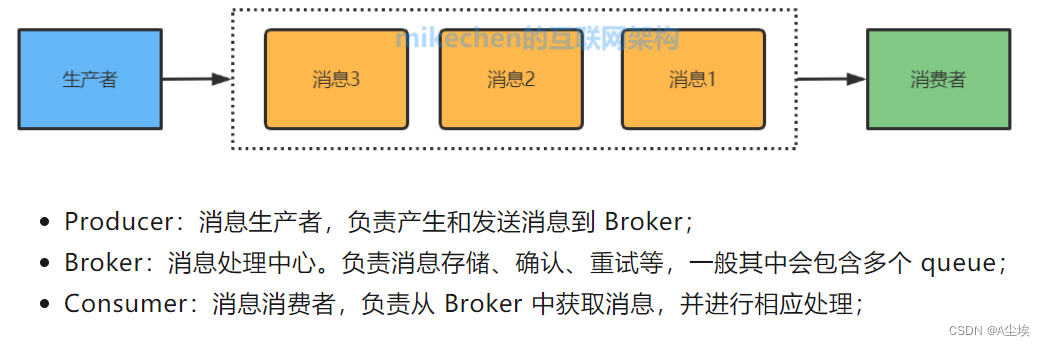
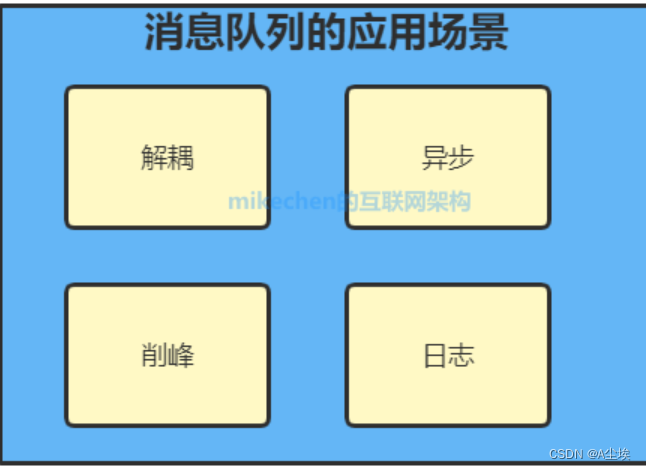
消息队列是一种应用程序之间通过异步通信进行数据交换的通信模式
消息队列的类型:
- 点对点,一对一的消息传递模型,其中每个消息只能被一个接收者消费。发送者将消息发送到队列中,而接收者从队列中获取消息并进行处理,一旦消息被接收者消费,它将从队列中删除。这种模型适用于需要可靠传递的消息,以及需要确保消息只被一个接收者处理的场景。
- 发布订阅,一对多的消息传递模型,其中消息被发送到一个主题(Topic),而订阅该主题的所有接收者都会接收到该消息。
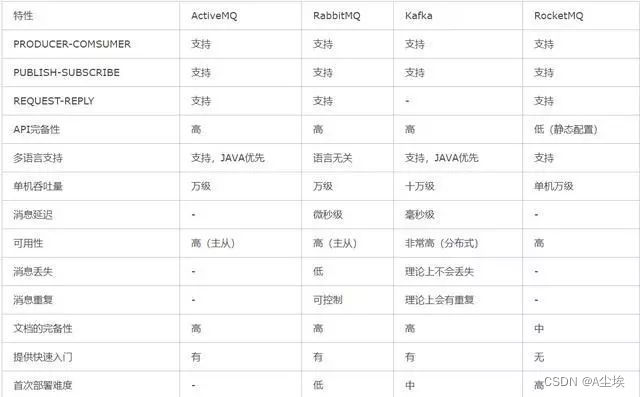
总结:ZeroMQ小而美,RabbitMQ大而稳,Kakfa和RocketMQ快而强劲
RabbitMQ
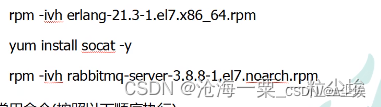
一、安装
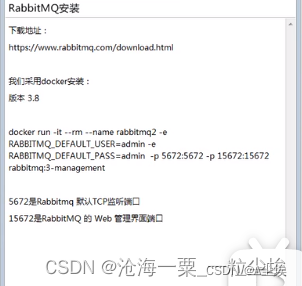
- 官网https://www.rabbitmq.com/download.html
- 文件上传/usr/local/software目录(erland提前的语言环境 + rabbitmq-server)
3. 常用命令进行设置

