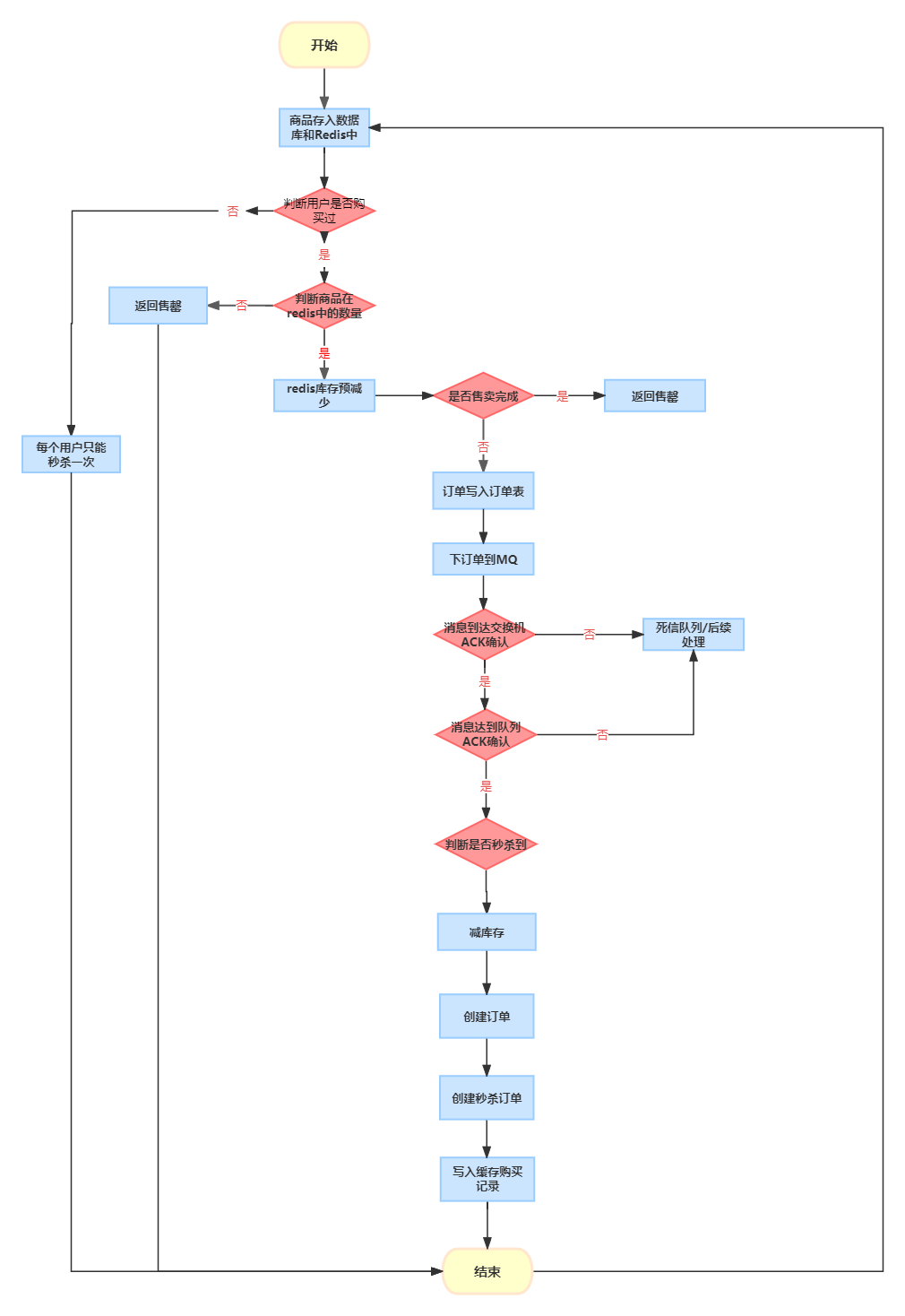
7.7.1 从 ResNet 到 DenseNet
DenseNet 可以视为 ResNet 的逻辑扩展。
ResNet 将函数展开为 f ( x ) = x + g ( x ) f(\boldsymbol{x})=x+g(\boldsymbol{x}) f(x)=x+g(x),即一个简单的线性项和一个复杂的非线性项。
若将 f f f 拓展成超过两部分,则 DenseNet 便是其中一种方案。这即是 DenseNet 和 ResNet 的主要区别。

DenseNet 这个名字由变量之间的“稠密连接”而得来。主要由两部分构成:
-
稠密块:定义如何连接输入和输出。
-
过渡层:控制通道数量,使其不会太复杂。
何为稠密连接?即最后一层与之前的所有层紧密相连,DenseNet 输出是连接执行从 x \boldsymbol{x} x 到其展开式的映射:
x → [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) , f 3 ( [ x , f 1 ( x ) , f 2 ( [ x , f 1 ( x ) ] ) ] , … ) ] \boldsymbol{x}\to \left[\boldsymbol{x},f_1(\boldsymbol{x}),f_2([\boldsymbol{x},f_1(\boldsymbol{x})]),f_3([\boldsymbol{x},f_1(x),f_2([\boldsymbol{x},f_1(x)])],\dots)\right] x→[x,f1(x),f2([x,f1(x)]),f3([x,f1(x),f2([x,f1(x)])],…)]

