并行处理器:从客户端到云
任务级并行或进程级并行:通过同时运行独立的多个程序来使用多处理器
并行处理程序:同时在多个处理器上运行的单个程序
通过增加硬件的方式,将取指令和指令译码实现并行,一次性取出多条指令,然后分发给多个并行的指令译码器,进行译码,然后对应交给不同的功能单元去处理。这样,在一个时钟周期里,能够完成的指令就不只一条了。这种 CPU 设计,叫作多发射(Mulitple Issue)和超标量(Superscalar)。
多发射是指将多条指令同时发射到不同的译码器或者后续处理流水线中。
超标量的CPU里面有很多并行的流水线,而不是单一一条。
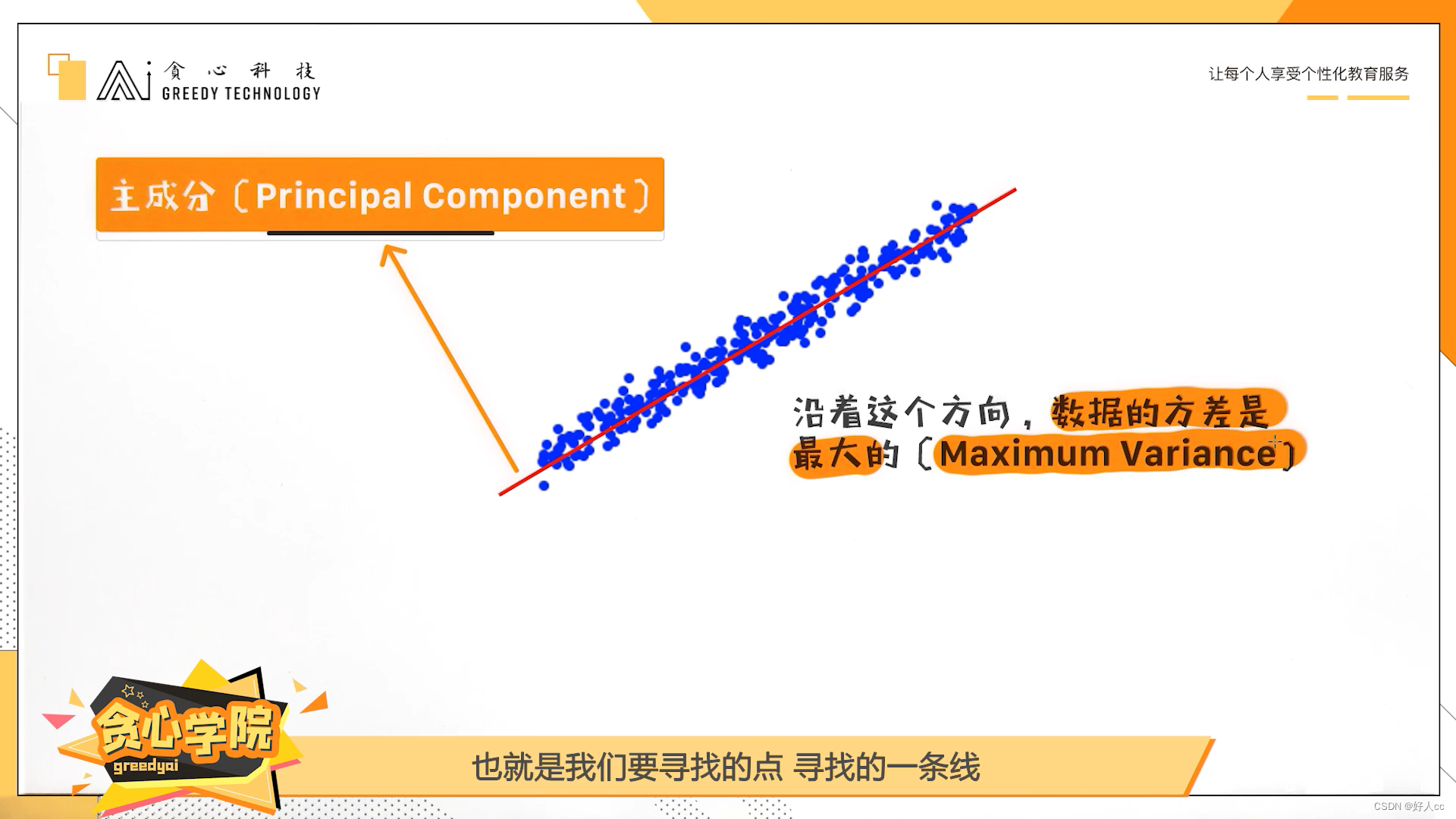
向量和标量
向量指令的重要属性:
- 单个向量指令指定了大量工作--相当于执行了完整的循环。正因为这样,指令取指和译码带宽大大减少
- 通过使用向量指令,编译器或程序员确认了向量中的每个结果都是独立的,因此硬件无需再检查向量指令内的数据冒险
- 当程序中存在数据级并行时,相比使用MMD多处理器,使用向量体系结构和编译器的组合更容易写出高效的应用程序
- 硬件只需要在两条向量指令之间检查向量操作数之间的数据冒险,而无须检查向量中的每个数据元,减少检查的次数可以节省能耗和时间
- 访问存储器的向量指令具有确定的访问模式。如果向量中的数据元位置都是连续的,则可以从一组存储器中交叉访问数据块,从而快速获取向量。因此,对整个向量而言,主存储器的延迟开销看上去只有一次,而不是对向量中每一个字都产生一次
- 因为整个循环被具有已知行为的向量指令所取代,所以通常由循环引发的控制冒险不再存在
- 与标量体系结构相比,节省的指令带宽和冒险检查以及对存储器带宽的有效利用,使得向量体系结构在功耗和能耗方面更具有优势
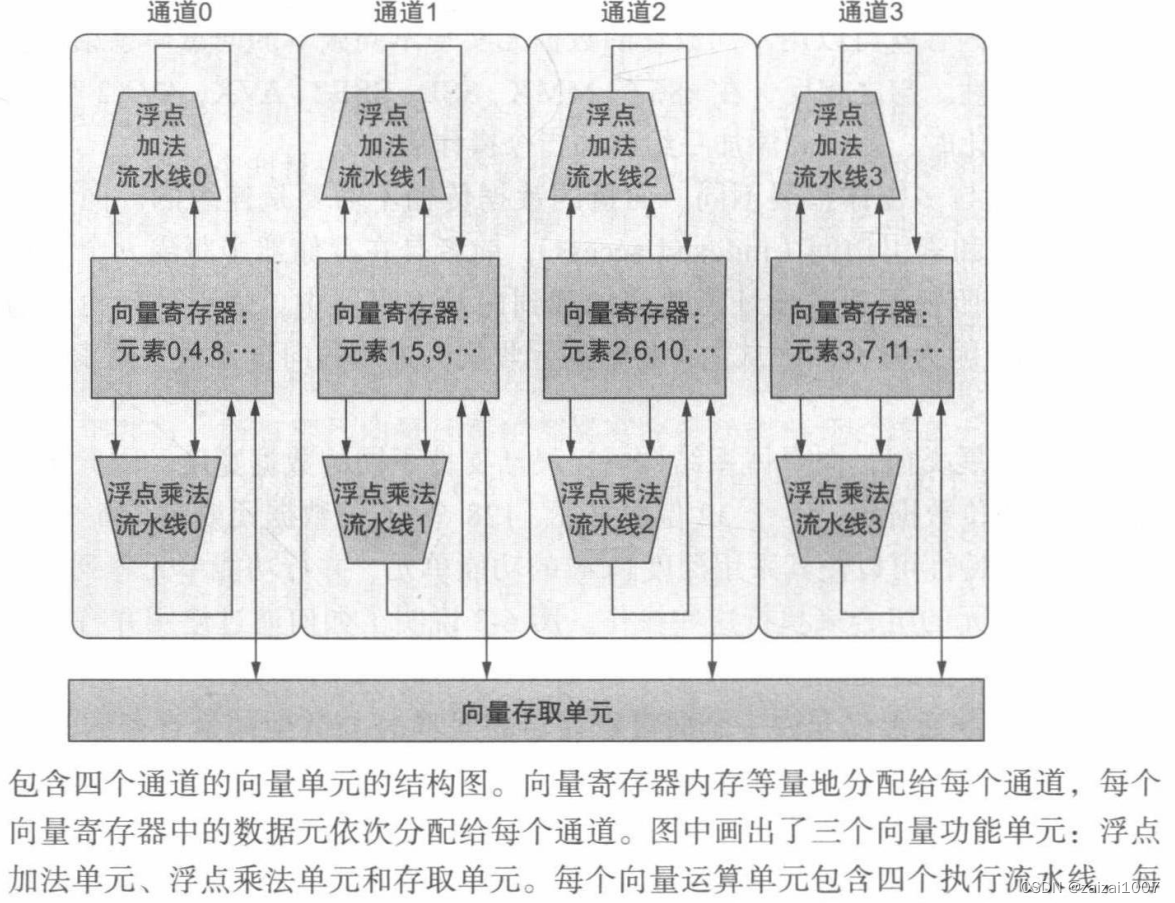
向量算术指令通常允许一个向量寄存器的元素N与其他向量寄存器的元素N进行交互。这极大地简化了高度并行的向量单元的构造--可构造为多个平行的向量通道
向量通道:一个或多个向量功能单元和一部分向量寄存器堆

硬件多线程
线程:包括程序计数器,寄存器状态和栈。线程是一个轻量级的进程,线程通常共享一个地址空间,而进程则不共享
进程:包括一个或多个线程,完整的地址空间和操作系统状态。因此,进程的切换通常需要调用操作系统,而线程切换则不用
硬件多线程:通过在一个线程停顿时切换到另一个线程来提高处理器的利用率
硬件多线程允许多个线程以重叠的方式共享单个处理器的功能单元,以有效地利用硬件资源
细粒度多线程:硬件多线程的一种版本,在每条指令之后切换线程
在每条指令执行后进行线程切换,导致了多线程的交叉执行。这种交叉执行通常以一种轮转方式完成,并跳过在该时钟周期停顿的任何线程。细粒度多线程的一个有点就是可以隐藏由短期和长期停顿引起的吞吐量损失,主要缺点是会减慢单个线程的执行速度,因为已经就绪的线程会因为执行其他线程的指令而延迟
粗粒度线程:硬件多线程的另一种版本,仅在重大事件(例如末级cache失效)之后才切换线程
几乎不会减慢单个线程的执行速度,因为只有在线程遇到高开销的停顿时才会发射来自其他线程的指令。但是有个严重缺点:降低吞吐量损失的能力有限,尤其对于短停顿
同时多线程:多线程的一个版本,通过利用多发射,动态调度的微体系结构的资源来降低多线程的成本
因为SMT依赖于现有的动态机制,因此它不会在每个时钟周期切换资源,相反,SMT始终执行来自多个线程的指令,将资源分配交给硬件完成,这些资源是指令槽和重命名寄存器
同时多线程:多线程的一个版本,通过利用多发射,动态调度的微体系结构的资源来降低多线程的成本


共享内存多处理器(SMP):为所有处理器提供统一物理地址空间
处理器通过存储器中的共享变量进行通信,所有处理器能够通过加载和存储指令访问任意存储器位置
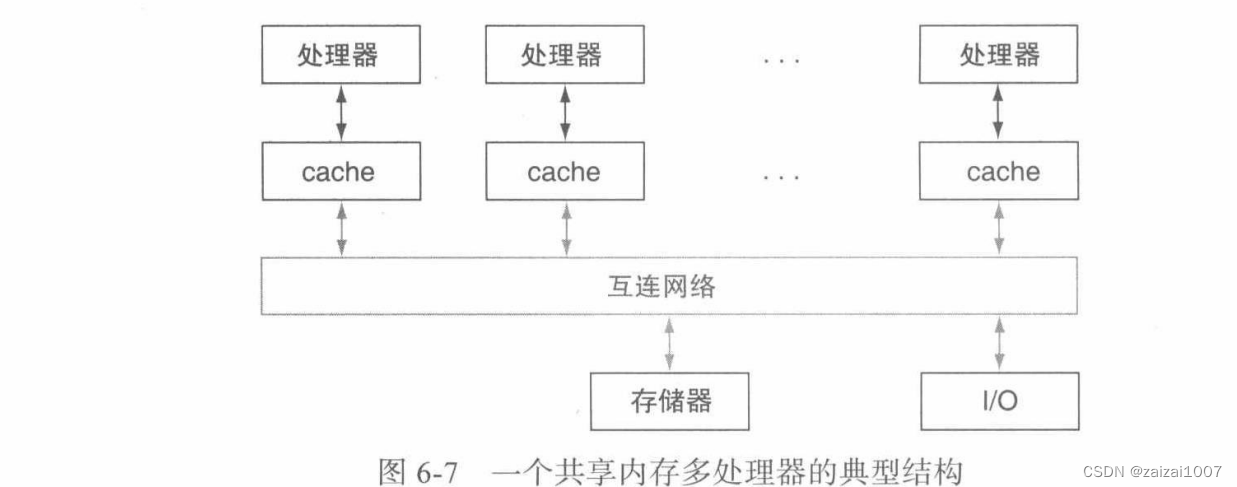
统一内存访问:一种多处理器,无论哪个处理器访问存储器,存储器的访问延迟都大致相同
非统一内存访问:一种单地址空间多处理器,存储器的访问延迟各不相同,具体取绝与哪个处理器访问哪个存储
同步:协调两个或多个进程行为的过程,这些进程可能在不同的处理器上运行
GPU简介--图形处理单元(Graphics Processing Unit)
GPU区别于CPU的关键特性:
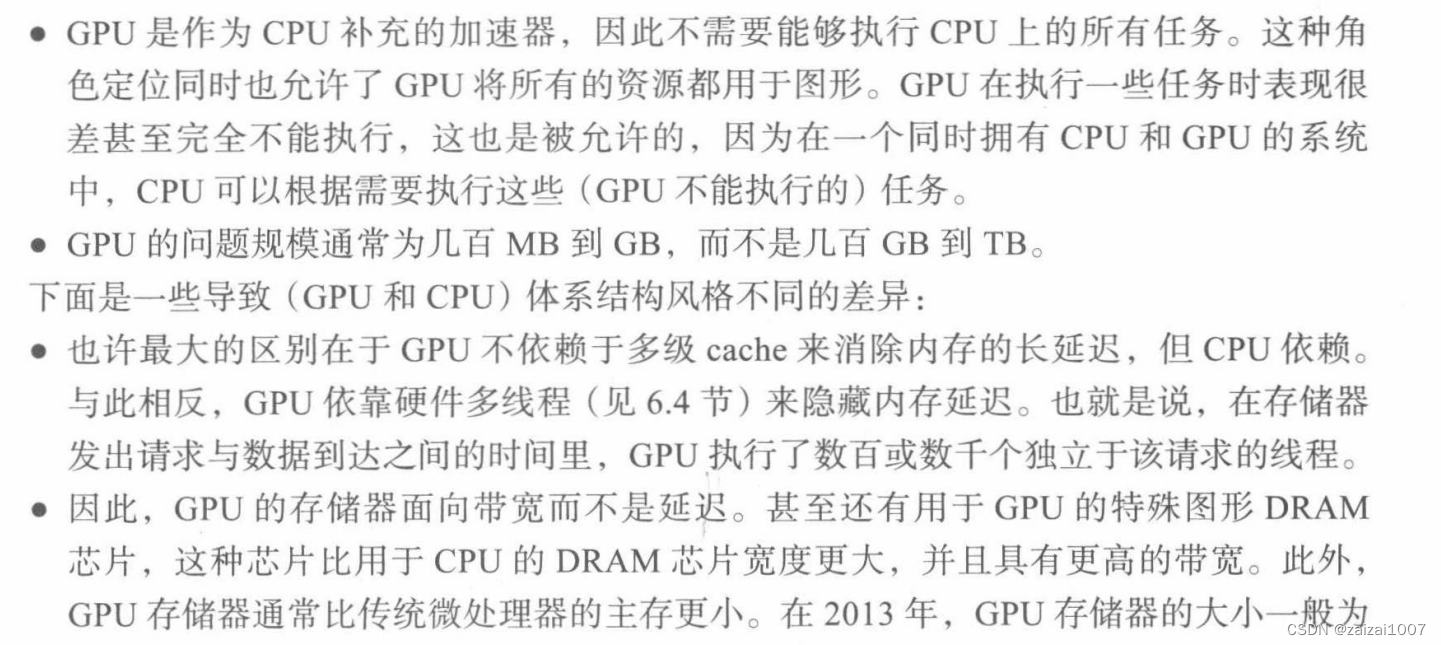

GPU依赖单个多线程SIMD处理器中的硬件多线程来隐藏存储器延迟
GPU中包含一个多线程SIMD(Single Instruction,Multiple Threads)处理器的集合,也就是说,GPU是由多线程SIMD处理器组成的MIMD(Multiple Instruction,Multiple Threads)

好文推荐:计算机组成原理 - 标签 - 庞某人 - 博客园 (cnblogs.com)
![[RF学习记录][ssh library][execute Command】关键字的返回值](https://img-blog.csdnimg.cn/72a23bafb56e49ebb956c7bf20bf051b.png)