Focus操作
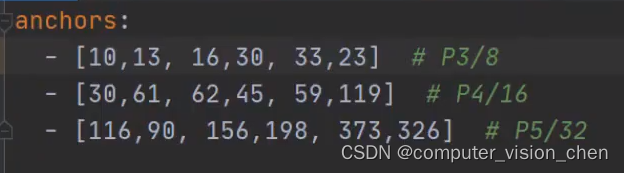
anchors
先验框
其它
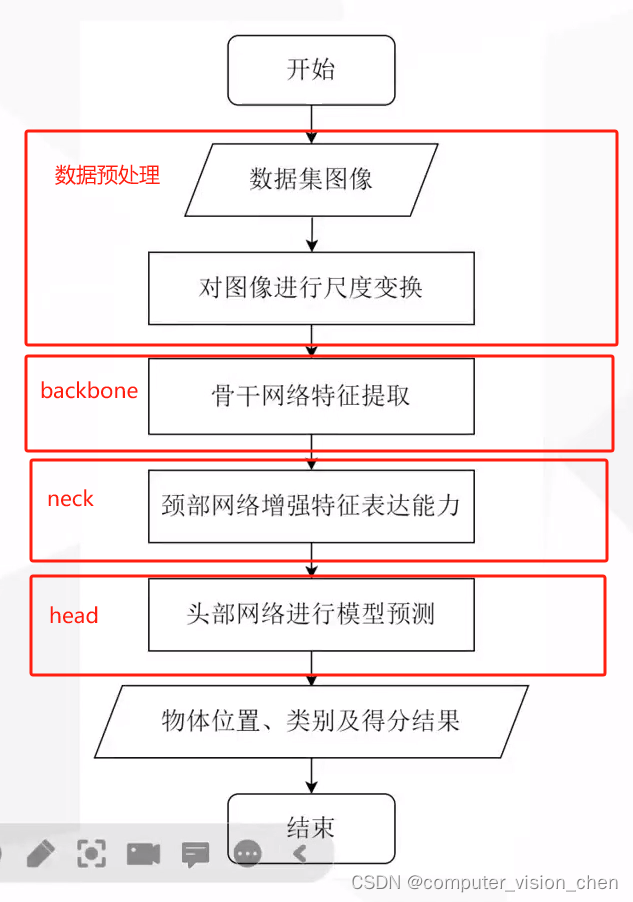
Yolov5的模型主要由Backbone、Neck和Head三部分组成。
Backbone:负责提取输入图像的特征。在Yolov5中,常见的Backbone网络包括CSPDarknet53或ResNet。这些网络都是相对轻量级的,能够在保证较高检测精度的同时,尽可能地减少计算量和内存占用。其结构主要有Conv模块、C3模块、SPPF模块。Conv模块主要由卷积层、BN层和激活函数组成,C3模块则将前面的特征图进行自适应聚合,SPPF模块通过全局特征与局部特征的加权融合,获取更全面的空间信息。
Neck:Neck部分负责对Backbone提取的特征进行多尺度特征融合,并把这些特征传递给预测层。例如,在Yolov5采用的PANet结构中,通过多次上采样、拼接、点和点积来设计聚合策略,以此更好地利用多尺度特征。
Head:Head主要负责进行最终的回归预测,即利用Backbone骨干网络提取的特征图来检测目标的位置和类别。
