目录
第一题
题目来源
题目内容
解决方法
方法一:哈希表+双向链表
方法二:TreeMap
方法三:双哈希表
第二题
题目来源
题目内容
解决方法
方法一:二分查找
方法二:线性搜索
方法三:Arrays类的binarySearch方法
方法四:插入排序
第三题
题目来源
题目内容
解决方法
方法一:二维数组
方法二:哈希集合
方法三:单一遍历
方法四:位运算
第一题
题目来源
460. LFU 缓存 - 力扣(LeetCode)
题目内容

解决方法
方法一:哈希表+双向链表
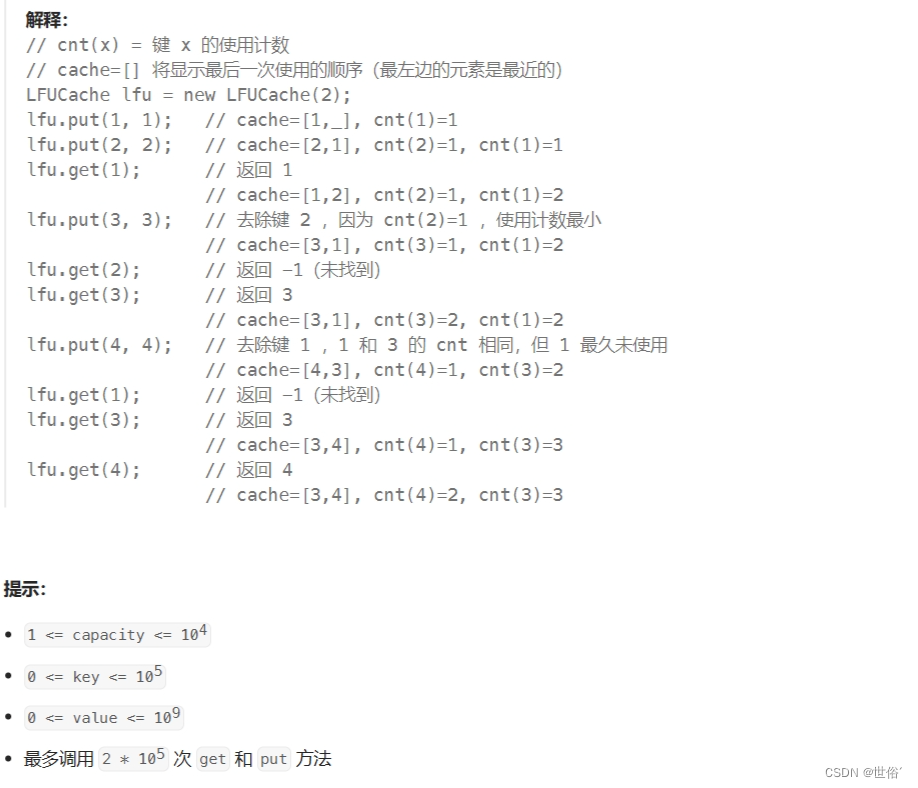
LFU(Least Frequently Used)缓存算法的主要思想是根据键的使用频率来进行缓存项的管理。
首先,我们需要设计一个数据结构来存储缓存的键值对,并记录每个键的使用计数(即使用频率)。为了支持 O(1) 的时间复杂度,我们可以使用哈希表来存储键值对,并且使用双向链表来维护具有相同使用计数的键的顺序。
算法的关键步骤如下:
- 使用一个哈希表
values来存储键值对,以支持快速的键值获取和更新操作。 - 使用另一个哈希表
frequencies来记录每个键的使用计数。 - 使用一个哈希表
frequencyKeys来记录具有相同使用计数的键的集合,并使用双向链表来维护它们的顺序。 - 使用一个变量
minFrequency来记录当前最小的使用计数。
对于 get 操作:
- 如果键不存在于缓存中,返回 -1。
- 如果键存在于缓存中,需要执行以下操作:
- 更新键的使用计数:将该键的使用计数加一。
- 将该键从原来的使用计数对应的双向链表中移除。
- 如果该键所在的双向链表为空且使用计数等于
minFrequency,则更新minFrequency为下一个更大的使用计数。 - 将该键添加到新的使用计数对应的双向链表中,并更新
minFrequency为 1(因为该键变成了最近被使用的键)。 - 返回键对应的值。
对于 put 操作:
- 如果容量已满且需要插入一个新的键值对时,需要执行以下操作:
- 通过
frequencyKeys[minFrequency]找到双向链表的头节点,得到需要移除的键,将其从缓存中和相应的哈希表中移除。
- 通过
- 如果键已经存在于缓存中,需要执行以下操作:
- 更新键对应的值。
- 执行 get 操作来更新键的使用计数和双向链表的顺序。
- 如果键不存在于缓存中,需要执行以下操作:
- 如果缓存已满,执行上述的容量已满的移除操作。
- 插入新的键值对到缓存中。
- 将该键的使用计数设置为 1。
- 将该键添加到使用计数为 1 的双向链表中。
- 更新
minFrequency为 1。
import java.util.HashMap;
import java.util.LinkedHashSet;
import java.util.Map;
class LFUCache {
private int capacity;
private int minFrequency;
private Map<Integer, Integer> values;
private Map<Integer, Integer> frequencies;
private Map<Integer, LinkedHashSet<Integer>> frequencyKeys;
public LFUCache(int capacity) {
this.capacity = capacity;
this.minFrequency = 1;
this.values = new HashMap<>();
this.frequencies = new HashMap<>();
this.frequencyKeys = new HashMap<>();
}
public int get(int key) {
if (!values.containsKey(key)) {
return -1;
}
// 更新键的使用频率
int frequency = frequencies.get(key);
frequencies.put(key, frequency + 1);
// 更新相应频率的键集合
frequencyKeys.get(frequency).remove(key);
if (frequency == minFrequency && frequencyKeys.get(frequency).isEmpty()) {
minFrequency++;
}
frequencyKeys.computeIfAbsent(frequency + 1, k -> new LinkedHashSet<>()).add(key);
