- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
目录
一、AlexNet
1.卷积模块
2.全连接模块
3.AlexNet创新点
1.更深的神经网络结构
2.ReLU激活函数的使用
3.局部响应归一化(LRN)的使用
4.数据增强和Dropout
5.大规模分布式训练
二、AlexNet实现
1.定义AlexNet网络模型
2.加载数据集
3.训练模型
4.测试模型
三、实现图像分类
一、AlexNet
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年ImageNet图像分类竞赛中提出的一种经典的卷积神经网络。当时,AlexNet在 ImageNet 大规模视觉识别竞赛中取得了优异的成绩,把深度学习模型在比赛中的正确率提升到一个前所未有的高度。因此,它的出现对深度学习发展具有里程碑式的意义。
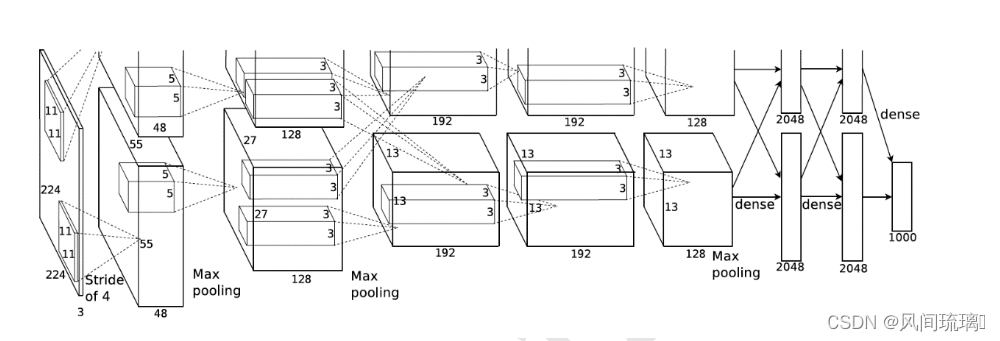
AlexNet输入为RGB三通道的3 x 224 × 224大小的色彩图像。AlexNet 共包含5 个卷积层(包含3个池化)和 3 个全连接层。其中,每个卷积层都包含卷积核、偏置项、ReLU激活函数和局部响应归一化(LRN)模块。第1、2、5个卷积层后面都跟着一个最大池化层,后三个层为全连接层。最终输出层为softmax,将网络输出转化为概率值,得到样本属于 1000 个类别的概率分布,用于预测图像的类别。
为了能够在当时的显卡设备NVIDIA GTX 580(3GB显存)上训练模型, Alex Krizhevsky 将卷积层、前 2 个全连接层等拆开在两块显卡上面分别训练,最后一层合 并到一张显卡上面,进行反向传播更新。AlexNet 在 ImageNet 取得了 15.3%的Top-5 错误 率,比第二名在错误率上降低了 10.9%。
1.卷积模块
AlexNet共有五个卷积层,每个卷积层都包含卷积核、偏置项、ReLU激活函数和局部响应归一化(LRN,Local Response Normalization)模块。
卷积层C1:
输入数据:3x224x224
使用96个核(2个部分之和,每个部分为48,因为输出特征层的通道数等于卷积核个数)对3 x 224 × 224的输入图像进行特征提取,卷积核大小为3 x 11 × 11(输入特征层的通道数等于卷积核的通道数),步长为4。将一对48x55×55的特征图分别放入ReLU激活函数。激活后的图像进行最大池化,size为3×3,stride为2,池化后的特征图size为48x27×27(一部分),总共就是96x27x27。池化后进行LRN处理。
LRN(Local Response Normalization) 局部响应归一化,LRN模拟神经生物学上一个叫做侧抑制(lateral inhibitio)的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。
LRN局部响应归一化借鉴侧抑制的思想实现局部抑制,使得响应比较大的值相对更大,提高了模型的泛化能力。LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。LRN概念是在AlexNet模型中首次提出,在GoogLenet中也有应用,但是LRN的实际作用存在争议,如在2015年Very Deep Convolutional Networks for Large-Scale Image Recognition 论文中指出LRN基本没什么用。
卷积层C2:
输入数据:96x27x27
使用卷积层C1的输出作为输入,并使用256个卷积核进行滤波,核大小为48x5 × 5。卷积后数据为256x27x27,做了padding,使得卷积后图像大小不变。其次进行relu,然后进行最大池化,最大池化Maxpool的核大小为3x3,步长为2,池化后的数据为256x13x13([27-3]/2 + 1),下部分:128x13x13。
卷积层C3:
输入数据:256x13x13
使用384个卷积核,核大小为256 x 3 × 3 ,与卷积层C2的输出相连。卷积后的数据:384x13x13,卷积前后图像的大小不变,然后经过relu层,输出数据384x13x13, C3层没有Maxpool层和norm层。
卷积层C4:
输入数据:384x13x13
使用384个卷积核,核大小为384 x 3 × 3。卷积核数据384 x 13 x13,做了padding填充,使卷积后图像大小不变,relu后数据384 x 13 x 13。同样没有池化层和norm层。
卷积层C5:
输入数据:384 x 13 x13
使用256个卷积核,核大小为384 x 3 × 3。经过relu和池化后256 x 6 x 6(9216),池化核size同样为3×3,stride为2。
其中,卷积层C3、C4、C5互相连接,中间没有接入池化层或归一化层。
2.全连接模块
全连接层F6:
输入数据:256x6x6
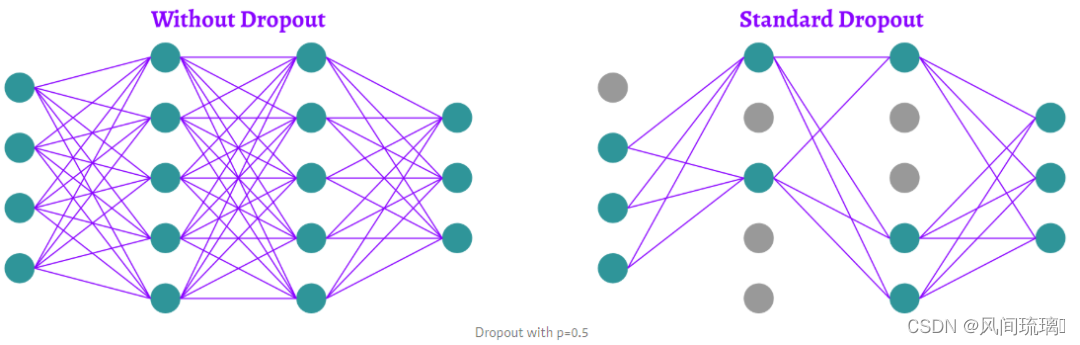
全连接层输出:因为是全连接层,卷积核size为6×6×256,4096个卷积核生成4096个特征图,尺寸为1×1。然后放入ReLU函数、Dropout处理。值得注意的是AlexNet使用了Dropout层,以减少过拟合现象的发生。
Dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率(一般是50%,这种情况下随机生成的网络结构最多)将其暂时从网络中丢弃(保留其权值),不再对前向和反向传输的数据响应。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而相当于每一个mini-batch都在训练不同的网络,drop out可以有效防止模型过拟合,让网络泛化能力更强,同时由于减少了网络复杂度,加快了运算速度。还有一种观点认为drop out有效的原因是对样本增加来噪声,变相增加了训练样本。
全连接层F7:与F6层相同。
全连接层F8:最后一层全连接层的输出是1000维softmax的输入,softmax会产生1000个类别预测的值。
各网络层参数:

较为详细的网络结构:(227x227是经过填充后的图像),这里将分开训练的两部分合在一起啦。

注意:C3和C4层无池化层哦。
3.AlexNet创新点
1.更深的神经网络结构
AlexNet 是首个真正意义上的深度卷积神经网络,它的深度达到了当时先前神经网络的数倍。通过增加网络深度,AlexNet 能够更好地学习数据集的特征,从而提高了图像分类的精度。
2.ReLU激活函数的使用
AlexNet 首次使用了修正线性单元(ReLU)这一非线性激活函数。相比于传统的 sigmoid 和 tanh 函数,ReLU 能够在保持计算速度的同时,有效地解决了梯度消失问题,从而使得训练更加高效。
3.局部响应归一化(LRN)的使用
LRN是在卷积层和池化层之间添加的一种归一化操作。在卷积层中,每个卷积核都对应一个特征图(feature map),LRN就是对这些特征图进行归一化。具体来说,对于每个特征图上的每个位置,计算该位置周围的像素的平方和,然后将当前位置的像素值除以这个和。
LRN本质是抑制邻近神经元的响应,从而增强了神经元的较大响应。这种技术在一定程度上能够避免过拟合,并提高网络的泛化能力。
4.数据增强和Dropout
为了防止过拟合,AlexNet 引入了数据增强和 Dropout 技术。
数据增强可以通过对图像进行旋转、翻转、裁剪等变换,增加训练数据的多样性,提高模型的泛化能力。
Dropout 则是在训练过程中随机删除一定比例的神经元,强制网络学习多个互不相同的子网络,从而提高网络的泛化能力。Dropout简单来说就是在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
5.大规模分布式训练
AlexNet在使用GPU进行训练时,可将卷积层和全连接层分别放到不同的GPU上进行并行计算,从而大大加快了训练速度。像这种大规模 GPU 集群进行分布式训练的方法在后来的深度学习中也得到了广泛的应用。
二、AlexNet实现
1.定义AlexNet网络模型
AlexNet网络模型的构建完全按照前面的各层的参数设置的,包括5层卷积层和3层全连接层。
class AlexNet(nn.Module):
def __init__(self, num_classes=1000, init_weights=False):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
# input [3, 224, 224] output [96, 55 ,55]
nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[96, 27, 27]
nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, padding=2), # output[256, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[256, 13, 13]
nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, padding=1), # output[384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, padding=1), # output[384, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, padding=1), # output[256, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2) # output[256, 6, 6]
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
# 初始化参数
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, start_dim=1)
# x = x.view(-1, 6*6*256)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules(): # 变量网络所有层
if isinstance(m, nn.Conv2d): # 是否为卷积层
# 使用Kaiming初始化方法来初始化该层的权重
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None: # 否具有偏差项
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear): # 是否为Linear
# 正太分布初始化全连接层
nn.init.normal_(m.weight, 0, 0.01)
# 将偏项设置为0
nn.init.constant_(m.bias, 0)
2.加载数据集
这里数据集是自定义的5中花朵数据集,每个文件夹下对应着一种花。
这是总的数据集,但是我们还需要将数据集分为测试集和训练集,分类脚本如下
def mk_file(file_path: str):
if os.path.exists(file_path):
# 如果文件夹存在,则先删除原文件夹在重新创建
rmtree(file_path)
os.makedirs(file_path)
def main():
# 保证随机可复现
random.seed(0)
# 将数据集中10%的数据划分到验证集中
split_rate = 0.1
# 指向你解压后的flower_photos文件夹
cwd = os.getcwd()
data_root = os.path.join(cwd, "flower_data")
origin_flower_path = os.path.join(data_root, "flower_photos")
assert os.path.exists(origin_flower_path), "path '{}' does not exist.".format(origin_flower_path)
flower_class = [cla for cla in os.listdir(origin_flower_path)
if os.path.isdir(os.path.join(origin_flower_path, cla))]
# 建立保存训练集的文件夹
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(train_root, cla))
# 建立保存验证集的文件夹
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in flower_class:
# 建立每个类别对应的文件夹
mk_file(os.path.join(val_root, cla))
for cla in flower_class:
cla_path = os.path.join(origin_flower_path, cla)
images = os.listdir(cla_path)
num = len(images)
# 随机采样验证集的索引
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
# 将分配至验证集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
# 将分配至训练集中的文件复制到相应目录
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
处理完后如下:
 然后就可以加载数据集和测试集,并进行相应的预处理操作。
然后就可以加载数据集和测试集,并进行相应的预处理操作。
# 预处理
data_transform = {
"train": transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪
transforms.RandomHorizontalFlip(), # 随机翻转
transforms.ToTensor(), # 类型转变并归一化
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# 数据集根目录
data_root = os.path.abspath(os.getcwd())
print(os.getcwd())
# 图片目录
image_path = os.path.join(data_root, "data_set", "flower_data")
print(image_path)
assert os.path.exists(image_path), "{} path does not exit.".format(image_path)
# 准备数据集
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"),
transform=data_transform["val"])
val_num = len(validate_dataset)
# 定义一个包含花卉类别到索引的字典:雏菊,蒲公英,玫瑰,向日葵,郁金香
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
# 获取包含训练数据集类别名称到索引的字典,这通常用于数据加载器或数据集对象中。
flower_list = train_dataset.class_to_idx
# 创建一个反向字典,将索引映射回类别名称
cla_dict = dict((val, key) for key, val in flower_list.items())
# 将字典转换为格式化的JSON字符串,每行缩进4个空格
json_str = json.dumps(cla_dict, indent=4)
# 打开名为 'class_indices.json' 的JSON文件,并将JSON字符串写入其中
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
batch_size = 32
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print("using {} dataloader workers every process".format(nw))
# 加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images for validation.".format(train_num, val_num))3.训练模型
数据集准备好后就可以实例化网络进行模型的训练。
