥,只要把每个人的电脑上的 Key 都添加到 GitHub/Gitee 上,就可以实现每台电脑都能往 GitHub/Gitee 上提交推送了。
4.3 查看克隆的仓库信息
当我们从远程仓库克隆后,实际上 Git 会自动把本地的 master 分支和远程的 master 分支对应起来,并且远程仓库的默认名称是origin 。在本地我们可以使用 git remote 命令,来查看远程库的信息,如:

或者,使用 git remote -v 显示更详细的信息:
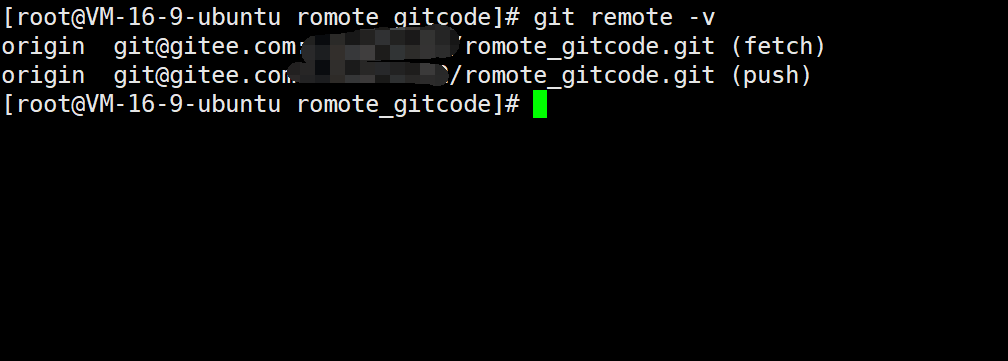
上面显示了可以抓取和推送的 origin 的地址。如果没有推送权限,就看不到 push 的地址。那么推送是什么意思呢,我们继续往下看。
五、向远程仓库推送
5.1 在本地仓库新增文件
本地已经成功克隆远程仓库后,我们便可以向仓库中提交内容,例如新增一个 file.txt 文件:

此时,使用 vim 新增并编辑了 file.txt 文件,然后使用 add 和 commit 命令将其储存到了本地版本库中,如果此时使用 git status 命令:
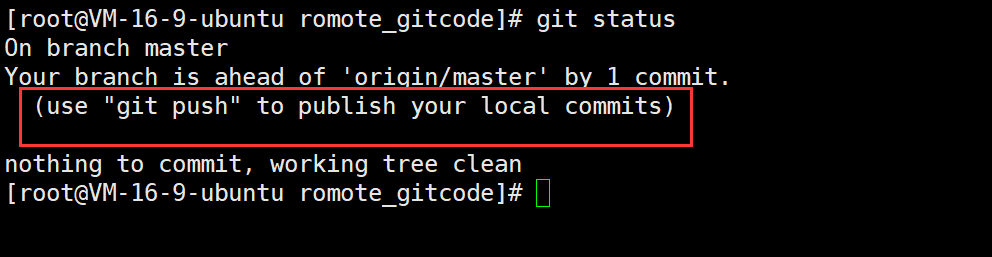
可以看到,提示我们使用 push 命令将其推送至远程仓库。
另外提交时要注意,如果我们之前设置过全局的 name 和 email,这两项配置需要和当前码云上配置的用户名和邮箱一致,否则会出错;如果从来没有设置过全局的 name 和 email,那么我们第一次提交时也会报错,这就需要我们重新配置下了。
