Spectral–Spatial Feature Partitioned Extraction Based on CNN for Multispectral Image Compression
(基于CNN的光谱-空间特征分割提取多光谱图像压缩)
近年来,多光谱成像技术的迅速发展引起了各领域的高度重视,这就不可避免地涉及到图像的传输和存储问题。针对这一问题,提出了一种基于光谱空间特征分割提取的端到端多光谱图像压缩方法。整个多光谱图像压缩框架是基于卷积神经网络(CNN),其创新之处在于特征提取模块被分为两个并行部分,一个是光谱部分,另一个是空间部分。首先,利用光谱特征提取模块独立提取光谱特征,并对空间特征提取模块进行操作以获得分离的空间特征。在特征提取之后,光谱和空间特征被逐元素融合,随后进行下采样,这可以减小特征图的大小。然后,通过量化和无损熵编码将数据转换为比特流。为了使数据更加紧凑,向网络添加了率失真优化器。解码器是编码器的相对逆过程。为了比较,所提出的方法进行了测试沿着JPEG 2000,3D-SPIHT和ResConv,另一个基于CNN的算法从Landsat-8和WorldView-3卫星的数据集。实验结果表明,在相同码率下,该算法的性能优于其他方法。
Introduction
通过捕获几个连续窄光谱带的数字图像,传感器可以生成包含丰富光谱和空间信息的三维多光谱图像。这些丰富的信息在军事侦察、目标监视、农作物状况评估、地表资源调查、环境研究、海洋应用等方面有着广泛的应用。然而,随着多光谱成像技术的快速发展,多光谱数据的光谱空间分辨率越来越高,导致其数据量迅速增长。庞大的数据量不利于图像的传输、存储和应用,阻碍了相关技术的发展。因此,有必要找到一种有效的多光谱图像压缩方法,在使用前对图像进行处理。
