准备工作(建表、插入数据)
1、建立表格:学生-学习科目表student_study
注意:科目kemu列内容是字典码,需要更换成对应内容。
CREATE TABLE "TEST"."STUDENT_STUDY"
(
"NAME" VARCHAR(255),
"KEMU" VARCHAR(255)) STORAGE(ON "MAIN", CLUSTERBTR) ;
COMMENT ON COLUMN "TEST"."STUDENT_STUDY"."NAME" IS '姓名';
COMMENT ON COLUMN "TEST"."STUDENT_STUDY"."KEMU" IS '科目,内容是字典码,以英文逗号分隔';
INSERT INTO TEST.STUDENT_STUDY VALUES('张三','@1,@2'),('李四','@1,@3'),('王五','@1,@2,@3');

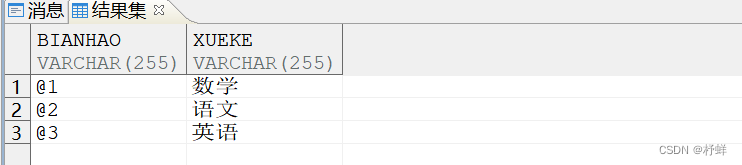
2、建立表格:编号-学科对应表格xueke
注意:这张表是字典码编号和科目xueke的对应关系表。
CREATE TABLE "TEST"."XUEKE"
(
"BIANHAO" VARCHAR(255),
"XUEKE" VARCHAR(255)) STORAGE(ON "MAIN", CLUSTERBTR) ;
COMMENT ON COLUMN "TEST"."XUEKE"."BIANHAO" IS '字典码编号';
COMMENT ON COLUMN "TEST"."XUEKE"."XUEKE" IS '学科名称';
INSERT INTO TEST.XUEKE VALUES('@1','数学'),('@2','语文'),('@3','英语');
自定义存储函数
-- 所有函数及定义参考DM8_SQL语言使用手册、DM8_SQL程序设计(在DM安装目录/doc/下)
CREATE OR REPLACE FUNCTION get_code_meaning(codes IN VARCHAR(200)) RETURN VARCHAR(200)
AS
i INT DEFAULT 1;-- 或者 i INT := 1
max_i INT;
code VARCHAR(100);
meaning VARCHAR(100);
result_type VARCHAR(200);
BEGIN
-- 去除前后多余的逗号,LEADING去除左边(或使用LTRIM()函数),TRAILING去除右边(或使用RTRIM()函数),BOTH去除两端(默认是BOTH)
codes := TRIM(BOTH ',' FROM codes);
-- 获取字符串内码值个数
max_i := LENGTH(codes) - LENGTH(REPLACE(codes, ',', '')) + 1;
WHILE i<=max_i LOOP
-- 取出每个元素,以','进行分割
code := SUBSTRING_INDEX(SUBSTRING_INDEX(codes, ',', i), ',', -1);
-- 在这里查询代码表获取每个代码的含义,并赋值给meaning变量
-- 此处根据WHERE条件查询的结果必须是一行记录,否则报错 ;多行记录需使用`TOP 1`或者`LIMIT 1`进行处理
SELECT XUEKE INTO meaning FROM TEST.XUEKE WHERE BIANHAO = code;
IF result_type IS NOT NULL THEN
result_type := CONCAT_WS(',',result_type,meaning);
ELSE
result_type := meaning;
END IF;
i := i+1;
END LOOP;
RETURN result_type;
END;
查询出多个字典码对应的内容
SELECT NAME,KEMU,get_code_meaning(KEMU) FROM TEST.STUDENT_STUDY;

替换多个字典码对应的内容
UPDATE TEST.STUDENT_STUDY SET KEMU=get_code_meaning(KEMU);
表里科目列字典项数据已经替换成对应内容:

参考SQL Server更新某一列中多个字典码对应内容(sql示例),该博主给出的是SQL Server的方法,因业务需求,本人自行更改为DM数据库的可行方法。