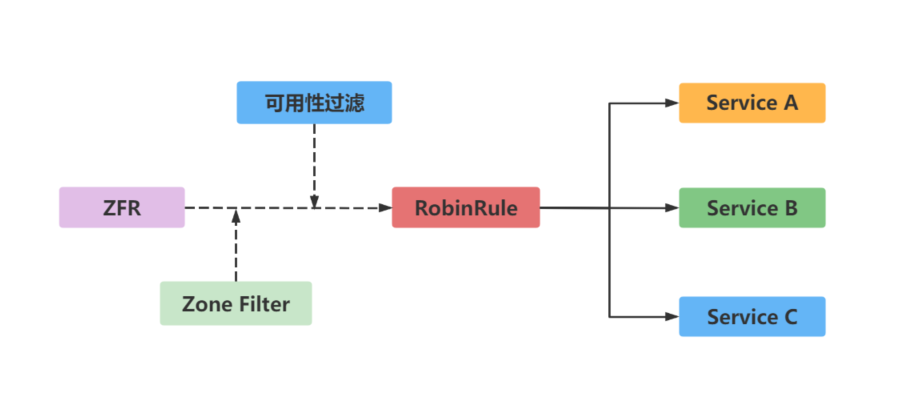
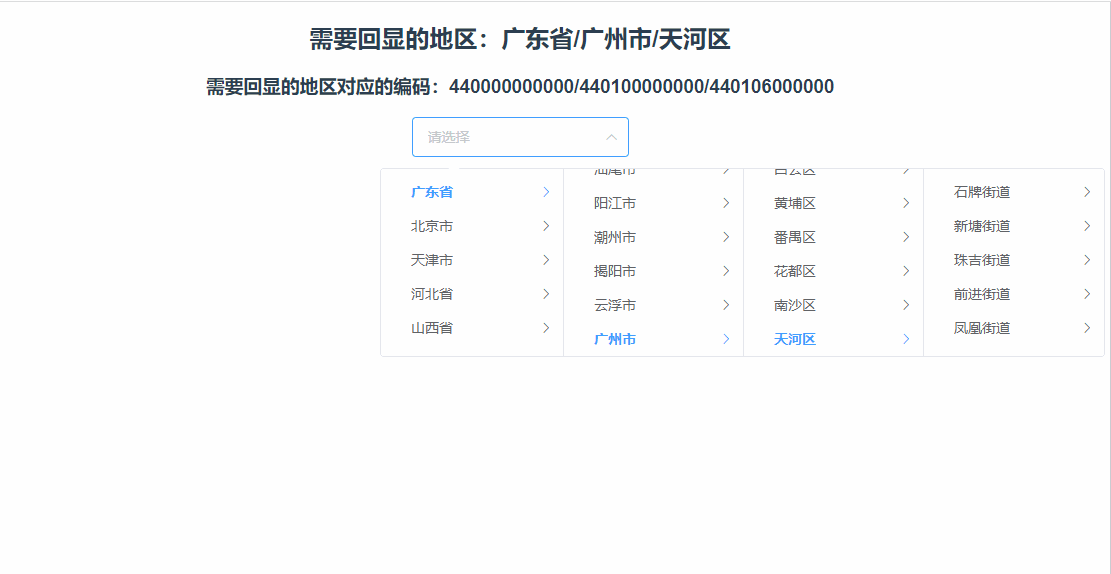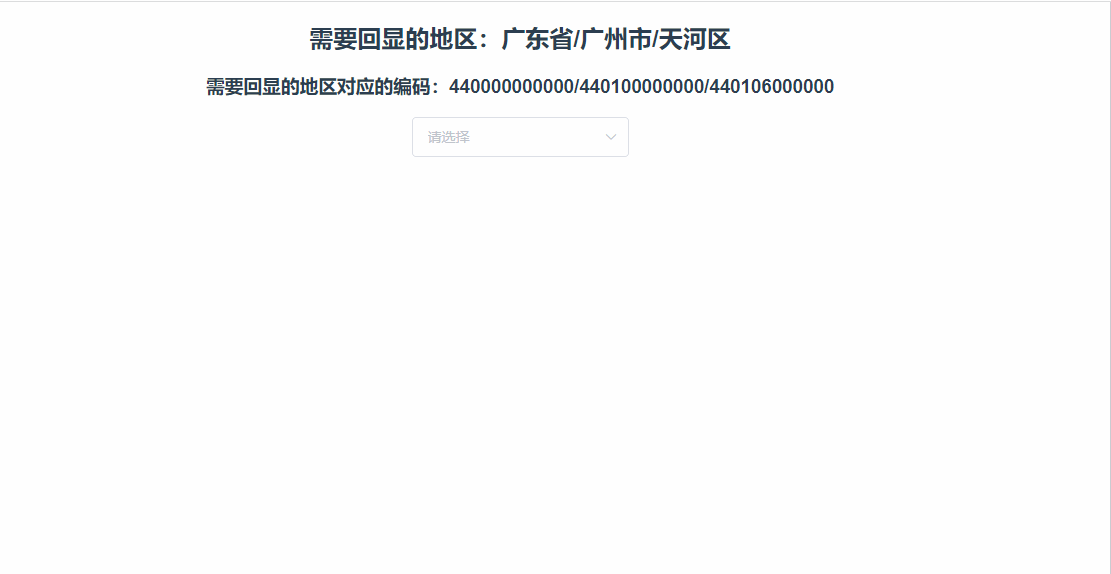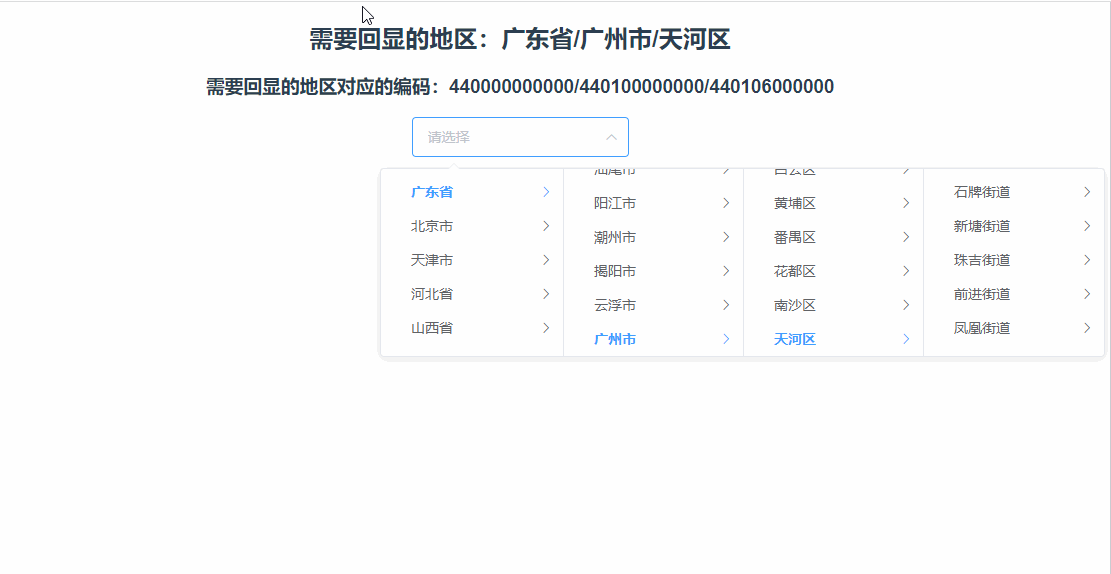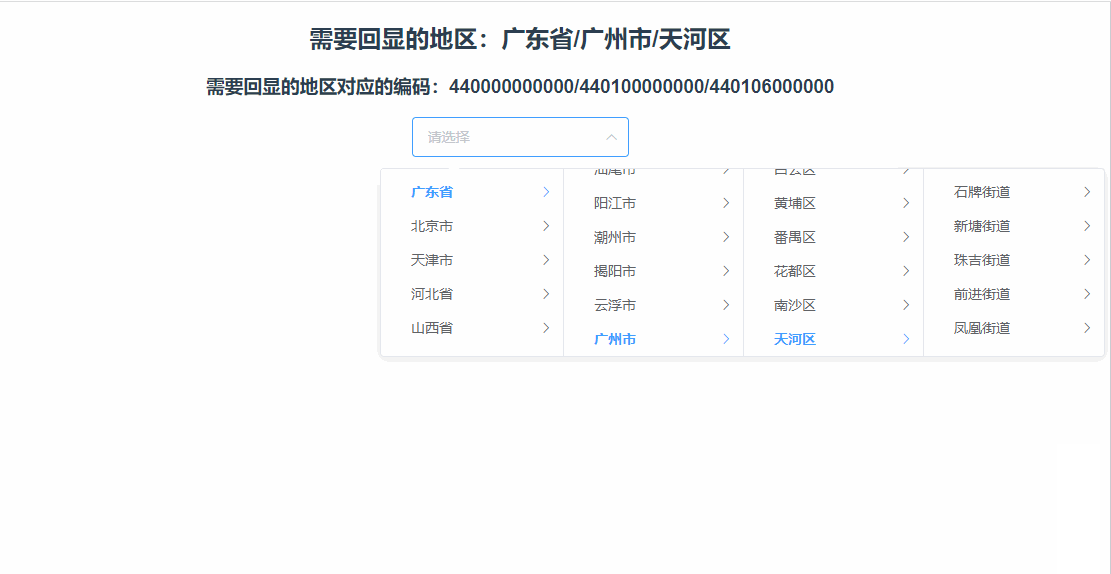
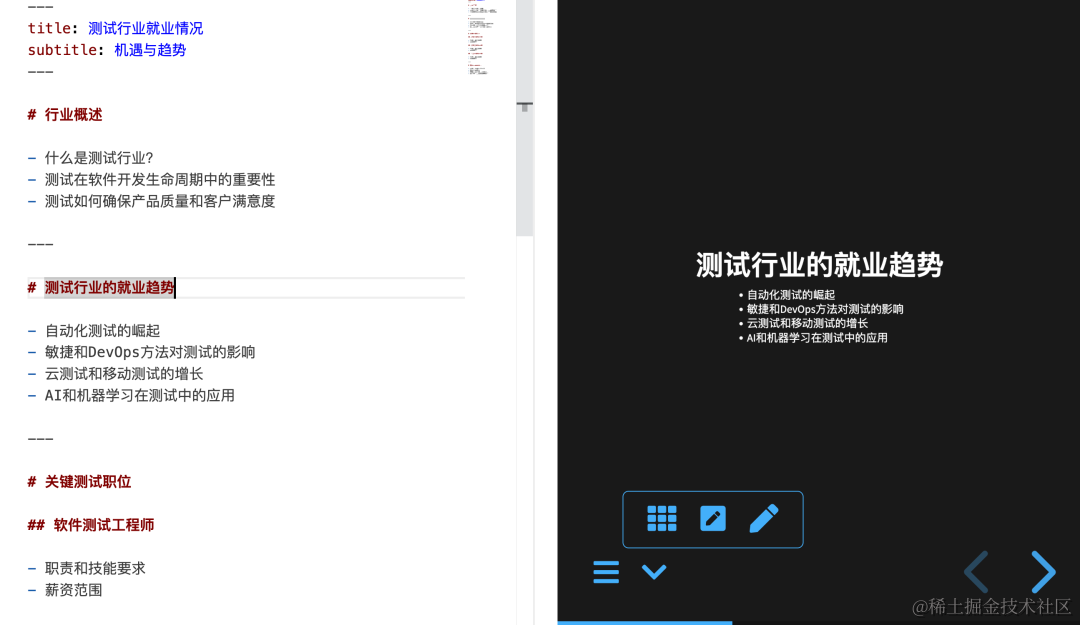
什么是灾难性雪崩效应
假设我们有两个访问量比较大的服务A和B,这两个服务分别依赖C和D,C和D服务都依赖E服务。
