-
目前最先进的神经网络模型,其本质上也是在利用一系列线性和非线性的函数去拟合目标输出。既然是拟合,当然越多的样本就能获得越准确的结果,这也是为什么现在训练神经网络所使用的数据规模越来越大。
-
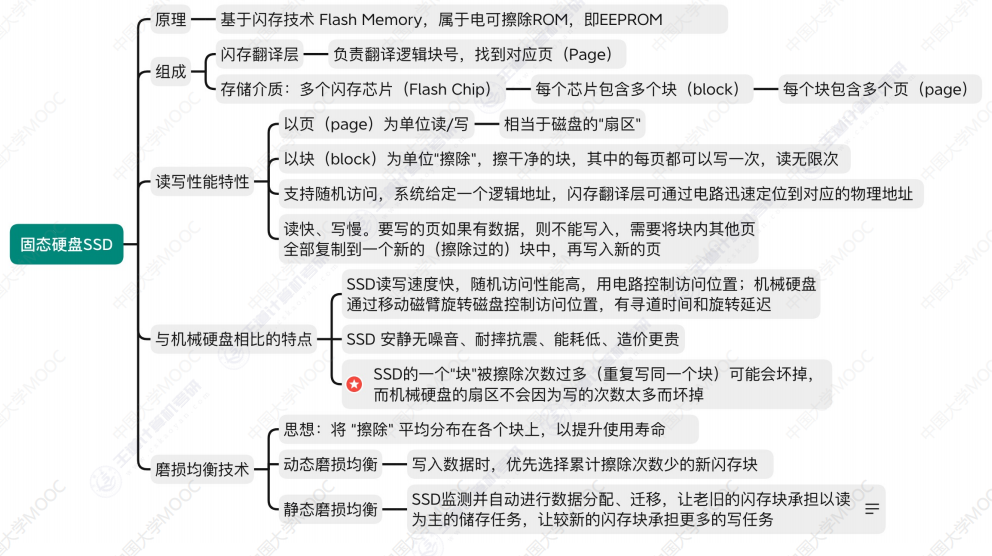
在实际使用中,我们往往可能只有几千甚至几百份数据。面对神经网络数以 M 计的参数,很容易陷入过拟合的陷阱。因为神经网络的收敛需要一个较长的训练过程,而这个过程中网络遇到的反反复复都是训练集的那几张图片,硬背都背下来了,自然很难学到什么能够泛化的特征。一个自然的想法是,能不能用一张图片去生成一系列图片,从而成百上千倍地扩充我们的数据集?而这,也正是数据增强的目的之一。
-
神经网络是没有常识的,因此它永远只会用最“方便”的方式区分两个类别。假设我们要训练一个区分苹果和橘子的神经网络,但手上的数据只有红苹果和青橘子,那无论我们拍摄多少张照片,神经网络也只会简单地认为红色的就是苹果,青色的就是橘子。这在实际使用中经常出现,拍摄的灯光、拍摄的角度等等,任何一个不起眼的区分点,都会被神经网络当做分类的依据。
-
数据增强的目标并不是无脑地堆数据,而是尽可能地去覆盖原始数据无法覆盖不到,但现实生活中会出现的情况。使用数据增强技术可以增加数据集中图像的多样性,从而提高模型的性能和泛化能力。在Pytorch框架中,常用的数据增强的函数主要集成在了transforms文件中,由于transforms的输入规定为PIL文件格式,所以我们需要使用PIL.Image模块。
-
导包:
-
from PIL import Image from pathlib import Path import matplotlib.pyplot as plt import torch import numpy as np plt.rcParams["savefig.bbox"]="tight" org_img=Image.open(Path("nest.jpg")) torch.manual_seed(0) print(np.array(org_img).shape) # (2286, 2603, 3) -
resize,缩放
-
import torchvision.transforms as T resize_img=[T.Resize(size=newsize)(org_img) for newsize in [1000,2000]] ax1=plt.subplot(131) ax1.set_title("original") ax1.imshow(org_img) ax2=plt.subplot(132) ax2.set_title("1000*1000") ax2.imshow(resize_img[0]) ax3=plt.subplot(133) ax3.set_title(2000*2000) ax3.imshow(resize_img[1]) plt.show() -

-
灰度化
-
gray_img = T.Grayscale()(org_img) ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('gray') ax2.imshow(gray_img,cmap='gray') plt.show() -