return values.get(key);
}
public void put(int key, int value) {
if (capacity <= 0) {
return;
}
if (values.containsKey(key)) {
// 更新键的值和使用频率
values.put(key, value);
get(key);
return;
}
if (values.size() >= capacity) {
// 移除最不经常使用的项
int evictKey = frequencyKeys.get(minFrequency).iterator().next();
values.remove(evictKey);
frequencies.remove(evictKey);
frequencyKeys.get(minFrequency).remove(evictKey);
}
// 插入新的键值对
values.put(key, value);
frequencies.put(key, 1);
frequencyKeys.computeIfAbsent(1, k -> new LinkedHashSet<>()).add(key);
minFrequency = 1;
}
}
复杂度分析:
对于 get 操作:
- 在哈希表中查找键值对的时间复杂度为 O(1)。
- 更新键的使用计数、移除和添加键到相应的双向链表的时间复杂度也为 O(1)。
对于 put 操作:
- 在哈希表中插入键值对的时间复杂度为 O(1)。
- 更新键的使用计数、移除和添加键到相应的双向链表的时间复杂度也为 O(1)。
因此,get 和 put 操作的时间复杂度都是 O(1)。
空间复杂度主要取决于存储缓存键值对和使用计数的数据结构:
- 哈希表 `values` 存储键值对,占用的空间为 O(capacity),其中 capacity 是缓存的最大容量。
- 哈希表 `frequencies` 存储键的使用计数,占用的空间为 O(capacity)。
- 哈希表 `frequencyKeys` 存储具有相同使用计数的键的集合,占用的空间为 O(capacity)。
- 双向链表的节点数等于缓存中的键数,最多为 capacity。
因此,LFU 缓存算法的空间复杂度为 O(capacity)。
需要注意的是,以上复杂度分析是基于假设哈希表的操作时间复杂度为 O(1) 的情况。在实际应用中,哈希表的性能也受到哈希函数的质量和哈希冲突的处理等因素影响。此外,LFU 缓存算法本身的性能也与具体的使用场景和数据访问模式相关。因此,在实际应用中,需要综合考虑实际情况来评估算法的性能。
LeetCode运行结果:
方法二:TreeMap
import java.util.*;
class LFUCache {
private int capacity;
private Map<Integer, Integer> cache; // 存储键值对
private Map<Integer, Integer> frequencies; // 存储键的使用计数
private TreeMap<Integer, LinkedHashSet<Integer>> frequencyKeys; // 存储具有相同使用计数的键的集合
public LFUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
this.frequencies = new HashMap<>();
this.frequencyKeys = new TreeMap<>();
}
public int get(int key) {
if (cache.containsKey(key)) {
updateFrequency(key);
return cache.get(key);
}
return -1;
}
public void put(int key, int value) {
if (capacity <= 0) return;
if (cache.containsKey(key)) {
cache.put(key, value);
updateFrequency(key);
} else {
if (cache.size() >= capacity) {
removeLFUKey();
}
cache.put(key, value);
frequencies.put(key, 1);
addToFrequencyKeys(key, 1);
}
}
private void updateFrequency(int key) {
int frequency = frequencies.get(key);
