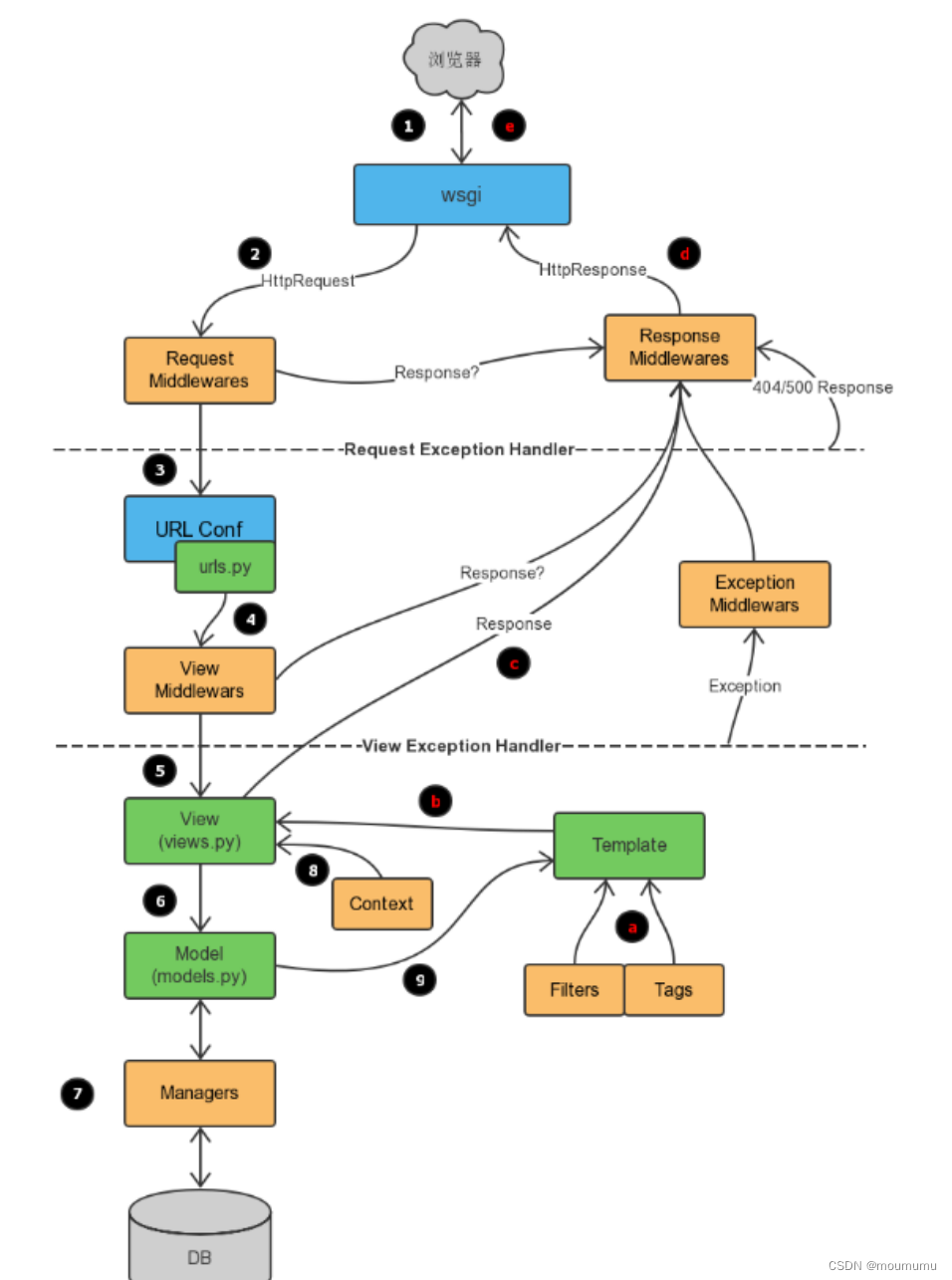
大纲
一、二叉树
二叉树:1.二叉树简介
二叉树:2.二叉树的性质
二叉树:3.二叉树的存储
二叉树:4.二叉树的遍历
二叉树:5.求解先序、后序、层次遍历序列
二叉树:6.例题二、二叉堆
二叉堆:1.二叉堆简介
二叉堆:2.二叉堆的插入操作
二叉堆:3.二叉堆的删除堆顶操作
二叉堆:4.二叉堆复杂度分析
二叉堆:5.二叉堆代码实现
二叉堆:6.优先队列
二叉堆:7.例题
二叉树
一、二叉树简介
(1)简介
二叉树是N个节点的有限集合(N是自然数),当N=0时,那么就是一个空集合(叫空二叉树)。
总的来讲(N>0的情况),二叉树就是由一个根节点和两棵子树组成的。
然而,从名字就可以看出来,二叉树的每一个节点最多都只有两棵子树(分别称为左子树和右子树)
(2)二叉树的形态(类别)
按照节点数分类:
空二叉树:
N=0
当这个集合的节点数为0时,称为空二叉树
只有一个根节点的二叉树:
N=1
需要满足的条件:集合的节点树为1
根节点只有左子树
需要满足的条件:根节点没有右子树,只有左子树
根节点只有右子树
需要满足的条件:根节点没有左子树,只有右子树
根节点左子树和右子树都有
需要满足的条件:根节点的左子树和右子树都有
按照形态分类:
常见二叉树形态 \color{blue}常见二叉树形态 常见二叉树形态
斜树
从名字就可以看出来,斜树是斜的,所以需要满足条件:
所有的节点都只有左节点或者右节点
斜树还分左斜树和右斜树,每个节点都只有左节点的叫做左斜树,每个节点都只有右节点的叫做右斜树
满二叉树
如果所有分支节点都存在左子树和右子树,并且所有叶子节点都在同一层上,这样的二叉树称为满二叉树
完全二叉树
如果编号为i(1 ≤ i ≤ N)的结点与同样深度的满二叉树中编号为i的节点在二叉树中位置完全相同,则这棵二叉树称为完全二叉树。
二、二叉树的性质
性质1:在二叉树的第i层上至多有2^(i-1)个节点
证明:设d(i)表示第i层的最大节点数
每个节点至多有两个子节点:d(i)=d(i-1)*2
第一层是根节点,只有一个节点,所以:d(1)=1=2^(1-1)
第i层的最大节点数d(i)=d(1)*2 ^ (i-1)=2 ^ (i-1)
性质2:深度为k的二叉树至多有2^k-1个节点
证明:设d(i)表示深度为i的二叉树的最大节点数
d(1)=1=2 ^ 1-1
d(2)=d(1)+2 ^ 1=2 ^ 1+2 ^ 1-1=2 ^ 2-1
d(3)=d(2)+2 ^ 2=2 ^ 2+2 ^ 2-1=2 ^ 3-1
d(k)=d(k-1)+2 ^ (k-1)=2 ^ (k-1)+2 ^ (k-1)-1=2 ^ k-1
性质3:一棵二叉树叶子节点数(设为n0)等于度为2的节点数(设为n2):
证明:
① 二叉树中除了叶子节点外,剩下的节点要么度为1,要么度为2。(叶子节点度为0),
那么二叉树的节点数 n = n0 + n1 + n2(式子1)。
② 度为1的节点拥有1个孩子,度为2的节点拥有2个孩子,孩子结点总数为: n1+ 2n2 。
③ 二叉树中,只有根节点不是孩子节点,所以: n = n1 + 2n2 + 1 (式子2 )。
根据式子1和式子2可知: n0 + n1 + n2 = n1 + 2n2 + 1 ⇒ n0 = n2 +1。
性质4:具有n个结点的完全二叉树的深度为log2(n)向下取整+1
证明:设完全二叉树的深度为k,需证明: k=floor(log2(n))+1
根据完全二叉树的定义可知:前k − 1层一定是满的。
根据二叉树的性质2可知:前k − 1 层结点数为2 ^ (k-1)-1