5.2 推送本地文件至远程仓库
到这里我们已经将内容提交至本地仓库中,如何将本地仓库的内容推送⾄远程仓库呢,就需要使用 git push 命令,该命令用于将本地的分支版本上传到远程并合并,命令格式如下:
git push <远程主机名> <本地分⽀名>:<远程分⽀名>
# 如果本地分⽀名与远程分⽀名相同,则可以省略冒号 `:`
git push <远程主机名> <本地分⽀名>
此时我们要将本地的 master 分支推送到 origin 主机的master 分支,则可以:

推送成功!这里由于我们使用的是 SSH 协议,是不用每一次推送都输入密码的,方便了我们的推送操作。如果使用的是 HTTPS 协议,如果不进行额外的设置,可能每次推送都必须输用户名和密码了。
查看码云上的远程仓库,发现就推送成功了。

六、从远程仓库拉取
在实际开发过程中,往往是多个开发人员协同进行开发,如果某个开发人员向远程仓库中提交了新的代码,那么此时自己的本地仓库上的内容就和远程仓库上的内容不同了,因此就需要从远程仓库重新拉取。
6.1 修改远程仓库的内容
此时,可以通过修改远程仓库上 file.txt 文件的内容,来模拟其他开发人员向远程仓库推送新的代码:
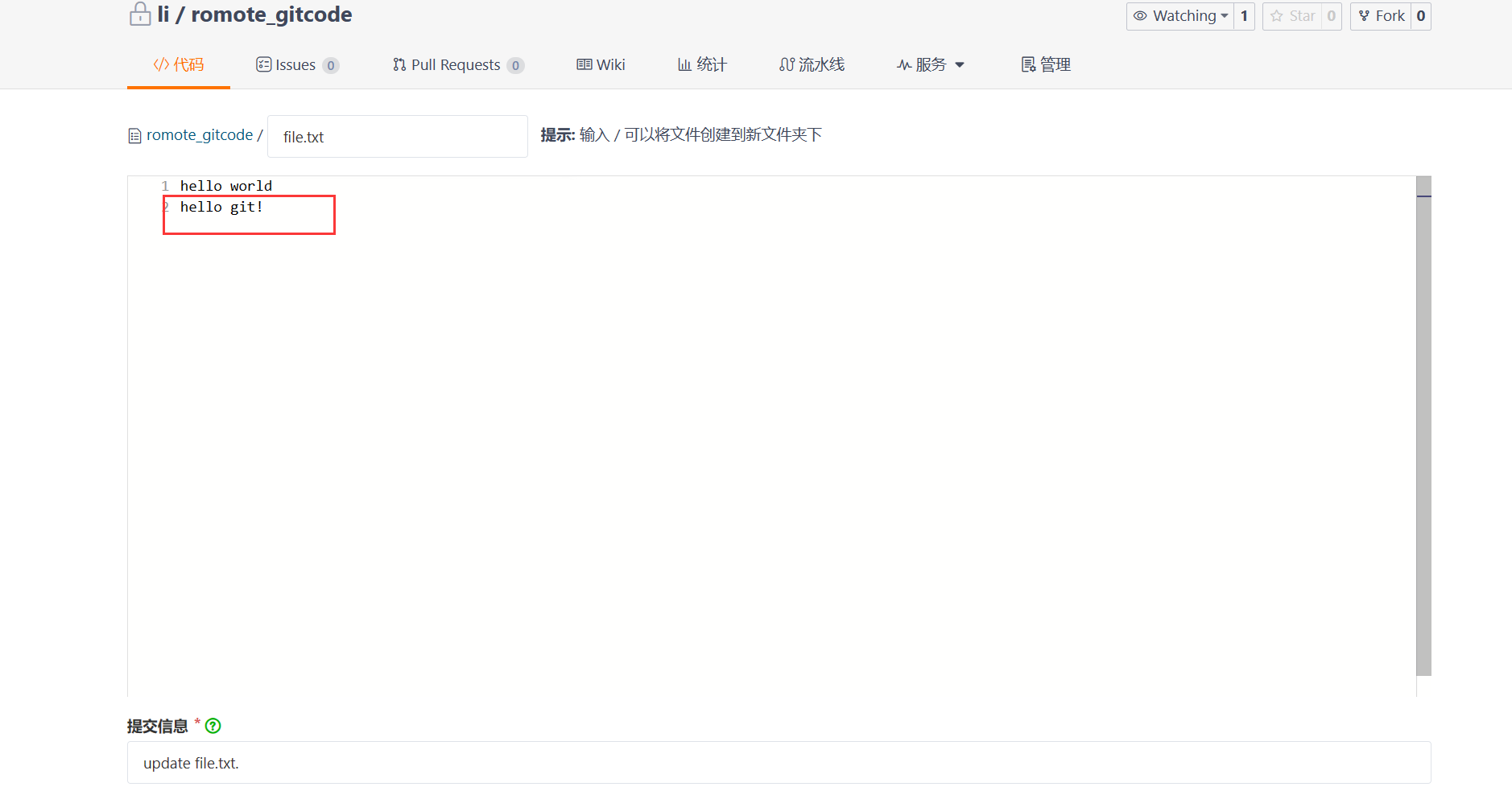
此时,远程仓库是要领先于本地仓库一个版本,为了使本地仓库保持最新的版本,我们需要拉取下远端代码,并合并到本地。
