1- 学习目标
- ELK基本概念,特点
- 安装部署 Kibana + ES集群 + Logstash + Filebeat + Kafka集群
- 性能瓶颈以及优化
- QA汇总
2- 介绍
2.1- 基本概念
- Elasticsearch
分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
- Logstash
数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置;
- Kibana
数据分析和可视化平台。通常与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
- Filebeat
ELK 协议栈的新成员,一个轻量级开源日志文件数据搜集器,基于 Logstash-Forwarder 源代码开发,是对它的替代。在需要采集日志数据的 server 上安装 Filebeat,并指定日志目录或日志文件后,Filebeat 就能读取数据,迅速发送到 Logstash 进行解析,亦或直接发送到 Elasticsearch 进行集中式存储和分析。
filebeat是Beats中的一员。Beats在是一个轻量级日志采集器,其实Beats家族有6个成员,早期的ELK架构中使用Logstash收集、解析日志,但是Logstash对内存、cpu、io等资源消耗比较高。相比Logstash,Beats所占系统的CPU和内存几乎可以忽略不计。
目前Beats包含六种工具:
Packetbeat:网络数据(收集网络流量数据)
Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据)
Filebeat:日志文件(收集文件数据)
Winlogbeat:windows事件日志(收集Windows事件日志数据)
Auditbeat:审计数据(收集审计日志)
Heartbeat:运行时间监控(收集系统运行时的数据)
- Kafka
数据缓冲队列。作为消息队列解耦了处理过程,同时提高了可扩展性。具有峰值处理能力,使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃
- 常用架构及使用场景介绍
2.2- 特点
3- 安装部署
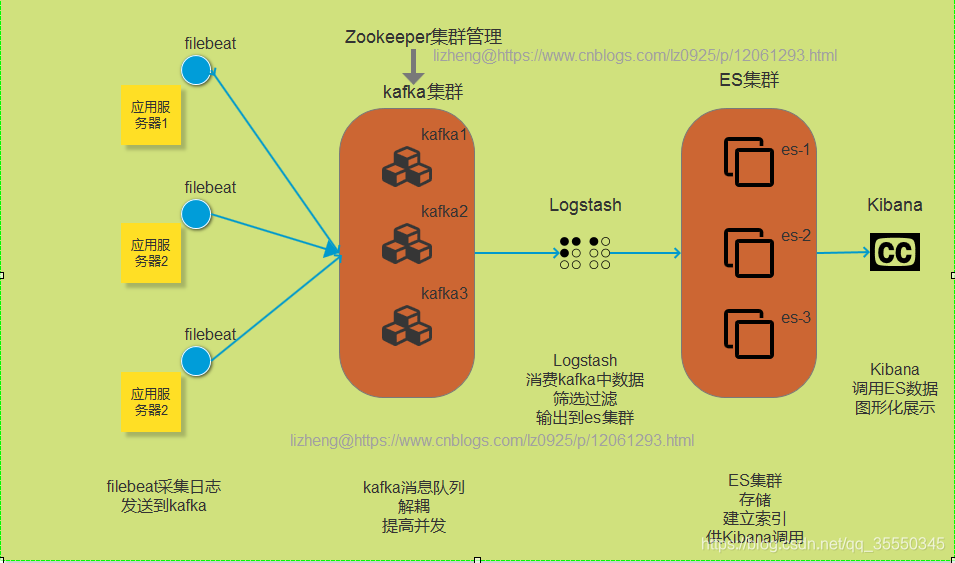
3.0- 准备工作
- 安装java1.8环境
- 实验环境介绍
db 172.16.212.11: kibana,filebeat,httpd
test1 172.16.212.21: kafka,zk,es
test2 172.16.212.22: kafka,zk,es
test3 172.16.212.23: kafka,zk,logstash,es
3.1- test1,2,3上安装Kafka集群
安装步骤详见 https://blog.csdn.net/qq_35550345/article/details/116237584
#创建topic
bin/kafka-topics.sh --create --zookeeper 172.16.212.21:2181 --topic httpd --partitions 3 --replication-factor 1
bin/kafka-topics.sh --create --zookeeper 172.16.212.21:2181 --topic test --partitions 3 --replication-factor 1
3.2- test1,2,3上安装ES集群
- 1)安装并设置开机自启
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.13.0-x86_64.rpm
yum localinstall elasticsearch-7.13.0-x86_64.rpm -y
systemctl enable elasticsearch.service
- 2)修改配置并启动
#1. 修改系统配置
vim /etc/security/limits.conf
#末尾添加
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
echo "vm.max_map_count=262144" >> /etc/sysctl.conf
sysctl -p
#2. 修改主要配置
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-es #集群名称,自定义
node.name: node-3 #当前节点的名字,可以与主机名不同
path.data: /var/lib/elasticsearch #数据存储位置
path.logs: /var/log/elasticsearch #日志存储位置
network.host: 172.16.212.23 #绑定监听IP,对外服务port默认为9200
discovery.seed_hosts: ["172.16.212.21", "172.16.212.22", "172.16.212.23"] #写入候选主节点的设备地址,在开启服务后可以被选为主节点
cluster.initial_master_nodes: ["node-1", "node-2", "node-3"] #写入候选主节点的设备地址,在开启服务后可以被选为主节点
#3. 修改jvm配置
vim /etc/elasticsearch/jvm.options
##分配系统一半的内存,但最大最好不要超过32G
-Xms1g
-Xmx1g
##GC configuration
##-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
#4. 修改日志配置
vim /etc/elasticsearch/log4j2.properties
#启动es
systemctl start elasticsearch.service
- 3)检查集群运行情况
#查看当前节点信息
curl http://172.16.212.23:9200
{
"name" : "node-3",
"cluster_name" : "my-es",
"cluster_uuid" : "X5b3K0jBRLO-1cnghQ5UTg",
"version" : {
"number" : "7.13.0",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "5ca8591c6fcdb1260ce95b08a8e023559635c6f3",
"build_date" : "2021-05-19T22:22:26.081971330Z",
"build_snapshot" : false,
"lucene_version" : "8.8.2",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
#查看集群节点状态
curl http://172.16.212.23:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.16.212.21 27 94 1 0.00 0.03 0.05 cdfhilmrstw * node-1
172.16.212.23 48 94 1 0.08 0.12 0.10 cdfhilmrstw - node-3
172.16.212.22 28 93 1 0.08 0.03 0.05 cdfhilmrstw - node-2
#查看集群状态
curl http://172.16.212.23:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1622515553 02:45:53 my-es green 3 3 0 0 0 0 0 0 - 100.0%
#查看集群index状态
curl http://172.16.212.23:9200/_cat/indices?v
# 查看指定索引信息
curl "http://172.16.212.23:9200/_cluster/health/index_name?pretty"
curl "http://172.16.212.23:9200/_cluster/health/index_name,index_name2?pretty"
3.3- test3上安装Logstash
- 1)安装并设置开机自启
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.13.0-x86_64.rpm
yum localinstall logstash-7.13.0-x86_64.rpm
systemctl enable logstash
- 2)修改配置并启动logstash
vim /etc/logstash/conf.d/logstash.conf
input {
kafka {
bootstrap_servers => "172.16.212.21:9092,172.16.212.22:9092,172.16.212.23:9092"
topics => ["test", "httpd"]
}
}
filter {
json {
source => "message"
}
grok {
match => ["message", "%{TIMESTAMP_ISO8601:logdate}"]
}
date {
match => ["logdate", "yyyy-MM-dd HH:mm:ss.SSS"]
target => "@timestamp"
locale => "ch"
timezone => "Asia/Shanghai"
}
ruby {
code => "require 'time'
event.set('datetime', Time.now.strftime('%Y%m%d'))"
}
}
output {
file {
path => "/opt/logs/logstash/%{[fields][service]}/%{[host][name]}-%{datetime}.log"
codec => line { format => '%{message}' }
}
elasticsearch {
hosts => ["172.16.212.21:9200", "172.16.212.22:9200", "172.16.212.23:9200"]
index => "%{[fields][service]}-%{[host][name]}-%{+YYYY.MM.dd}"
}
}
#启动
systemctl start logstash
- 3)检查logstash运行情况
systemctl status logstash.service
3.4- db上安装Kibana
- 1)安装并设置开机自启
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.13.0-x86_64.rpm
yum localinstall -y kibana-7.13.0-x86_64.rpm
systemctl enable kibana
- 2)修改配置并启动kibana
vim /etc/kibana/kibana.yml
server.host: "172.16.212.11"
elasticsearch.hosts: ["http://172.16.212.21:9200", "http://172.16.212.22:9200", "http://172.16.212.23:9200"]
i18n.locale: "zh-CN"
systemctl start kibana
- 3)检查kibana运行情况
systemctl status kibana
浏览器访问:http://172.16.212.11:5601
3.5- db上安装Filebeat
- 1)安装并设置开机自启
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.13.0-x86_64.rpm
yum localinstall -y filebeat-7.13.0-x86_64.rpm
systemctl enable filebeat
- 2)修改配置并启动filebeat
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/httpd/access_log
fields:
service: httpd
topic: httpd
multiline:
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
tail_files: true
- type: log
enabled: true
paths:
- /var/log/messages
fields:
service: messages
topic: test
multiline:
pattern: '^[0-9]{4}-[0-9]{2}-[0-9]{2}'
negate: true
match: after
tail_files: true
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
filebeat.config.inputs:
enabled: true
path: ${path.config}/inputs.d/*.yml
output.kafka:
hosts: ["172.16.212.21:9092","172.16.212.22:9092","172.16.212.23:9092"]
topic: '%{[fields.topic]}'
key: '%{[beat.hostname]}'
systemctl start filebeat
- 3)检查filebeat运行情况
systemctl status filebeat
3.6-验证日志收集情况
- 1)安装并启动httpd
yum -y install httpd
systemctl start httpd
systemctl status httpd
#浏览器访问 http://172.16.212.11,多访问几次,httpd的log日志会增加
ll /var/log/httpd
- 2)查看日志收集情况





![[ 数据结构 -- 手撕排序算法第七篇 ] 归并排序](https://img-blog.csdnimg.cn/c0621bb74ad3488b8cb8ac9b0a8d9311.png)