2 ^ (k-1)-1<n<=2 ^ k-1⇒2 ^ (k-1)<=n<2 ^ k
对上面的狮子两边取对数:k-1<=log2(n)<k
得出k是整数,所以k=floor(log2(n))+1成功证明
性质5:编号为k的节点的左节点等于2k,右节点等于2k+1
额…没啥好证的了
三、二叉树的存储
1.数组存储
我们可以通过二叉树的编号进行存储,tr[i]表示编号为i的节点的信息。
我们可以通过刚才的性质5,可以快速的得出编号为k的节点:
双亲(父节点)等于floor(k/2)
左节点等于2k
右节点等于2k+1
int trv[N];
void UpdateLeft(int p,int v)trv[p<<1]=v;//p<<1等效p*2
void UpdateRight(int p,int v)trv[p<<1|1]=v;//p<<1|1等效p*2+1,注意:s|1不一定等于s+1
并且在完全二叉树的时候非常节省空间。
但是在非完全二叉树的时候会比较浪费空间,所以我们就要引出新的存储方法——链表
2.链表存储
由于二叉树每个节点最多有两个孩子,所以我们可以为其设计一个链表来存储二叉树,这个链表叫二叉链表。
struct Edge{
int dat;
int LeftChild,RightChild;
}trv[N];
四、二叉树的遍历
先序遍历
先序遍历的规则是先根后左右
struct Edge{
int dat;
int LeftChild,RightChild;
}trv[N];
void Prnt(int idx){
cout<<trv[idx].dat<<' ';
}
void PreODR(int r){
if(!r)return;
Prnt(r); //根
PreODR(trv[r].LeftChild); //左
PreODR(trv[r].RightChild);//右
}
中序遍历
中序遍历的规则是先左后根右
struct Edge{
int dat;
int LeftChild,RightChild;
}trv[N];
void Prnt(int idx){
cout<<trv[idx].dat<<' ';
}
void PreODR(int r){
if(!r)return;
PreODR(trv[r].LeftChild);//左
Prnt(r); //根
PreODR(trv[r].RightChild);//右
}
后序遍历
后序遍历的规则是先左后右根
struct Edge{
int dat;
int LeftChild,RightChild;
}trv[N];
void Prnt(int idx){
cout<<trv[idx].dat<<' ';
}
void PreODR(int r){
if(!r)return;
PreODR(trv[r].LeftChild);//左
PreODR(trv[r].RightChild);//右
Prnt(r); //根
}
层次遍历
层次遍历就和图的bfs一样,就是按照层次和每一个层次里的顺序来遍历
struct Edge{
int dat;
int LeftChild,RightChild;
}trv[N];
void Prnt(int idx){
cout<<trv[idx].dat<<' ';
}
void bfs(int r){
queue<int>q;q.push(r);
Prnt(r);
while(!q.empty()){
int t=q.front();q.pop();
if(trv[t].LeftChild){
Prnt(trv[t].LeftChild);