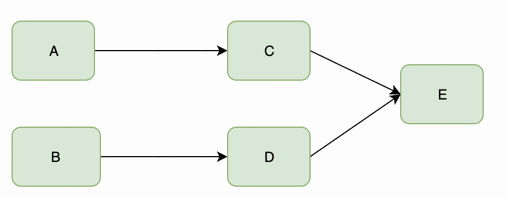
A和B不断的调用C,D处理客户请求和返回需要的数据。当E服务不能供服务的时候,C和D的超时和重试机制会被执行
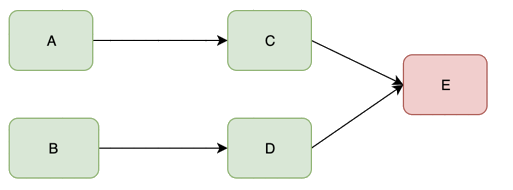
由于新的调用不断的产生,会导致C和D对E服务的调用大量的积压,产生大量的调用等待和重试调用,慢慢会耗尽C和D的资源比如内存或CPU,然后也down掉。
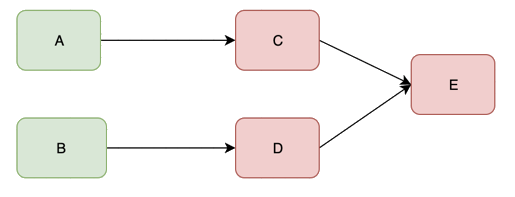
A和B服务会重复C和D的操作,资源耗尽,然后down掉,最终整个服务都不可访问。
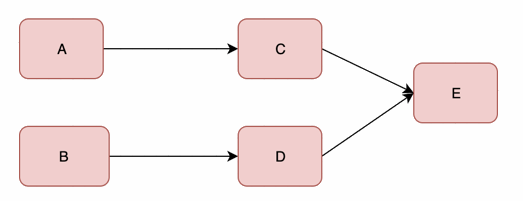
结论:
服务与服务之间的依赖性,故障会传播,造成连锁反应,会对整个微服务系统造成灾难性的严重后果,这就是服务故障的“雪崩”效应。
![]()
造成雪崩原因是什么
- 服务提供者不可用(硬件故障、程序bug、缓存击穿、用户大量请求)
- 重试加大流量(用户重试,代码逻辑重试)
- 服务调用者不可用(同步等待造成的资源耗尽)
注意:
在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等。我们要构建稳定、可靠的分布式系统,就必须要有一套容错方法。