多光谱图像压缩方法的研究一直受到广泛关注。经过几十年的不懈努力,针对不同应用需求,开发出了各种多光谱图像压缩算法,可以概括如下:基于预测编码的框架、基于矢量量化编码的框架、基于变换编码的框架。预测编码主要应用于无损压缩。它的基本原理是利用像素之间的相关性来预测未知数据的基础上,然后对真实的值和预测值之间的残差进行编码。在[6]中,Slyz等人提出了一种基于块的带间无损多光谱图像压缩方法,将每幅图像分割成块,并利用相邻带中对应的块预测当前块。对于矢量量化编码,将若干标量数据集形成一个矢量,然后在矢量空间中将数据作为一个整体量化,以便在不损失太多信息的情况下进行压缩。由于矢量量化编码的性能与码本密切相关,为了提高时间效率,Qian在[7]中提出了一种快速码本搜索方法。在广义Lloyd算法(GLA)的全搜索过程中,如果到分区的距离比前一次迭代的更好,则不需要搜索来找到最小距离分区。变换编码是多光谱图像压缩中的一种重要方法,在有损压缩中有着广泛的应用。该算法通过将数据转换为变换域表示来降低像素之间的相关性,从而使信息集中,从而进行量化和编码。Karhunen-Loève变换(KLT)、离散余弦变换(DCT)和离散小波变换都是常用的变换编码算法。随着我们对多光谱图像的深入了解,开发了越来越多的改进算法,如3D-SPECK、3D-SPIHT等。
上述传统的压缩方法都是有效的,取得了很好的效果,但也存在着不足。例如,实现预测编码算法简单,但是压缩比相对较低。矢量量化编码算法虽然可以达到较为理想的效果,但由于其计算复杂度,不利于实现。为了克服传统压缩方法的不足,同时又保证压缩性能,近年来许多基于深度学习的多光谱图像压缩算法得到了迅速的发展。其中,卷积神经网络(CNN)是近年来图像压缩的主要算法之一。CNN的历史始于LeNet风格的模型,该模型包括用于特征提取的卷积层和用于下采样的最大池化层的简单堆栈。为了提取更多不同尺度的特征,2012年提出的AlexNet遵循了这一思想,并通过在每两个最大池化层之间添加几个卷积层进行了改进。