q.push(trv[t].LeftChild);
}
if(trv[t].RightChild){
Prnt(trv[t].RightChild);
q.push(trv[t].RightChild);
}
}
}
五、求解先序、后序、层次遍历序列
1.中序后续求先序
方法1:
① 找根:基于后序序列的尾元素即是根,找出树的根。
② 划分子问题:基于中序序列、根和后序序列,划分出左右子树的中序和后序序列。
③ 治理子问题:基于左右子树的中序和后序序列,递归的处理左右子树。
④ 合并:将左右子树根节点的存储位置,合并为原树的左右子树。
⑤ 先序遍历:基于构建出的树,进行先序遍历,输出先序序列。
struct Node{
char dat;
int l,r;
}tr[N];
int tot;
string in,ps;
int build(int ib,int ie,int pb,int pe){
int r=++tot;tr[r].dat=ps[pe];
int rps=in.find(tr[r].dat);
interestinglen=rps-ib;
if(rps>ib)tr[r].l=build(ib,rps-1,pb,pb+len-1);
if(rps<ie)tr[r].r=build(rps+1,ie,pb+len,pe-1);
return r;
}
void ODR(int r){
if(!r)return;
cout<<tr[r].dat;
ODR(tr[r].l);
ORD(tr[r].r);
}
int main(){
cin>>in>>ps;
int r=build(0,in.size()-1,0,ps.size()-1);
ODR(r);
}
方法2:
在算法1的处理过程中直接输出根,接着先递归处理左子树,再递归处理右子树。
string in,ps;
void solve(int ib,int ie,int pb,int pe){
char r=ps[pe];
cout<<r;
int rps=in.find(r);
int len=rps-ib;
if(rps>ib)solve(ib,rps-1,pb,pb+len-1);
if(rps<ie)solve(rps+1,ie,pb+len,pe-1);
}
2.前序中序求后序
方法1:
① 找根:基于先序序列的首元素即是根,找出树的根。
② 划分子问题:基于中序序列、根和先序序列,划分出左右子树的中序和先序序列。
③ 治理子问题:基于左右子树的中序和先序序列,递归的处理左右子树。
④ 合并:将左右子树根节点的存储位置,合并为原树的左右子树。
⑤ 后序遍历:基于构建出的树,进行后序遍历,输出后序序列。
struct Node{
char dat;
int l,r;
}tr[N];
int tot;
string in,pr;
int build(int ib,int ie,int pb,int pe){
int r=++tot;
tr[r].dat=pr[pb];
int rps=in.find(tr[r].dat);
int len=rps-ib;
if(rps>ib)tr[r].l=build(ib,rps-1,pb+1,pb+len);
if(rps<ie)tr[r].r=build(rps+1,it,pb+len+1,pe);
return r;
}
void ODR(int r){
if(!r)return;
ODR(tr[r].l);
ODR(tr[r].r);
cout<<tr[r].dat;
}
int main(){
cin>>in>>pr;
int r=build(0,in.size()-1,0,pr.size()-1);