6.2 从远程仓库上拉取
Git 提供了 git pull 命令,该命令于于从远程获取代码并合并本地的版本。格式如下:
git pull <远程主机名> <远程分⽀名>:<本地分⽀名>
# 如果远程分⽀是与当前分⽀合并,则冒号后⾯的部分可以省略。
git pull <远程主机名> <远程分⽀名>
例如,拉取远程仓库中的代码:
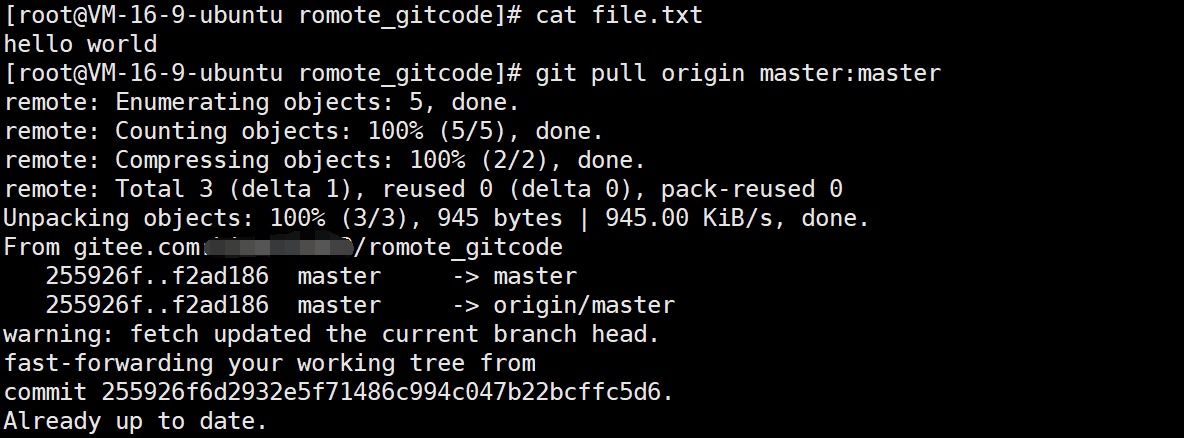
再次查看 file.txt 文件,发现和远程仓库的内容一样了。

七、gitignore 文件
在日常开发中,我们有些文件不想或者不应该提交到远端,比如保存了数据库密码的配置文件,那怎么让 Git 知道要忽略哪些文件呢?在Git 工作区的根目录下创建⼀个特殊的 .gitignore 文件,然后把要忽略的文件名填进去,Git 就会自动忽略这些文件了。
7.1 配置 gitignore 文件
一般都不需要我们自己创建 .gitignore 文件,因为在码云上创建远程仓库的时候,如果我们勾选了添加 .gitignore 选项都会我们自动生成:
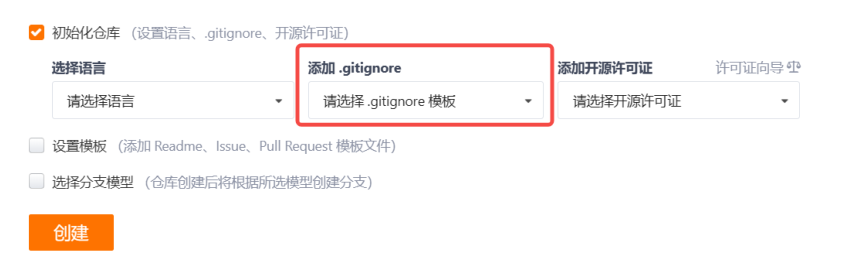
如果当时没有选择这个选项,在工作区创建一个也是可以的。无论哪种方式,最终都可以得到一个完整的 .gitignore 文件,例如我们想忽略以 .so 和 .ini 结尾的所有文件,.gitignore 的内容如下:
# 省略选择模本的内容
...