为了获得更好的性能,需要增加网络的深度。于是,VGG、GoogLENet 、ResNet等优秀的网络架构开始陆续涌现。这些网络框架都是图像压缩技术发展的里程碑,在以往的ILSVRC等竞赛中都取得了很好的成绩。受这些杰出的网络框架的启发,许多基于CNN的压缩方法已经出现,并显示出适用于可见图像。在[18]中,Ballé提出了一种基于CNN的端到端优化图像压缩方法,具有广义分裂归一化(GDN)联合非线性,通过灵活使用线性卷积和非线性变换,所提出的网络实现了与JPEG2000相当的性能。为了进一步提高重建图像的质量,Jiang等人将CNN添加到编码器和解码器以进行联合训练。编码器中的CNN产生用于编码的紧凑呈现,并且解码器中的另一CNN是以高质量恢复解码图像,利用其可以显著减少块效应。已知多光谱图像是三维数据,其中两个维度是空间的,一个维度是光谱的。由于RGB图像也具有三个波段,因此可以将其视为特殊的多光谱数据。因此,许多用于可见光图像的压缩方法也可以应用于多光谱图像。在[20]中,提出了具有优化残差单元的多光谱图像的端到端压缩框架。它也基于CNN,并调整了网络中采用的ResNet的默认架构,以更好地适应多光谱图像。实验证明,该算法的有效性和PSNR比JPEG2000提高了约2 dB。尽管如此,上述方法仍然未能集中在多光谱图像的光谱之间的强相关性,因为这对RGB图像不太重要。然而,对于多光谱图像压缩,忽略光谱相关性会导致压缩后的信息丢失。因此,在本文中,我们提出了一种新的多光谱图像压缩方法的基础上的光谱空间特征的分割提取。