ODR(r);
}
方法2:
在算法1处理过程中,找到根后先储存,当递归处理完左右子树后,再输出根。
string in,pr;
void solve(int ib,int ie,int pb,int pe){
char r=pr[pb];
int rps=in.find(r);
int len=rps-ib;
if(rps>ib)solve(ib,rps-1,pb+1,rp+len);
if(rps<ie)solve(rps+1,ie,pb+len+1,pe);
cout<<r;
}
int main(){
cin>>in>>pr;
solve(0,in.size()-1,0,pr.size()-1);
}
3.前序中序求层次
① 找根:基于先序序列的首元素即是根,找出树的根。
② 划分子问题:基于中序序列、根和先序序列,划分出左右子树的中序和先序序列。
③ 治理子问题:基于左右子树的中序和先序序列,递归的处理左右子树。
④ 合并:将左右子树根节点的存储位置,合并为原树的左右子树。
⑤ 层次遍历:基于构建出的树,进行层次遍历,输出层次序列。
struct Node{
char dat;
int l,r;
}tr[N];
int tot;
string in,pr;
int build(int ib,int ie,int pb,int pe){
int r=++tot;
tr[r].dat=pr[pb];
int rps=in.find(tr[r].dat);
int len=rps-ib;
if(rps>ib)tr[r].l=build(ib,rps-1,pb+1,pb+len);
if(rps<ie)tr[r].r=build(rps+1,ie,pb+len+1,pe);
return r;
}
void Prnt(int r){
cout<<tr[r].dat;
}
void bfs(int r){
queue<int>q;q.push(r);
Prnt(r);
while(!q.empty()){
int n=q.ront();q.pop();
if(tr[n].l){
Prnt(tr[n].l);
q.push(tr[n].l);
}
if(tr[n].r){
Prnt(tr[n].r);
q.push(tr[n].r);
}
}
}
int main(){
cin>>in>>pr;
int r=build(0,in.size()-1,0,pr.size()-1);
bfs(r);
}
4.中序层次求先序
① 找根:基于层次遍历的首元素是整棵树的根,找出树根。
② 划分子问题:基于中序序列和根可以划分出左右子树的中序序列。
通过中序序列可以得到左子树和右子树各自所包含的所有节点,左子树的所有节点中最先
出现在层次遍历序列中的节点是左子树的根,同理可得右子树的根。
string in,l;
int fr(int ib,int ie){
for(int i=0;i<l.size();i++)
for(int j=ib;j<=ie;j++)
if(l[i]==in[j])return j;
}
void solve(int ib,int ie){
int r=fr(ib,ie);cout<<in[r];
if(r>ib)solve(ib,r-1);
if(r<ie)solve(r+1,ie);
}
int main(){
cin>>in>>l;solve(0,in.size()-1);
}
六、例题
1.小球下落-简化版
有一棵二叉树,最大深度为D,且所有叶子的深度都相同。所有节点从上到下,从左到右的编号为1,2,3...,2^D-1.