7.7.2 稠密块体
import torch
from torch import nn
from d2l import torch as d2l
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block( # 输入通道按稠密连接调整
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1) # 连接通道维度上每个块的输入和输出
return X
blk = DenseBlock(2, 3, 10) # 会得到 3+2*10=23 通道数的输出
X = torch.randn(4, 3, 8, 8)
Y = blk(X)
Y.shape
torch.Size([4, 23, 8, 8])
7.7.3 过渡层
由于每个稠密块都会带来通道数的增加,由此会导致模型复杂化。可以使用过渡层来控制模型复杂度,它通过 1 × 1 1\times 1 1×1 的卷积层来减小通道数,并使用步幅为2的平均汇聚层加班班高度和宽度,从而降低模型复杂度。
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
blk = transition_block(23, 10) # 通道数缩减为10
blk(Y).shape
torch.Size([4, 10, 4, 4])
7.7.4 DenseNet 模型
b1 = nn.Sequential( # b1 层和前面一样的
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
num_convs_in_dense_blocks = [4, 4, 4, 4] # 使用4个稠密块,每个稠密块内使用4个卷积层
num_channels, growth_rate = 64, 32 # 增长率为32则每个稠密块增加4*32=128个通道
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
num_channels += num_convs * growth_rate # 计算上一个稠密块的输出通道数作为下一个块的输入通道数
if i != len(num_convs_in_dense_blocks) - 1: # 在稠密块之间添加一个过渡层,使通道数量减半
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)), # 最终使用全局汇聚层和全连接层输出结果
nn.Flatten(),
nn.Linear(num_channels, 10))
7.7.5 训练模型
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu()) # 大约需要十五分钟,慎跑
loss 0.140, train acc 0.948, test acc 0.914
865.0 examples/sec on cuda:0

练习
(1)为什么我们在过渡层使用平均汇聚层而不是最大汇聚层?
我觉得平均汇聚就像考虑所有特征,而最大汇聚就像只考虑最明显的特征。
过渡层如果只考虑最明显特征可能就会有特征损失掉。
不过实测差别似乎不大 。
(2)DenseNet 的优点之一是其模型参数比 ResNet 小。为什么呢?
X = torch.rand(size=(1, 1, 224, 224), device=d2l.try_gpu())
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
DenseBlock output shape: torch.Size([1, 192, 56, 56])
Sequential output shape: torch.Size([1, 96, 28, 28])
DenseBlock output shape: torch.Size([1, 224, 28, 28])
Sequential output shape: torch.Size([1, 112, 14, 14])
DenseBlock output shape: torch.Size([1, 240, 14, 14])
Sequential output shape: torch.Size([1, 120, 7, 7])
DenseBlock output shape: torch.Size([1, 248, 7, 7])
BatchNorm2d output shape: torch.Size([1, 248, 7, 7])
ReLU output shape: torch.Size([1, 248, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 248, 1, 1])
Flatten output shape: torch.Size([1, 248])
Linear output shape: torch.Size([1, 10])
可以看到过渡层的存在很好的抑制了输出通道数,同样的卷积层数,FenseNet 的层数始终没有超过256。
(3)DenseNet 一个诟病的问题是内存或显存消耗过多。
a. 真的是这样吗?可以把输入形状换成 $224\times 224$,来看看实际的显存消耗。
b. 还有其他方法来减少显存消耗吗?需要改变框架么?
net2 = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)), # 最终使用全局汇聚层和全连接层输出结果
nn.Flatten(),
nn.Linear(num_channels, 10))
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# d2l.train_ch6(net2, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# 别跑,一跑显存直接爆炸
# CUDA out of memory. Tried to allocate 294.00 MiB (GPU 0; 4.00 GiB total capacity; 2.48 GiB already allocated; 109.80 MiB free; 2.61 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
(4)实现 DenseNet 论文表 1 所示的不同 DenseNet 版本。

def conv_block_121(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, 4 * input_channels, kernel_size=1), # 按原作加个BottleNeck
nn.BatchNorm2d(4 * input_channels), nn.ReLU(),
nn.Conv2d(4 * input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock_121(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock_121, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block_121(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X, Y), dim=1)
return X
b1 = nn.Sequential(
nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
num_convs_in_dense_blocks_121 = [6, 12, 23, 16]
num_channels, growth_rate = 64, 32
blks_121 = []
for i, num_convs in enumerate(num_convs_in_dense_blocks_121):
blks_121.append(DenseBlock_121(num_convs, num_channels, growth_rate))
num_channels += num_convs * growth_rate
if i != len(num_convs_in_dense_blocks_121) - 1:
blks_121.append(conv_block_121(num_channels, num_channels // 2))
num_channels = num_channels // 2
net3 = nn.Sequential(
b1, *blks_121,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 10))
lr, num_epochs, batch_size = 0.1, 10, 64
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
# d2l.train_ch6(net3, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
# 跑不了一点,batch_size都调到 64 了,还是爆显存,看看 shape 得了
# CUDA out of memory. Tried to allocate 90.00 MiB (GPU 0; 4.00 GiB total capacity; 2.49 GiB already allocated; 19.80 MiB free; 2.74 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
X = torch.rand(size=(1, 1, 224, 224)) # 好吧,看个 shape 都得 6.5 秒
for layer in net3:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
DenseBlock_121 output shape: torch.Size([1, 256, 56, 56])
Sequential output shape: torch.Size([1, 128, 56, 56])
DenseBlock_121 output shape: torch.Size([1, 512, 56, 56])
Sequential output shape: torch.Size([1, 256, 56, 56])
DenseBlock_121 output shape: torch.Size([1, 992, 56, 56])
Sequential output shape: torch.Size([1, 496, 56, 56])
DenseBlock_121 output shape: torch.Size([1, 1008, 56, 56])
BatchNorm2d output shape: torch.Size([1, 1008, 56, 56])
ReLU output shape: torch.Size([1, 1008, 56, 56])
AdaptiveAvgPool2d output shape: torch.Size([1, 1008, 1, 1])
Flatten output shape: torch.Size([1, 1008])
Linear output shape: torch.Size([1, 10])