该网络是基于CNN的端到端框架,由编码器和解码器组成。在编码器中,有两个部分分别用于光谱特征提取和空间特征提取。第一部分采用连续光谱特征提取模块独立提取光谱特征。这一部分不涉及空间信息的融合。第二部分是用于空间特征提取,其中包含多个残差块。我们使用组卷积来分离每个通道,以便只有空间特征可以提取,而不混合其中的光谱信息。然后,所有特征被融合在一起,然后采用下采样来减小特征图的大小。此外,为了使数据更紧凑,在网络中使用了速率失真优化器。在获得中间特征数据后,进行量化和无损熵编码,以获得压缩的二进制比特流。在解码器中,比特流首先经过熵解码和逆量化,然后上采样有助于恢复图像大小。最后,通过相应的反卷积操作获得光谱和空间特征,并利用联合特征重建图像。实验结果表明,该网络优于JPEG 2000和3D-SPIHT。
Proposed Method
Spectral Feature Extraction Module
二维卷积技术已被证明具有很大的应用前景,并成功地应用于图像视觉和处理的许多方面,如目标检测、图像分类和图像压缩。然而,由于多光谱图像是三维的,更加复杂,丰富的光谱信息更加重要,因此,在采用二维卷积处理多光谱图像时,不可避免地会遇到信息丢失的问题。虽然将深度学习应用于多光谱图像压缩已有很多先例,并取得了很好的性能,超过了JPEG和JPEG2000等一些传统压缩方法,但在特征提取过程中,由于卷积核是二维的,无法有效去除第三维上的光谱冗余,抑制了网络的性能。
为了解决这个问题,我们提出了分别提取光谱或空间特征的想法。其中,提取光谱特征的灵感来源于。参考文献[21]使用三维核进行卷积运算,这可以保持多光谱图像数据中光谱特征的完整性。为了避免数据量过大,在谱维上采用1 × 1 × n卷积核,称为一维谱卷积,独立提取光谱特征。图1显示了2D卷积和1D光谱卷积之间的差异。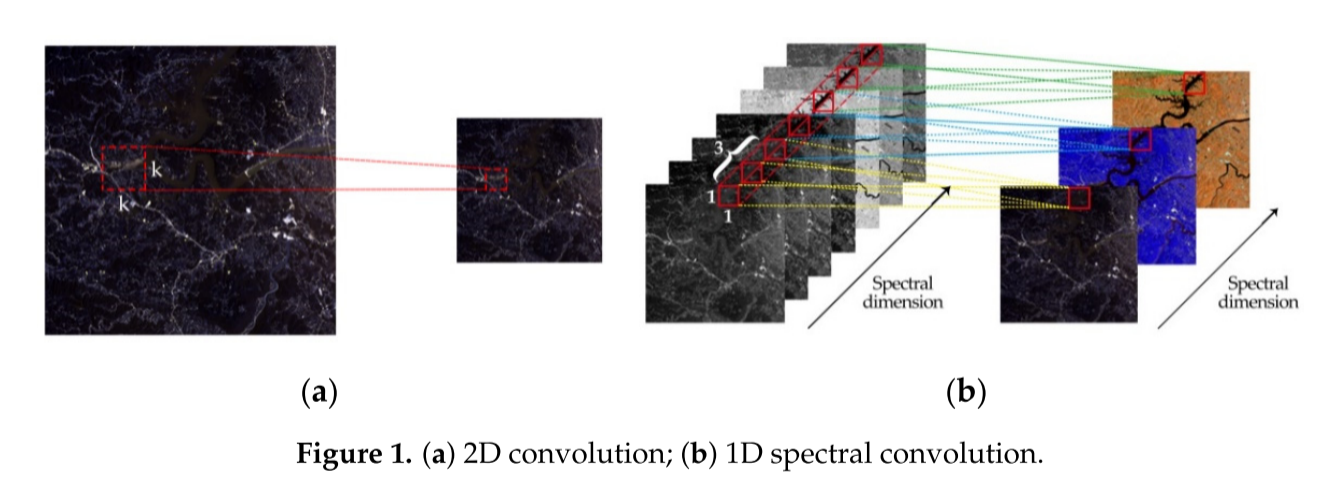
如图1a所示,图像通过2D卷积进行卷积,其内核是二维的,通常后跟激活函数,例如校正线性单元(ReLU),参数校正线性单元(PReLU)等。该操作可以表示如下:
类似地,考虑到光谱的维度,在3D图像上操作的1D光谱卷积可以公式化如下:
考虑到激活函数,我们采用ReLU作为我们的首选,因为当使用ReLU时,反向传播中的梯度通常是恒定的,这缓解了深度网络训练中梯度消失的问题,并有助于网络收敛。此外,使用ReLU时的计算成本比其他函数(例如,Sigmiod)。此外,ReLU可以使一些神经元的输出为零,这保证了网络的稀疏性,从而缓解过拟合问题。ReLU函数可以公式化如下:
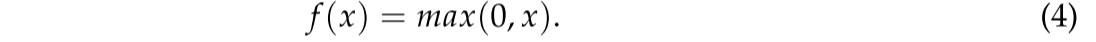
综上所述,当对三维图像进行2D卷积运算时,输出总是二维的,这可能导致大量的光谱信息丢失。因此,我们采用一维光谱卷积保留更多的多光谱图像的特征数据。
Spatial Feature Extraction Module
为了确保空间信息不与光谱特征相混合,我们使用群卷积代替空间维度上的普通二维卷积。群卷积最早出现在AlexNet,是为了解决当时硬件资源有限的问题。特征图被分发到多个GPU进行同步处理,最后连接在一起。图2显示了正常卷积和群卷积之间的区别。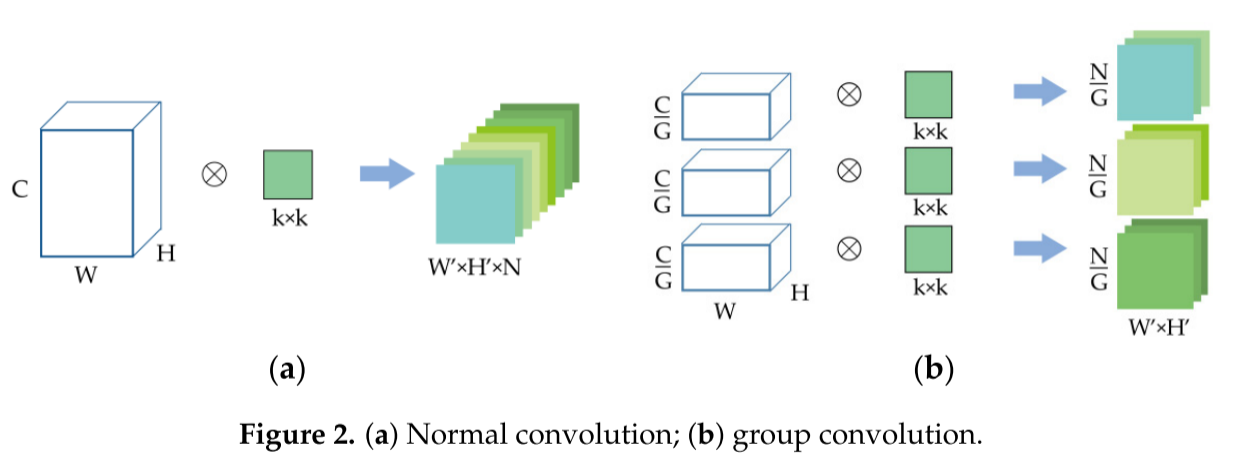
如图2a所示,输入数据的大小为C×H×W,分别表示特征图的通道数、宽度和高度。卷积核的大小为k×k,核的数目为N。这一点,输出特征图的大小为N×H’×W’。N个卷积核的参数数为:
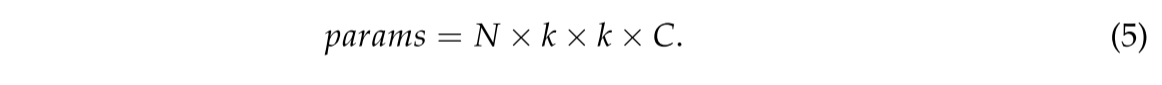
组卷积,顾名思义,将输入的特征图分成若干组,然后分别卷积。假设输入的大小仍然是C×H×W并且输出特征图的数量是N。如果将输入分成G组,则每组中的输入特征图的数量为C/G,每组中的输出特征图的数量为N/G,卷积核的大小为k×k,即卷积核的数量保持不变,每组中的核的数量为N/G。由于特征图仅由相同组的卷积核卷积,所以参数的总数可以计算为: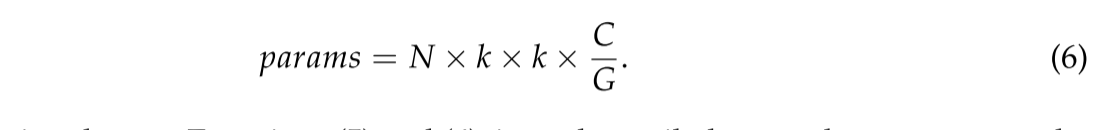