# My configurations:
*.ini
*.so
另外,在 .gitignore 文件中也可以指定某个确定的文件或者文件夹,表示忽略这个文件或者文件夹下所有的内容。
最后一步就是把 .gitignore 也提交到远端,就完成了对 .gitignore 文件的配置了:
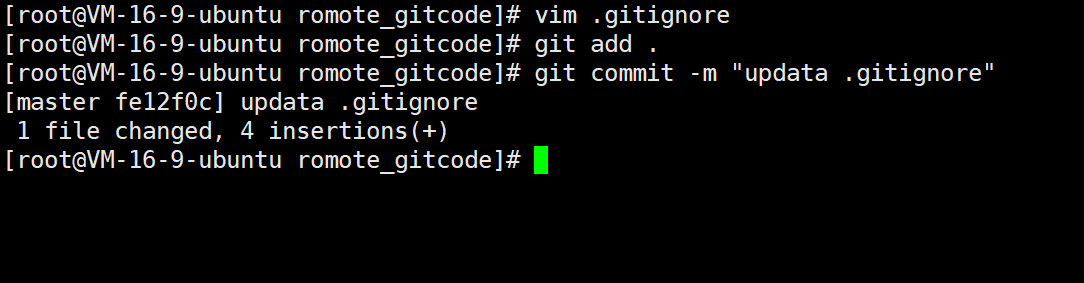
例如,此时再在工作区上创建 test.so 文件,看看 Git 是否对其进行了追踪管理。

使用 git status 命令发现,工作区还是干净的,说明成功忽略了 test.so 文件。
7.2 推送忽略的文件
- 有些时候,我们可能想要添加⼀个文件到 Git,但由于这个文件被
.gitignore忽略了,根本添加不了,那么可以用-f选项强制添加:
git add -f [filename]
- 或者我们发现,可能是
.gitignore写得有问题,需要找出来到底哪个规则写错了,比如说test.so文件是要被添加的,此时可以用下面的命令进行检查:
git check-ignore -v [filename]
例如:

此时,就可以找到 test.so 被忽略的原因了。