frequencies.put(key, frequency + 1);
removeFromFrequencyKeys(key, frequency);
addToFrequencyKeys(key, frequency + 1);
}
private void removeLFUKey() {
LinkedHashSet<Integer> keysWithMinFreq = frequencyKeys.firstEntry().getValue();
int lfuKey = keysWithMinFreq.iterator().next();
keysWithMinFreq.remove(lfuKey);
if (keysWithMinFreq.isEmpty()) {
frequencyKeys.remove(frequencyKeys.firstKey());
}
cache.remove(lfuKey);
frequencies.remove(lfuKey);
}
private void addToFrequencyKeys(int key, int frequency) {
frequencyKeys.computeIfAbsent(frequency, k -> new LinkedHashSet<>()).add(key);
}
private void removeFromFrequencyKeys(int key, int frequency) {
LinkedHashSet<Integer> keysWithFreq = frequencyKeys.get(frequency);
if (keysWithFreq != null) {
keysWithFreq.remove(key);
if (keysWithFreq.isEmpty()) {
frequencyKeys.remove(frequency);
}
}
}
}
以上代码中,cache 是存储键值对的哈希表,frequencies 是存储键的使用计数的哈希表,frequencyKeys 是存储具有相同使用计数的键的集合的有序映射(基于 TreeMap 实现)。
复杂度分析:
时间复杂度分析:
- LFUCache(int capacity) 构造函数的时间复杂度为 O(1),只是对私有变量进行初始化。
- get(int key) 方法的时间复杂度为 O(1)。通过 HashMap 直接访问键值对,时间复杂度为常数级别。
- put(int key, int value) 方法的时间复杂度为 O(1)。通过 HashMap 直接插入或更新键值对,时间复杂度为常数级别。
- updateFrequency(int key) 方法的时间复杂度为 O(log M),其中 M 表示不同频率的数量。在更新某个键的使用计数时,需要先获取当前计数,然后进行加一操作,并将该键从旧的频率集合中删除,再将其添加到新的频率集合中。由于使用的是 TreeMap,获取和删除操作的时间复杂度为 O(log M)。
- removeLFUKey() 方法的时间复杂度为 O(log M),其中 M 表示不同频率的数量。通过 TreeMap 的 firstEntry() 获取最小频率对应的 keys 集合的时间复杂度为 O(log M)。然后从集合中移除一个键和删除空集合的时间复杂度为 O(1)。因此,整个方法的时间复杂度为 O(log M)。
综上所述,根据给定的 LFU 缓存算法实现,主要操作的时间复杂度为 O(1) 和 O(log M),其中 M 表示不同频率的数量。
空间复杂度分析:
- 存储键值对的 cache 使用的空间为 O(capacity),其中 capacity 是 LFU 缓存的容量。
- 存储键的使用计数的 frequencies 使用的空间为 O(capacity),最坏情况下需要存储 capacity 个键的使用计数。
- 存储具有相同使用计数的键的集合的 frequencyKeys 使用的空间为 O(capacity * maxFreq),其中 maxFreq 表示频率的最大值,即最高使用计数。每个键和频率都需要占用常数级别的空间。
综上所述,根据给定的 LFU 缓存算法实现,总体的空间复杂度为 O(capacity * maxFreq)。
LeetCode运行结果:
方法三:双哈希表
import java.util.*;
class LFUCache {
private int capacity;
private Map<Integer, Integer> cache; // 存储键值对
private Map<Integer, Integer> frequencies; // 存储键的使用计数