通过比较两个方程(5)和(6),可以很容易地知道,群卷积可以大大减少参数的数量,准确地说,它可以减少到1/G。此外,根据[14],由于组卷积可以增加滤波器之间的对角相关性,因此滤波器关系变得稀疏和不相关。
图3示出了相邻层的滤波器之间的相关矩阵[23],高度相关的滤波器更亮,而较低相关的滤波器更暗。滤波器组(即组卷积)的作用是利用块对角稀疏性来学习关于信道维度的信息。低相关滤波器不需要学习,也就是说,它们不需要给定参数。此外,如图3所示,当使用组卷积时,可以以更结构化的方式训练高度相关的滤波器。因此,利用结构化稀疏性,群卷积不仅可以减少参数的数量,而且可以更准确地学习,以制作更高效的网络。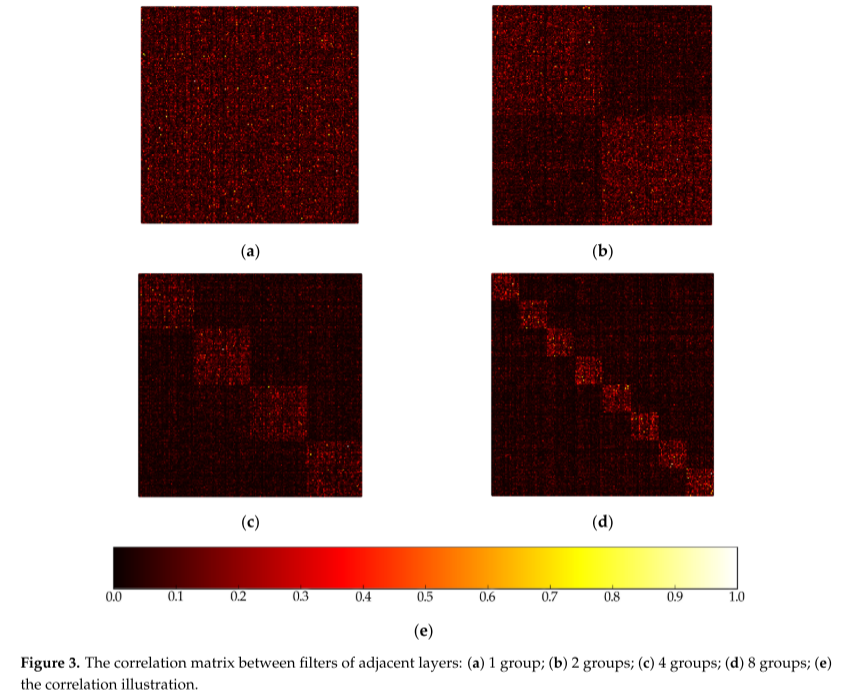
Framework ofthe Proposed Network
所提出的压缩网络的整个框架在图4中示出。该方法首先将多光谱图像送入前向网络,经过特征提取后,再经过量化和熵编码器压缩并转换为码流。解码器的结构与编码器的结构是对称的。因此,对于解码,比特流依次经过熵解码、逆量化和后向网络,以恢复图像。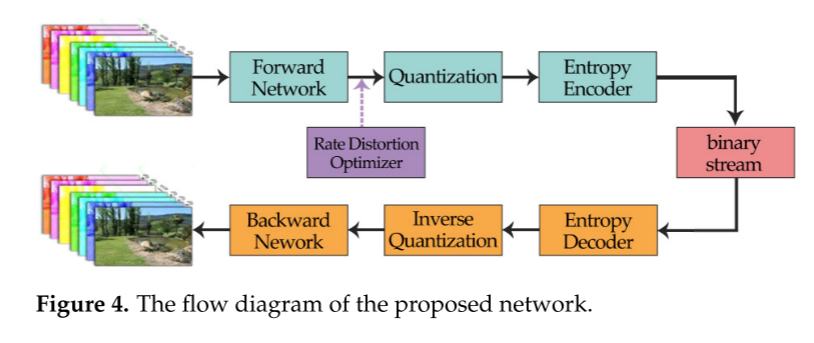
The Forward Network and the Backward Network
前向和后向网络的架构如图5所示,频谱块和空间块如图6所示。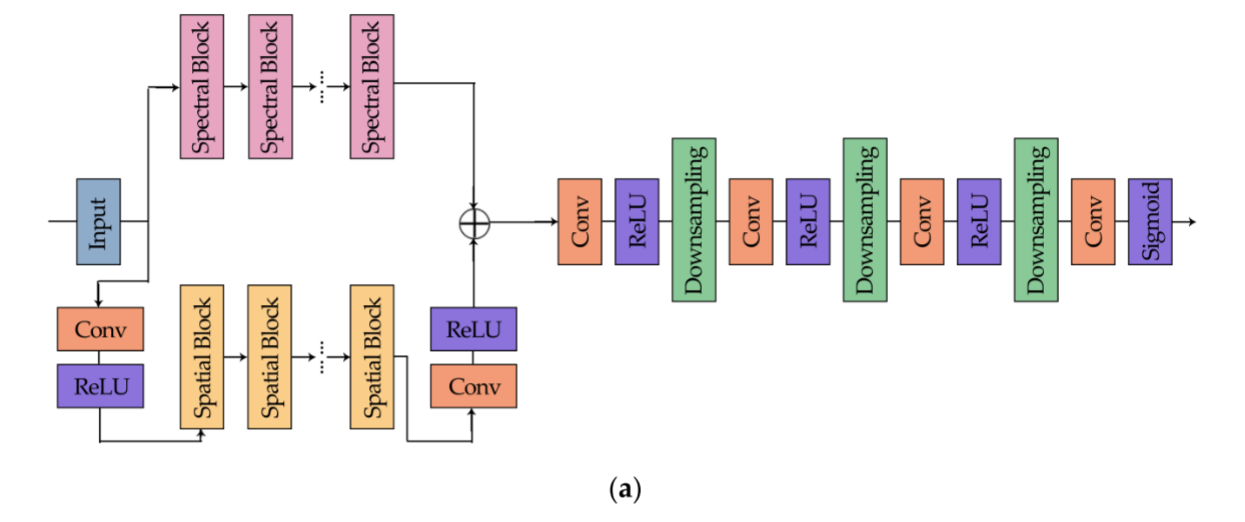
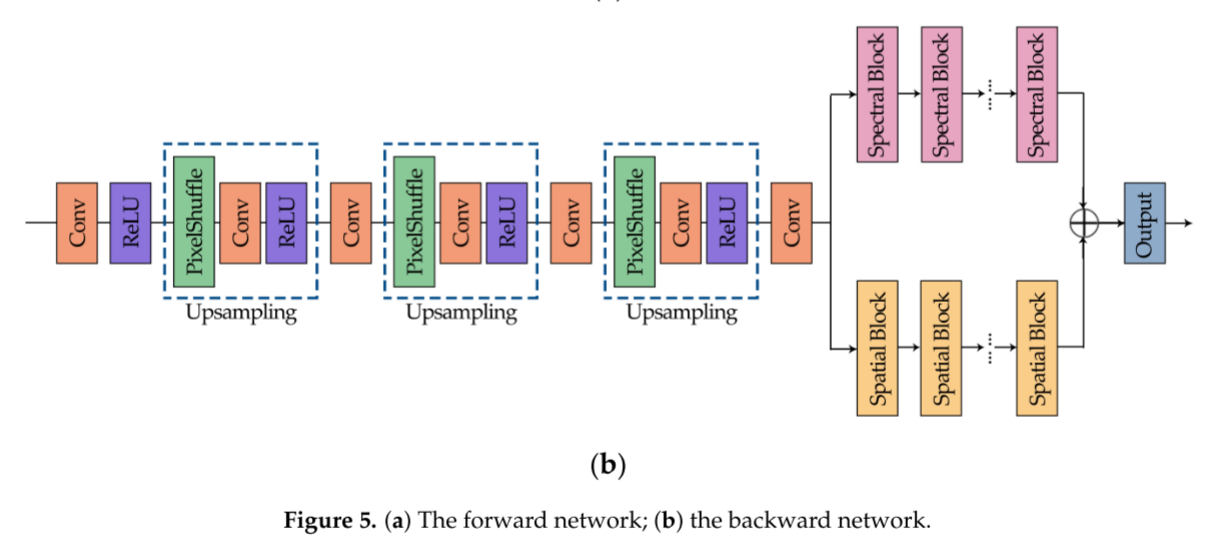
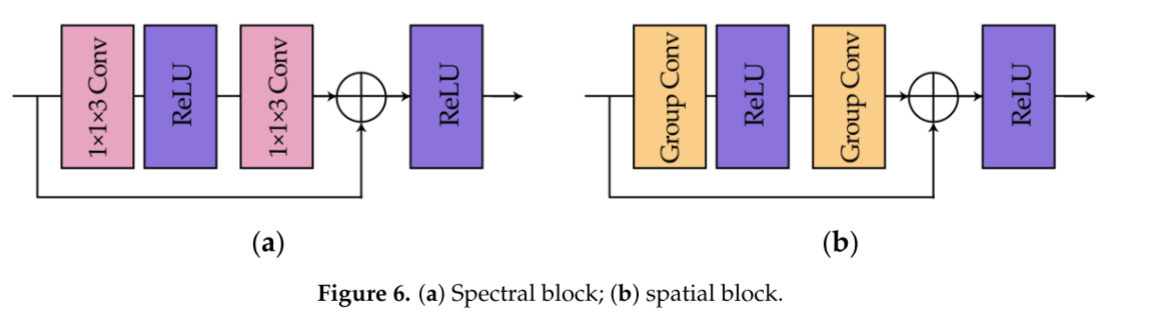
