一、目的
经过6个月的奋斗,项目的离线数仓部分终于可以上线了,因此整理一下离线数仓的整个流程,既是大家提供一个案例经验,也是对自己近半年的工作进行一个总结。
二、数仓实施步骤
(六)步骤六、在ClickHouse的ADS层建表并用Kettle同步Hive中DWS层的结果数据
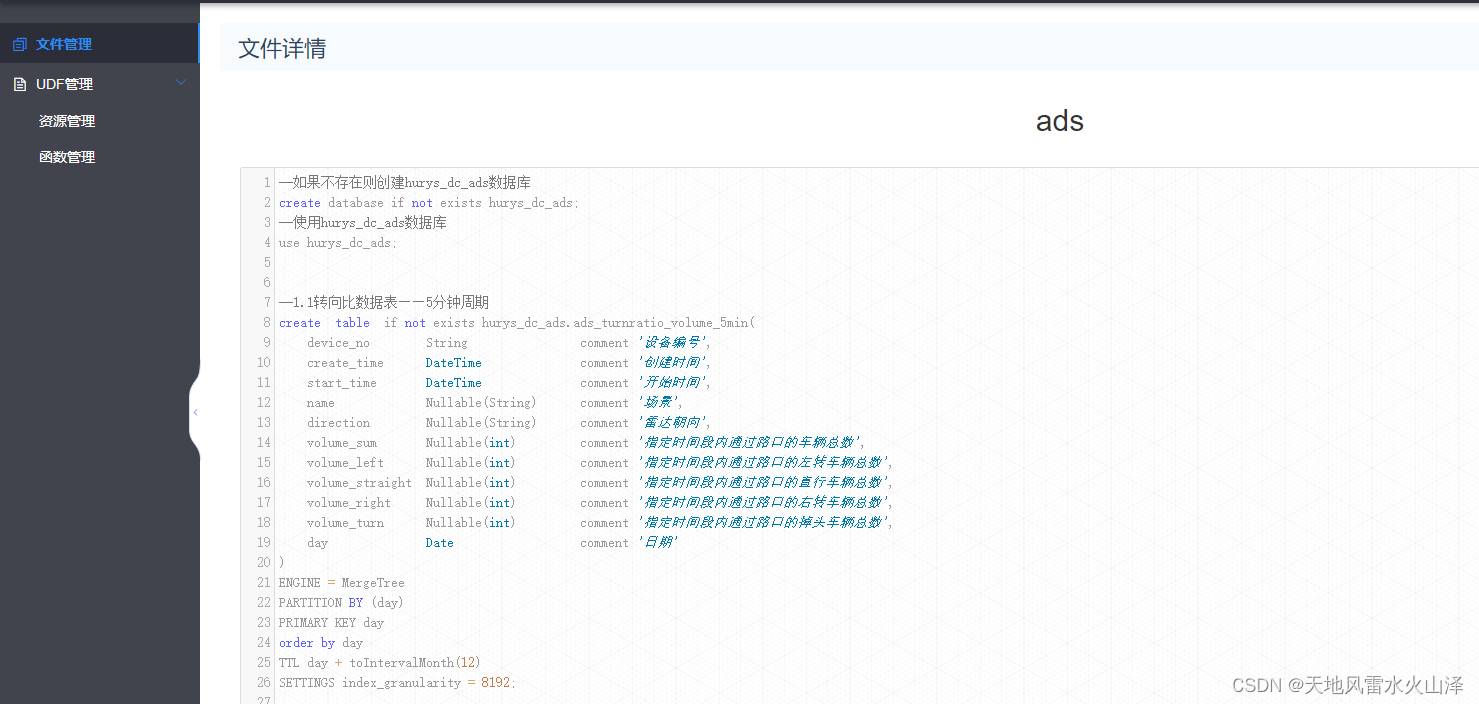
1、ClickHouse的ADS层建库建表语句
--如果不存在则创建hurys_dc_ads数据库
create database if not exists hurys_dc_ads;
--使用hurys_dc_ads数据库
use hurys_dc_ads;
--1.1转向比数据表——5分钟周期
create table if not exists hurys_dc_ads.ads_turnratio_volume_5min(
device_no String comment '设备编号',
create_time DateTime comment '创建时间',
start_time DateTime comment '开始时间',
name Nullable(String) comment '场景',