net = AlexNet(num_classes=5, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 200
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# 将神经网络设置为训练模式
net.train()
running_loss = 0.0
# 使用 tqdm 创建一个进度条以显示训练进度
# tqdm 用于包装 train_loader,使其在终端中显示一个进度条,以便用户可以实时查看训练进度。file=sys.stdout 参数将进度条输出到终端。
train_bar = tqdm(train_loader, file=sys.stdout)
# 迭代训练数据集
for step, data in enumerate(train_bar):
images, labels = data
# 清除梯度
optimizer.zero_grad()
# 前向传播
outputs = net(images.to(device))
# 计算损失
loss = loss_function(outputs, labels.to(device))
# 反向传播
loss.backward()
# 更新权重
optimizer.step()
# 累积损失值
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
4.测试模型
每训练完一个epoch,就进行一次测试,并将比较准确率大小,并根据当前模型的准确率保存模型,如果当前准确率优于之前的最佳准确率,则保存当前模型参数;否则,不变。
# 将神经网络设置为评估模式
net.eval()
acc = 0.0 # 准确率
# 在评估模式下不进行梯度计算
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
# 前向传播
outputs = net(val_images.to(device))
# 预测类别
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
# 计算验证集准确率
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
# 如果当前模型的验证准确率优于之前的最佳准确率,则保存当前模型参数
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
三、实现图像分类
利用上述训练好的网络模型进行测试,验证是否能完成分类任务。
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载图片
img_path = 'tulips.jpg'
assert os.path.exists(img_path), "file: '{}' does not exist.".format(img_path)
image = Image.open(img_path)
# img.show()
image.show()
# [N, C, H, W]
img = data_transform(image)
# 扩展维度
img = torch.unsqueeze(img, dim=0)
# 获取标签
json_path = 'class_indices.json'
assert os.path.exists(json_path), "file: '{}' does not exist.".format(json_path)
with open(json_path, 'r') as f:
# 使用json.load()函数加载JSON文件的内容并将其存储在一个Python字典中
class_indict = json.load(f)
# 加载网络
model = AlexNet(num_classes=5).to(device)
# 加载模型文件
weights_path = "./AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
# 对输入图像进行预测
output = torch.squeeze(model(img.to(device))).cpu()
# 对模型的输出进行 softmax 操作,将输出转换为类别概率
predict = torch.softmax(output, dim=0)
# 得到高概率的类别的索引
predict_cla = torch.argmax(predict).numpy()
res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)], predict[predict_cla].numpy())
draw = ImageDraw.Draw(image)
# 文本的左上角位置
position = (10, 10)
# fill 指定文本颜色
draw.text(position, res, fill='red')
image.show()
for i in range(len(predict)):
print("class: {:10} prob: {:.3}".format(class_indict[str(i)], predict[i].numpy()))预测结果:


结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。
愿尔之学习之路风平浪静,充满希望💐。再次感谢尔之阅读与关注,吾期望再次相见!