图5示出了我们的网络的详细过程。首先,将输入的多光谱图像同时分别送入光谱特征提取网络和空间特征提取网络,光谱特征提取网络和空间特征提取网络由相应的功能模块组成。在频谱部分中,存在若干频谱块(图6a),其基于残差块结构。我们将卷积层替换为调整后的1D谱卷积,以满足我们的期望,内核的大小为1×1×3。同样地,空间部分由具有类似结构的若干空间块组成,如图6 b所示,并且使用组卷积,使得每个通道将不会彼此交互。具体地,当输入多光谱图像具有七个或八个波段时,GROUP被设置为7或8。此外,为了增强特征的学习能力,增加了一些卷积层,其核大小为3 × 3。提取后,将两部分特征融合在一起,然后进行下采样以减小特征图的大小。在前向网络的末端,sigmoid函数起着限制中间输出值的作用,此外,与ReLU类似,它引入了非线性因素,使网络对模型更具表达力。
与前向网络对称,后向网络由上采样层、一些卷积层和分区提取部分形成。特别地,使用PixelShuffle实现上采样,其可以使用子像素操作将低分辨率图像变成高分辨率图像。
Quantization and Entropy Coding
在前向网络之后,中间数据首先由量化器量化成一系列离散整数。由于下降梯度用于后向传播以在训练网络时更新参数,因此梯度需要向下传递。然而,舍入函数是不可微的[25],这将阻碍网络的优化。因此,我们放松了函数,它被计算为: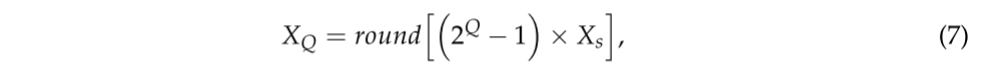
其中Q是量化级别,Xs ∈(0,1)是Sigmoid激活之后的中间数据,round[·]是舍入函数,并且XQ是量化数据。该函数对前向网络中的数据进行舍入,并在反向传播期间跳过,以将梯度直接传递到前一层。
然后,我们采用ZPAQ作为无损熵编码标准,并选择“方法-6”作为压缩模式,以便进一步处理量化的XQ并生成二进制比特流。在解码器中,比特流经过熵解码器和去量化,数据XQ/(
2
Q
2^{Q}
