相关知识
为了完成本关任务,你需要掌握: 1.Alter Table 命令
Alter Table 命令
Alter Table 命令 可以在 Hive 中修改表名,列名,列注释,表注释,增加列,调整列顺序,属性名等操作。
1.修改表名
ALTER TABLE table_name RENAME TO new_table_name;
此命令可以将表 table_name 重命名为 new_table_name,数据所在的位置改变,但是分区名都没有改变。 这是一个hive 根据课程划分学生的分区表,最后一列为分区的课程。

现在将表名 test1 改为新表名 student。
alter table test1 rename to student;
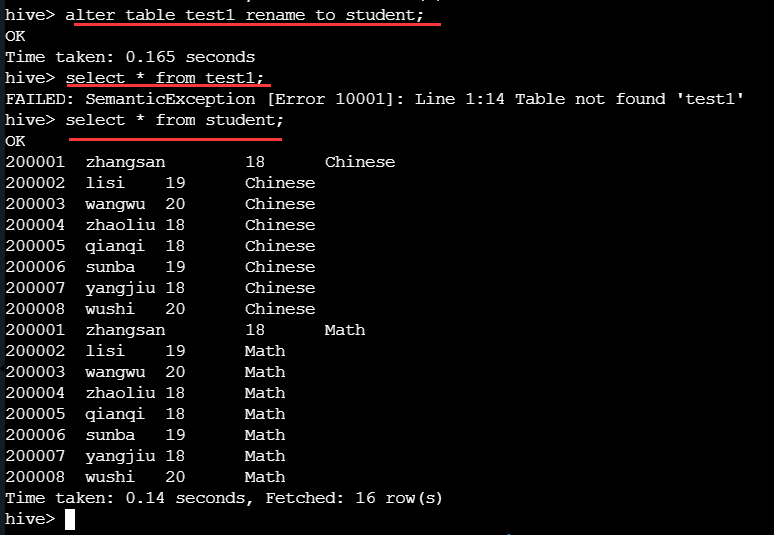
再次查询 test1 内容,系统提示找不到 test1 表了。查询新表名 student ,查询出来的数据为原表 test1 的内容,可以看到表分区的名字并没有修改,只是数据所在的位置发生改变。
2.修改列名和注释
ALTER TABLE table_name CHANGE col new_col STRING COMMENT 'xxxxxx'
查看 student 的表结构
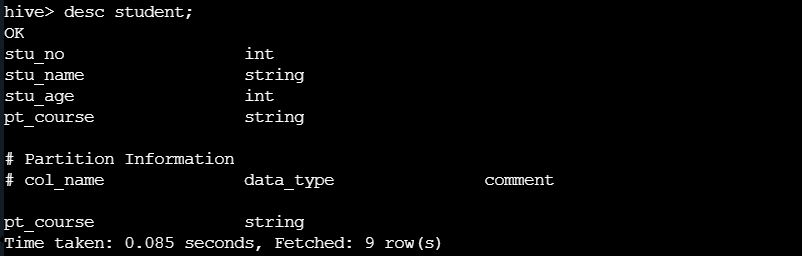
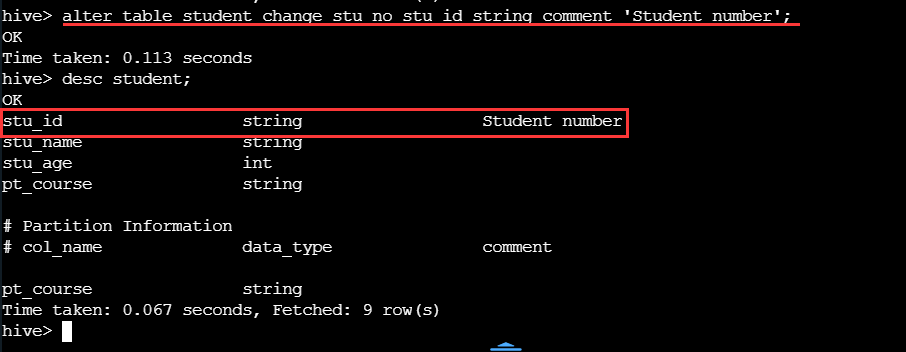
修改 student 表中列名 stu_no 为 stu_id,并将改列int 数据类型改为 string 数据类型,添加注释。
alter table student change stu_no stu_id string comment 'Student number';
再次查看表结构,发生了以下改变
3.改变列的位置
ALTER TABLE table_name CHANGE [col1 new_col column_type] [FIRST|AFTER col2]
修改列的位置,FIRST将列放在第一列,AFTER col2是将 col1 放在 col2 的后面一列。
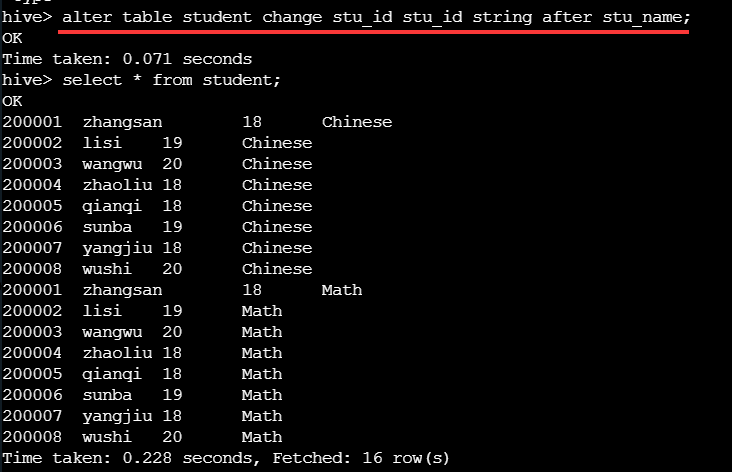
修改后发现列数据不会根据列的位置发生改变,因为Hive 中不支持对数据的改写和添加,所有的数据都是在加载的时候中确定好的。注意换列的位置的时候注意数据类型,或者在插入数据前将列位置排序好,最后将数据插入进来。 将 stu_id 列放回第一行。
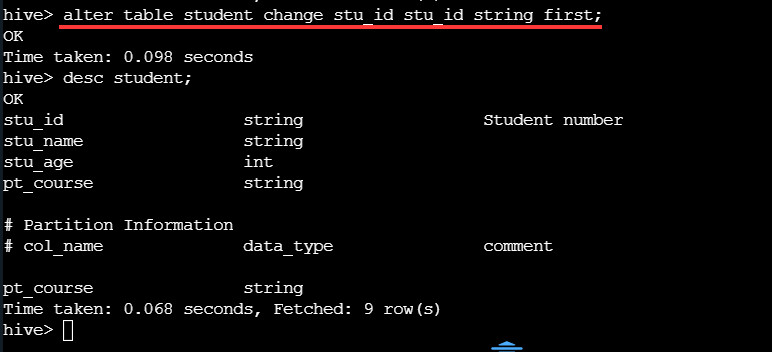
4.增加列
ALTER TABLE table_name ADD COLUMNS (col_name data_type [CONMMENT col_comment], ...);
ADD COLUMNS 允许用户在当前列的末尾,分区列之前添加新的列。
在 student 表中插入一列 score
alter table student add columns (score string comment 'Course results');
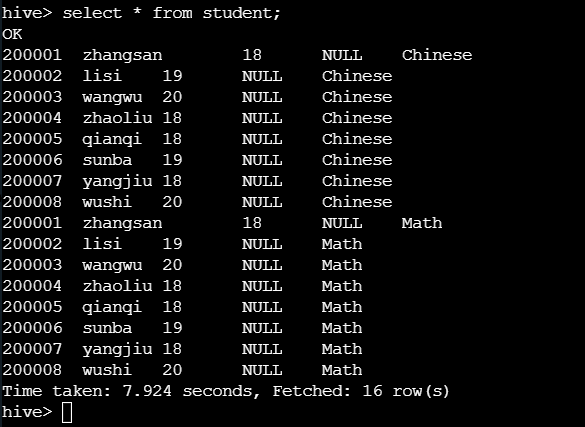