- 还有些时候,当我们编写的规则排除了
.*类型的所有文件,例如:
# 排除所有.开头的隐藏⽂件:
.*
但是我们发现 .* 这个规则把 .gitignore 也排除了。虽然可以用 git add -f 强制添加,但是总是显得不那么优雅,破坏 .gitignore 的规则,这个时候,可以添加一条例外规则:
# 排除所有.开头的隐藏⽂件:
.*
# 不排除.gitignore
!.gitignore
把指定文件排除在 .gitignore 规则外的写法就是 ! + 文件名。所以,只需把例外文件添加进去即可。
八、标签管理
8.1 什么是标签
在 Git 中,标签(Tag)是对某次 commit 的一个有意义的标识,可以看作是为特定的 commit 起了一个别名。标签的主要作用是标识项目中的重要版本、里程碑或发布版本,让人们更容易理解和记住。
标签的意义:
为什么要使用标签呢?相对于那一长串难以记忆的 commit id,标签提供了以下重要好处:
-
易于记忆和使用: 标签通常使用有意义的名字来表示版本,例如 “v1.0”,“Release-2.1”,或者 “Beta”。这使得开发者和团队更容易记住和使用标签,而不是需要记住一长串的哈希值。
-
版本管理: 标签是版本管理的有力工具。当项目需要发布一个新版本或者重要的里程碑时,可以为相关的 commit 创建一个标签,以便随时找到并访问这个特定版本的代码。
-
易于回退: 当需要回退到某个特定版本时,可以直接使用标签来定位,而不必记住 commit id。这极大地简化了版本切换的过程。
-
可读性和清晰性: 标签的名字可以传达版本的信息,例如是否是正式版、修复了哪些问题、添加了哪些功能等。这有助于团队成员更好地理解版本的含义。
标签是 Git 中用于标识重要版本和里程碑的有力工具。它们提供了更易于记忆和使用的方式来定位特定的 commit,使版本管理和协作更加高效和清晰。
8.2 标签的创建
在 Git 中打标签非常简单,首先切换到需要打标签的分支上:

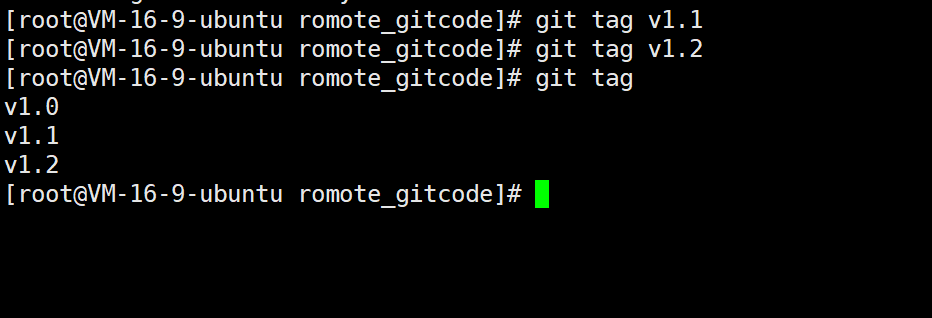
然后,使用命令 git tag [name] 就可以打一个新标签了:

可以使用命令 git tag 来查看所有的标签:
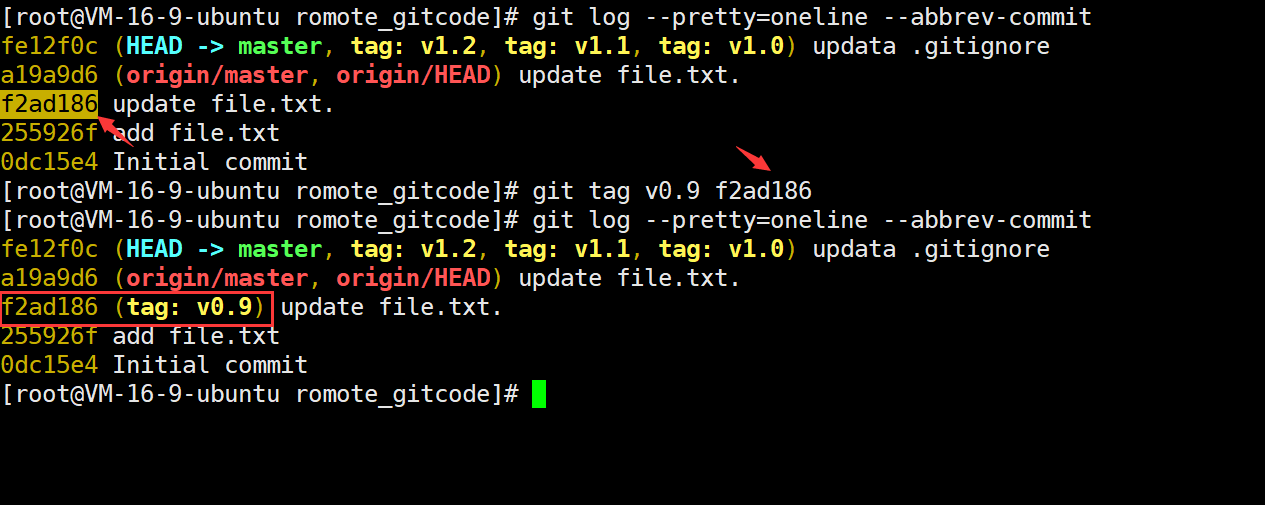
默认标签是打在最新提交的 commit 上的。那如何在指定的 commit 上打标签呢?方法是找到历史提交的 commit id,然后使用下面的命令打上标签就可以了:
git tag [name] [commit id]
例如下面的例子:
8.3 查看标签信息
使用 git tag 查看标签的信息,可以发现并不是按时间顺序列出的,而是按字母顺序排序的。

另外,可以用 git show [tagname] 查看标签的信息:
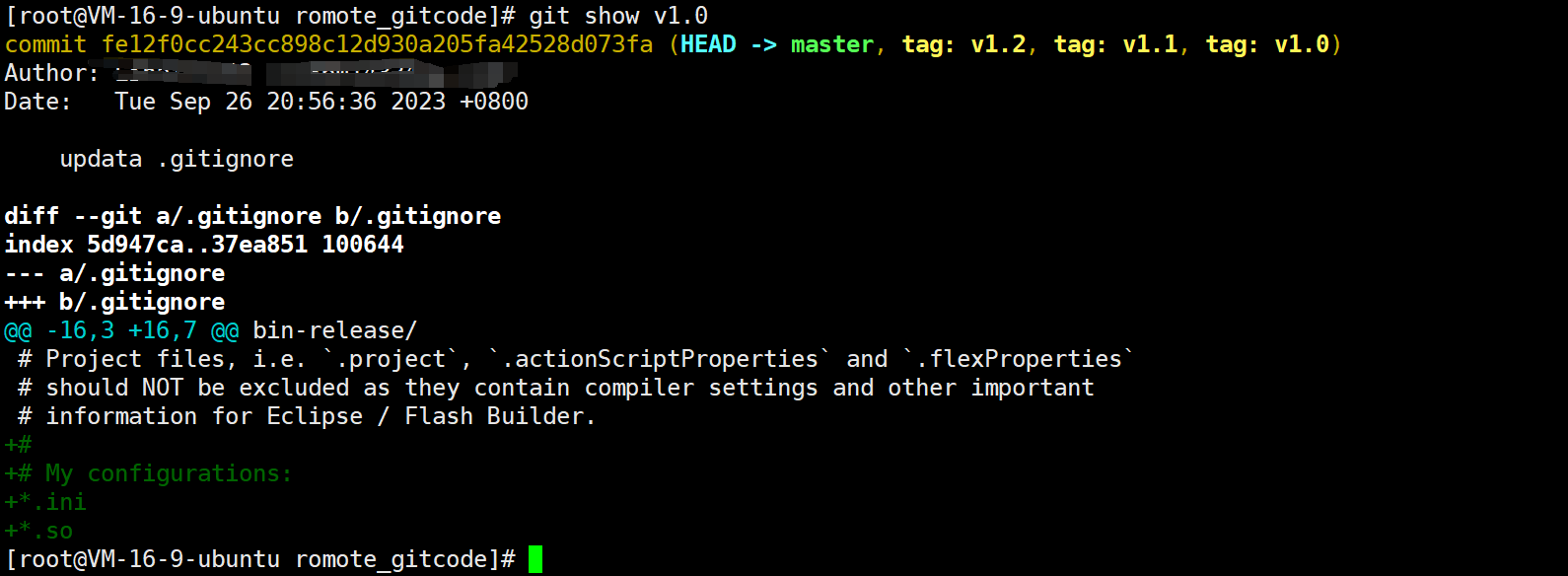
此时,列出了对应 commit 时的所有信息。
不仅如此,Git 还提供可以创建带有说明的标签,使用 -a 指定标签名,-m 指定说明文字,格式为:
git tag -a [name] -m "XXX" [commit_id]
打完标签之后,使用 tree .git 命令查看本地库的变化:
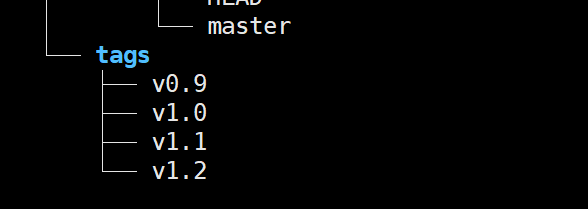
可以发现 tags 目录下存放的就是刚刚打的标签。
如果查看某个标签的内容,就可以发现,其实所谓的标签就是保存了一下 commit id:

8.3 本地标签的删除
如果标签打错了,也可以对标签进行删除,删除标签使用的命令:
git tag -d [tagname]
例如,删除 v1.1、v1.2 标签:
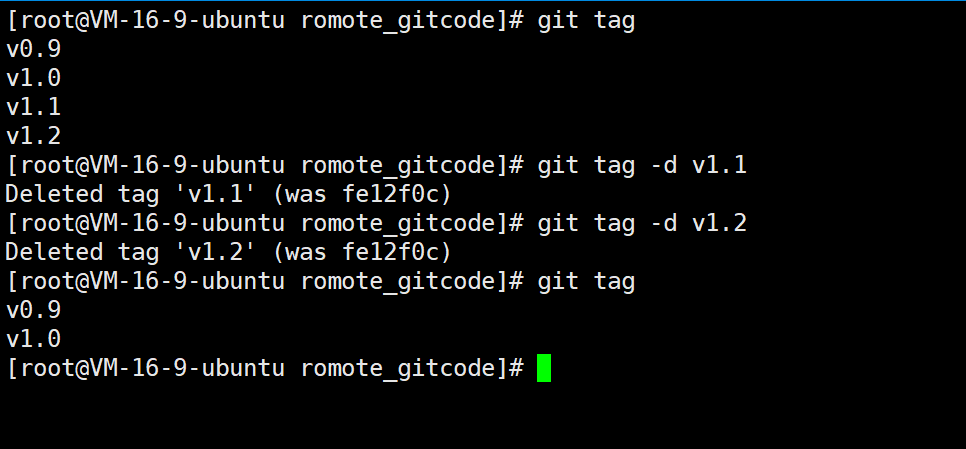
之所以能够删除标签,是因为创建的标签都只存储在本地,不会自动推送到远程。所以,打错的标签可以在本地安全删除。
8.4 标签的推送
如果要推送某个标签到远程,需要使用的命令如下:
git push origin [tagname]
例如,推送 v1.0 和 v0.9 到远程仓库:
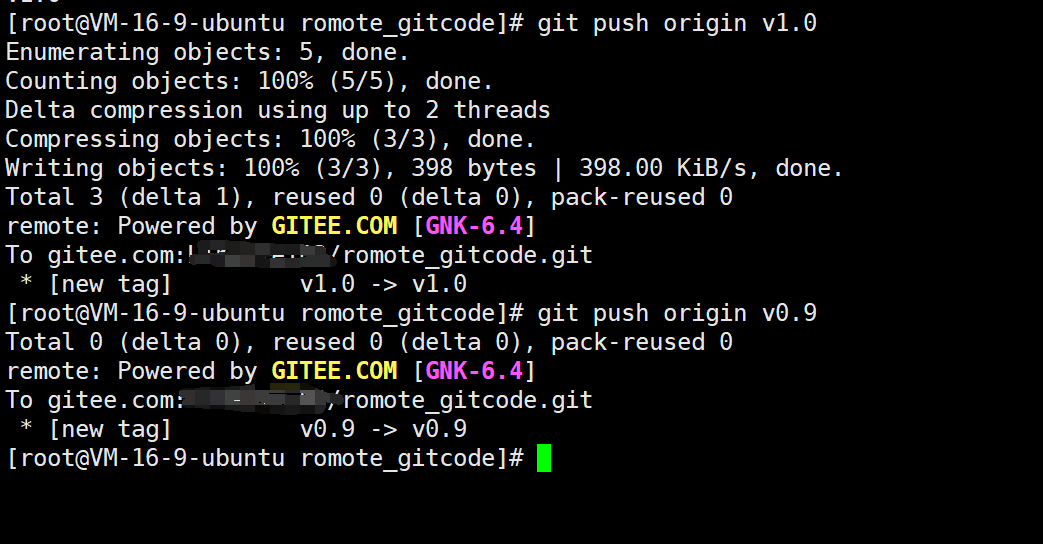
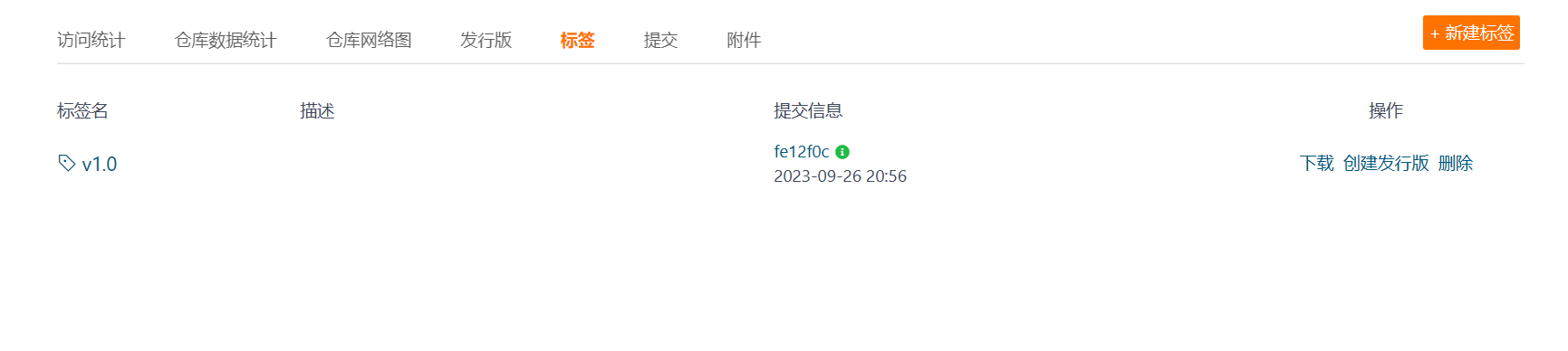
当推送标签成功之后,在远程仓库中就可以看到更新的标签了。
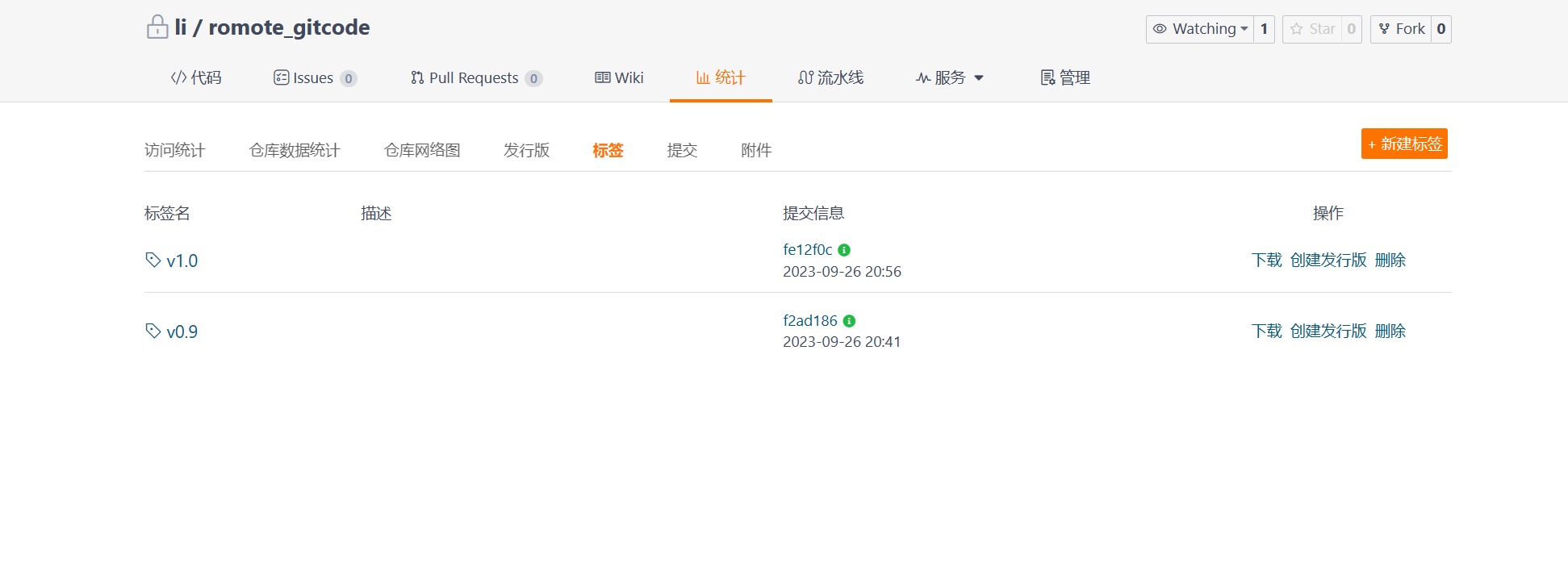
当然,如果本地有很多标签,也可以一次性的全部推送到远端:
git push origin --tags
8.5 远程标签的删除
如果标签已经推送到远程,要删除远程标签就麻烦一点,先从本地删除:

然后从远程删除。删除命令也是 push,但是命令的格式如下:
git push origin :refs/tags/[tagname]
例如:

再次查看远程仓库,可以发现标签成功删除了。