接上篇《36、Selenium 动作交互》
上一篇我们介绍了selenium操作网页的动作内容。本篇我们来学习有关phantomjs的相关知识。
一、selenium的缺点
在介绍PhantomJS之前,让我们先讨论一下直接使用Selenium的一些缺点。
1、显示浏览器窗口:Selenium通常需要一个真实的浏览器窗口来执行测试或爬虫任务。这就意味着它会打开一个可见的浏览器窗口,这可能不是理想的选择,因为大部分同学都希望在后台运行这些自动化任务。
2、速度较慢:由于Selenium模拟了浏览器的交互行为,它可能比其他工具执行相同的任务更慢,尤其是在大规模数据爬取或测试方面。
3、内存占用高:Selenium驱动真实的浏览器窗口,因此它需要占用大量内存资源。如果你需要同时运行多个并发任务,这可能会导致内存消耗过高,影响性能。
此时,我们就需要使用“无头浏览器”来解决这些问题。那么,什么是“无头浏览器”呢?
无头浏览器就是Web浏览器在没有图形用户界面的情况下。此程序的行为与浏览器类似,但不会显示任何GUI。
无头驱动程序的一些示例包括:
● HtmlUnit
● Ghost
● PhantomJS
● ZombieJS
● Watir-WebDriver
在本篇博客,我们将先来介绍phantomjs。
二、phantomjs介绍及价值
让我们看看PhantomJS如何解决上述问题,以及为什么它具有价值的。
PhantomJS是一个基于WebKit的无界面浏览器,它可以通过命令行或脚本进行控制和操作,而无需显示实际浏览器窗口。这使得PhantomJS在以下方面具有优势:
1、无界面操作:PhantomJS在后台执行任务,没有可见窗口,这对于需要在服务器或自动化环境中运行的任务非常有用。你可以在无需人工干预的情况下执行自动化测试、网页截图、数据爬取等操作。
2、快速执行:由于PhantomJS不需要显示浏览器窗口,它通常比使用Selenium的方法更快。它可以以较高的速度加载和渲染页面,从而提高您的自动化任务的效率。
3、较低的内存消耗:相比于Selenium驱动实际浏览器窗口,PhantomJS通常需要更少的内存资源。这使得它在需要同时处理多个任务或大规模数据爬取时更具优势。
综上所述,PhantomJS通过提供无界面浏览器的功能,解决了Selenium直接使用的一些缺点。它能够在后台执行任务,加快执行速度,并且占用较少的内存资源。这使得PhantomJS成为一个强大的工具,适用于自动化测试、网络爬虫、屏幕截图等各种应用场景。
这样看来,如果我们把Selenium和PhantomJS结合在一起,就可以运行一个非常强大的网络爬虫了,这个爬虫可以处理JavaScrip、Cookie、headers,以及任何我们真实用户需要做的事情。
三、PhantomJS的工作原理
1、WebKit引擎

PhantomJS是一个基于WebKit的无界面浏览器,而WebKit是一个开源的浏览器引擎,被PhantomJS用于解析和渲染网页内容。
WebKit是一个跨平台的Web浏览器引擎,苹果的Safari、谷歌的Chrome浏览器都是基于这个框架来开发的。WebKit还支持移动设备和手机,包括iPhone和Android手机都是使用WebKit做为浏览器的核心。
WebKit负责处理HTML、CSS和JavaScript,并将它们转化为可视化的网页。它具有优秀的兼容性和高性能,是许多主流浏览器所采用的核心引擎之一。
2、页面加载和渲染流程
下面是PhantomJS利用WebKit浏览器引擎在后台进行网页加载和渲染的过程:
(1)发起网络请求