direction Nullable(String) comment '雷达朝向',
volume_sum Nullable(int) comment '指定时间段内通过路口的车辆总数',
volume_left Nullable(int) comment '指定时间段内通过路口的左转车辆总数',
volume_straight Nullable(int) comment '指定时间段内通过路口的直行车辆总数',
volume_right Nullable(int) comment '指定时间段内通过路口的右转车辆总数',
volume_turn Nullable(int) comment '指定时间段内通过路口的掉头车辆总数',
day Date comment '日期'
)
ENGINE = MergeTree
PARTITION BY (day)
PRIMARY KEY day
order by day
TTL day + toIntervalMonth(12)
SETTINGS index_granularity = 8192;
2、海豚执行ADS层建表语句工作流
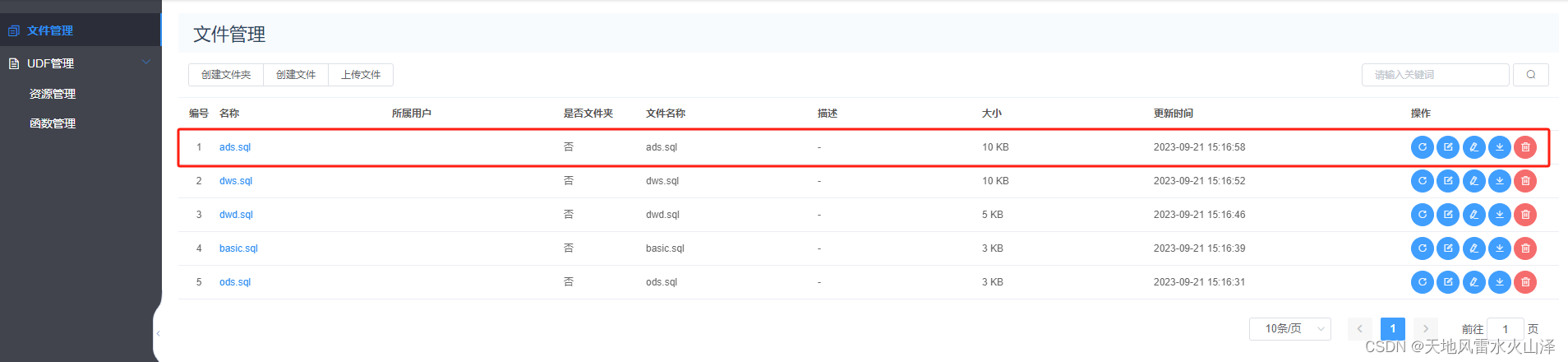