-
标准化
-
norm_img=T.Normalize(mean=(0.5,0.5,0.5),std=(0.5,0.5,0.5))(T.ToTensor()(org_img)) norm_img=[T.ToPILImage()(norm_img)] ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('normalize') ax2.imshow(norm_img[0]) plt.show() -

-
旋转
-
plt.rcParams['font.sans-serif'] = ['SimHei'] rotate_img=[T.RandomRotation(degrees=180)(org_img)] # print(rotate_img) ax1=plt.subplot(121) ax1.set_title("original") ax1.imshow(org_img) ax2=plt.subplot(122) ax2.set_title("$180$") ax2.imshow(rotate_img[0]) plt.show() -

-
中心裁剪
-
center_crop=[T.CenterCrop(size=newsize)(org_img) for newsize in (300,600)] ax1 = plt.subplot(131) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(132) ax2.set_title('300*300') ax2.imshow(np.array(center_crop[0])) ax3 = plt.subplot(133) ax3.set_title('600*600') ax3.imshow(np.array(center_crop[1])) plt.show() -

-
随机裁剪
-
rand_corp=[T.RandomCrop(size=newsize)(org_img) for newsize in [500,1000]] ax1 = plt.subplot(131) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(132) ax2.set_title('500*500') ax2.imshow(np.array(rand_corp[0])) ax3 = plt.subplot(133) ax3.set_title('1000*1000') ax3.imshow(np.array(rand_corp[1])) plt.show() -

-
加入高斯噪声
-
blur_img=[T.GaussianBlur(kernel_size=(3,3),sigma=x)(org_img) for x in (30,60)] ax1 = plt.subplot(131) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(132) ax2.set_title('sigma=30') ax2.imshow(np.array(blur_img[0])) ax3 = plt.subplot(133) ax3.set_title('sigma=60') ax3.imshow(np.array(blur_img[1])) plt.show() -

-
调色,饱和等
-
colorjitter=[T.ColorJitter(brightness=(0.2,0.8),contrast=(0.5,0.5),saturation=(0.5,0.5),hue=0.5)(org_img)] # 亮度(brightness)、对比度(contrast)、饱和度(saturation)和色调(hue) # brightness_factor从[max(0, 1 - brightness), 1 + brightness]中随机采样产生。应当是非负数。 # contrast_factor从[max(0, 1 - contrast), 1 + contrast]中随机采样产生。应当是非负数。 # saturation_factor从[max(0, 1 - saturation), 1 + saturation]中随机采样产生。应当是非负数。 # hue_factor从[-hue, hue]中随机采样产生,其值应当满足0<= hue <= 0.5或-0.5 <= min <= max <= 0.5 ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('colorjitter') ax2.imshow(np.array(colorjitter[0])) plt.show() -

-
水平翻转
-
horizon=[T.RandomHorizontalFlip(p=1)(org_img)] # p表示概率 ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('horizon') ax2.imshow(np.array(horizon[0])) plt.show() -

-
垂直翻转
-
vertical=[T.RandomVerticalFlip(p=1)(org_img)] ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('VerticalFlip') ax2.imshow(np.array(vertical[0])) plt.show() -

-
加入自定义噪声
-
def add_noise(imputs,noise_fac=0.5): noise=imputs + torch.randn_like(imputs)*noise_fac noise=torch.clip(noise,0.0,1.0) # clip这个函数将将数组中的元素限制在a_min, a_max之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min。 return noise noise_img=[add_noise(T.ToTensor()(org_img),fac) for fac in (0.4,0.8)] noise_img=[T.ToPILImage()(n_img) for n_img in noise_img] ax1 = plt.subplot(131) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(132) ax2.set_title('noise_factor=0.4') ax2.imshow(np.array(noise_img[0])) ax3 = plt.subplot(133) ax3.set_title('noise_factor=0.8') ax3.imshow(np.array(noise_img[1])) plt.show() -

-
加入掩码块
-
def add_box(img,num_box,size=100): h,w=size,size img=np.asarray(img).copy() img_size=img.shape[1] boxes=[] for k in range(num_box): y,x=np.random.randint(0,img_size-w,(2,)) img[y:y+h,x:x+w]=0 boxes.append((x,y,h,w)) img=Image.fromarray(img.astype('uint8'),'RGB') return img block_img=[add_box(org_img,num_box=15)] ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('add black boxes') ax2.imshow(np.array(block_img[0])) plt.show() -