PhantomJS通过网络协议(如HTTP和HTTPS)向服务器发送请求,获取网页内容。
(2)HTML解析和DOM树构建
接收到网页内容后,PhantomJS进行HTML解析,将HTML文档转换为DOM树结构。
DOM树代表了网页的结构,每个元素都对应着DOM节点,可以通过节点进行操作和访问。
(3)样式处理和布局计算
PhantomJS处理CSS样式信息,匹配选择器与DOM节点,计算最终的样式结果。
样式信息包括字体、颜色、大小等,对页面外观和布局起着重要作用。
(4)页面渲染和资源加载
将DOM树和样式信息合成为最终的渲染结果。
渲染过程包括布局计算、绘制元素、处理图像等,将网页呈现给用户。
同时,PhantomJS会加载页面所需的资源,如图片、脚本和样式表等。
(5)JavaScript执行
PhantomJS支持JavaScript的执行,它能够对页面进行交互和动态效果的实现。
执行JavaScript代码可以触发事件、修改DOM内容等。
(6)渲染结果呈现
最终渲染结果可以在屏幕上显示给用户,也可以进行进一步处理,如截图、数据提取等操作。
四、PhantomJS的使用步骤及示例
1、安装和配置
PhantomJS官网下载地址:https://phantomjs.org/download.html
下载完毕后,解压压缩包,将文件夹放在我们python安装文件夹的下面: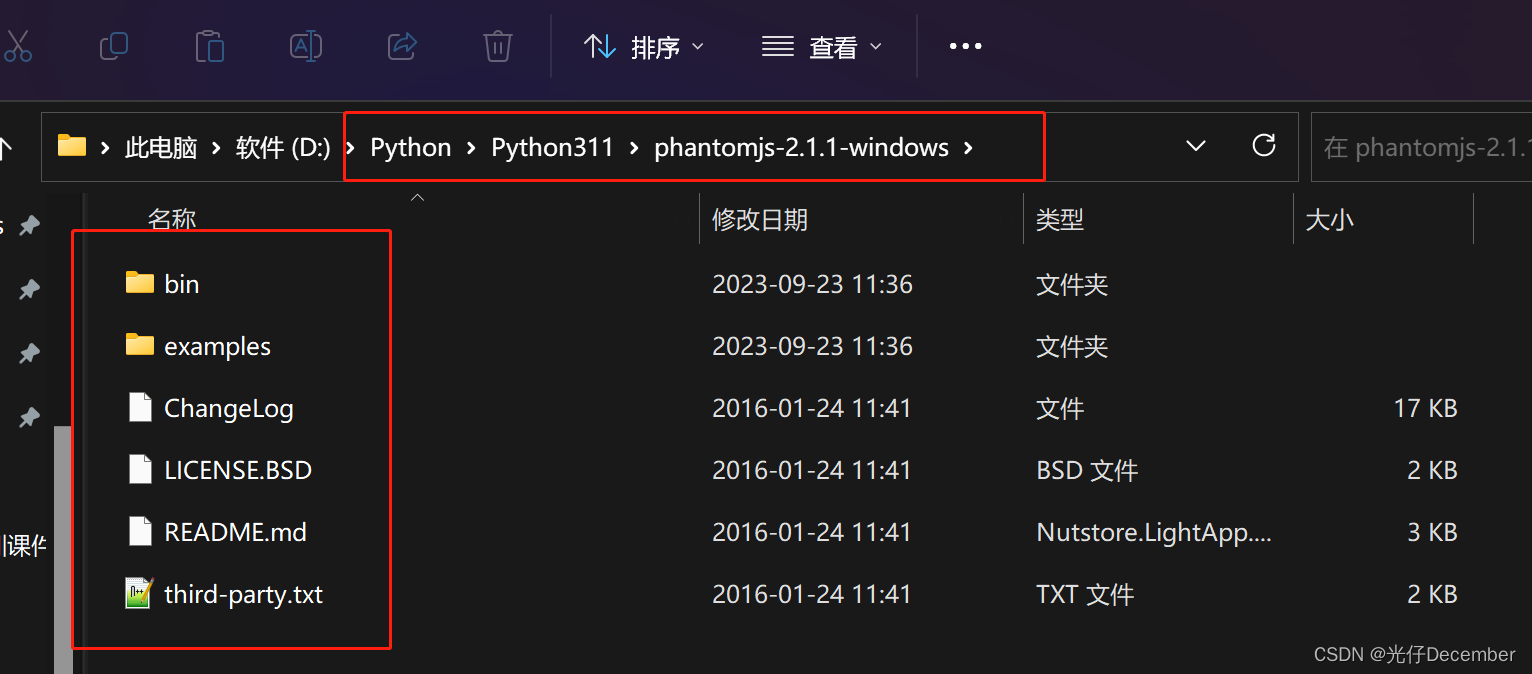
进入bin文件夹,然后复制上面的路径,桌面右击我的电脑选择属性:
点击高级环境设置:
点击环境变量:
在下面的系统变量中找到Path并双击:
点击新建,将之前复制的bin的全路径粘贴进去,依次点击确定,完成配置:
然后打开cmd,输入phantomjs,按回车如果结果为下图则安装正确:
下面我们就可以使用phantomjs了。
2、在python中测试phantomjs
编写以下代码,使用PhantomJS浏览器打开百度:
# _*_ coding : utf-8 _*_
# @Time : 2023-09-23 11:45
# @Author : 光仔December
# @File : PhantomJS样例
# @Project : Python_Projects
from selenium import webdriver
browser = webdriver.PhantomJS() # 初始化浏览器
# 发送请求
browser.get('https://www.baidu.com/')
print(browser.title) # 打印页面的标题
# 退出模拟浏览器
browser.quit() # 一定要退出!不退出会有残留进程能够正常显示百度的标题,证明环境安装成功:
这里注意,新版的selenium已经放弃PhantomJS(两家分手了,官方推荐我们用Chrome或Firefox的无头版本来替代),所以可能会出现下面的报错:
AttributeError: module 'selenium.webdriver' has no attribute 'PhantomJS'
这里如果我们想要测试,需要把selenium版本降低(一般是2.48.0)。
通过pip show selenium显示当前的默认安装版本(我是4.12.0,先降级吧= =)。
先执行删除新版本
pip uninstall selenium再安装指定版本
pip install selenium==2.48.03、使用phantomjs的步骤
(1)首先,确保你已经安装了Selenium和PhantomJS,并将它们添加到你的项目中。