private Map<Integer, LinkedHashSet<Integer>> frequencyKeys; // 存储具有相同使用计数的键的集合
public LFUCache(int capacity) {
this.capacity = capacity;
this.cache = new HashMap<>();
this.frequencies = new HashMap<>();
this.frequencyKeys = new HashMap<>();
}
public int get(int key) {
if (cache.containsKey(key)) {
updateFrequency(key);
return cache.get(key);
}
return -1;
}
public void put(int key, int value) {
if (capacity <= 0) return;
if (cache.containsKey(key)) {
cache.put(key, value);
updateFrequency(key);
} else {
if (cache.size() >= capacity) {
removeLFUKey();
}
cache.put(key, value);
frequencies.put(key, 1);
addToFrequencyKeys(key, 1);
}
}
private void updateFrequency(int key) {
int frequency = frequencies.get(key);
frequencies.put(key, frequency + 1);
removeFromFrequencyKeys(key, frequency);
addToFrequencyKeys(key, frequency + 1);
}
private void removeLFUKey() {
int minFreq = Collections.min(frequencyKeys.keySet());
LinkedHashSet<Integer> keysWithMinFreq = frequencyKeys.get(minFreq);
int lfuKey = keysWithMinFreq.iterator().next();
keysWithMinFreq.remove(lfuKey);
if (keysWithMinFreq.isEmpty()) {
frequencyKeys.remove(minFreq);
}
cache.remove(lfuKey);
frequencies.remove(lfuKey);
}
private void addToFrequencyKeys(int key, int frequency) {
frequencyKeys.computeIfAbsent(frequency, k -> new LinkedHashSet<>()).add(key);
}
private void removeFromFrequencyKeys(int key, int frequency) {
LinkedHashSet<Integer> keysWithFreq = frequencyKeys.get(frequency);
if (keysWithFreq != null) {
keysWithFreq.remove(key);
if (keysWithFreq.isEmpty()) {
frequencyKeys.remove(frequency);
}
}
}
}
这个代码实现了LFU缓存的基本思路和算法。
缓存的核心数据结构是一个双哈希表,其中包括三个部分:
- cache:用于存储键值对的哈希表。通过键来查找对应的值。
- frequencies:用于存储键的使用计数的哈希表。通过键来查找对应的使用计数。
- frequencyKeys:用于存储具有相同使用计数的键的集合。使用键的使用计数作为键,并使用链式哈希集合(LinkedHashSet)来存储键的集合。这里使用了链式哈希集合是因为它既可以快速添加和删除元素,又可以保持插入顺序。
LFU缓存的操作主要包括 get 和 put 两个方法。
get(int key) 方法的实现如下:
- 首先检查缓存中是否包含该键,如果存在,则需要更新键的使用频率。
- 更新使用频率的操作包括将键的使用计数加一,将键从原来使用计数对应的集合中删除,再将键添加到新的使用计数对应的集合中。
- 最后返回键对应的值。
put(int key, int value) 方法的实现如下:
- 首先检查缓存中是否已经存在该键,如果存在,则更新键对应的值,并更新使用频率。
- 如果缓存已满,需要删除一个最不经常使用的键(即使用频率最低的键)。通过查找 frequencyKeys 中对应的最小使用频率,找到对应的键集合,从集合中删除一个键。如果该键集合为空,需要将该使用频率从 frequencyKeys 中删除。
- 添加新键值对到缓存中,设置键的使用计数为1,并将键添加到使用计数为1的集合中。
整个实现过程主要依赖于哈希表和链式哈希集合的高效查询和操作,以及通过比较使用频率来确定最不经常使用的键。这种LFU缓存算法能够保持高频率访问的键在缓存中长时间保存,而低频率访问的键则会被逐渐淘汰掉。
这个版本的代码与之前的方法二:TreeMap相比,只是将存储具有相同使用计数的键的集合 frequencyKeys 从 TreeMap 改为了 HashMap,同时使用了 LinkedHashSet 来保持插入顺序。使用 Collections.min 来快速获取最小频率。
实际上,在大多数情况下,由于哈希表的高效性能,这个版本和之前的版本在时间和空间复杂度上没有太大差别。
复杂度分析:
时间复杂度分析:
- 对于 get 操作,由于只需要在哈希表中查找键值,并且更新键的使用频率,其时间复杂度为 O(1)。
- 对于 put 操作,如果缓存中已有相同的键,则需要更新该键对应的值,并将键的使用频率加一。这里的时间复杂度也是 O(1)。
- 如果缓存未满,可以直接将新键值对添加到哈希表中,同时将键的使用频率设置为1。这个操作的时间复杂度也是 O(1)。
- 当缓存已满时,需要先删除一个最不经常使用的键。这里需要查找使用频率最低的键,然后从集合中删除。由于使用了哈希表和链式哈希集合,查找最小频率的键和删除某个键的时间复杂度均为 O(1)。
因此,整个算法的时间复杂度为 O(1)。
空间复杂度分析:
- 空间复杂度主要取决于缓存的容量和缓存中存储的键值对数量。由于缓存容量是固定的,所以空间复杂度为 O(capacity)。
- 注意到使用了三个哈希表来维护键值对、键的使用计数以及具有相同使用计数的键的集合,所以存储键值对和键的使用计数需要额外的空间。但由于哈希表能够快速查找,所以缓存中存储的键值对数量不会很大,因此空间复杂度为 O(capacity)。
- 另外,由于使用了链式哈希集合来维护具有相同使用计数的键的集合,并且将其按频率从低到高存储在哈希表中,所以这里的空间复杂度也是 O(capacity)。
因此,总的空间复杂度为 O(capacity)。
LeetCode运行结果:

第二题
题目来源
35. 搜索插入位置 - 力扣(LeetCode)
题目内容

解决方法
方法一:二分查找
- 在每一次迭代中,通过计算中间元素的索引 mid,并将其与目标值进行比较。根据比较结果,可以确定目标值在数组中的位置。
- 如果中间元素等于目标值,则直接返回中间元素的索引。
- 如果中间元素小于目标值,则说明目标值应该在右半部分,更新左指针 left 为 mid + 1。
- 如果中间元素大于目标值,则说明目标值应该在左半部分,更新右指针 right 为 mid - 1。
- 当循环结束时,左指针 left 的位置就是目标值应该插入的位置,因为 left 右侧的数字都大于或等于目标值,而 left 左侧的数字都小于目标值。
class Solution {
public int searchInsert(int[] nums, int target) {
int left = 0;
int right = nums.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid;
} else if (nums[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
// 如果循环结束仍未找到目标值,则返回应插入的位置(即左指针的位置)
return left;
}
}
复杂度分析:
- 时间复杂度为 O(log n),其中 n 是数组的长度。每次迭代都将搜索范围缩小一半,因此算法的时间复杂度为对数级别。
- 空间复杂度为 O(1),因为该算法只使用了常数级别的额外空间。无论输入数组的大小如何,算法所使用的额外空间都是固定的,与数组大小无关。
LeetCode运行结果:

方法二:线性搜索
除了二分查找算法之外,还可以使用线性搜索的方法来解决搜索插入位置的问题。
class Solution {
public int searchInsert(int[] nums, int target) {
int i = 0;
while (i < nums.length && nums[i] < target) {
