1. 拉取镜像
docker pull registry.baidubce.com/paddlepaddle/paddle:2.4.0
注:写该文章时,Paddle 最新版本为2.5.1,但是在实际安装中会出现与 PaddleHub 2.3.1版本的冲突,故采用2.4.0版本
2. 构建并进入容器
docker run --name paddle_docker -it registry.baidubce.com/paddlepaddle/paddle:2.4.0 /bin/bash
3. 安装paddlehub
pip install paddlehub==2.3.1
4. 下载paddleocr项目文件
git clone https://github.com/PaddlePaddle/PaddleOCR.git /PaddleOCR
5. 安装项目所需包
pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
注:
如果是拉取的最新版的PaddleOCR代码(写该文章时最新版未release-2.7),pillow可能会安装不成功,10.0.0版本需要python 3.8+以上版本,经过测试安装pillow=9.5.0亦可
6. 下载并解压模型文件
mkdir -p /PaddleOCR/inference/
# 下载文本检测模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar -P /PaddleOCR/inference/
tar xf /PaddleOCR/inference/ch_PP-OCRv3_det_infer.tar -C /PaddleOCR/inference/
# 下载文本识别模型
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar -P /PaddleOCR/inference/
tar xf /PaddleOCR/inference/ch_PP-OCRv3_rec_infer.tar -C /PaddleOCR/inference/
# 下载方向检测模型
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar -P /PaddleOCR/inference/
tar xf /PaddleOCR/inference/ch_ppocr_mobile_v2.0_cls_infer.tar -C /PaddleOCR/inference/
7. 安装OCR模块
hub install deploy/hubserving/ocr_system/

8. 启动服务
hub serving start --modules [Module1==Version1, Module2==Version2, ...] \
--port XXXX \
--use_multiprocess \
--workers \
| 参数 | 用途 |
|---|---|
| –modules/-m | PaddleHub Serving预安装模型,以多个Module==Version键值对的形式列出,当不指定Version,默认选择最新版本 |
| –port/-p | 服务端口,默认为8866 |
| –use_multiprocess | 是否启用并发方式,默认为单进程方式,推荐多核CPU机器使用此方式,Windows操作系统只支持单进程模式 |
| –workers | 在并发方式下指定的并发任务数,默认为2*cpu_count-1,其中cpu_count为CPU核数 |
| 配置文件启动(支持CPU、GPU) |
hub serving start -c config.json
其中,config.json格式如下:
{
"modules_info": {
"ocr_system": {
"init_args": {
"version": "1.0.0",
"use_gpu": true
},
"predict_args": {
}
}
},
"port": 8868,
"use_multiprocess": false,
"workers": 2
}
- init_args中的可配参数与module.py中的_initialize函数接口一致。其中,当use_gpu为true时,表示使用GPU启动服务。
- predict_args中的可配参数与module.py中的predict函数接口一致。
注意:
- 使用配置文件启动服务时,其他参数会被忽略。
- 如果使用GPU预测(即,use_gpu置为true),则需要在启动服务之前,设置CUDA_VISIBLE_DEVICES环境变量,如:export CUDA_VISIBLE_DEVICES=0,否则不用设置。
- use_gpu不可与use_multiprocess同时为true
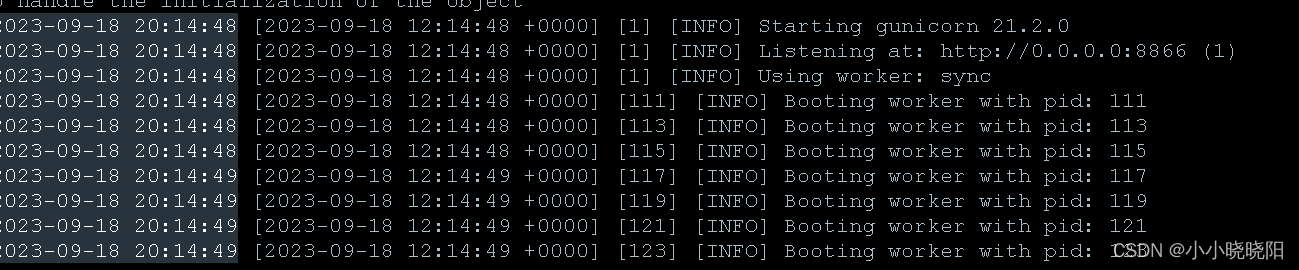
9. 参考意见
- 可直接通过官方提供的Dockerfile文件部署,但是官方文件没有考虑版本问题,所以直接安装过程中可能出现各种包冲突问题。
地址:https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/deploy/docker/hubserving/cpu/Dockerfile - 该部署方式默认不启用cpu加速,如果需要开启cpu加速可以去如下文件中(https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/deploy/hubserving/ocr_system/module.py)中修改enable_mkldnn参数未True,截止文章发布日期,pp-ocr-v4不支持该参数。
- 不推荐使用默认workers,调用量较大情况下,速度会很慢,尤其在开启CPU加速情况下,cpu资源耗费会更大,请合理分配workers。
- worker挂掉会自动重启,内存不够会报内存溢出error
参考文件:
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/deploy/hubserving/readme.md