在结点1处放一个小球,它会往下落,每个内结点上都有一个开关(开关的状态是false或true),初始时全部是false状态,当每次有小球落到这个结点上时,开关的状态被改变。
当小球达到一个内结点时,如果该结点的开关状态是关闭的,则小球往左走,否则往右走,直到走到叶子结点。
如下图所示:
表示结点编号为1,2,3...15,最大深度为4的完全二叉树,由于初始时,所有的结点的开关状态是false,所以第一个球下落时经过结点1 2 4最终落在结点8上,第二个球下落时经过结点1 3 6最终落在结点12上,第三个球下落时,经过结点1 2 5最终落在结点10上。
现在给出多组测试数据,最多包含1000组,每组测试数据两个值。第一个值是D,表示二叉树的最大深度。第二个值是L,表示小球的个数L。
假设I不超过整棵树的叶子个数,2≤D≤20,and 1≤L≤5000
编写一个程序,计算出小球从节点1处依次开始下落,最后一个小球L将会落下哪里?输出第L个小球最后所在的叶子编号。
输入格式
第一行一个整数n,表示测试数据的组数
接下来n行,每行两个整数分别表示二叉树的深度D和小球的个数L,用空格隔开
最后一行,“-1”,表示测试数据结束
输出格式
输出n行,分别表示每组测试数据,第L个小球最后所在的叶子编号
输入输出样列
输入样例1:
5
4 2
3 4
10 1
2 2
8 128
-1
输出样例1:
12
7
512
3
255
这道题就是个大大大大大氵题,直接按照题目的思路模拟即可。
#include <bits/stdc++.h>
#define debug(x) cout << #x << '=' << x << '\n';
using namespace std;
bool tr[1000010]; //lson=t*2,rson=t*2+1
int T;
void slove(){
memset(tr,0,sizeof(tr));
int D,L;scanf("%d%d",&D,&L);
int a=(1<<D-1),b=(1<<D)-1;
int l=b-a+1,x;
for(int ball=1;ball<=L;ball++){
int now=1;
while(now<l){
int t=now;
if(!tr[now])now=now<<1;
else now=now<<1|1;
tr[t]^=1;
}x=now;
}
printf("%d\n",x);
}
int main () {
scanf("%d",&T);
while(T--)slove();
return 0;
}
2.美国血统 American Heritage [USACO 3.4]
农夫约翰非常认真地对待他的奶牛们的血统.然而他不是一个真正优秀的记帐员.他把他的奶牛们的家谱作成二叉树,并且把二叉树以更线性的”树的中序遍历“和”树的前序遍历“的符号加以记录而不是用图形的方法.
你的任务是在被给予奶牛家谱的”树中序遍历“和”树前序遍历“的符号后,创建奶牛家谱的”树的后序遍历“的符号。每一头奶牛的姓名被译为一个唯一的字母. (你可能已经知道你可以在知道树的两种遍历以后可以经常地重建这棵树.)显然,这里的树不会有多余 26 个的顶点.
这是在样例输入和 样例输出中的树的图形表达方式:
C
/ \
/ \
B G
/ \ /
A D H
/ \
E F
树的中序遍历是按照左子树,根,右子树的顺序访问节点。
树的前序遍历是按照根,左子树,右子树的顺序访问节点。
树的后序遍历是按照左子树,右子树,根的顺序访问节点。
输入格式
第一行: 树的中序遍历
第二行: 同样的树的前序遍历
输出格式
单独的一行表示该树的后序遍历.
输入输出样列
输入样例1:
ABEDFCHG
CBADEFGH
输出样例1:
AEFDBHGC
模板题啊。
#include <bits/stdc++.h>
#define debug(x) cout << #x << '=' << x << '\n';
using namespace std;
string p, i;
void build (string p, string i) {
if (p.empty ()) return;
char r = p[0];
int k = i.find (r);
p.erase (p.begin ());
string l1 = p.substr (0, k);
string r1 = p.substr (k);
string l2 = i.substr (0, k);
string r2 = i.substr (k + 1);
build (l1, l2);
build (r1, r2);
cout << r;
}
int main () {
cin >> i >> p;
build (p, i);
return 0;
}
二叉堆
一、二叉堆简介
二叉堆使用完全二叉树实现,分为大根堆和小根堆两种:
大根堆:任意一个分支结点的值都大于或者等于其子节点的值。
小根堆:任意一个分支结点的值都小于或者等于其子节点的值。
查询最大值(大根堆)和最小值(小根堆)时,直接取根节点即可,时间复杂度O(1)
二、二叉堆的插入操作
插入操作要求在不影响二叉堆性质的前提下,在二叉堆中添加一个新元素。
性质1:完全二叉树结构,插入新元素后需要继续保持完全二叉树的结构。
性质2:任何一个分支节点的值都大于等于(大根堆)或小于等于(小根堆)其子节点的值。
① 堆尾插入:每次在堆尾插入新元素(确保插入后仍然是完全二叉树结构)。
② 向上调整(和父节点比较),将新元素调整到合适的位置。
三、二叉堆的删除堆顶操作
删顶操作要求在不影响二叉堆性质的前提下,将堆顶元素删除。
性质1:完全二叉树结构,删除堆顶后需要继续保持完全二叉树的结构。
性质2:任何一个分支节点的值都大于等于(大根堆)或小于等于(小根堆)其子节点的值。
① 将堆顶赋值为堆尾元素的值,接着删除堆尾节点。(保持完全二叉树结构)
② 向下调整(和孩子节点比较),堆顶元素调整到合适的位置。
我们可以通过数组来实现这个二叉堆!