插入后,数据查询出来发现 score 新增出来,但是数据为空值。
5.更新列
ALTER TABLE table_name REPLACE COLUMNS (col_name data_type [CONMMENT col_comment], ...);
REPLACE COLUMNS 允许用户更新列,更新的过程是先删除当前的列,然后在加入新的列。
只保留学生学号 stu_id 和学生姓名 stu_name 列。
alter table student replace columns (stu_id string,stu_name string);
查询表结构和表数据发现 student 只保留了 stu_id 和stu_name 两列,其他的列被删除了(更新列需慎用)。

但是数据并没有删除,只是没有对应的列所以没有显示出来,如果这个时候加上两列的话,数据依旧可以显示。
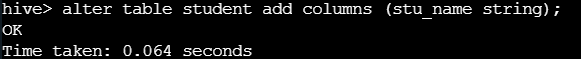
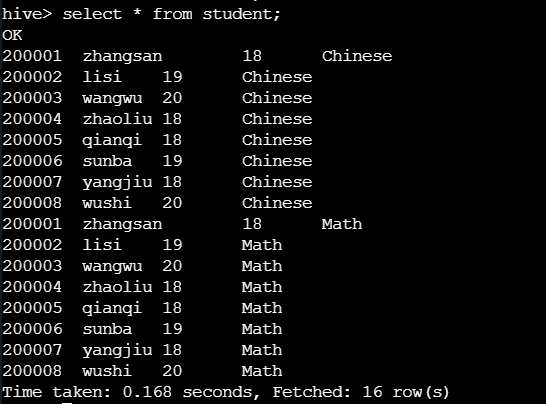
加分区表字段需要加上 hiveQL 语句要加上 CASCADE 参数。
6.增加表的属性
ALTER TABLE table_name SET TBLPEOPERTIES table_properties;
用户可以使用这个语句增加表属性,table_properties的结构为(property_name=property_value,property_name=property_value, ...),目前last_modified_time(最后修改时间),last_modified_user(做最后修改的用户)是由 Hive 自动管理的。用户可以向列中添加自己的属性,然后使用DISCRIBE EXTEBDED TABLE来获取这些信息。
#内部表转外部表alter table table_name set TBLPROPERTIES ('EXTERNAL'='TRUE');#外部表转内部表alter table table_name set TBLPROPERTIES ('EXTERNAL'='FALSE');
7.增加 SerDE 属性
ALTER TABLE table_name SET SERDE serde_class_name [WHIT SERDEPROPERTIES serde_properties];ALTER TABLE table_name SET SERDEPROPERTIES serde_properties;
上面两个命令都允许用户向 SerDE 对象增加用户定义的元数据。Hive为了序列化和反序列化数据,将会初始化SerDE属性,并将属性传给表的 SerDE。这样用户可以为自定义的SerDe 存储属性。上面serde_properties的结构为(property_name=property_value,property_name=property_value, ...)。
#设置表字符格式ALTER TABLE student SET SERDEPROPERTIES ('charset' = 'GBK');
8.修改表文件格式和组织
