一、前言
关于搜索引擎自己接触的还算是比较多的,先简单回忆一下以前做过的事情,以前工作没有什么文档沉淀下来很多事情几乎都快忘差不多了,挺遗憾的。
1、10几年前在东奇软件做企业网站时玩过Lucene,当时中文分词还很弱,很多词搜不出来,印象中当时好像是给中国银行做企业网站,然后我的技术被银行的人鄙视,不过银行技术部门的人虽然会做银行的信息系统,但用的是C或Dephi,还不会JSP根本不会做网站,哈哈。
2、在阿里接触过三套搜索引擎,做淘宝教育对接VSearch,做分类信息对接淘宝主搜,另外还请淘宝终搜团队给我们小组做技术架构分享,VSearch和终搜都是基于Lucene和Solr搭建的,做了一些扩展,提供框架支持全量和增量数据的导入,Vsearch是为当时淘宝垂直市场战略服务的,因为对接主搜周期特别长而且很多个性化需求都不能满足,而终搜是另外一个团队开发的一个竟品,终搜字面意思就是统一掉所有搜索,当时两个组打得挺厉害,然后主搜是基于C语言开发的,最初的架构应该是来源于Yahoo,一淘和淘宝列表页(这个印象中叫Hasper系统什么来着)搜索都是主搜搭建的。
3、在牛邦做股票软件时,新股数据的查询由ElasticSearch提供,我当时负责写Python爬虫到几个网站去爬新股数据并导入ElasticSearch,领导负责搭建ElasticSearch及提供服务接口。
4、在现在公司做牛奶业务时,曾经让一个同事搭建ES,主要是解决配送单变更日志查询,但后来该业务一直没有起色搭好后最终没有进行切换。
5、窗帘系统正在搭建ES去解决一些实际中碰到的问题,比如每天的库存价值报告快照,实时库存报告导出,各种报表、现在完全依赖于数据库,突发负载还是比较高,另外一些实时数据查询导出需求使用数据库很难满足。
二、MySQL VS ElasticSearch
用ES一般做法是把MySQL里存储的数据同步一份到ES,然后用ES来做海量数据的实时查询,解决模糊搜索仅是一个小特性。
1、关系数据库存储结构化业务数据,更多是为了满足业务流程而进行设计,如果太过于考虑满足查询进行设计,整个结构会比较混乱会有很多冗余,而ES天生就是为了解决查询的,可以把多张表数据合并成一个Schema(或者叫类型),这样就可以解决掉很多耗性能的多表关联查询。
2、MySQL用事务特性来保证不会产生脏数据,而ES对事务方面并无什么支持,所以一般还是要用MySQL来存储原始数据。
3、MySQL做海量数据查询需要做分库分表,但最终你的查询还是会落在某个库的某张表中,而ES是天生的分布式架构,数据进行分片存储,在查询时一个节点A收到请求会将其转发给它数据节点,其它数据节点在本机查询将结果ID返回节点A,然后由节点A对所有结果进行排序分页,然后再去各个数据节点根据ID查原始数据返回给用户。
4、即使是单片查询,ES Lucene的倒排索引也比MySQL的B+TREE快。
三、倒排索引
ES是一个基于Lucene搜索服务,它提供分布式多用户全文搜索引擎,而Lucene仅是一个全文搜索引擎工具包。
1、倒排索引是什么
倒排索引是全文检索里的概念,既然有倒排索引那肯定也有正排索引,不管正排倒排都是全文检索里的概念,MySQL数据库Innodb是B+TREE索引,和正排倒排没关系。
正排索引:通过检索全文,然后再找到词语,就是全文正排索引。
文档->单词1、单词2
单词1 出现的次数 ,单词1出现的位置;单词2出现次数,单词2出现的位置。
倒排索引:通过词语查找到全文,就是全文倒排索引
单词1--->文档1,文档2,文档3
单词2--->文档1,文档2
2、倒排索引生成例子
文章1内容:qingcai lives in Hangzhou,I live in Hangzhou too.
文章2内容:he once lived in Shangrao.
step1:取得关键字
英文单词比较简单直接空格分词,中文需要分词器,过滤掉无意义的词比如in、too等,过滤掉标点符号,然后统一大小写,还原lives和lived成live,这样通过查live可以把lives和lived一起查出来。
文章1关键词:[qingcai][live][hangzhou][i][live][hangzhou]
文章2关键词:[he][live][shangrao]
step2:建立倒索引
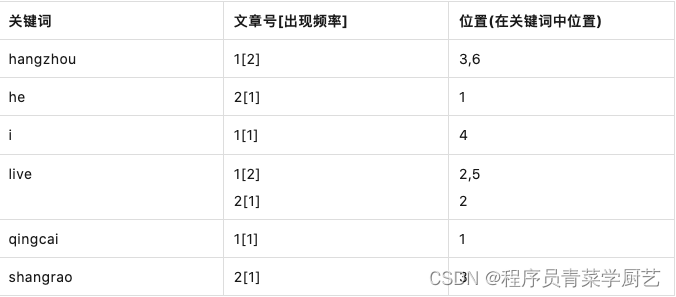
关键词是按字符顺序排列的,可以用二分搜索算法快速搜索关键词。
Lucene会将上面三列分别做为以下三个文件保存。
-
词典文件(Term Dictionary)
-
频率文件(frequencies)
-
位置文件(positions)
Term Dictionary还保存了指向另外两个文件的指针,最后Lucene还会对索引进行压缩。
3、索引查询
假如查询单词"live",Lucene通过对词典文件Term Dictionary)进行二分查找,然后通过指针读出所有的文章号,最后返回结果数据,而词典文件一般非常小,整个查询过程非常快速高效。