对于刚部署的服务器,由于Hive没有建库建表、而且手动建表效率低,因此通过海豚调度器直接执行建库建表的.sql文件
(1)海豚的资源中心加建库建表的SQL文件
(2)海豚配置DWS层建表语句的工作流(不需要定时,一次就行)

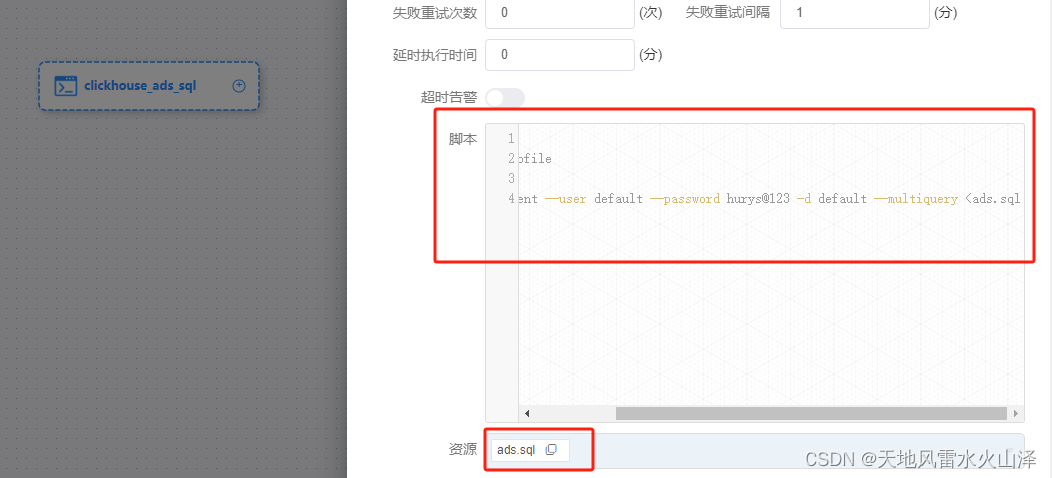
#! /bin/bash
source /etc/profile
clickhouse-client --user default --password hurys@123 -d default --multiquery <ads.sql
注意:default是clickhouse创建时自带的数据库
3、Kettle转换任务配置
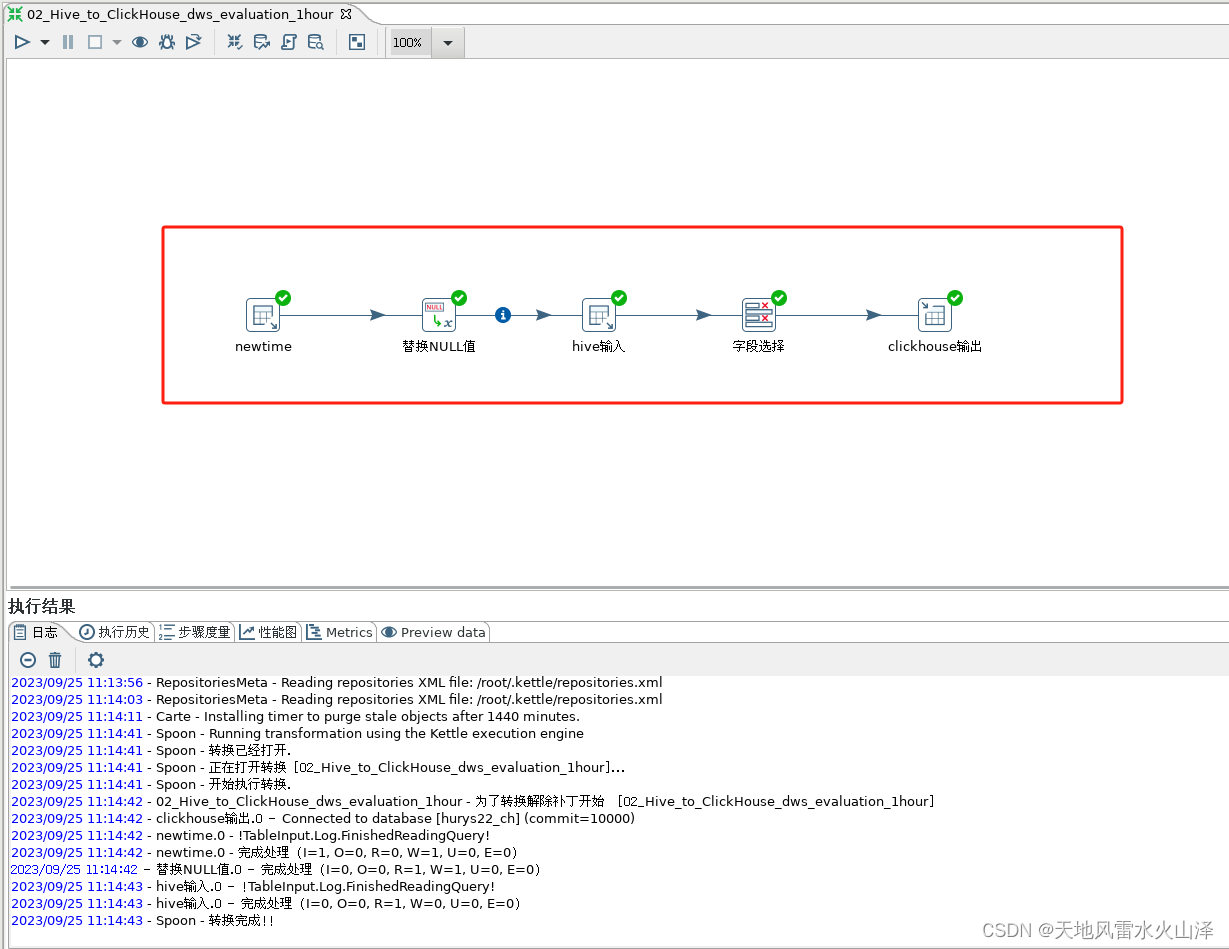
注意:从Hive到ClickHouse,每次是增量导入,而不是全量导入
4、海豚调度器调度kettle转换任务
(1)海豚配置ADS层每日执行Kettle任务的工作流(需要定时,每日一次)
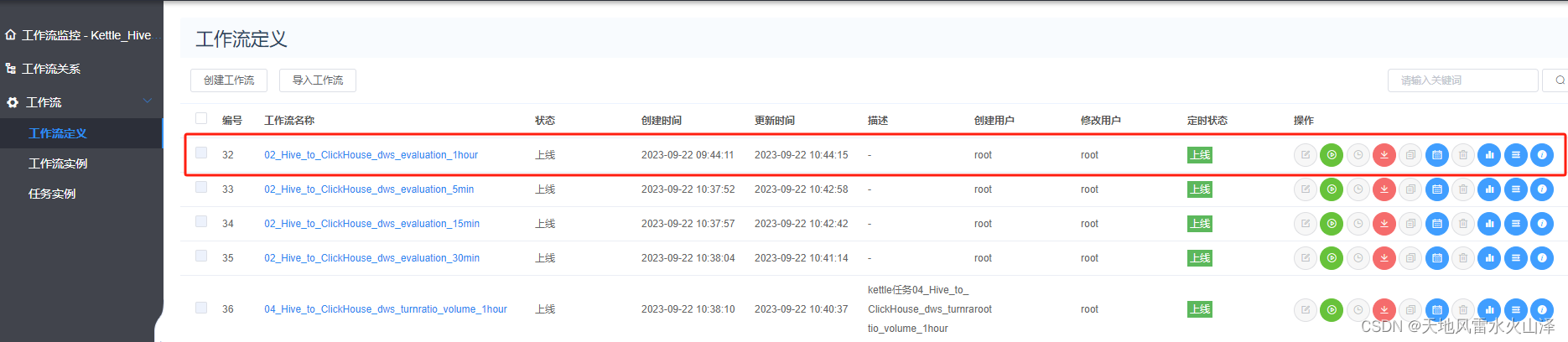
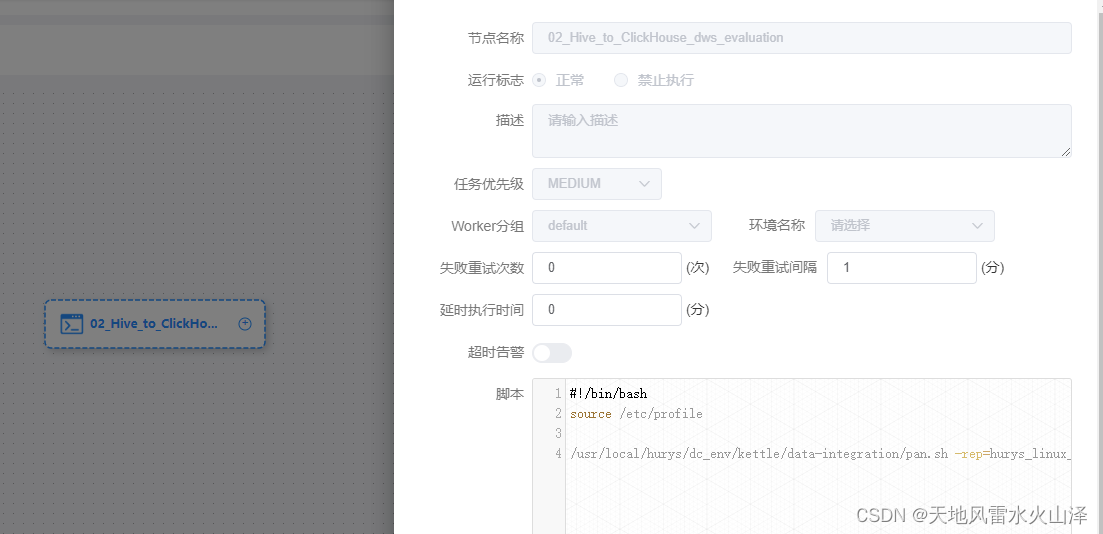
