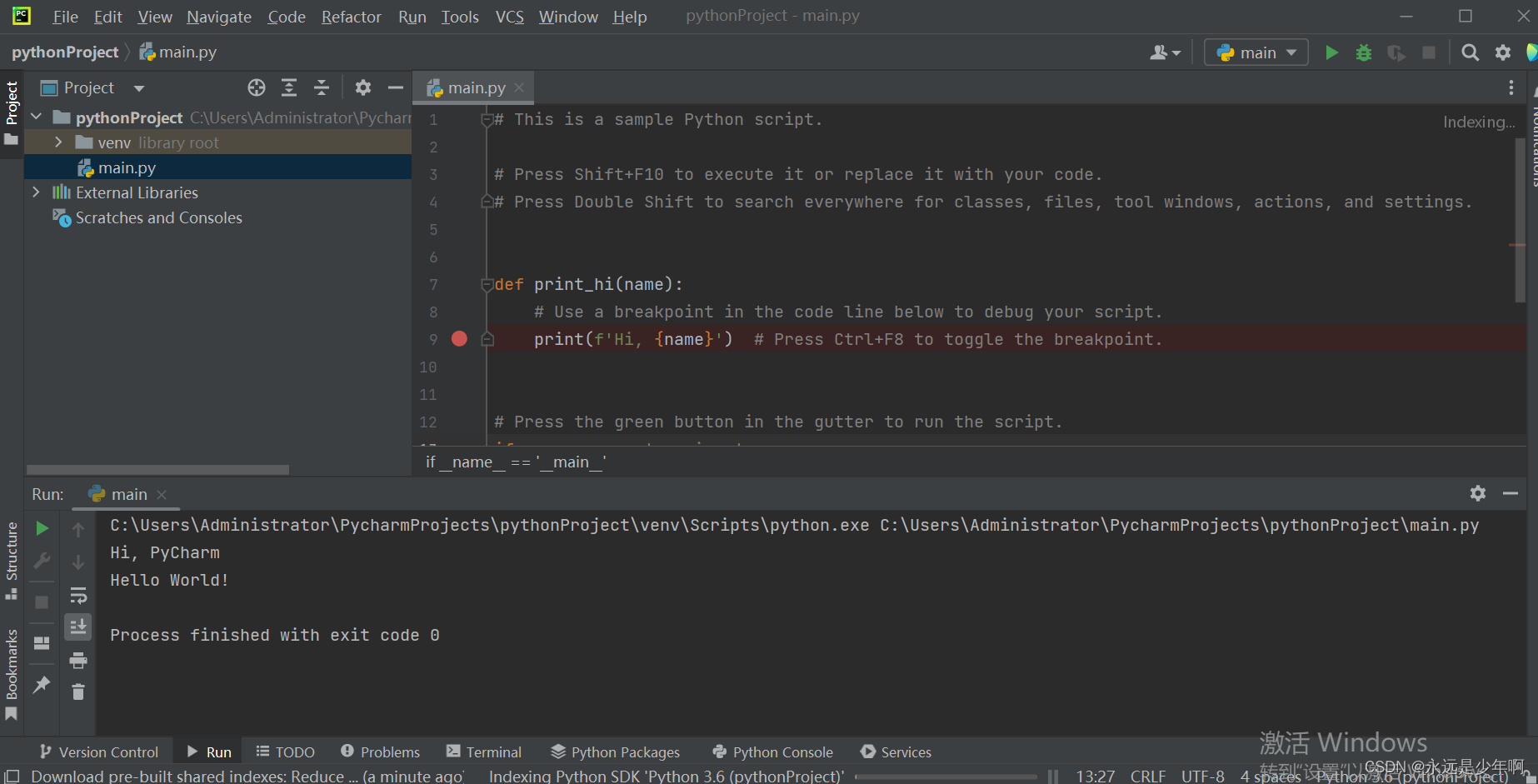
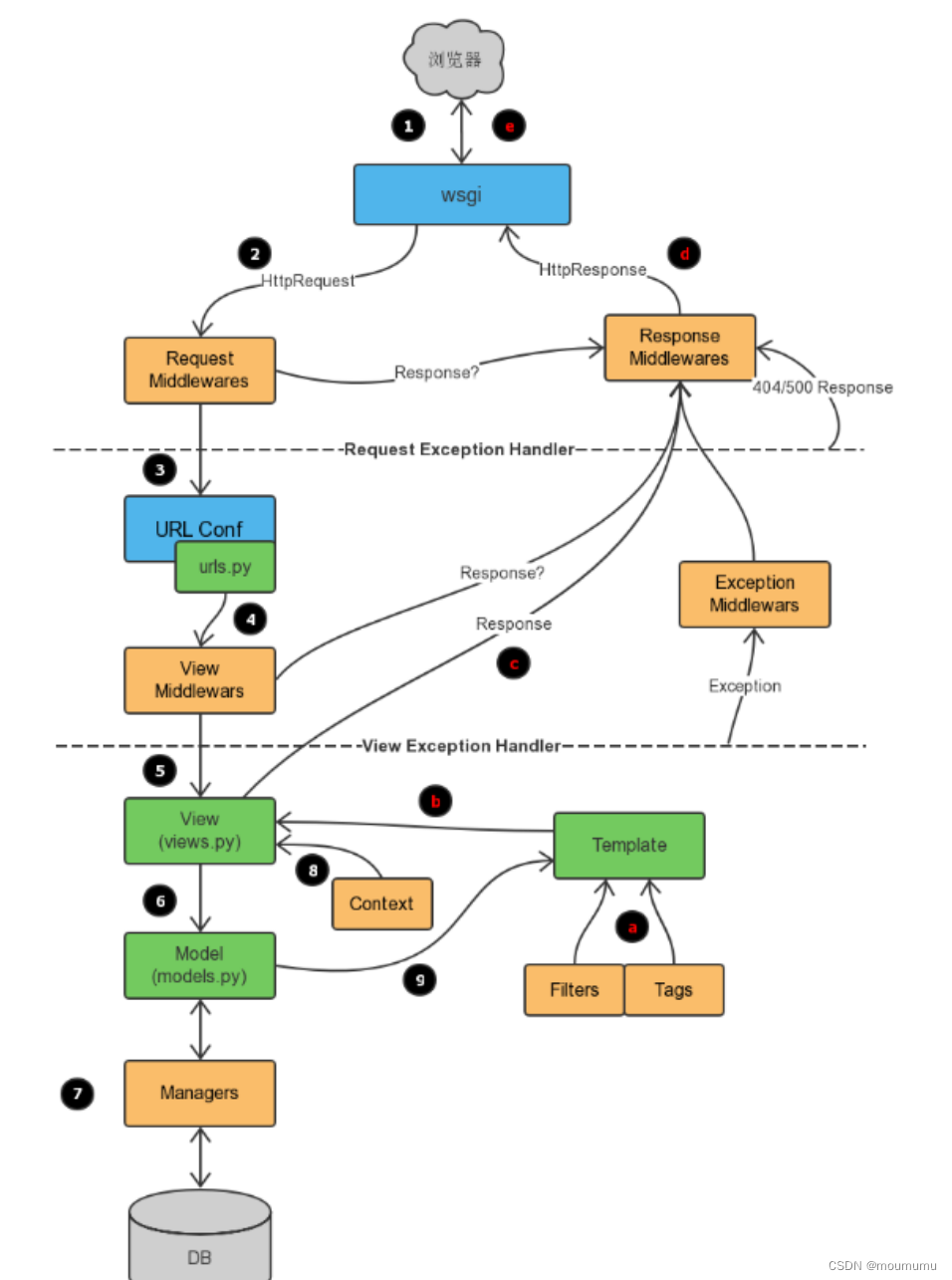
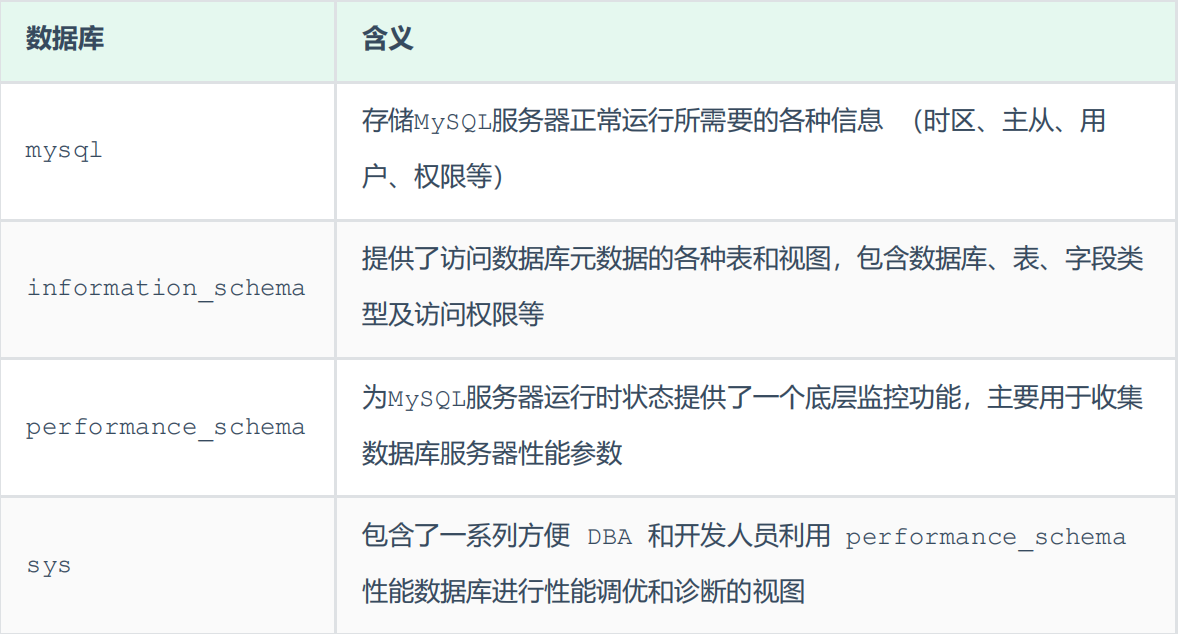
欢迎关注我的CSDN:https://blog.csdn.net/caroline_wendy