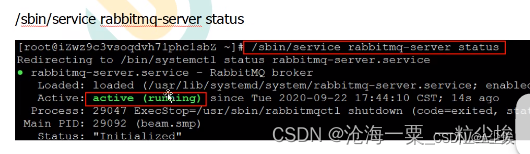
4. 查看服务状态
-
停止服务
/sbin/service rabitmq-server stop -
开启web管理
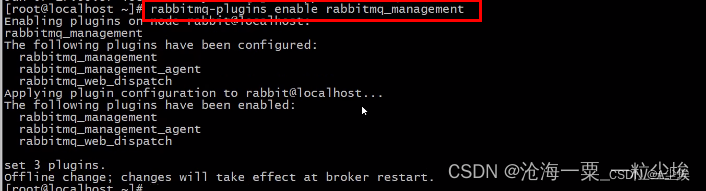
-
查看防火墙状态,需要关闭防火墙(关闭防火墙,并指定下次开机不需要开启防火墙)


-
/sbin/service rebbitmq-server start 重新启动,然后通过浏览器进行访问
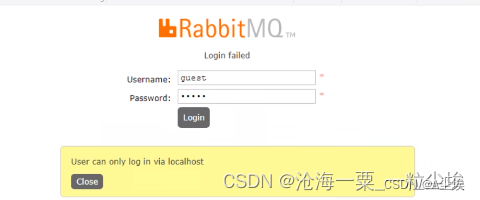
创建用户以及权限

重新使用admin的方式进行登录
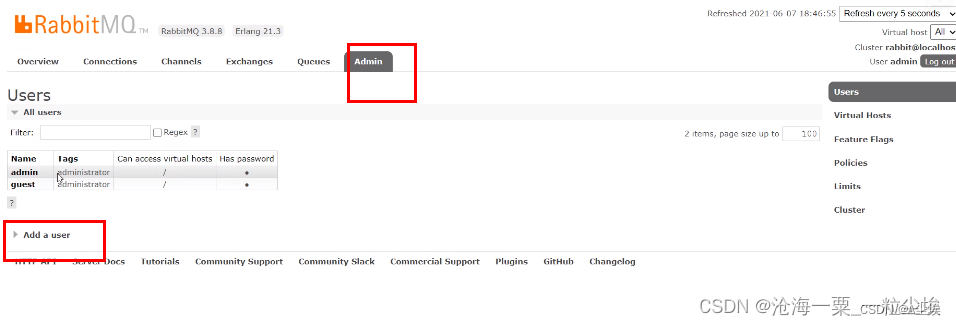
通过用户界面添加新用户
docker方式安装
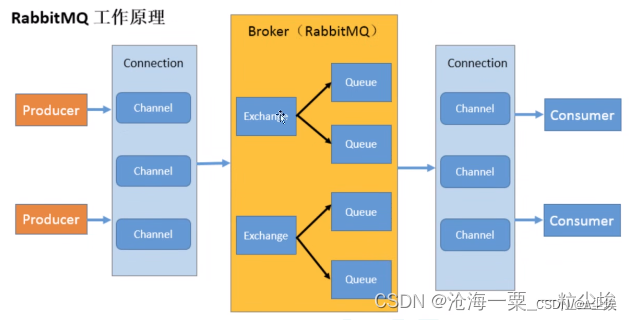
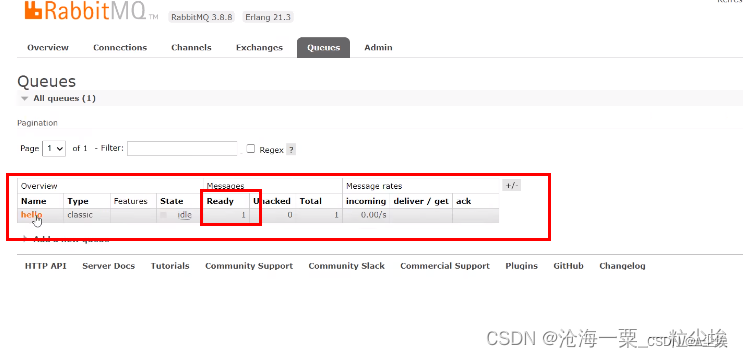
二、使用Rabbit