四、二叉堆复杂度分析
插入操作:堆尾添加元素时间复杂度O(1),向上调整的次数最大为完全二叉树的层数:
log2 n + 1,故插入操作的时间复杂度为:O(log2 n )。
删顶操作:堆顶复制和堆尾删除时间复杂度O(1), 向下调整的次数最大为完全二叉树
的层数: log2 n + 1,故删顶操作的时间复杂度为:O(log2 n )。
五、二叉堆代码实现
int heap[N],tt;
bool empty(){return !tt;}
int sz(){return tt;}
int tp(){return heap[1];}
int psh(int v){
heap[++tt]=v;
int x=tt;
while(x>1&&heap[x]<heap[x>>1]){
swap(heap[x>>1],heap[x]);
x>>=1;
}
}
void pop(){
heap[1]=heap[tt--];
int x=1,p=x<<1;
while(p<=tt){
if(p+1<=tt&&heap[p+1]<heap[p])p++;
if(heap[x]<=heap[p])break;
swap(heap[x],heap[p]);x=p,p=x<<1;
}
}
六、优先队列
优先队列priority_queue和堆是实现的相近的功能:插入一个数和删除最小或最大的值
常用函数:

优先队列也是可以使用小根堆和大根堆的,分别是greater(上升)、less(下降)
就比如:
priority_queue<int,vector<int>,greater<int> >qg;
priority_queue<int,vector<int>,less<int> >ql;
然后就比如插入一个数x:
q.push(x);
删除队头(同前面的堆顶):
q.pop();
同样,优先队列的类型也可以是结构体,但是需要重载运算符。
大根堆需要重载小于运算符
struct Node{
int a;
bool operator<(const Node&W)const{
return a>W.a;
}
}
priority_queue<Node,vector<Node>,less<Node> >q;
小根堆需要重载大于运算符
struct Node{
int a;
bool operator<(const Node&W)const{
return a<W.a;
}
}
priority_queue<Node,vector<Node>,greater<Node> >q;
七、例题
有两个长度都是N的序列A和B,在A和B中各取一个数相加可以得到N^2个和,求这N^2个和中最小的N个。
输入格式
第一行一个正整数N;
第二行N个整数Ai,满足Ai<=Ai+1且Ai<=10^9;(i和i+1表示序列的下标)
第三行N个整数Bi, 满足Bi<=Bi+1且Bi<=10^9。(i和i+1表示序列的下标)
输出格式
输出仅一行,包含N个整数,从小到大输出这N个最小的和,相邻数字之间用空格隔开。
输入输出样列
输入样例1:
3
2 6 6
1 4 8
输出样例1:
3 6 7
说明
【数据规模】
对于50%的数据中,满足1<=N<=1000;
对于100%的数据中,满足1<=N<=100000。

同样的反过来统计也一样:
#include<bits/stdc++.h>
using namespace std;
typedef pair<int,int>PII;
const int N=1e5+10;
int n,a[N],b[N],t[N];
priority_queue<PII,vector<PII>,greater<PII> >q;
int main(){
cin>>n;
for(int i=1;i<=n;i++)cin>>a[i];
for(int i=1;i<=n;i++)cin>>b[i];
for(int i=1;i<=n;i++)q.push(make_pair(a[1]+b[i],i)),t[i]=1;
for(int i=1;i<=n;i++){
cout<<q.top().first<<' ';
int idx=q.top().second;t[idx]++;
q.pop();
q.push(make_pair(a[t[idx]]+b[idx],idx));
}
return 0;
}



![[思维模式-8]:《如何系统思考》-4- 认识篇 - 什么是系统思考?系统思考的特征?系统思考的思维转变。](https://img-blog.csdnimg.cn/img_convert/29d7c2475f0368b5359c843443bbd3f0.jpeg)