前言:
很早之前,我发过小白YOLOv5全流程-训练+实现数字识别_牛大了2022的博客-CSDN博客_yolov5数字识别这篇文章,里面用简练语言分享用yolov5训练自己的识别器,但包括我在内许多人仍不了解其运行原理;过去两周,我也发了深度学习Week9-YOLOv5-C3模块实现(Pytorch)_牛大了2022的博客-CSDN博客和深度学习Week10-YOLOv5-Backbone模块实现(Pytorch)_牛大了2022的博客-CSDN博客两篇yolov5结构部分框架的初探。从这篇文章开始,会一步步的详细剖析yolov5,让我们一同学习,加深对yolov5的理解。
本周先以跑通官方代码为目标。
一、环境配置
跟着我做过小白yolov5全流程的朋友可以跳过这一步,没有安装源码环境的参考以下步骤
注意:安装涉及的路径不要有中文
1. yolov5开源地址 进去后下载源码到本地
2.anaconda中新建一个虚拟环境,python3.9 ,pytorch1.12.1,yolov5 v6.0
(如若使用GPU,cuda version >=10.1,自己搜cuda下载配置)
3.控制台中进行以下操作(建议pycharm搞)
git clone https://github.com/ultralytics/yolov5 # clone
cd yolov5
pip install -r requirements.txt # install 安装各种包
二、运行代码
在pycharm中打开detect.py
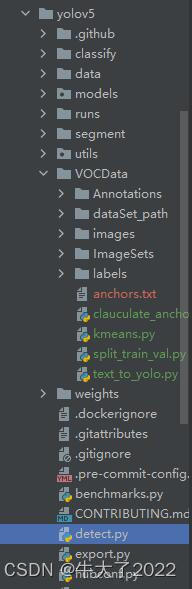
第一次用可以用它默认的识别模型yolov5s.pt,(如果没有网盘下载 yolov5s.pt 提取码:bum6)然后上传本地要识别的图片或者视频
加载摄像头进行识别:(图片视频default修改路径就行如'test1.jpg',摄像头default为0)
parser.add_argument('--source', type=str, default=0, help='source') #file/dir/URL/glob/screen/0(webcam)最后生成的图片或者视频在runs\detect\exp1234...
这里偷懒,就放我以前博客的识别图片,原理都一样。还是强烈建议初学者想快速上手可以看看我这篇文章