/**
消息生产者
*/
public class Producer{
//队列名称
public static final String Queue_NAME = "hello";
//发消息
public static void main(){
//创建连接工厂
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.200.129");
factory.setUsername("admin");
factory.setPassword("123");
//创建连接
Connection conneciton = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
生成一个队列
参数:队列名,是否持久化(默认是存储内存),是否提供一个消费者进行消费(true多个消费者共享)
是否自动删除(true是不自动删除),其他参数
*/
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
String message = "hello world";//发送消息
//参数:发送到哪个交换机,路由key是哪个,其他参数,发送消息的消息体
channel.basicPublish("",QUEUE_NAME,null,message.getBytes())
System.out.println("消息发送完毕");
}
}
/**
消息消费者
*/
public class Consumer{
//队列名称(必须和生产者的队列名称一致)
public static final String QUEUE_NAME = "hello";
//接收消息
public static void main(String[] args){
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.200.129");
factory.setUsername("admin");
factory.setPassword("123");
//创建连接
Connection conneciton = factory.newConnection();
//获取信道
Channel channel = connection.createChannel();
/**
消费者消费消息
参数:消费哪个队列,消费成功后是否应答(true标识自动应答,false手动应答)
消费者未成功消费的回调
*/
DeliverCallback deliverCallback = (consumerTag,messaage) -> {
System.out.println(new String(message.getBody()));
}
//取消消息时回调
CancelCallack cancelCallback = consumerTag -> {
System.out.println("消息消费被中断");
}
channel.basicConsume(QUEUE_NAME,trye,deliverCallback,cancelCallback);
}
}
三、工作模式的场景
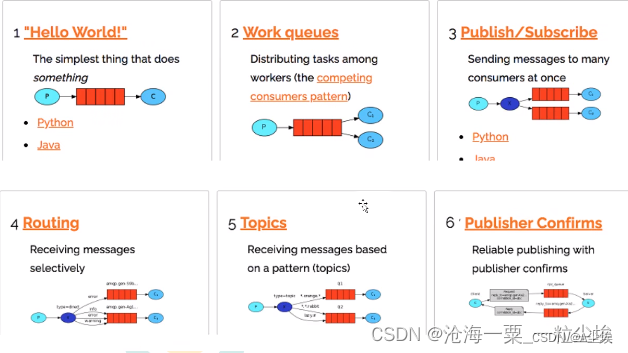
work queues:一个消息只能被处理一次,不可以处理多次,消费者(工作线程)采用轮询的方式依次接收消息。
默认是轮询机制,如果两个消费者的处理时间差距大,必须采用处理消息快的能够多次消费到消息
//抽取工具类,将连接工厂、创建信道抽取为一个工具
public class RabbitMqUtils{
public static Channel getChannel() throws Exception{
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("182.92.234.71");
factory.setUsername("admin");
factory.setPassword("123");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
return channel;
}
}
//消费者,工作线程
publci class Worker01{
//队列名称
public static final String QUEUE_NAME = "hello";
public static void main(String[] args){
Channel channel = RabbitMqUtils.getChannel();
//消息接收
DeliverCallback deliverCallback = (sonsumerTag,message) -> {
System.out.println("接收到的消息"+new String(message.getBody()));
};
//消息被取消执行
CancelCallback cancelCallback = (consumerTag) -> {
System.out.println(consumerTag+"消费者取消消费接口回调逻辑");
};
/**
参数:
消费哪个队列,
消费成功之后是否要自动应答true,手动应答false
消费者未成功消费的回调
消费者取消消费的回调
*/
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}
}
采用idea工具,模拟多线程消费
//生产者,发送大量消息
public class Task01{
//队列名称
public static final String QUEUE_NAME = "hello";
//发送大量消息
public static void main(String[] args){
Channel channel = RabbitMqUtils.getChannel();
/**
参数:
队列名称
队列里的消息是否持久化,默认是内存中
队列消息是否只供一个消费者进行消费,true多个消费者,false一个消费者
是否自动删除,最后一个消费者断开连接true自动删除,false不自动删除
其他参数
*/
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
//从控制台接收信息
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("发送消息完成:"+message);
}
}
}
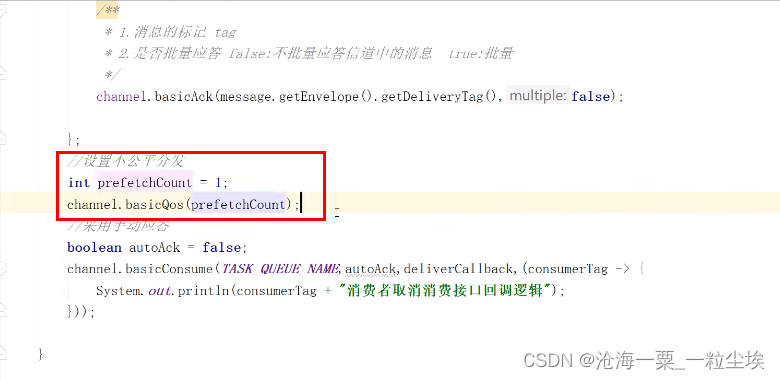
不公平分发,消费者 接收消息设置参数channelasicQos(1),每个消费者都需要设置
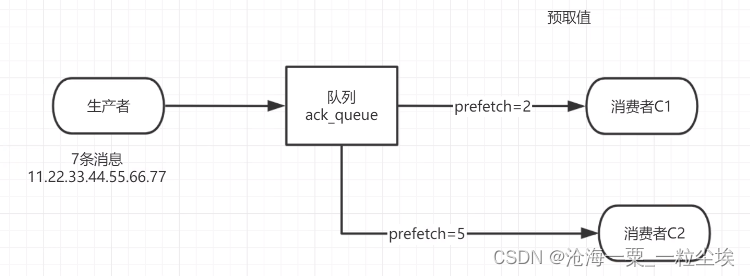
预取值,提前指定消费者
设置方式和不公平分发一样