2Q − 1)最终被馈送到反向网络以恢复图像。
Rate-Distortion Optimizer
评价一种压缩方法有两个标准,一个是比特率,另一个是恢复图像的质量。为了提高网络的性能,在这两个标准之间取得平衡至关重要。因此,引入了率失真优化: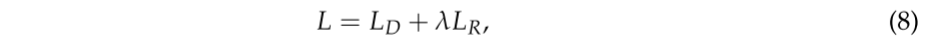
其中L是在训练期间应当最小化的损失函数,LD指示失真损失,LR表示速率损失,其可以由惩罚λ控制。当我们使用MSE来测量恢复图像的失真损失时,LD可以表示如下: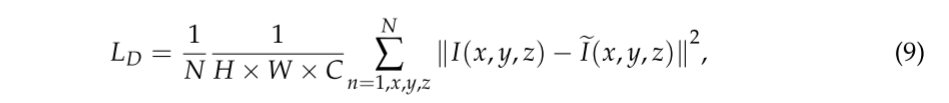
其中,N表示批量大小,I表示原始多光谱图像,并且I是恢复图像,H、W和C分别是图像的高度、宽度和光谱带号。
为了估计速率损失,我们采用了一个重要的网络,以取代熵计算的代码长度的连续近似。重要性网络用于生成从输入图像学习的重要性图P(X)。目的是根据图像内容的重要性来分配比特率,将更多比特分配给复杂区域,并且将更少比特分配给平滑区域。重要网络简单地由四层组成,两个1 × 1卷积层和一个由两个3 × 3卷积层组成的残差块,如图7所示。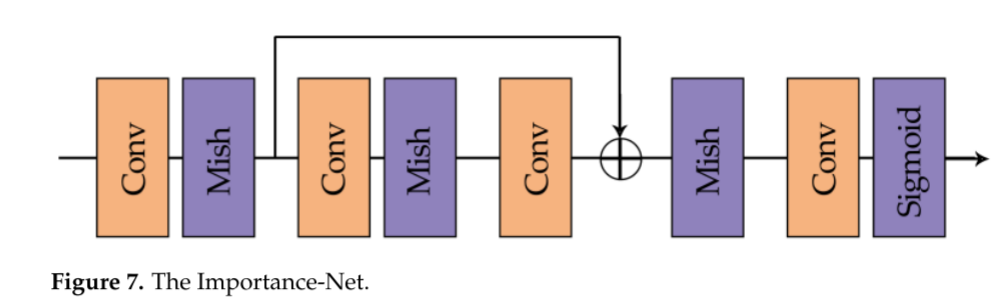
重要性网络中使用的激活函数是Mish [27],它已被证明比ReLU更平滑,并获得更好的结果。由于增加的补偿而导致的时间成本和有限的硬件条件仅在重要性网络中而不是整个网络中采用Mish,如下所示: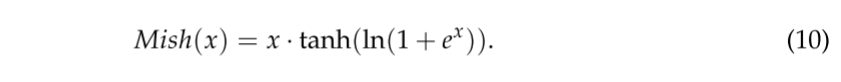
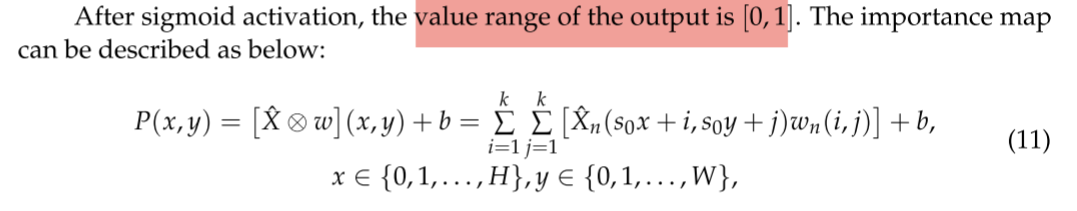

![[vulntarget靶场] vulntarget-c](https://img-blog.csdnimg.cn/03c4e38da3fe4bcd80d6e18652a403f2.png)