(2)导入相应的包:
from selenium import webdriver(3)创建一个PhantomJS的WebDriver实例:
driver = webdriver.PhantomJS()(4)使用WebDriver打开网页:
driver.get("http://example.com")(5)进行其他的操作,比如查找元素、点击按钮等:
element = driver.find_element_by_id("my-element")
element.click()(6)最后,记得关闭WebDriver:
driver.quit()这些代码将创建一个PhantomJS的WebDriver实例,并通过该实例控制浏览器行为。大家可以根据自己的需求,在代码中添加更多的操作和逻辑。请注意,从Selenium 4开始,PhantomJS被废弃了,建议使用基于Chrome的Headless模式代替。
4、实例
我们通过selenium操作PhantomJS模拟浏览器行为,百度搜索“我要学python”,获取第一个非广告的搜索结果,打印其标题和链接地址:
代码如下:
# _*_ coding : utf-8 _*_
# @Time : 2023-09-23 11:45
# @Author : 光仔December
# @File : PhantomJS样例
# @Project : Python_Projects
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.PhantomJS() # 初始化浏览器
# 发送请求
browser.get('https://www.baidu.com/')
print(browser.title) # 打印页面的标题
# (1)通过ID定位百度搜索的按钮
element1 = browser.find_element(By.ID, "su")
# (2)通过名称定位元素(百度的搜索输入框)
element2 = browser.find_element(By.NAME, "wd")
# 给输入框输入字符串“我要学python”
element2.send_keys("我要学python")
element1.click() # 点击搜索
# 使用浏览器隐式等待3秒
browser.implicitly_wait(3)
resultObj = browser.find_element(By.XPATH, "//div[@id=\"content_left\"]//div[@id=\"1\"]")
url = resultObj.get_attribute("mu")
aObj = resultObj.find_element(By.TAG_NAME, "a")
text = aObj.text
# 获取
print("搜索‘我要学python’的第一个非广告结果:")
print("结果标题:", text)
print("地址链接:", url)
# 退出模拟浏览器
browser.quit() # 一定要退出!不退出会有残留进程效果:
PS:搞完了,我赶紧把selenium升级回4.12.0版本,以免影响后面新技术的学习= =。
由于selenium已经放弃PhantomJS,下一篇我们使用Chrome的无头版本来代替,学习Chrome的Handless无头浏览器的使用。
参考:尚硅谷Python爬虫教程小白零基础速通教学视频
转载请注明出处:https://guangzai.blog.csdn.net/article/details/133203375