四、集群
镜像模式搭建RabbitMQ集群
- 3台节点,每台节点都执行如下,启动RabbitMQ

通过浏览器ip依次访问3台节点

- 对3个节点依次操作

- 浏览器进行访问验证
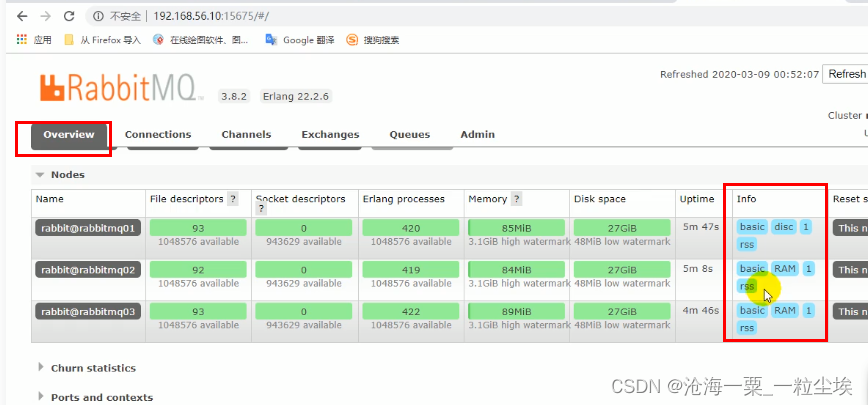
- 对普通集群进行镜像集群的转化

- 通过浏览器进行对任意一个队列的创建队列,发送消息。看其他节点是否一致
五、RabbitMQ 如何保证全链路数据100%不丢失 ?
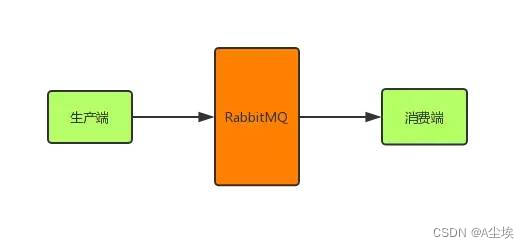
消息从生产端到消费端消费要经过3个步骤:
- 生产端发送消息到RabbitMQ
- RabbitMQ发送消息到消费端
- 消费端消费这条消息
生产端可靠性投递:
丢失原因,消息在网络传输的过程中发生网络故障消息丢失;消息投递到RabbitMQ时RabbitMQ挂了,那消息也可能丢失
针对以上情况,RabbitMQ提供的机制:
①、事务消息机制:由于会严重降低性能,一般不采用,而采用另一种轻量级的解决方案:confirm消息确认机制
②、confirm消息确认机制:生产端投递的消息一旦投递到RabbitMQ后,RabbitMQ就会发送一个确认消息给生产端,让生产端知道我已经收到消息了,否则这条消息就可能已经丢失了,需要生产端重新发送消息了。
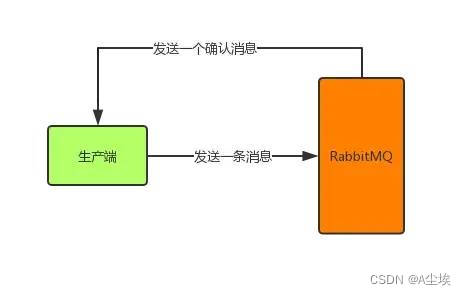
通过以下代码来开启确认模式
channel.confirmSelect();//开启发送方确认模式
然后异步监听确认和未确认的消息
channel.addConfirmListener(new ConfirmListener(){
//消息正确到达broker
@Override
public void handleAck(long deliveryTag,boolean multiple) throws IOException{
System.out.println("已收到消息");
//做一些其他处理
}
//RabbitMQ因为自身内部错误导致消息丢失,就会发送一条nack消息
@Override
public void handlerNack(long deliveryTag,boolean multiple) throws IOException{
System.out.println("未确认消息,标识:" + deliveryTag);
//做一些其他处理,比如消息重发等
}
});
消息持久化:
RabbitMQ收到消息后将这个消息暂时存在了内存中,那这就会有个问题,如果RabbitMQ挂了,那重启后数据就丢失了,所以相关的数据应该持久化到硬盘中,这样就算RabbitMQ重启后也可以到硬盘中取数据恢复。那如何持久化呢?
message消息到达RabbitMQ后先是到exchange交换机中,然后路由给queue队列,最后发送给消费端。
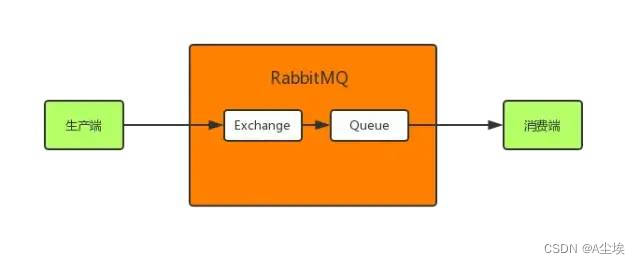
需要给exchange、queue和message都进行持久化:
①、exchange持久化