i++;
}
return i;
}
}
在这个方法中,我们使用一个索引变量 i 来遍历数组 nums。在每次迭代中,我们检查当前数字是否小于目标值。如果是,则继续向后移动 i,直到找到第一个大于等于目标值的位置或者达到数组的末尾。
最终,返回的 i 就是目标值应该插入的位置。
复杂度分析:
- 使用线性搜索方法解决搜索插入位置问题的时间复杂度为 O(n),其中 n 是数组的长度。在最坏情况下,需要遍历整个数组才能确定插入位置或者达到数组的末尾。
- 空间复杂度为 O(1),因为该方法只使用了常数级别的额外空间,不随输入规模变化。
因此,虽然线性搜索方法不符合题目要求的时间复杂度 O(log n),但仍然可以得到正确的结果。在处理规模较小的数组时,线性搜索方法是可行的选择。如果需要更高效的算法,可以考虑使用二分查找算法。
LeetCode运行结果:
方法三:Arrays类的binarySearch方法
除了二分查找和线性搜索,还有一种方法可以使用Java来解决搜索插入位置问题,即使用Arrays类的binarySearch方法。
import java.util.Arrays;
class Solution {
public int searchInsert(int[] nums, int target) {
int index = Arrays.binarySearch(nums, target);
// 如果找到目标值,则直接返回索引
if (index >= 0) {
return index;
} else {
// 如果未找到目标值,则返回应插入的位置(取反并减一)
return -index - 1;
}
}
}
在这个方法中,我们使用Arrays类的binarySearch方法来搜索目标值在数组中的位置。如果找到目标值,则直接返回该索引;如果未找到目标值,则返回应插入的位置。
需要注意的是,使用Arrays类的binarySearch方法前,需要确保数组是有序的。如果数组无序,那么需要先对数组进行排序,再使用binarySearch方法。
复杂度分析:
- 使用Arrays类的binarySearch方法解决搜索插入位置问题的时间复杂度为O(log n),其中n是数组的长度。这是因为binarySearch方法利用二分查找的思想,在每一轮迭代中将搜索范围缩小一半,直到找到目标值或无法再缩小搜索范围为止。
- 空间复杂度为O(1),因为该方法只使用了常数级别的额外空间。
需要注意的是,使用binarySearch方法前需要确保数组是有序的。如果数组无序,那么需要先对数组进行排序,再使用binarySearch方法。对于未排序数组的排序操作,时间复杂度为O(n log n)。
因此,在确定数组是有序的情况下,使用Arrays类的binarySearch方法可以在较低的时间复杂度内解决搜索插入位置问题。如果数组无序,则需要先进行排序,导致时间复杂度增加。
LeetCode运行结果:

方法四:插入排序
除了二分查找、使用Arrays类的binarySearch方法和线性搜索,还有一种方法是使用插入排序的思想来解决搜索插入位置问题。
class Solution {
public int searchInsert(int[] nums, int target) {
int i = 0;
// 找到第一个大于等于目标值的位置
while (i < nums.length && nums[i] < target) {
i++;
}
// 将目标值插入到找到的位置
int[] newArr = new int[nums.length + 1];
for (int j = 0; j < i; j++) {
newArr[j] = nums[j];
}
newArr[i] = target;
for (int j = i; j < nums.length; j++) {
newArr[j + 1] = nums[j];
}
return i;
}
}
在这个方法中,我们使用一个索引变量i来找到第一个大于等于目标值的位置。然后,我们创建一个新的数组newArr,将目标值插入到找到的位置,并将原数组中的元素按照顺序复制到新数组中。
最后,返回的i就是目标值应该插入的位置。
复杂度分析:
- 使用插入排序思想解决搜索插入位置问题的时间复杂度为O(n),其中n是数组的长度。这是因为在最坏情况下,每次都需要遍历整个数组来找到第一个大于等于目标值的位置。
- 空间复杂度为O(n+1),因为需要创建一个新的长度比原数组多一的数组来存储插入后的结果。