-
中心掩码块
-
def add_center(o_img,size=150): h,w=size,size img=np.asarray(o_img).copy() img_size=img.shape[1] img[int(img_size/2-h):int(img_size/2+h),int(img_size/2-w):int(img_size/2+w)]=0 img=Image.fromarray(img.astype('uint8'),'RGB') return img center_img=[add_center(org_img,size=200)] ax1 = plt.subplot(121) ax1.set_title('original') ax1.imshow(org_img) ax2 = plt.subplot(122) ax2.set_title('add_center') ax2.imshow(np.array(center_img[0])) plt.show() -

-
多进程与多线程
-
并发:在一段时间内交替去执行多个任务。例子:对于单核cpu处理多任务,操作系统轮流让各个任务交替执行。
-
并行:在一段时间内真正的同时一起执行多个任务。例子:对于多核cpu处理多任务,操作系统会给cpu的每个内核安排一个执行的任务,多个内核是真正的一起同时执行多个任务。这里需要注意多核cpu是并行的执行多任务,始终有多个任务一起执行。
-
进程是操作系统分配资源的最小单元, 线程是操作系统调度的最小单元。(一个是供分配, 一个是供调度)
-
一个应用程序至少包括1个进程,而1个进程包括1个或多个线程,线程的尺度更小。
-
每个进程在执行过程中拥有独立的内存单元,而一个进程的多个线程在执行过程中共享内存。
-
一座工厂(类似CPU),假设电力有限,只能供一个车间,即只能运行一个任务,里面有许多的车间(类似进程),执行单个的任务,这时,就是每次只能单个车间运行,若是另一个车间想工作,则当前车间得休息。
-
而多核CPU,就像多个工厂,它可以同时让多个车间(类似多个进程)一起工作,当然,是工作在不同工厂里,也就是运行在不同CPU核上。
-
而每个车间里有很多的工人,这就类似是线程,一个车间可以有多个工人,也就是一个进程可有多个线程。
-
这就是基本的CPU、多核、进程、线程之间的关系。这里好像一切都很和谐,跟锁没什么关系。为社么会出现锁呢? 接下来就得谈谈内存占用的问题。
-
在一个进程下,它拥有的资源是有限的(有多少呢,举个例子),而在这个进程下,多个线程是共享这些资源的,就像是一个车间地方大小是一定的,每个工人工作占用的地方不一致,那怎么办呢,那就得加把锁了,当某个工作地方被占满了就得挂上锁,告诉其他工人,这里已经容不下人了。得等人出来,也就是某个线程结束释放内存时,才能又进去人,开始新的线程。
-
这里大佬们发明了一个简单防止冲突的方法,叫做互斥锁(Mutual exclusion,缩写 Mutex)。也就是说,一个线程在使用共享内存时,会把门锁住,防止其他人进来占用。后来的人得等着,等这把锁被解开,也就是空间被释放,才能再进去用这个空间。
-
还有些房间,可以同时容纳n个人。也就是说,如果人数大于n,多出来的人只能在外面等着。这好比某些内存区域,只能供给固定数目的线程使用。这时的解决方法,就是在门口挂n把钥匙。进去的人就取一把钥匙,出来时再把钥匙挂回原处。后到的人发现钥匙架空了,就知道必须在门口排队等着了。这种做法叫做"信号量"(Semaphore),用来保证多个线程不会互相冲突。
-
-
多进程CPU会自动分配资源,同时可以跑在不同的内核上。而Python多线程则在CPU上实际上是间断的工作,就是一个线程跑,则其他线程处于休息状态,下一个线程开始,则其他线程又进入休息状态。
-
多线程: threading,利用CPU和IO可以同时执行的原理,让CPU不会干巴巴等待IO完成
- 多线程Thread ( threading) 优点:相比进程,更轻量级.占用资源少。缺点:相比讲程,多线程只能并发执行,不能利用多CPU ( GIL)·相比协程:启动数目有限制,占用内存资源,有线程切换开销。适用于:Io密集型计算、同时运行的任务数目要求不多
-
多进程:multiprocessing,利用多核CPU的能力,真正的并行执行任务
- 多进程Process ( multiprocessing)·优点:可以利用多核CPU并行运算。缺点:占用资源最多、可启动数自比线程少,适用于:CPU密集型计算
-
异步IO: asyncio,在单线程利用CPU和IO同时执行的原理,实现函数异步执行
- 多协程Coroutine ( asyncio ) 优点:内存开销最少、启动协程数量最多。 缺点:支持的库有限制(aiohttp vs requests)、代码实现复杂。适用于:IO密集型计算、需要超多任务运行、但有现成库支持的场景
-
一个进程里可有多个线程,一个线程里可有多个协程。
-
使用Lock对资源加锁,防止冲突访问
-
使用Queue实现不同线程/进程之间的数据通信,实现生产者-消费者模式
-
使用线程池Pool/进程池Pool,简化线程/进程的任务提交、等待结束、获取结果
-
使用subprocess启动外部程序的进程,并进行输入输出交互
-
CPU密集型也叫计算密集型,是指 I/O 在很短的时间就可以完成,CPU需要大量的计算和处理,特点是CPU占用率相当高
- 例如:压缩解压缩、加密解密、正则表达式搜索
-
I/O 密集型指的是系统运作大部分的状况是CPU在等I/O(硬盘/内存)的读/写操作,CPU占用率仍然较低。
- 例如:文件处理程序、网络爬虫程序、读写数据库程序
-
全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。即便在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。GIL简化了共享资源的管理.
- 因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
-
多线程threading机制依然是有用的,用于IO密集型计算。因为在I/O (read,write,send,recv,etc.)期间,线程会释放GIL,实现CPU和IO的并行因此多线程用于IO密集型计算依然可以大幅提升速度。但是多线程用于CPU密集型计算时,只会更加拖慢速度。
-
使用multiprocessing的多进程机制实现并行计算、利用多核CPU优势。为了应对GIL的问题,Python提供了multiprocessing
-