//第三个参数true标识这个exchange持久化
channel.exchangeDeclare(EXCHANGE_NAME,"direct",true);
②、queue持久化
//第二个参数true表示这个queue持久化
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
队列持久化:声明队列的时候把durable参数设置为持久化,当rabbitmq重启后队列不会被删除掉
如果之前声明的队列不是持久化,需要把原先队列删除,或者重新创建一个队列,否职责会报错

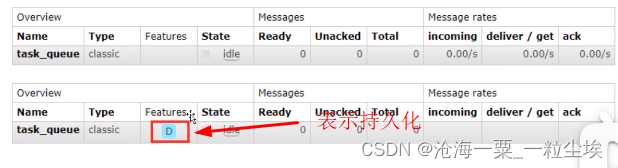
③、message持久化
//第三个参数MessageProperties.PERSISTENT_TEXT_PLAIN表示这条消息持久化
channel.basicPublish(EXCHENGE_NAME,ROUTING_KEY,MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes(StandardCharsets.UTF_8));
消息持久化:消息生产者MessageProperties.PERSISTENT_TEXT_PLAIN

这样,如果RabbitMQ收到消息后挂了,重启后会自行恢复消息。
RabbitMQ收到消息还没来得及将消息持久化到硬盘时,RabbitMQ挂了,这样消息还是丢失了,或者RabbitMQ在发送确认消息给生产端的过程中,由于网络故障而导致生产端没有收到确认消息,这样生产端就不知道RabbitMQ到底有没有收到消息,就不好做接下来的处理。
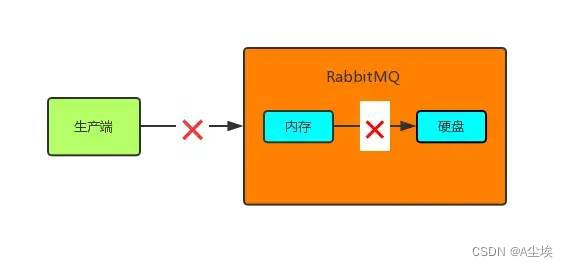
所以除了RabbitMQ提供的一些机制外,我们自己也要做一些消息补偿机制,以应对一些极端情况。其中的一种解决方案——消息入库。
将要发送的消息保存到数据库中。
首先发送消息前先将消息保存到数据库中,有一个状态字段status=0,表示生产端将消息发送给了RabbitMQ但还没收到确认。在生产端收到确认后将status设为1,表示RabbitMQ已收到消息。
这里有可能会出现上面说的两种情况,所以生产端这边开一个定时器,定时检索消息表,将status=0并且超过固定时间后(可能消息刚发出去还没来得及确认这边定时器刚好检索到这条status=0的消息,所以给个时间)还没收到确认的消息取出重发(第二种情况下这里会造成消息重复,消费者端要做幂等性),可能重发还会失败,所以可以做一个最大重发次数,超过就做另外的处理。
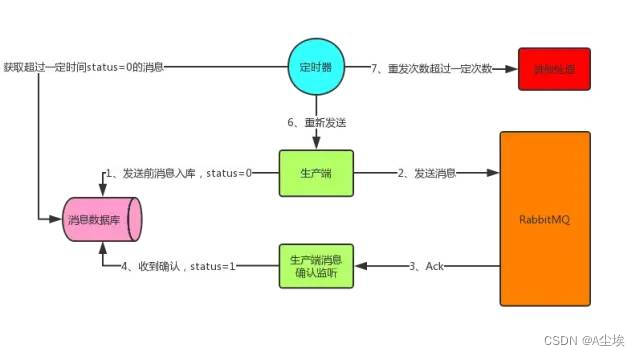
这样消息就可以可靠性投递到RabbitMQ中了,而生产端也可以感知到了。
消费端可靠性接收:
一、在RabbitMQ将消息发出后,消费掉还没接收之前,发送网络故障,消费端与RabbitMQ断开连接,此时消息会丢失。
二、在RabbitMQ将消息发出后,消费端还没接收到消息,消费端挂了,消息会丢失
三、消费端接收到消息,但在处理消息的过程中发生异常,宕机。消息也会丢失。