需要注意的是,虽然此方法的时间复杂度较高,但它仍然可以正确地解决搜索插入位置问题。如果对时间复杂度有更高的要求,可以使用二分查找或Arrays类的binarySearch方法。二分查找的时间复杂度为O(log n),Arrays类的binarySearch方法的时间复杂度也为O(log n)。
因此,在处理较大规模的数据时,推荐使用二分查找或Arrays类的binarySearch方法来解决搜索插入位置问题,以获得更好的时间复杂度。而插入排序思想适用于规模较小的问题或者不需要高效解法的情况下。
LeetCode运行结果:
第三题
题目来源
36. 有效的数独 - 力扣(LeetCode)
题目内容


解决方法
方法一:二维数组
class Solution {
public boolean isValidSudoku(char[][] board) {
// 用三个布尔型数组分别记录每行、每列、每个九宫格中数字是否出现过
boolean[][] row = new boolean[9][9];
boolean[][] col = new boolean[9][9];
boolean[][] block = new boolean[9][9];
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
if (board[i][j] != '.') {
int num = board[i][j] - '1';
int k = (i / 3) * 3 + j / 3; // 计算当前位置所在的九宫格编号
if (row[i][num] || col[j][num] || block[k][num]) { // 如果当前数已经出现过
return false;
}
row[i][num] = true;
col[j][num] = true;
block[k][num] = true;
}
}
}
return true;
}
}
该题解法比较简单,使用三个布尔型二维数组来表示数独中每行、每列、每个九宫格中数字是否出现过。对于每个非空数字,根据其所在的行、列、九宫格编号判断该数字是否已经出现过。如果出现过,则返回false,否则标记为出现过。
复杂度分析:
- 对于给定的9x9数独,我们遍历了所有的格子,所以时间复杂度为O(1)。
- 空间复杂度为O(1),因为我们只使用了有限数量的额外空间来存储布尔数组,不随输入规模增长。无论输入的数独尺寸如何变化,额外空间的大小都保持不变。
因此,该算法的时间复杂度和空间复杂度都是常数级别的,具有很高的效率。
LeetCode运行结果:

方法二:哈希集合
除了使用二维数组之外,还可以使用哈希集合来实现判断数独是否有效的算法。
class Solution {
public boolean isValidSudoku(char[][] board) {
Set<String> seen = new HashSet<>();
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
char digit = board[i][j];
if (digit != '.') {
// 检查当前数字是否已经出现过
if (!seen.add(digit + " in row " + i) ||
!seen.add(digit + " in column " + j) ||
!seen.add(digit + " in block " + i/3 + "-" + j/3)) {
return false;
}
}
}
}
return true;
}
}
这种方法利用了哈希集合的无重复性质。我们遍历数独中的每个格子,对于非空格子,将当前数字加入三个不同的字符串形式的键值,分别是它所在的行、列以及九宫格。如果添加操作失败说明该数字在相应的行、列或九宫格内已经存在,即数独无效。
复杂度分析:
- 对于给定的9x9数独,我们遍历了所有的格子,所以时间复杂度为O(1)。
- 空间复杂度为O(1),因为我们只使用了有限数量的额外空间来存储哈希集合中的元素。无论输入的数独尺寸如何变化,额外空间的大小都保持不变。
因此,该算法的时间复杂度和空间复杂度都是常数级别的,具有很高的效率。与二维数组方法相比,这种基于哈希集合的实现可能更加简洁,但实际性能可能略有差异,具体取决于实际情况和测试数据。
LeetCode运行结果:

方法三:单一遍历
除了使用二维数组和哈希集合之外,还可以通过单一遍历的方式来检查数独的有效性。
class Solution {
public boolean isValidSudoku(char[][] board) {
int[] rows = new int[9];
int[] columns = new int[9];
int[] blocks = new int[9];
