🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
使用 Xcode 创建您的第一个 TensorFlow Lite 应用程序
步骤 1 . 创建一个基本的 iOS 应用程序
步骤 2 . 将 TensorFlow Lite 添加到您的项目
步骤 3 . 创建用户界面
步骤 4. 添加并初始化模型推理类
步骤 5 . 执行推理
步骤 6 . 将模型添加到您的应用程序
步骤 7. 添加 UI 逻辑
超越“Hello World”——处理图像
TensorFlow Lite 示例应用程序
概括
向您介绍了 TensorFlow Lite,以及如何使用它将您的 TensorFlow 模型转换为可在移动设备上使用的节能、紧凑的格式。在第 13 章中,您探索了如何创建使用 TensorFlow Lite 模型的 Android 应用程序。在本章中,您将使用 iOS 做同样的事情,创建几个简单的应用程序,并了解如何使用 Swift 编程语言对 TensorFlow Lite 模型进行推理。
你会如果您想按照本章中的示例进行操作,则需要一台 Mac,因为要使用的开发工具是 Xcode,它只能在 Mac 上使用。如果您还没有,可以从 App Store 安装它。它会为您提供所需的一切,包括一个 iOS 模拟器,您可以在该模拟器上运行 iPhone 和 iPod 应用程序而无需物理设备。
使用 Xcode 创建您的第一个 TensorFlow Lite 应用程序
启动并运行 Xcode 后,您可以按照本节中概述的步骤创建一个简单的 iOS 应用程序,其中包含第 12 章中的 Y = 2X – 1 模型。虽然这是一个极其简单的场景,并且对于机器学习应用程序来说绝对是矫枉过正,但骨架结构与用于更复杂应用程序的骨架结构相同,而且我发现它是演示如何在应用程序中使用模型的一种有用方式。
步骤 1 . 创建一个基本的 iOS 应用程序