ALTER TABLE table_name SET FILEFORMAT file_format;ALTER TABLE table_name CLUSTERED BY (col_name, col_name, ...)[SORTED By (col_name, ...)] INTO num_buckets BUCKETS;
上面两个命令都修改了表的物理属性。
编程要求
根据相关知识,在右侧命令行进行操作,Hadoop 服务已经自动启动了,只需要输入hive命令进入 Hive 客户端即可进行操作。 1.创建表
create table employee(id int,name string,department string,salary float)row format delimited fields terminated by ",";
2.导入数据
load data local inpath '/data/workspace/myshixun/data/emp.txt' into table employee;
3.使用 Alter Table 进行操作
- 下表包含表字段,显示的字段要被更改
| 字段名 | 数据类型 | 更改字段名称 | 转换为数据类型 |
|---|---|---|---|
| id | int | emp_id | int |
| name | string | emp_name | string |
| department | string | department | string |
| salary | float | salary | double |
- 新增列 hiredate 类型为 date。
# hive
#hive>create table employee(id int,name string,department string,salary float)row format delimited fields terminated by ",";
#hive> load data local inpath '/data/workspace/myshixun/data/emp.txt' into table employee;
Loading data to table default.employee
hive> alter table employee change id emp_id int ;
OK
Time taken: 0.115 seconds
hive> alter table employee change name emp_name string ;
OK
Time taken: 0.052 seconds
hive> alter table employee change salary salary double ;
OK
Time taken: 0.051 seconds
hive> alter table employee add columns (hiredate date);
![[vulntarget靶场] vulntarget-c](https://img-blog.csdnimg.cn/03c4e38da3fe4bcd80d6e18652a403f2.png)