for (int i = 0; i < 9; i++) {
for (int j = 0; j < 9; j++) {
char digit = board[i][j];
if (digit != '.') {
int mask = 1 << (digit - '1');
int blockIndex = (i / 3) * 3 + j / 3;
if ((rows[i] & mask) != 0 ||
(columns[j] & mask) != 0 ||
(blocks[blockIndex] & mask) != 0) {
return false;
}
rows[i] |= mask;
columns[j] |= mask;
blocks[blockIndex] |= mask;
}
}
}
return true;
}
}
这种方法使用三个一维数组来分别表示每行、每列和每个九宫格中数字是否出现过。对于每个非空格子,使用位运算来标记数字的出现情况。具体地,使用一个32位整数作为位掩码,将位掩码的对应位设置为1表示该数字已经出现过。如果在任何一个数组中发现重复的位掩码,则说明数独无效。
复杂度分析:
- 对于给定的9x9数独,我们遍历了所有的格子,所以时间复杂度为O(1)。
- 空间复杂度为O(1),因为我们只使用了三个固定大小的数组(每个数组大小为9)来存储数字的出现情况。无论输入的数独尺寸如何变化,额外空间的大小都保持不变。
因此,该算法的时间复杂度和空间复杂度都是常数级别的,具有很高的效率。与二维数组和哈希集合方法相比,这种基于单一遍历的实现可能更加简洁,并且减少了额外的存储空间,可能在某些情况下性能略有提升。但实际性能可能略有差异,具体取决于实际情况和测试数据。
LeetCode运行结果:

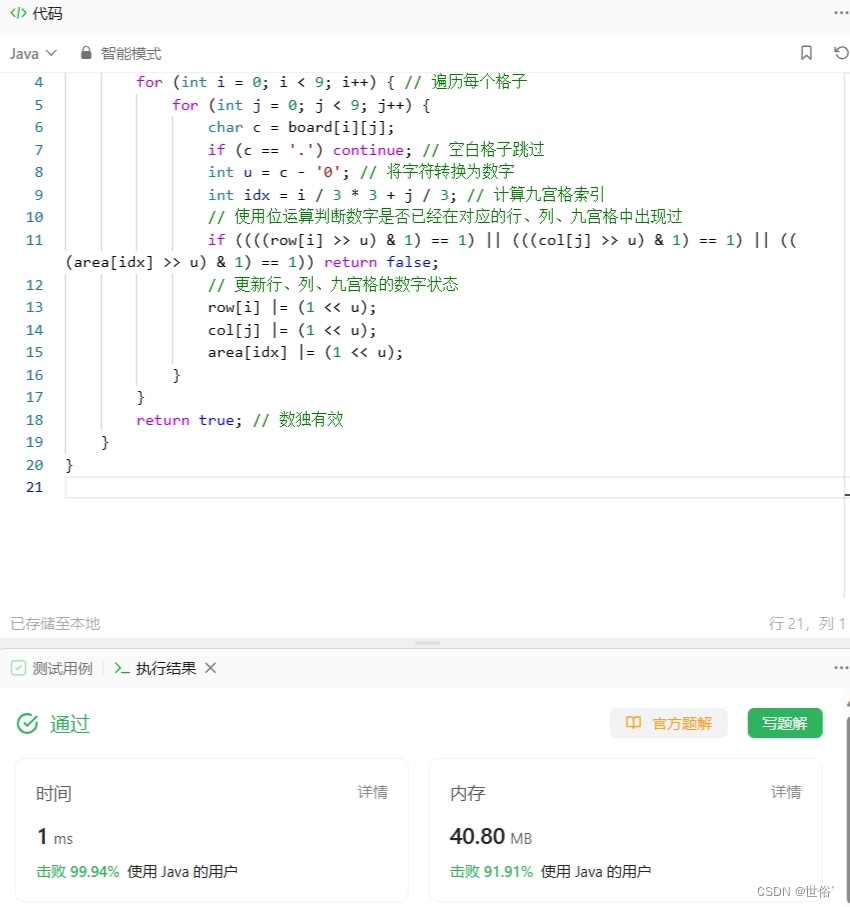
方法四:位运算
使用位运算来进行判断,利用了三个一维数组`row`、`col`和`area`来保存数独中每行、每列和每个九宫格的数字状态。
算法的实现逻辑如下:
1. 使用两个循环遍历数独的每个格子。
2. 对于非空格子,获取该格子的数字并将其转化为整数。
3. 根据当前格子所在的行、列和九宫格的索引,使用位运算来判断该数字是否在对应的行、列和九宫格中已经出现过。如果出现重复,则返回`false`。
4. 如果数字在当前行、列和九宫格中没有出现过,则更新对应的状态数组。
5. 最后,如果遍历完所有的格子都没有发现重复数字,则返回`true`,表示数独是有效的。
这种方法使用位运算来实现判断,可以减少内存的使用,并且具有较好的性能。
需要注意的是,该方法只能判断数独是否有效,而不能求解数独的解。
class Solution {
public boolean isValidSudoku(char[][] board) {
int[] row = new int[10], col = new int[10], area = new int[10]; // 分别表示行、列、九宫格的数字状态数组
for (int i = 0; i < 9; i++) { // 遍历每个格子
for (int j = 0; j < 9; j++) {
char c = board[i][j];
if (c == '.') continue; // 空白格子跳过
int u = c - '0'; // 将字符转换为数字
int idx = i / 3 * 3 + j / 3; // 计算九宫格索引
// 使用位运算判断数字是否已经在对应的行、列、九宫格中出现过
if ((((row[i] >> u) & 1) == 1) || (((col[j] >> u) & 1) == 1) || (((area[idx] >> u) & 1) == 1)) return false;
// 更新行、列、九宫格的数字状态
row[i] |= (1 << u);
col[j] |= (1 << u);
area[idx] |= (1 << u);
}
}
return true; // 数独有效
}
}
复杂度分析:
时间复杂度分析:
- 外层循环遍历数独的每一行,内层循环遍历数独的每一列,因此总共有 9 行 * 9 列 = 81 个格子需要遍历。
- 内部的位运算操作以及数组更新操作都是固定时间的常数操作。
- 因此,整体的时间复杂度为 O(1),即与输入规模无关。
空间复杂度分析:
- 空间复杂度由三个长度为 10 的一维数组
row、col和area决定,这是一个固定大小的数组。 - 不随输入规模变化,因此空间复杂度也为 O(1),与输入规模无关。
综上所述,这段代码的时间复杂度和空间复杂度均为 O(1)。这是一种高效的解决方案。
LeetCode运行结果: