第一章 神经网络是如何实现的
为什么使用 ReLu 函数?
五、梯度消失问题

1. 什么是梯度消失问题?
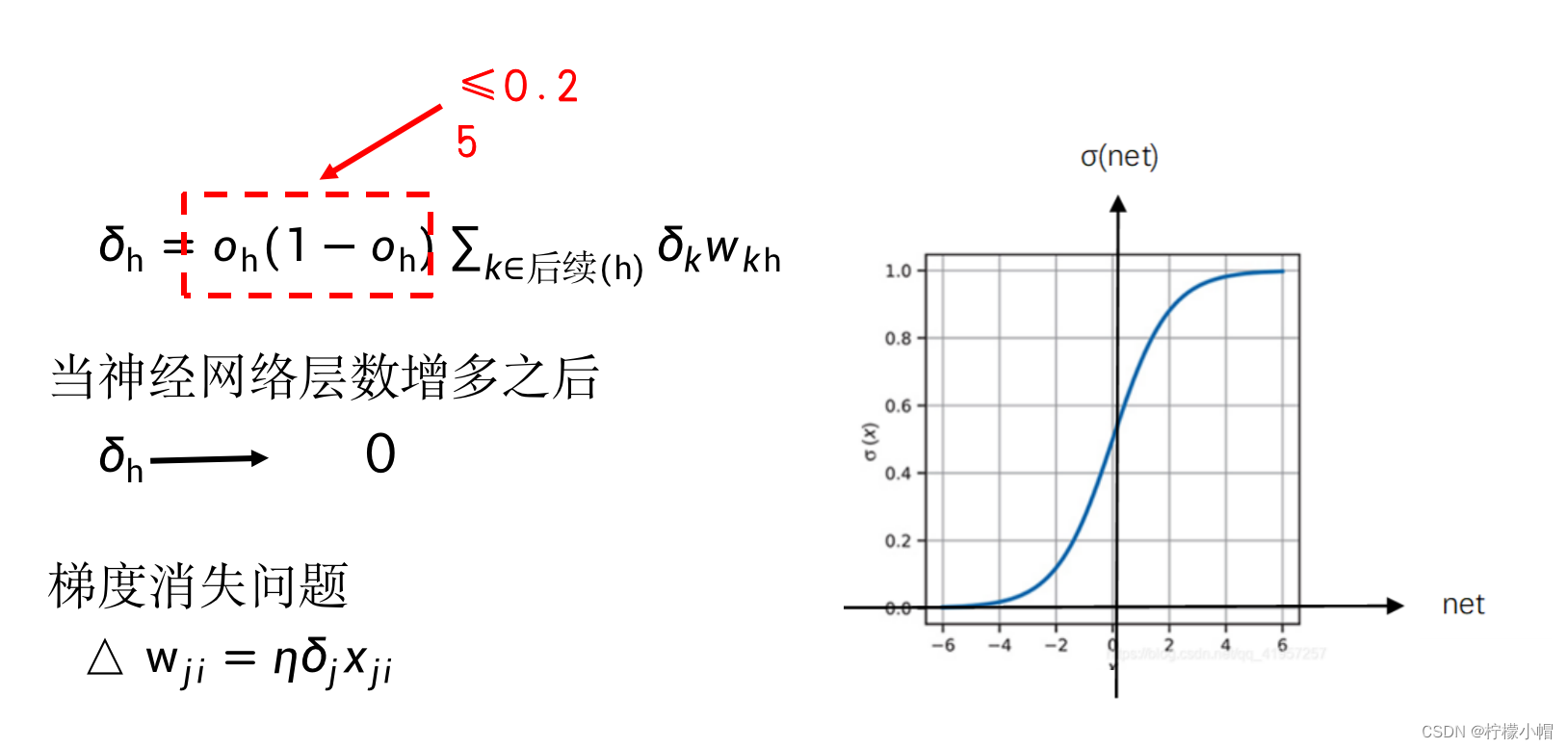
前面我们介绍的 BP 算法中,是这样更新权重值的:
δ
∗
h
=
o
h
(
1
−
o
h
)
∑
∗
k
∈
后续
(
h
)
δ
∗
k
w
∗
k
h
\delta*h = o_h(1 - o_h)\sum*{k\in 后续(h)}\delta*kw*{kh}
δ∗h=oh(1−oh)∑∗k∈后续(h)δ∗kw∗kh
Δ
w
∗
j
i
=
η
δ
j
x
∗
j
i
\Delta w*ji = \eta \delta_jx*{ji}
Δw∗ji=ηδjx∗ji
w
∗
j
i
=
w
∗
j
i
+
Δ
w
_
j
i
w*{ji} = w*{ji} + \Delta w\_{ji}
w∗ji=w∗ji+Δw_ji
BP 算法中主要是根据后一层的 δ \delta δ 值计算前一层的 δ \delta δ 值,一层一层反向传播。由 δ \delta δ 的计算公式可以看到,每次都要乘一个 o h ( 1 − o h ) o_h(1-o_h) oh(1−oh) ,其中 o h o_h oh 是神经元 h 的输出。当采用 sigmoid 激活函数时, 取值在 0、1 之间,无论 o h o_h oh 接近 1 还是接近 0, o h ( 1 − o h ) o_h(1-o_h) oh(1−oh) 的值都比较小,即便是最大值也只有 0.25(当 o h = 0.5 o_h = 0.5 oh=0.5 时)。如果神经网络的层数比较多的话,反复乘以一个比较小的数,会造成靠近输入层的 o h o_h oh 趋近于 0,从而无法对权重进行更新,失去了训练的能力。这一现象称作梯度消失。而 o h ( 1 − o h ) o_h(1-o_h) oh(1−oh) 刚好是 sigmoid 函数的导数,所以用 sigmoid 激活函数的话,很容易造成梯度消失。而如果换成 ReLU 激活函数的话,由于 ReLU(net)=max(0, net),当 net>0 时,ReLU 的导数等于 1, o h ( 1 − o h ) o_h(1-o_h) oh(1−oh)这一项就可以用 1 代替了,从而减少了梯度消失现象的发生。当然,梯度消失并不完全是激活函数造成的,为了建造更多层的神经网络,研究者也提出了其他的一些减少梯度消失现象发生的方法。
2. 解决思路