本文地址:https://blog.csdn.net/caroline_wendy/article/details/128382935
Paper:MAE - Masked Autoencoders Are Scalable Vision Learners
-
掩码的自编码器是可扩展的视觉学习器
-
Kaiming He,FAIR
Code:https://github.com/facebookresearch/mae
MAE结构:
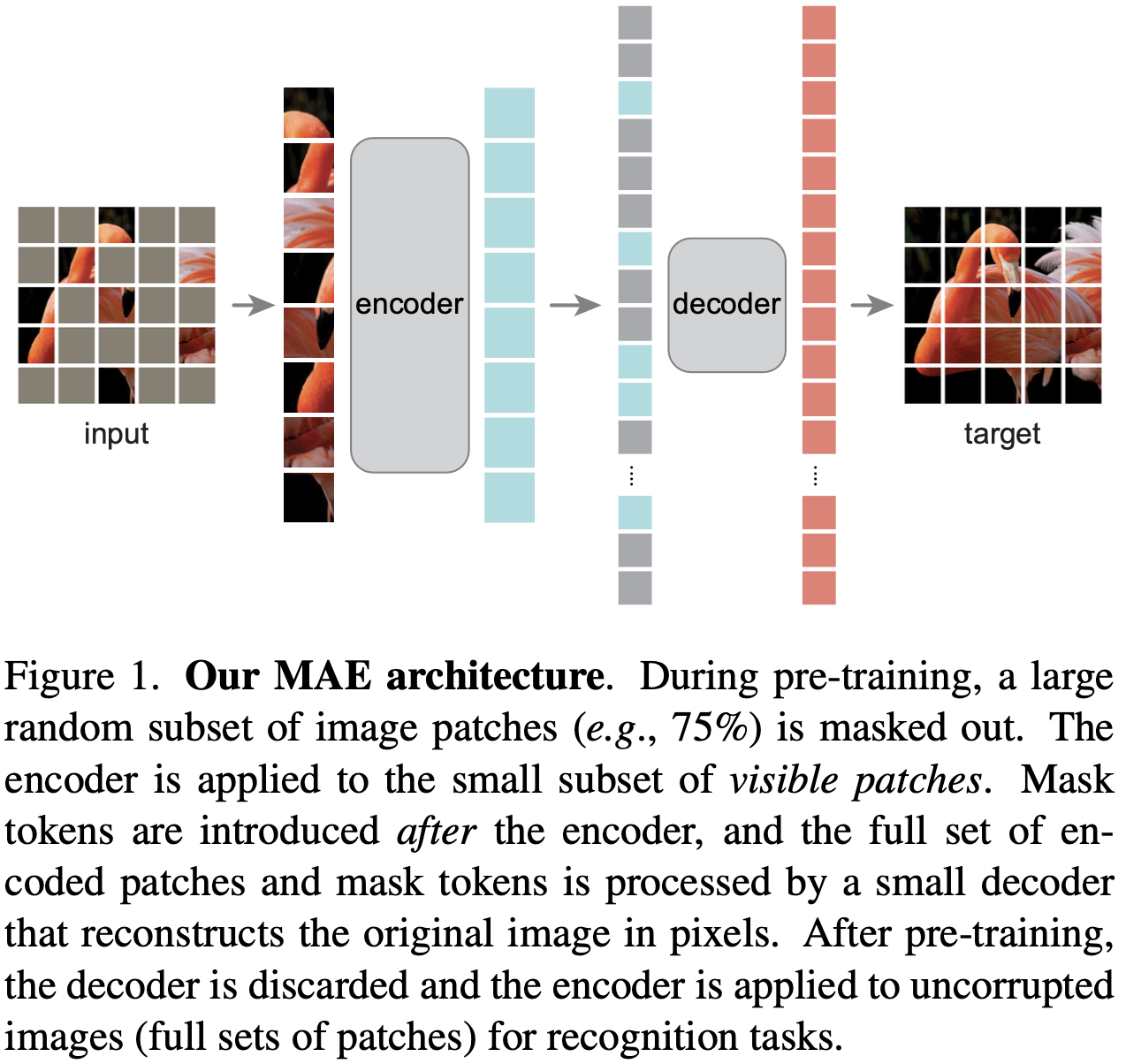
ViT的不同类型:An Image is worth 16X16 words: Transformers for Image recognition at scale
- 一张图片相当于 16X16 个字: 用于大规模图像识别的Transformers,Google Research