最后,输出端是模型预测的结果,包括每个目标的类别和其对应的边界框坐标等信息。
yolov4
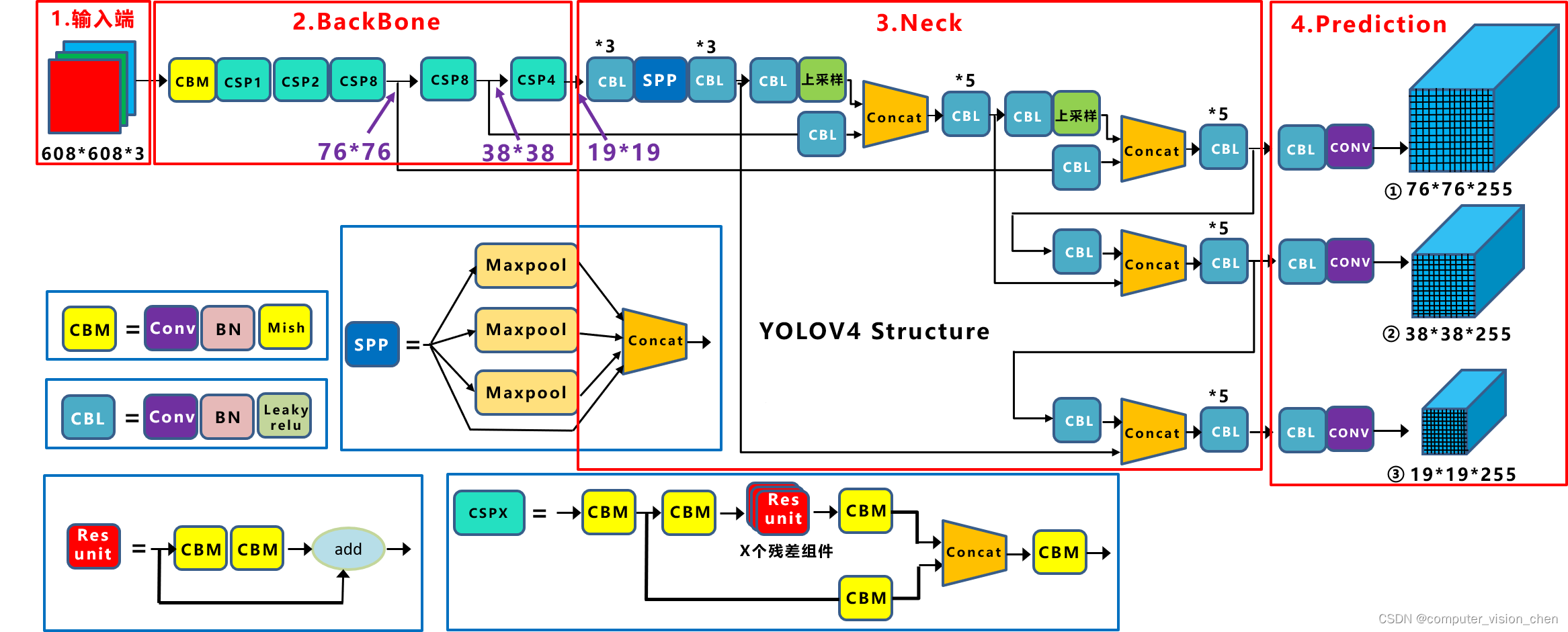
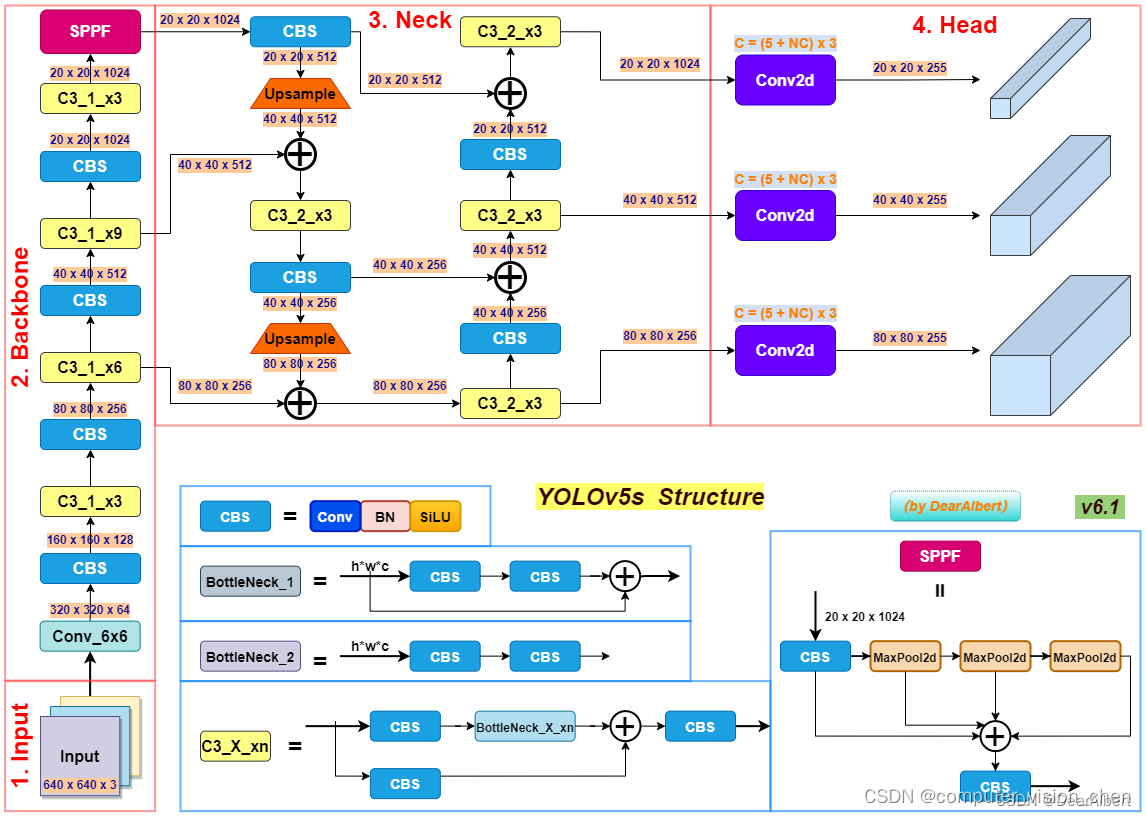
1,网络架构
通过解析代码仓库中的 .yaml 文件中的结构代码,YOLOv5 模型可以概括为以下几个部分:
Backbone: Focus structure, CSP network
Neck: SPP block, PANet
Head: YOLOv3 head using GIoU-loss
2,创新点
2.1,自适应anchor
在训练模型时,YOLOv5 会自己学习数据集中的最佳 anchor boxes,而不再需要先离线运行 K-means 算法聚类得到 k 个 anchor box 并修改 head 网络参数。总的来说,YOLOv5 流程简单且自动化了。
2.2, 自适应图片缩放
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。
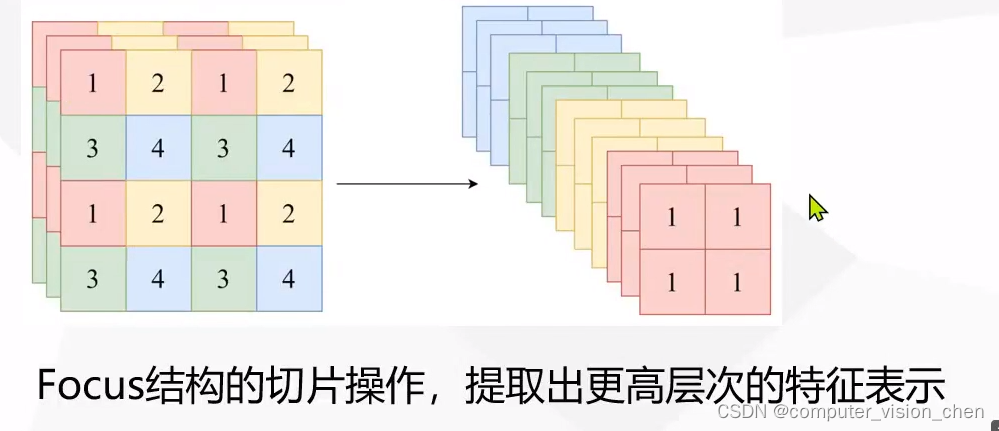
2.3,Focus结构
Focus 结构可以简单理解为将
大小的输入图片 4 个像素分别取 1 个(类似于邻近下采样)形成新的图片,这样 1 个通道的输入图片会被划分成 4 个通道,每个通道对应的 WH 尺寸大小都为原来的 1/2,并将这些通道组合在一起。这样就实现了像素信息不丢失的情况下,提高通道数(通道数对计算量影响更小),减少输入图像尺寸,从而大大减少模型计算量。
以 Yolov5s 的结构为例,原始 640x640x3 的图像输入 Focus 结构,采用切片操作,先变成 320×320×12 的特征图,再经过一次 32 个卷积核的卷积操作,最终变成 320×320×32 的特征图。
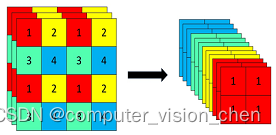
focus结构示例
3,四种网络结构
YOLOv5 通过在网络结构问价 yaml 中设置不同的 depth_multiple 和 width_multiple 参数,来创建大小不同的四种 YOLOv5 模型:Yolv5s、Yolv5m、Yolv5l、Yolv5x。

![孜然单授权系统V1.0[免费使用]](https://img-blog.csdnimg.cn/5d4887a2f14340c0895275802115f550.png)