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/kettle/data-integration/pan.sh -rep=hurys_linux_kettle_repository -user=admin -pass=admin -dir=/hive_to_clickhouse/ -trans=02_Hive_to_ClickHouse_dws_evaluation_1hour level=Basic >>/home/log/kettle/02_Hive_to_ClickHouse_dws_evaluation_1hour_`date +%Y%m%d`.log
(2)工作流定时任务设置(注意与其他工作流的时间间隔)

(3)注意点
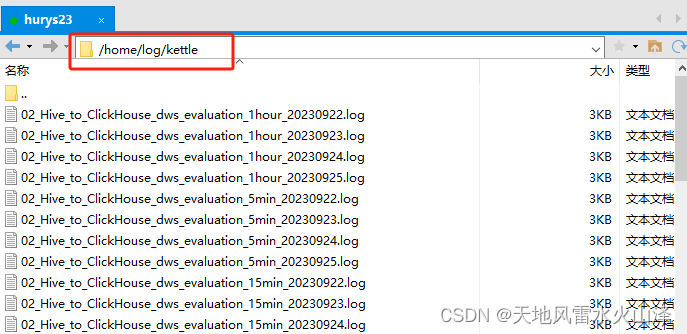
3.3.1 由于每次kettle任务是增量导入数据,因此在脚本里添加kettle运行的日志
level=Basic >>/home/log/kettle/02_Hive_to_ClickHouse_dws_evaluation_1hour_`date +%Y%m%d`.log
可以查看一下kettle运行的日志文件
离线数仓从Kafka到ClickHouse的全流程大致就是如此,当然很多细节需要优化完善!