-
新建线程系统需要分配资源、终止线程系统需要回收资源如果可以重用线程,则可以减去新建/终止的开销。一个线程的运行时间可以分为3部分:线程的启动时间、线程体的运行时间和线程的销毁时间。在多线程处理的情景中,如果线程不能被重用,就意味着每次创建都需要经过启动、销毁和运行3个过程。这必然会增加系统相应的时间,降低了效率。
-

-
使用线程池的好处1、提升性能:因为减去了大量新建、终止线程的开销,重用了线程资源;2、适用场景:适合处理突发性大量请求或需要大量线程完成任务、但实际任务处理时间较短;3、防御功能:能有效避免系统因为创建线程过多,而导致系统负荷过大相应变慢等问题;4、代码优势:使用线程池的语法比自己新建线程执行线程更加简洁
-
使用线程池:由于线程预先被创建并放入线程池中,同时处理完当前任务之后并不销毁而是被安排处理下一个任务,因此能够避免多次创建线程,从而节省线程创建和销毁的开销,能带来更好的性能和系统稳定性。线程池基本原理: 我们把任务放进队列中去,然后开N个线程,每个线程都去队列中取一个任务,执行完了之后告诉系统说我执行完了,然后接着去队列中取下一个任务,直至队列中所有任务取空,退出线程。
-

-
# 创建队列实例, 用于存储任务 queue = Queue() # 定义需要线程池执行的任务 def do_job(): while True: i = queue.get() time.sleep(1) print 'index %s, curent: %s' % (i, threading.current_thread()) queue.task_done() if __name__ == '__main__': # 创建包括3个线程的线程池 for i in range(3): t = Thread(target=do_job) t.daemon=True # 设置线程daemon 主线程退出,daemon线程也会推出,即时正在运行 t.start() # 模拟创建线程池3秒后塞进10个任务到队列 time.sleep(3) for i in range(10): queue.put(i) queue.join() -
多线程和多进程在python中的支持
-

-
信号量(英语:Semaphore)又称为信号量、旗语,是一个同步对象,用于保持在0至指定最大值之间的一个计数值。当线程完成一次对该semaphore对象的等待( wait)时,该计数值减一;·当线程完成一次对semaphore对象的释放(release)时,计数值加一。当计数值为0,则线程等待该semaphore对象不再能成功直至该semaphore对象变成signaled状态. semaphore对象的计数值大于0,为signaled状态;计数值等于0,为nonsignaled状态.
-
设置主进程守护:子进程对象.daemon=true。多线程是Python程序中实现多任务的一种方式;线程是程序执行的最小单位;同属一个进程的多个线程共享进程所拥有的全部资源.