上述3中情况导致消息丢失归根结底是因为RabbitMQ的自动ack机制,即默认RabbitMQ在消息发出后就立即将这条消息删除,而不管消费端是否接收到,是否处理完,导致消费端消息丢失时RabbitMQ自己又没有这条消息了。
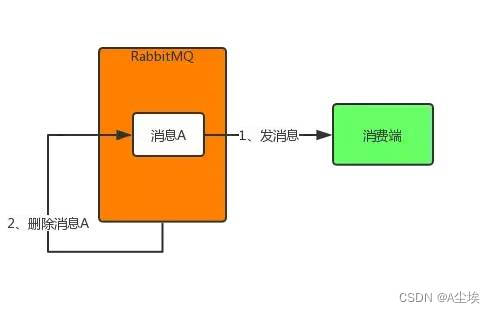
所以就需要将自动ack机制改为手动ack机制
当autoAck参数置为false,对于RabbitMQ服务端而言,队列中的消息分成了两个部分:
- 一部分是等待投递给消费端的消息
- 一部分是已经投递给消费端,但是还没有收到消费端确认信号的消息
应答机制:
- 自动应答
- 手动应答(手动应答三个方法):

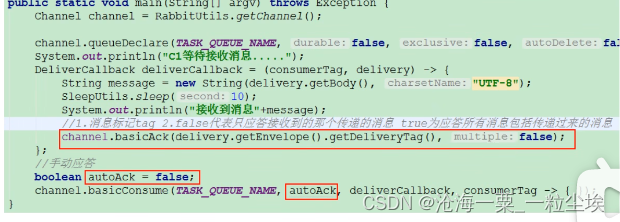
DeliverCallback deliverCallback = (consumerTag,delivery) -> {
try{
//接收到消息,做处理
//手动确认
channel.basicAck(delivery.getEnvelope().getDeliveryTag(),false);
}catch(Exception e){
//出错处理,这可以让消息重回队列重新发送或直接丢弃消息
}
};
//第二个参数autoAck设为false表示自动关闭确认机制,需要手动确认
channel.basicConsume(QUEUE_NAME,false,deliverCallback,consumerTag -> {
});
当消息被消费者完全处理后,队列才能删除消息。否则会一旦消费者出现故障,消息未被完全处理就被队列删除,造成消息丢失。
消息自动重新入队:
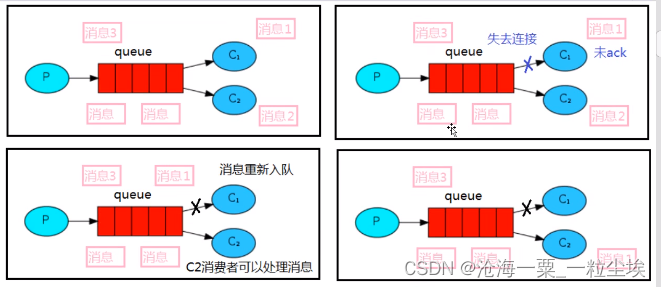
当接收消息的C1突然宕机,队列会重新安排消息进入队列,让其他消费者进行处理
//消息生产者
public class Task02{
//队列名称
public static final String task_queue_name = "ack_queue";
publix static void main(String[] args){
Channel channel = RabbitMqUtils.getChannel();
channel.queueDeclare(TASK_QUEUE_NAME,false,false,false,null);
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String message = scanner.next();
channel.basicPublish("",TASK_QUEUE_NAME,null,message.getBytes("UTF-8"));
System.out.println("生产者发出消息:"+message)
}
}
}
//消息消费者一,消息在手动应答时不丢失,放回队列中重新消费
public class Work01{
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args){
Channel channel = RabbitMqUtils.getChannel();
System.out.println("C1等待接收消息处理时间较短");
DeliverCallback deliverCallback = (consumerTag,message) -> {
//模拟处理业务
Thread.sleep(1000);
System.out.println("接收到的消息:"+ new String(message.getBody(),"UTF-8"));
//手动应答(消息的标记,不批量处理应答)
channel.basicAck(message.getEnvelope(),getDeliveryTag(),false);
};
//采用手动应答
boolean autoAck = false;
channel.basicConsumer(TASK_QUEUE_NAME,autoAck,(consumerTag -> {
System.out.println(consumerTag+"消费者取消消费接口回调逻辑");
}));
}
}
//消息消费者二,消息在手动应答时不丢失,放回队列中重新消费
public class Work02{
public static final String TASK_QUEUE_NAME = "ack_queue";
public static void main(String[] args){
Channel channel = RabbitMqUtils.getChannel();
System.out.println("C1等待接收消息处理时间较短");
DeliverCallback deliverCallback = (consumerTag,message) -> {
//模拟处理业务较长
Thread.sleep(1000000);
System.out.println("接收到的消息:"+ new String(message.getBody(),"UTF-8"));
//手动应答(消息的标记,不批量处理应答)
channel.basicAck(message.getEnvelope(),getDeliveryTag(),false);
};
//采用手动应答
boolean autoAck = false;
channel.basicConsumer(TASK_QUEUE_NAME,autoAck,(consumerTag -> {
System.out.println(consumerTag+"消费者取消消费接口回调逻辑");
}));
}
}
消息生产者发送消息后,C2处理时间较长,还未处理完就宕机,此时会看到C1接收到了
说明消息队列被重新入队了。

如果RabbitMQ一直没有收到消费端的确认信号,并且消费此消息的消费端已经断开连接或宕机(RabbitMQ会自己感知到),则RabbitMQ会安排该消息重新进入队列(放在队列头部),等待投递给下一个消费者,当然也有能还是原来的那个消费端,当然消费端也需要确保幂等性。
RocketMQ
RocketMQ主要由NameServer、Broker、Producer以及Consumer四部分构成。
- NameServer:主要负责对于源数据的管理,包括了对于Topic和路由信息的管理。每个NameServer节点互相之间是独立的,没有任何信息交互
- Broker:消息中转角色,负责存储消息,转发消息。单个Broker节点与所有的NameServer节点保持长连接及心跳,并会定时将Topic信息注册到NameServer,顺带一提底层的通信和连接都是基于Netty实现的。
- Producer:负责产生消息,一般由业务系统负责产生消息。由用户进行分布式部署,消息由Producer通过多种负载均衡模式发送到Broker集群,发送低延时,支持快速失败。
- Consumer:负责消费消息,一般是后台系统负责异步消费。由用户部署,支持PUSH和PULL两种消费模式,支持集群消费和广播消息,提供实时的消息订阅机制

流程:
- Broker在启动的时候会去向NameServer注册并且定时发送心跳,Producer在启动的时候会到NameServer上去拉取Topic所属的Broker具体地址,然后向具体的Broker发送消息。
消息领域模型:分为Message、Topic、Queue、Offset以及Group这几部分。
- Topic标识消息的第一级类型,比如一个电商系统的消息可以分为:交易消息、物流消息等。一条消息必须有一个Topic。
- Tag表示消息的第二级类型,比如交易消息又可以分为:交易创建消息,交易完成消息等。RocketMQ提供2级消息分类
- Group组,一个组可以订阅多个Topic。
- Message Queue消息的物理管理单位。一个Topic下可以有多个Queue,Queue的引入使得消息的存储可以分布式集群化,具有了水平扩展能力
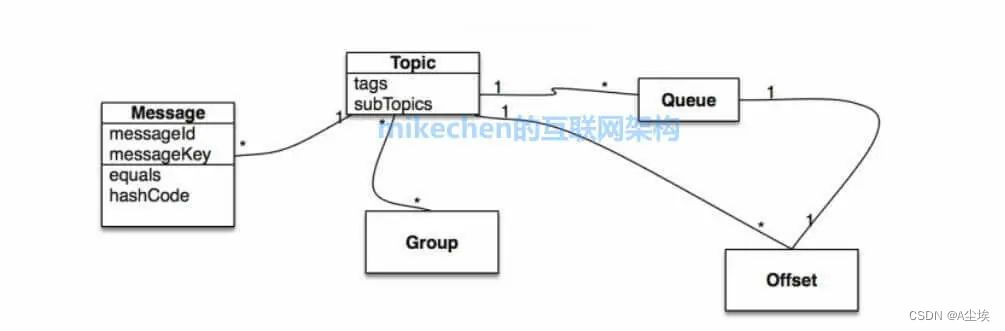
RocketMQ 中,所有消息队列都是持久化,长度无限的数据结构,所谓长度无限是指队列中的每个存储单元都是定长,访问其中的存储单元使用Offset来访问,Offset来访问,Offset为Java long类型64位。
Message Queue是一个长度无限的数组,Offset就是下标。
RocketMQ的关键特性:
①:消息的顺序,值得是消息消费时,能按照发送的顺序来消费。
例如:一个订单产生了 3 条消息,分别是订单创建、订单付款、订单完成。消费时,要按照这个顺序消费才有意义。但同时订单之间又是可以并行消费的。
RocketMQ是通过将“相同的ID的消息发送到同一个队列,而一个队列的消息只由一个消费者来处理”来实现顺序消息。
②:消息的重复,消息领域有一个对消息投递的Qos(服务质量)定义,分为:
- 最多一次:
- 至少一次:
- 仅一次:
③:消息去重
原则:使用业务端逻辑保持幂等性
就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用,数据库的结果都是唯一的,不可变的。
去重策略:保证每条消息都有唯一编号(唯一流水号),且保证消息处理成功与去重的日志同时出现。
建立一个消息表,拿到这个消息作数据库的insert操作,给这个消息做一个唯一主键或者唯一约束,那么就算出现重复消费的情况,就会导致主键冲突,那么就不再处理这条消息。
Kafka
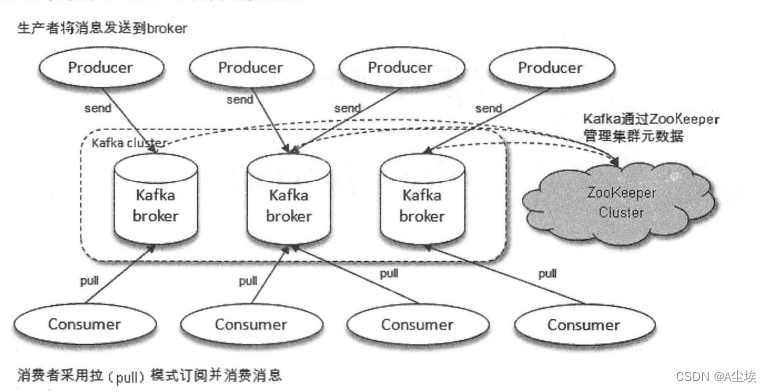
体系结构:若干个Producer,若干个Broker,若干个Consumer,一个Zookeeper集群。
Zookeeper:用来负责集群元数据的管理、控制器的选举。
Producer:将消息发送到Broker
Broker:将受到的消息存储到磁盘中
Consumer:负责从Broker订阅并消费消息
JDK+Zookeeper+kafka 的安装与配置
# jdk安装包的下载,并解压
ll jdk-8u181-linux- x64.tar.gz
tar zxvf jdk-8u181-linux- x64.tar.gz
#解压之后当前/opt目录下生成一个名为jdk1.8.0_181的文件夹
cd jdk1.8.0_181/
pwd
/opt/jdk1.8.0_181
配置JDK环境变量,修改/etc/prifile文件并向其添加如下配置
export JAVA_HOME=/opt/jdk1.8.0_181
export JRE_HOME=$JAVA_HOME/jre
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=./://$JAVA_HOME/LIB:$JRE_HOME/lib


![[vulntarget靶场] vulntarget-c](https://img-blog.csdnimg.cn/03c4e38da3fe4bcd80d6e18652a403f2.png)