打开Xcode 并选择文件 → 新建项目。系统会要求您为新项目选择模板。选择 Single View App,这是最简单的模板(图 14-1),然后单击 Next。
之后,系统会要求您为新项目选择选项,包括应用程序的名称。将其命名为firstlite,并确保语言是 Swift 并且用户界面是 Storyboard(图 14-2)。
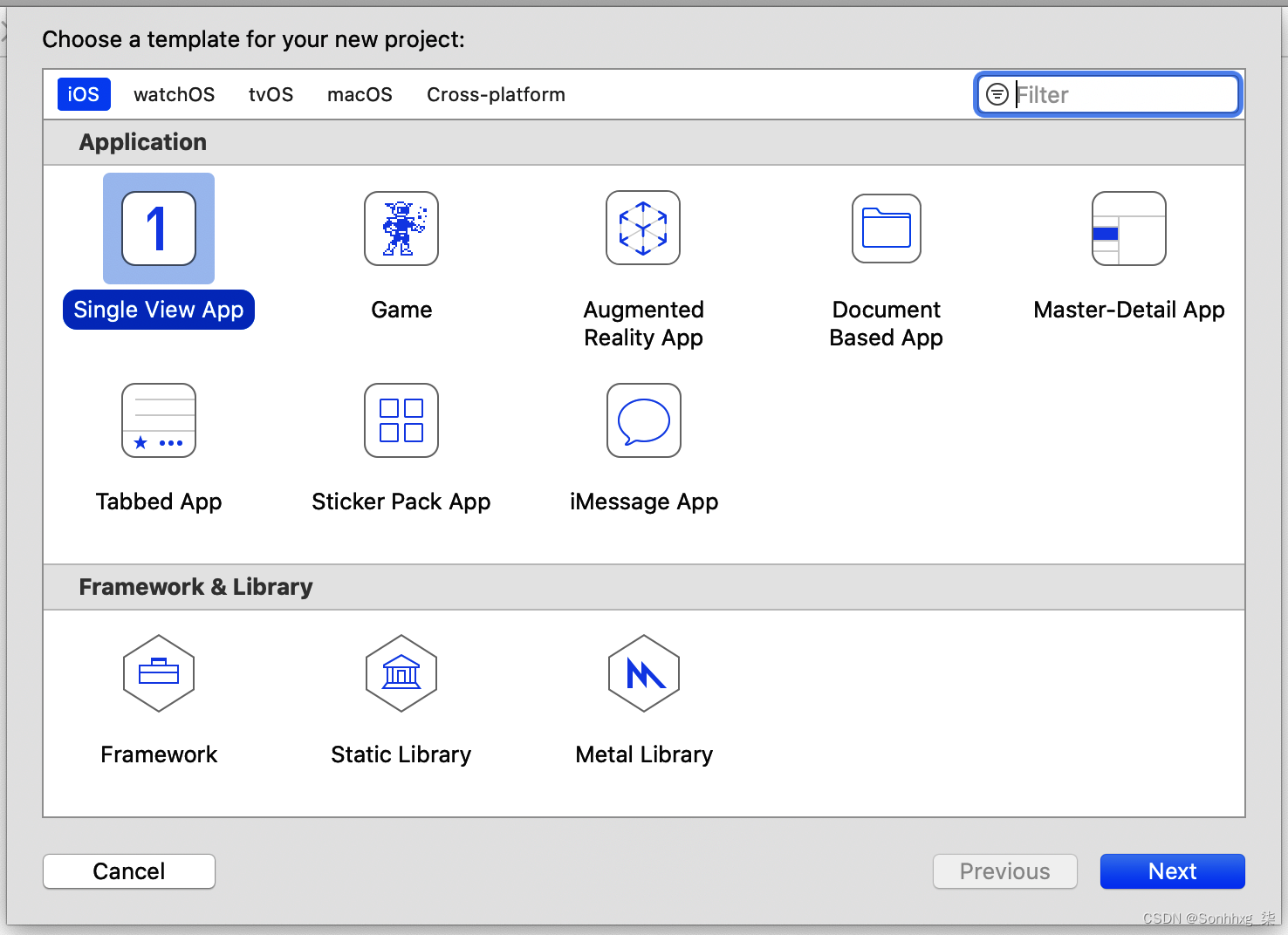
图 14-1。在 Xcode 中创建一个新的 iOS 应用程序
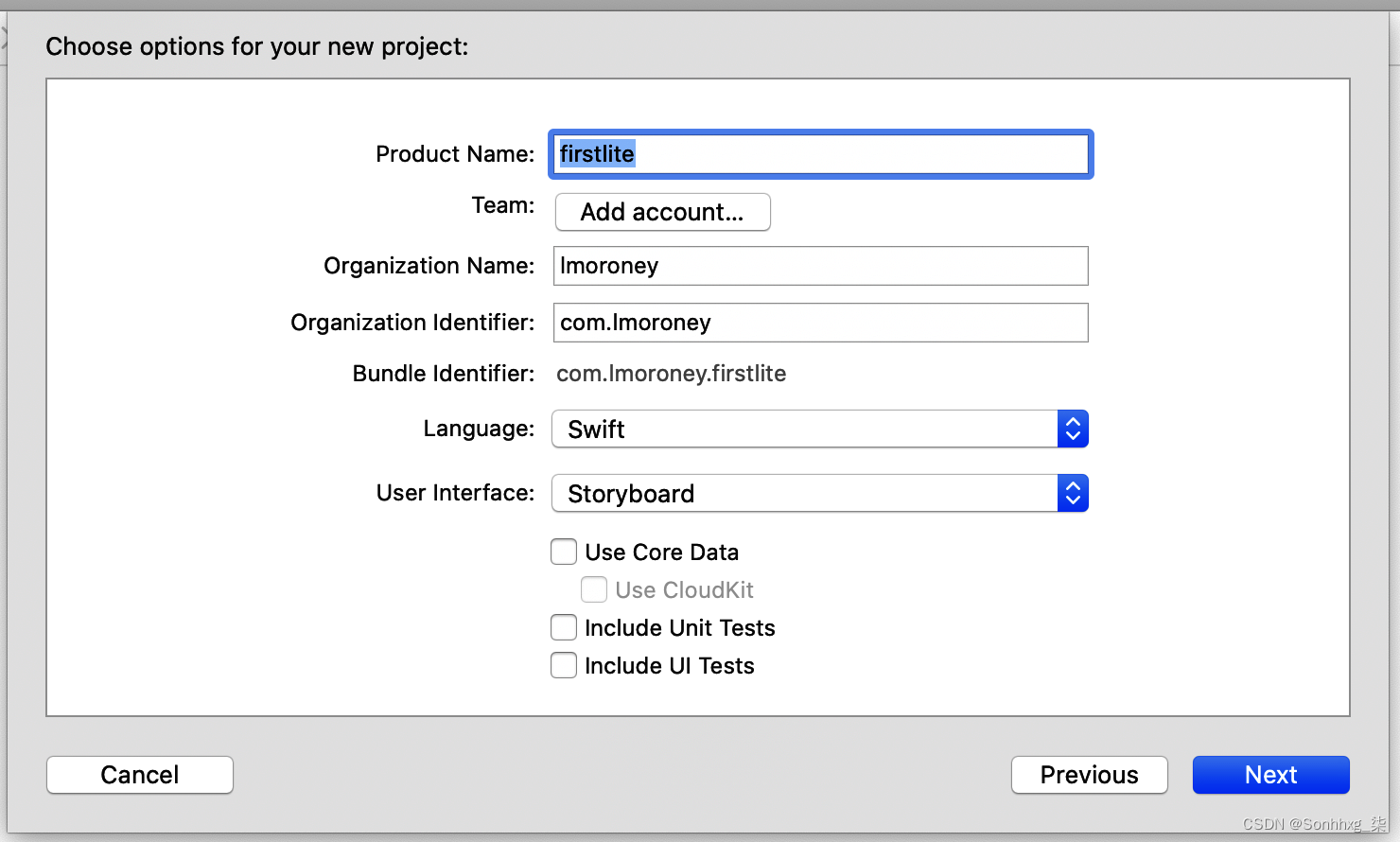
图 14-2。为您的新项目选择选项
单击“下一步”创建将在 iPhone 或 iPad 模拟器上运行的基本 iOS 应用程序。下一步是将 TensorFlow Lite 添加到其中。
步骤 2 . 将 TensorFlow Lite 添加到您的项目
至向 iOS 项目添加依赖项,您可以使用一种称为CocoaPods的技术,这是一个依赖项管理项目,具有数千个可以轻松集成到您的应用程序中的库。为此,您需要创建一个称为 Podfile 的规范,其中包含有关您的项目和您要使用的依赖项的详细信息。这是一个名为Podfile (无扩展名)的简单文本文件,您应该将其放在与Xcode 为您创建的firstlite.xcodeproj文件相同的目录中。其内容应如下:
# Uncomment the next line to define a global platform for your project
platform :ios, '12.0'
target 'firstlite' do
# Comment the next line if you're not using Swift and don't want to
# use dynamic frameworks
use_frameworks!
# Pods for ImageClassification
pod 'TensorFlowLiteSwift'
end重要的部分是显示为 的行pod 'TensorFlowLiteSwift',它表示需要将 TensorFlow Lite Swift 库添加到项目中。
接下来,使用终端,切换到包含 Podfile 的目录并发出以下命令:
pod install依赖项将被下载并添加到您的项目中,存储在一个名为Pods的新文件夹中。您还将添加一个.xcworkspace文件,如图 14-3所示。以后使用这个来打开您的项目,而不是.xcodeproj文件。
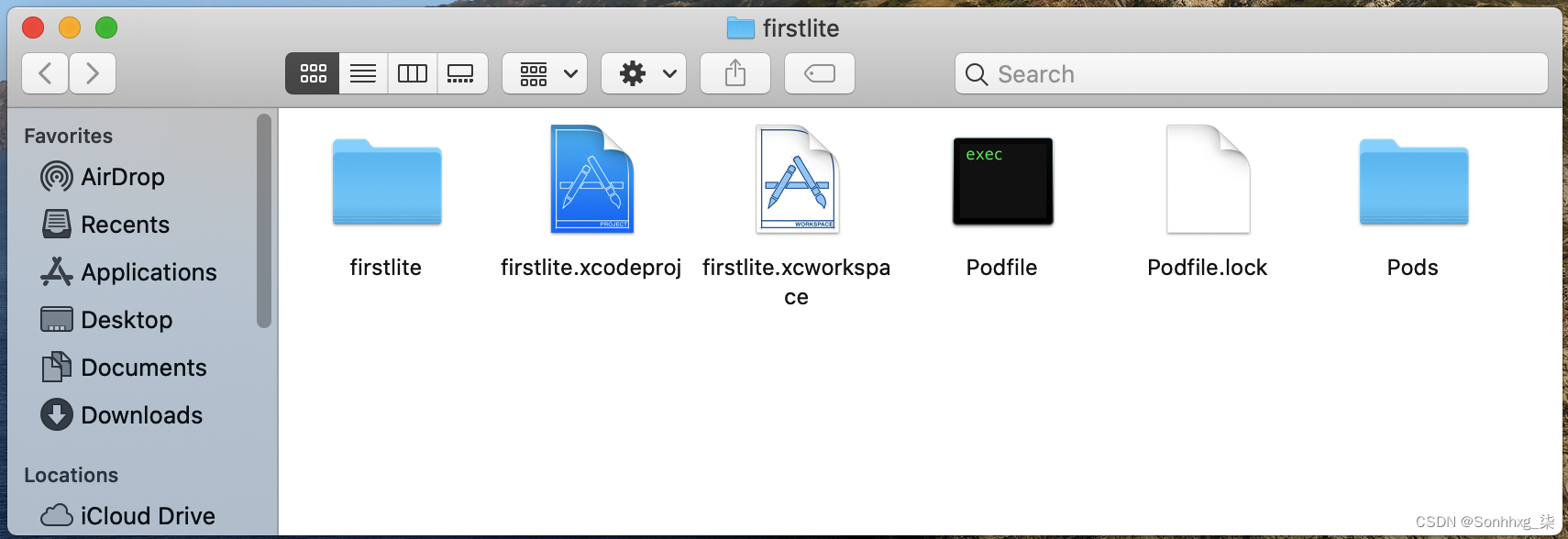
图 14-3。运行 pod install 后的文件结构
您现在拥有一个基本的 iOS 应用程序,并且您已经添加了 TensorFlow Lite 依赖项。下一步是创建用户界面。
步骤 3 . 创建用户界面
这Xcode 故事板编辑器是一种可视化工具,可让您创建用户界面。打开工作区后,您会在左侧看到源文件列表。选择Main.storyboard,然后使用控件面板,您可以将控件拖放到 iPhone 屏幕的视图上(图 14-4)。
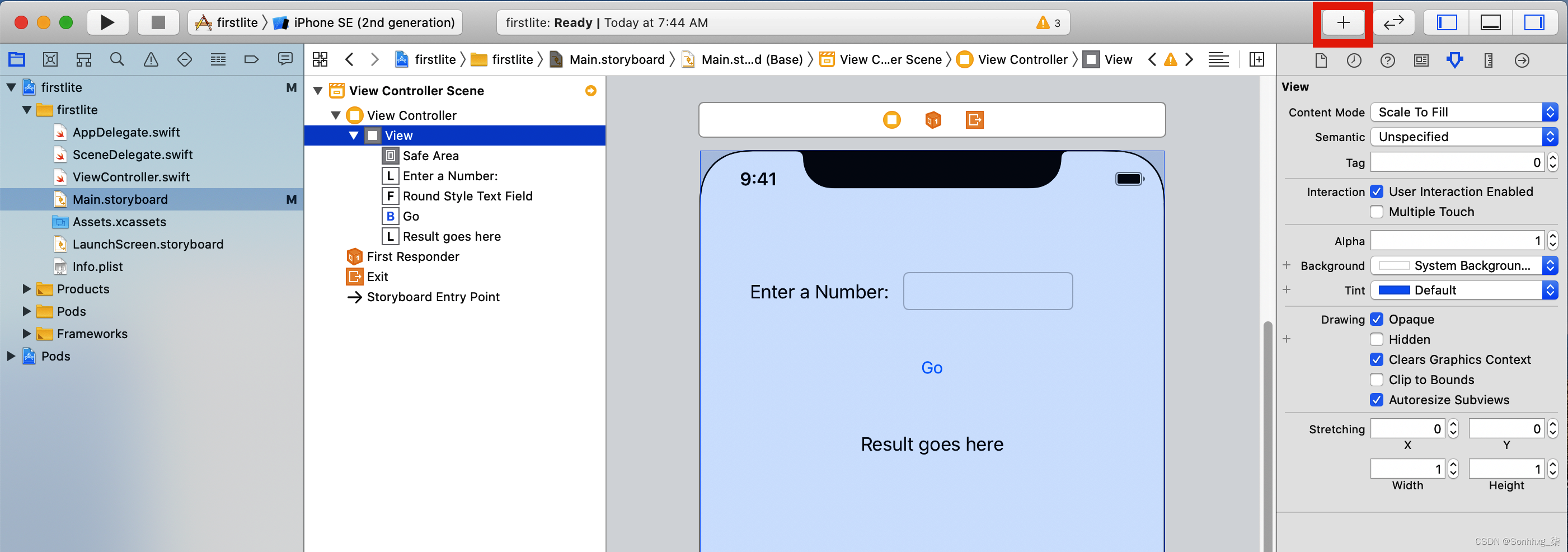
图 14-4。向故事板添加控件
如果找不到控件选项板,可以通过单击屏幕右上角的 + 访问它(在图 14-4中突出显示)。使用它,添加一个标签,并将文本更改为“输入数字”。然后添加另一个文本“Result goes here”。添加一个按钮并将其标题更改为“Go”,最后添加一个文本字段。按照与图 14-4中看到的类似的方式排列它们。它不必很漂亮!
现在控件已经布置好,您希望能够在代码中引用它们。用故事板的说法,您可以使用outlet(当您想要寻址控件以读取或设置其内容时)或操作(当您想要在用户与控件交互时执行某些代码时)来执行此操作。
最简单的连接方式是分屏,故事板在一侧,ViewController.swift代码在另一侧。您可以通过选择分屏控件(在图 14-5中突出显示),单击一侧并选择故事板,然后单击另一侧并选择ViewController.swift来实现此目的。
图 14-5。分割画面
完成此操作后,您可以开始通过拖放来创建出口和操作。使用这个应用程序,用户在文本字段中键入一个数字,按下 Go,然后对他们键入的值运行推理。结果将呈现在标有“Result goes here”的标签中。
这意味着您需要读取或写入两个控件,读取文本字段的内容以获取用户输入的内容,并将结果写入“Results goes here”标签。因此,您需要两个插座。要创建它们,请按住 Ctrl 键并将故事板上的控件拖到ViewController.swift文件上,将其放在类定义的正下方。将出现一个弹出窗口,要求您定义它(图 14-6)。
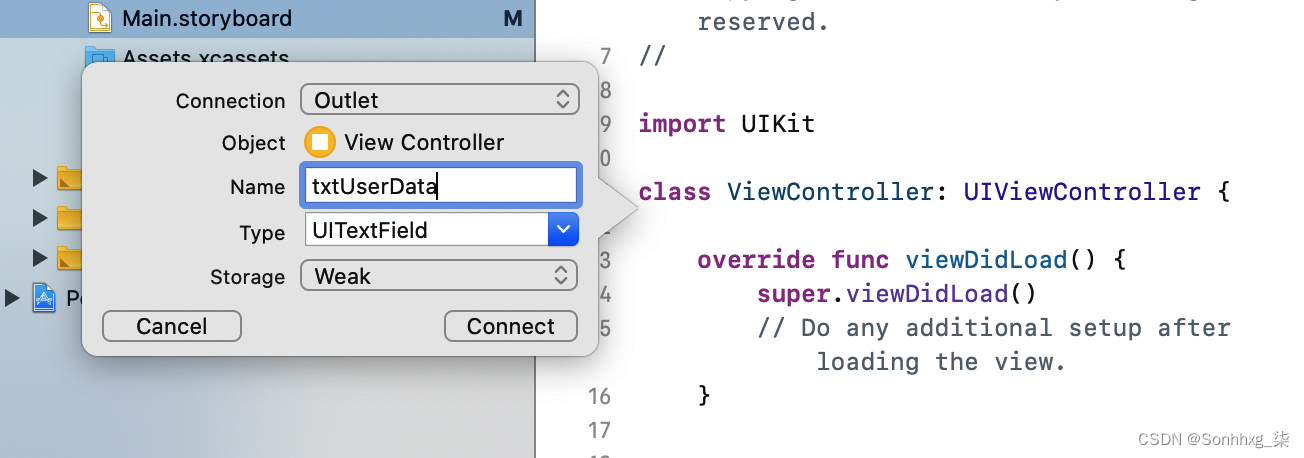
图 14-6。创建出口
确保连接类型为 Outlet,并为名为 的文本字段创建一个插座,为名为txtUserData的标签创建一个插座txtResult。
接下来,将按钮拖到ViewController.swift文件中。在弹出窗口中,确保连接类型为 Action,事件类型为 Touch Up Inside。使用它来定义一个名为btnGo(图 14-7)的动作。
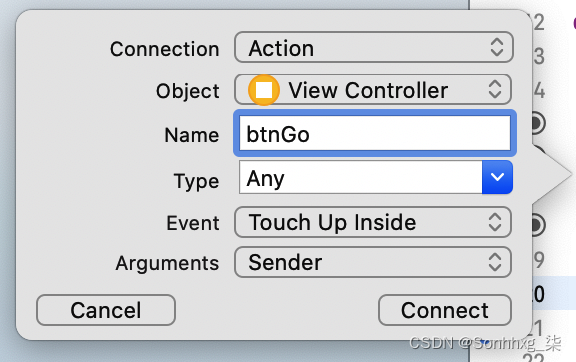
图 14-7。添加动作
此时你的ViewController.swift文件应该是这样的——注意IBOutlet代码IBAction:
import UIKit
class ViewController: UIViewController {
@IBOutlet weak var txtUserData: UITextField!
@IBOutlet weak var txtResult: UILabel!
@IBAction func btnGo(_ sender: Any) {
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
}
}现在 UI 已摆正,下一步将是创建处理推理的代码。与其将它与逻辑放在同一个 Swift 文件中,不如ViewController将它放在一个单独的代码文件中。
步骤 4. 添加并初始化模型推理类
至将 UI 与底层模型推断分开,您将创建一个包含ModelParser类的新 Swift 文件。将数据导入模型、运行推理然后解析结果的所有工作都将在这里进行。在 Xcode 中,选择 File → New File 并选择 Swift File 作为模板类型(图 14-8)。
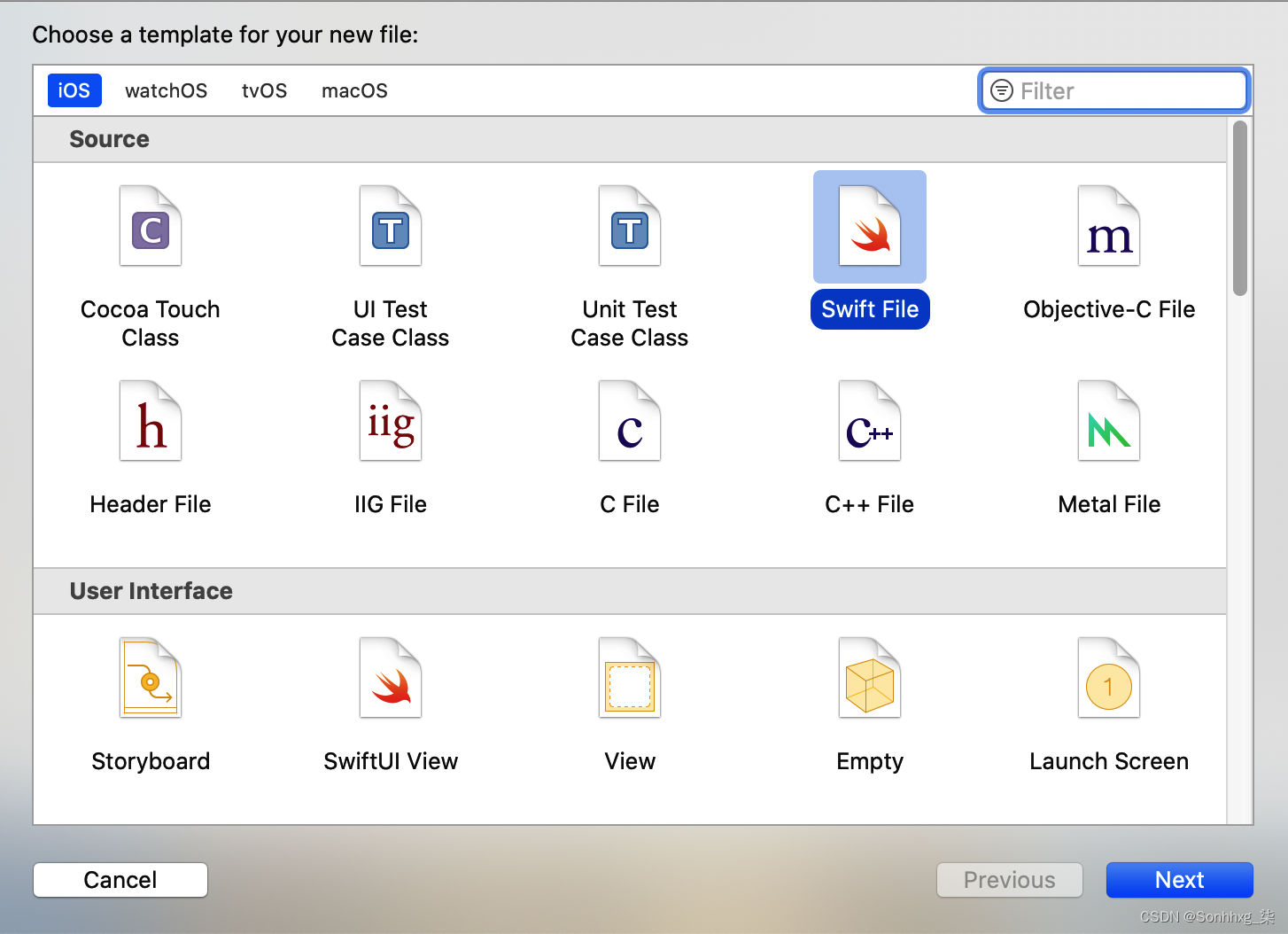
图 14-8。添加一个新的 Swift 文件
调用此ModelParser,并确保选中将其定位到 firstlite 项目的复选框(图 14-9)。
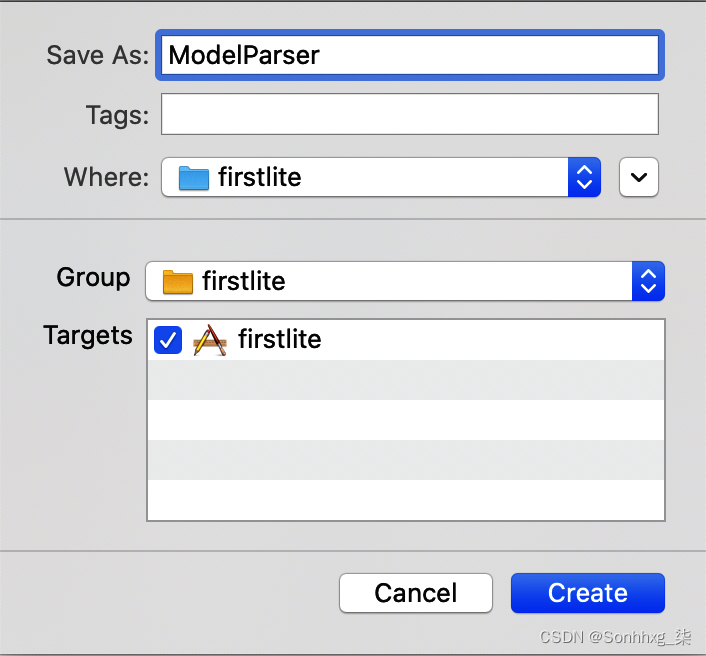
图 14-9。将 ModelParser.swift 添加到您的项目
这会将一个ModelParser.swift文件添加到您的项目中,您可以编辑该文件以添加推理逻辑。首先,确保文件顶部的导入包括TensorFlowLite:
import Foundation
import TensorFlowLite您将向此类传递对模型文件model.tflite的引用——您尚未添加它,但您很快就会:
typealias FileInfo = (name: String, extension: String)
enum ModelFile {
static let modelInfo: FileInfo = (name: "model", extension: "tflite")
}这typealias使enum代码更加紧凑。稍后您将看到它们的使用。接下来您需要将模型加载到解释器中,因此首先将解释器声明为类的私有变量:
private var interpreter: InterpreterSwift 需要初始化变量,您可以在init函数中进行初始化。以下函数将采用两个输入参数。第一个modelFileInfo是FileInfo您刚刚声明的类型。第二个threadCount是用于初始化解释器的线程数,我们将其设置为1。在此函数中,您将创建对您之前描述的模型文件 ( model.tflite ) 的引用:
init?(modelFileInfo: FileInfo, threadCount: Int = 1) {
let modelFilename = modelFileInfo.name
guard let modelPath = Bundle.main.path
(
forResource: modelFilename,
ofType: modelFileInfo.extension
)
else {
print("Failed to load the model file")
return nil
}一旦你有了包中模型文件的路径,你就可以加载它:
do
{
interpreter = try Interpreter(modelPath: modelPath)
}
catch let error
{
print("Failed to create the interpreter")
return nil
}步骤 5 . 执行推理
内ModelParser类,然后您可以进行推理。用户将在文本字段中键入一个字符串值,该字符串值将被转换为浮点数,因此您需要一个接受浮点数、将其传递给模型、运行推理并解析返回值的函数。
首先创建一个名为 的函数runModel。您的代码将需要捕获错误,因此以以下开头do{:
func runModel(withInput input: Float) -> Float? {
do{接下来,您需要在解释器上分配张量。这将对其进行初始化并准备好进行推理:
try interpreter.allocateTensors()然后您将创建输入张量。由于 Swift 没有Tensor数据类型,您需要将数据直接写入内存中的UnsafeMutableBufferPointer. 您可以指定 this 的类型,即Float,并从名为 的变量的地址开始写入一个值(因为您只有一个浮点数)data。这将有效地将浮点数的所有字节复制到缓冲区中:
var data: Float = input
let buffer: UnsafeMutableBufferPointer<Float> =
UnsafeMutableBufferPointer(start: &data, count: 1)使用缓冲区中的数据,您可以将其复制到输入 0 处的解释器。您只有一个输入张量,因此可以将其指定为缓冲区:
try interpreter.copy(Data(buffer: buffer), toInputAt: 0)要执行推理,您需要调用解释器:
try interpreter.invoke()只有一个输出张量,因此您可以通过将输出设为 0 来读取它:
let outputTensor = try interpreter.output(at: 0)与输入值时类似,您正在处理低级内存,这是不安全的数据。它在一个值数组中Float32(它只有一个元素但仍然需要被视为一个数组),可以这样读:
let results: [Float32] =
[Float32](unsafeData: outputTensor.data) ?? []如果您不熟悉??语法,这表示Float32通过将输出张量复制到其中来使结果成为一个数组,如果失败,则将其设为一个空数组。为了让这段代码起作用,你需要实现一个Array扩展;完整的代码将在稍后显示。
一旦您将结果放入数组中,第一个元素就是您的结果。如果失败,只需返回nil:
guard let result = results.first else {
return nil
}
return result
}该函数以 a 开头do{,因此您需要捕获任何错误、打印它们并nil在该事件中返回:
catch {
print(error)
return nil
}
}
}最后,仍然在ModelParser.swift中,您可以添加Array处理不安全数据的扩展并将其加载到数组中:
extension Array {
init?(unsafeData: Data) {
guard unsafeData.count % MemoryLayout<Element>.stride == 0
else { return nil }
#if swift(>=5.0)
self = unsafeData.withUnsafeBytes {
.init($0.bindMemory(to: Element.self))
}
#else
self = unsafeData.withUnsafeBytes {
.init(UnsafeBufferPointer<Element>(
start: $0,
count: unsafeData.count / MemoryLayout<Element>.stride
))
}
#endif // swift(>=5.0)
}
}如果你想直接从 TensorFlow Lite 模型中解析浮点数,这是一个方便的助手,你可以使用它。
现在解析模型的类已经完成,下一步是将模型添加到您的应用程序中。
步骤 6 . 将模型添加到您的应用程序
至将模型添加到您的应用程序,您需要在应用程序中有一个模型目录。在 Xcode 中,右键单击firstlite文件夹并选择新建组(图 14-10)。调用新组模型。
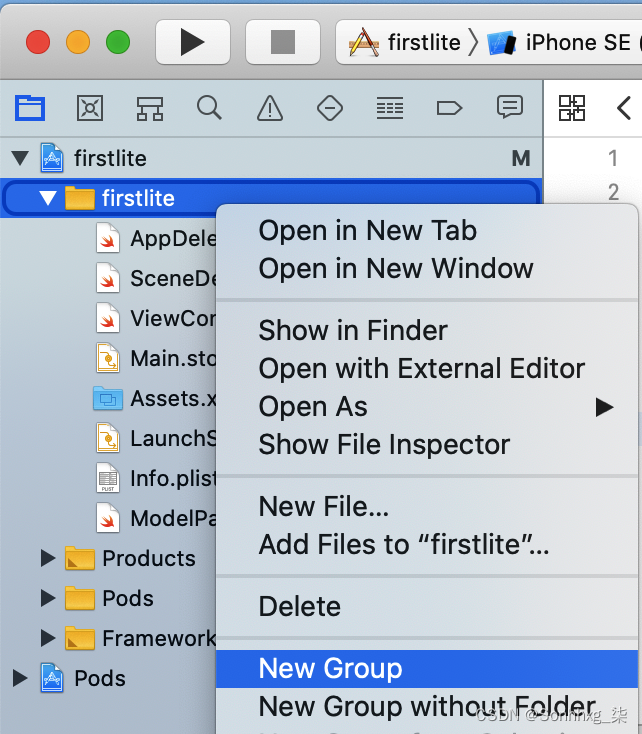
图 14-10。将新组添加到您的应用程序
您可以通过训练第 12 章中的简单 Y = 2X – 1 样本来获得模型。如果您还没有,可以使用本书GitHub 存储库中的 Colab 。
获得转换后的模型文件(称为model.tflite)后,您可以将其拖放到 Xcode 中刚刚添加的模型组中。选择“Copy items if needed”并确保通过选中它旁边的框将其添加到目标 firstlite(图 14-11)。
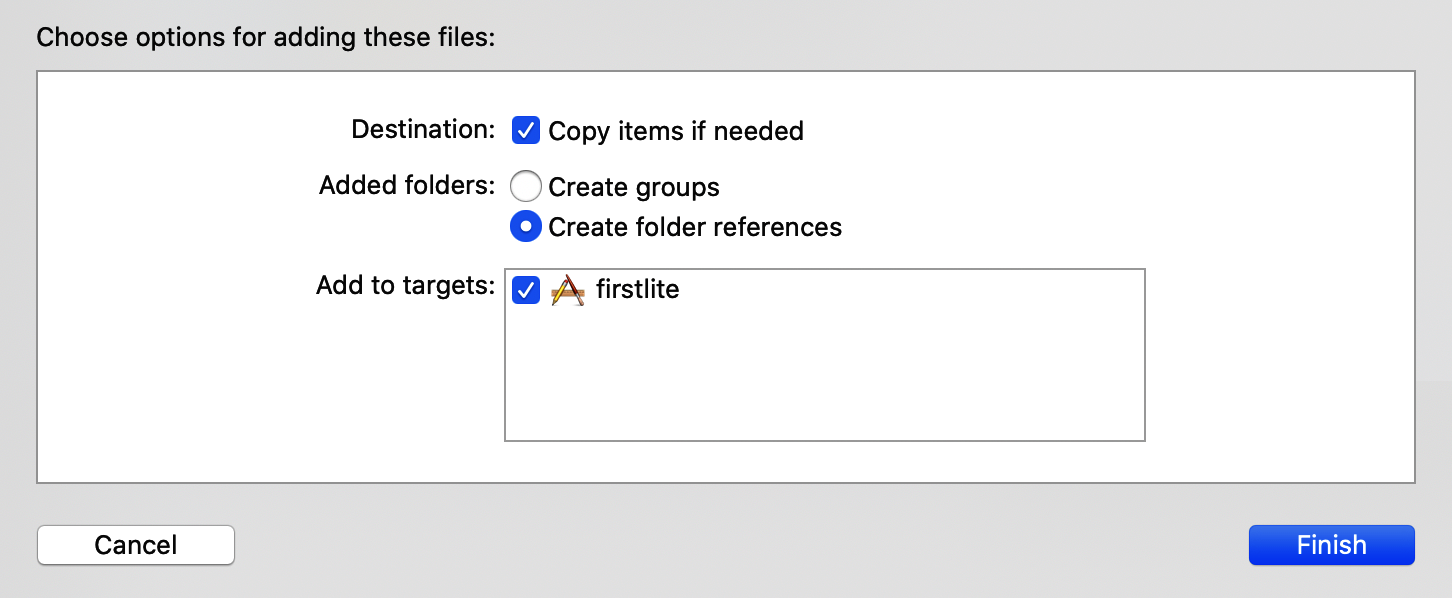
图 14-11。将模型添加到您的项目
该模型现在将在您的项目中并可用于推理。最后一步是完成用户界面逻辑——然后您就可以开始了!
步骤 7. 添加 UI 逻辑
之前,您创建了故事板ard 包含 UI 描述并开始编辑包含 UI 逻辑的ViewController.swift文件。由于大部分推理工作现在已经卸载到ModelParser类中,UI 逻辑应该非常轻量级。
首先添加一个声明ModelParser类实例的私有变量:
private var modelParser: ModelParser? =
ModelParser(modelFileInfo: ModelFile.modelInfo) 之前,您在名为 的按钮上创建了一个动作btnGo。这将在用户触摸按钮时调用。更新它以执行用户执行该操作时调用的函数doInference:
@IBAction func btnGo(_ sender: Any) {
doInference()
}接下来您将构建doInference函数:
private func doInference() {用户将在其中输入数据的文本字段称为txtUserData。读取这个值,如果它是空的,只需将结果设置为0.00,不要理会任何推论:
guard let text = txtUserData.text, text.count > 0 else {
txtResult.text = "0.00"
return
}否则,将其转换为浮点数。如果失败,退出函数:
guard let value = Float(text) else {
return
}如果代码已达到这一点,您现在可以运行模型,将输入传递给它。剩下的ModelParser将完成,返回结果或nil. 如果返回值为nil,那么您将退出该函数:
guard let result = self.modelParser?.runModel(withInput: value) else {
return
}最后,如果你已经达到这一点,你就有了一个结果,所以你可以txtResult通过将 float 格式化为字符串来将它加载到标签(称为 )中:
txtResult.text = String(format: "%.2f", result)而已!模型加载和推理的复杂性已由ModelParser类处理,让您ViewController轻松自在。为方便起见,这里是完整的清单:
import UIKit
class ViewController: UIViewController {
private var modelParser: ModelParser? =
ModelParser(modelFileInfo: ModelFile.modelInfo)
@IBOutlet weak var txtUserData: UITextField!
@IBOutlet weak var txtResult: UILabel!
@IBAction func btnGo(_ sender: Any) {
doInference()
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
}
private func doInference() {
guard let text = txtUserData.text, text.count > 0 else {
txtResult.text = "0.00"
return
}
guard let value = Float(text) else {
return
}
guard let result = self.modelParser?.runModel(withInput: value) else {
return
}
txtResult.text = String(format: "%.2f", result)
}
}您现在已经完成了让应用程序正常工作所需的一切。运行它,您应该会在模拟器中看到它。在文本字段中键入一个数字,按下按钮,您应该会在结果字段中看到一个结果,如图 14-12所示。
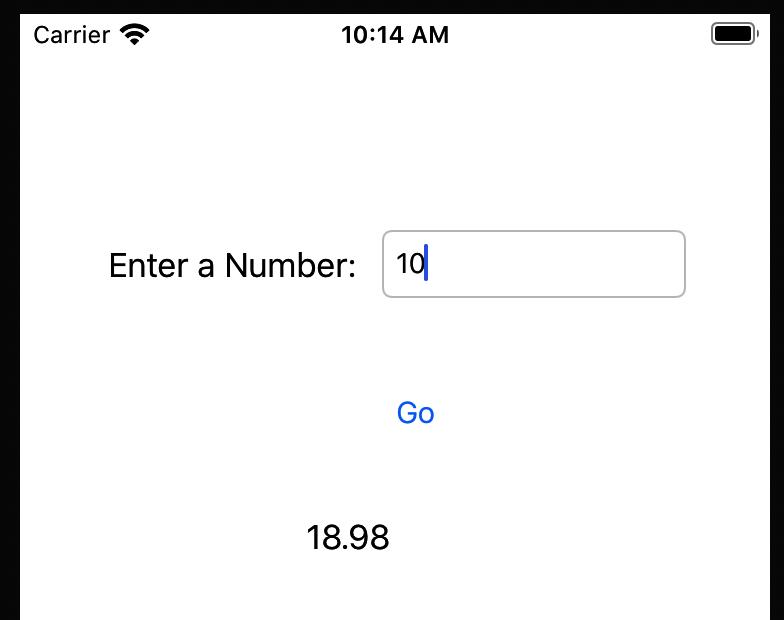
图 14-12。在 iPhone 模拟器中运行应用程序
虽然对于一个非常简单的应用程序来说这是一段漫长的旅程,但它应该提供一个很好的模板来帮助您了解 TensorFlow Lite 的工作原理。在本演练中,您了解了如何:
-
使用 pod 添加 TensorFlow Lite 依赖项。
-
将 TensorFlow Lite 模型添加到您的应用程序。
-
将模型加载到解释器中。
-
访问输入张量,并直接写入它们的内存。
-
从输出张量中读取内存并将其复制到高级数据结构,如浮点数组。
-
使用故事板和视图控制器将其全部连接到用户界面。
在下一节中,您将超越这个简单的场景,着眼于处理更复杂的数据。
超越“Hello World”——处理图像
在前面的示例中,您了解了如何创建一个完整的应用程序,该应用程序使用 TensorFlow Lite 进行非常简单的推理。然而,尽管应用程序很简单,但将数据导入模型和从模型中解析数据的过程可能有点不直观,因为您处理的是低级位和字节。当您进入更复杂的场景(例如管理图像)时,好消息是该过程并没有那么复杂。
考虑一下您在第 12 章中创建的 Dogs vs. Cats 模型。在本节中,您将了解如何使用经过训练的模型在 Swift 中创建 iOS 应用程序,给定一张猫或狗的图像,该模型将能够推断出图片中的内容。这本书的GitHub 存储库中提供了完整的应用程序代码。
一、回忆图像的张量具有三个维度:宽度、高度和颜色深度。因此,例如,当使用 Dogs vs. Cats 移动样本所基于的 MobileNet 架构时,尺寸为 224 × 224 × 3——每张图像为224 × 224像素,颜色深度为 3 个字节。请注意,每个像素由 0 到 1 之间的值表示,表示该像素在红色、绿色和蓝色通道上的强度。
在 iOS 中,图像通常表示为UIImage类的实例,它有一个有用的pixelBuffer属性,可以返回图像中所有像素的缓冲区。
在CoreImage库中,有一个CVPixelBufferGetPixelFormatTypeAPI 将返回像素缓冲区的类型:
let sourcePixelFormat = CVPixelBufferGetPixelFormatType(pixelBuffer)这通常是一个 32 位图像,带有 alpha(也称为透明度)、红色、绿色和蓝色通道。但是,有多种变体,通常这些通道的顺序不同。您需要确保它是这些格式之一,因为如果图像以不同的格式存储,其余代码将无法工作:
assert(sourcePixelFormat == kCVPixelFormatType_32ARGB ||
sourcePixelFormat == kCVPixelFormatType_32BGRA ||
sourcePixelFormat == kCVPixelFormatType_32RGBA)作为所需的格式是 224 × 224,这是正方形,接下来最好的办法是使用属性将图像裁剪到其中心最大的正方形,centerThumbnail然后将其缩小到 224 × 224:
let scaledSize = CGSize(width: 224, height: 224)
guard let thumbnailPixelBuffer =
pixelBuffer.centerThumbnail(ofSize: scaledSize)
else {
return nil
}现在您已将图像调整为 224 × 224,下一步是删除 alpha 通道。请记住,该模型是在 224 × 224 × 3 上训练的,其中 3 是 RGB 通道,因此没有 alpha。
现在你有一个像素缓冲区,你需要从中提取 RGB 数据。这个辅助函数通过找到 alpha 通道并将其切出来为您实现这一点:
private func rgbDataFromBuffer(_ buffer: CVPixelBuffer,
byteCount: Int) -> Data? {
CVPixelBufferLockBaseAddress(buffer, .readOnly)
defer { CVPixelBufferUnlockBaseAddress(buffer, .readOnly) }
guard let mutableRawPointer =
CVPixelBufferGetBaseAddress(buffer)
else {
return nil
}
let count = CVPixelBufferGetDataSize(buffer)
let bufferData = Data(bytesNoCopy: mutableRawPointer,
count: count, deallocator: .none)
var rgbBytes = [Float](repeating: 0, count: byteCount)
var index = 0
for component in bufferData.enumerated() {
let offset = component.offset
let isAlphaComponent = (offset % alphaComponent.baseOffset) ==
alphaComponent.moduloRemainder
guard !isAlphaComponent else { continue }
rgbBytes[index] = Float(component.element) / 255.0
index += 1
}
return rgbBytes.withUnsafeBufferPointer(Data.init)
}extension Data {
init<T>(copyingBufferOf array: [T]) {
self = array.withUnsafeBufferPointer(Data.init)
}
}现在您可以将刚刚创建的缩略图像素缓冲区传递给rgbDataFromBuffer:
guard let rgbData = rgbDataFromBuffer(
thumbnailPixelBuffer,
byteCount: 224 * 224 * 3
)
else {
print("Failed to convert the image buffer to RGB data.")
return nil
}此时,您拥有模型期望格式的原始 RGB 数据,您可以将其直接复制到输入张量:
try interpreter.allocateTensors()
try interpreter.copy(rgbData, toInputAt: 0)try interpreter.invoke()
outputTensor = try interpreter.output(at: 0)在 Dogs vs. Cats 的情况下,您有一个包含两个值的浮点数组作为输出,第一个是图像是猫的概率,第二个是它是狗的概率。这是与您之前看到的相同的结果代码,并且它使用与Array上一个示例相同的扩展名:
let results = [Float32](unsafeData: outputTensor.data) ?? []如您所见,尽管这是一个更复杂的示例,但相同的设计模式仍然适用。您必须了解模型的架构以及原始输入和输出格式。然后,您必须按照模型预期的方式构建输入数据——这通常意味着深入到您写入缓冲区的原始字节,或者至少使用数组进行模拟。然后,您必须读取来自模型的原始字节流,并创建一个数据结构来保存它们。从输出的角度来看,这几乎总是像我们在本章中看到的那样——一个浮点数数组。使用您已实施的帮助程序代码,您已经完成了大部分工作!
TensorFlow Lite 示例应用程序
这TensorFlow 团队已经构建了大量示例应用程序,并且还在不断添加。有了您在本章中学到的知识,您将能够探索它们并理解它们的输入/输出逻辑。在撰写本文时,iOS 有以下示例应用程序:
图片分类 :读取设备的摄像头并对多达一千种不同的项目进行分类。
物体检测 :读取设备的摄像头并为检测到的对象提供边界框。
姿势估计 :看看相机中的人物并推断他们的姿势。
语音识别 :识别常见的口头命令。
手势识别 :训练手势模型并在相机中识别它们。
图像分割 :类似于目标检测,但预测图像中每个像素属于哪个类别。
数字分类器 :识别手写数字。
概括
在本章中,您通过全面演练构建一个使用解释器调用模型来执行推理的简单应用程序,了解了如何将 TensorFlow Lite 整合到 iOS 应用程序中。特别是,您看到了在处理模型时如何必须对数据进行低级处理,以确保您的输入与模型的预期相匹配。您还看到了如何解析来自模型的原始数据。这只是将机器学习交到 iOS 用户手中的漫长而有趣的旅程的开始。在下一章中,我们将从本机移动开发转向了解如何使用 TensorFlow.js 在浏览器中对模型进行训练和运行推理。