3. 两个实例

3.1 GoogleNet

- 该神经网络在 ImageNet 比赛中曾经获得第一名。
- GoogLeNet 在命名时有意将 L 大写(后边 5 个字符刚好是 LeNet),以示该网络是在 LeNet 的基础上发展而来。

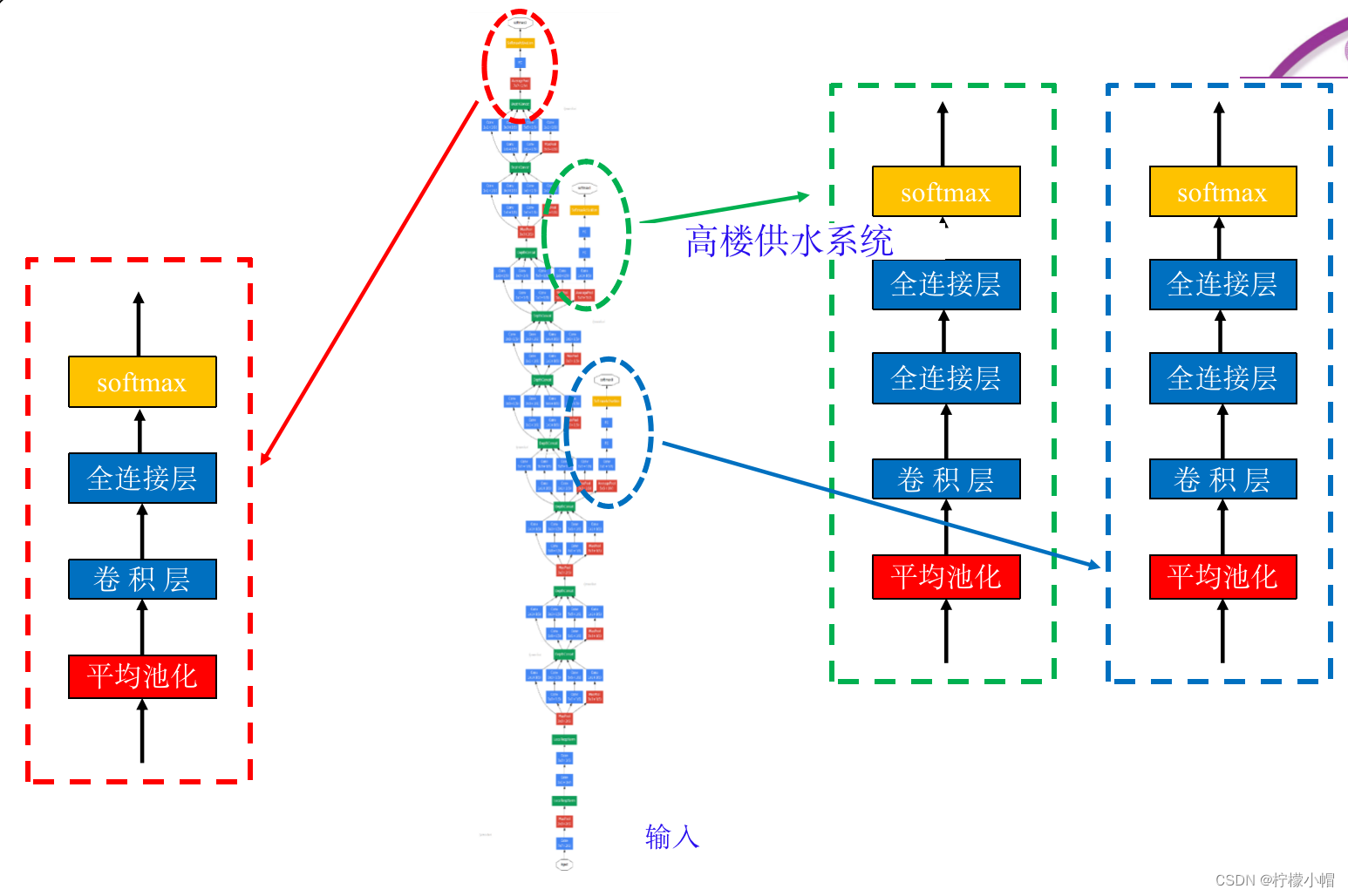
- GoogLeNet 有些复杂,其结构如图所示,输入层在最下边。该网络有两个主要特点,第一个特点与解决梯度消失问题有关。
- 不同于一般的神经网络只有一个输出层,GoogLeNet 分别在不同的深度位置设置了 3 个输出,图中用黄颜色表示,分别命名为 softmax0、softmax1 和 softmax2,从名称就可以看出,3 个输出均采用了 softmax 激活函数。对三个输出分别构造损失函数,再通过加权和整合在一起作为总体的损失函数。这样三个处于不同深度的输出,分别反向传播梯度值,同时配合使用 ReLU 激活函数,就比较好地解决了梯度消失问题。
- 三个输出中,最上边的 softmax2 是真正的输出,另外两个是辅助输出,只用于训练,训练完成后,就不再使用了。
- GoogLeNet 的第二个特点是整个网络由 9 个称作 inception 的模块组成,图中虚线框出来的部分就是第一个 inception 模块,后面还有 8 个这样的模块。

3.1.1 Inception 模块
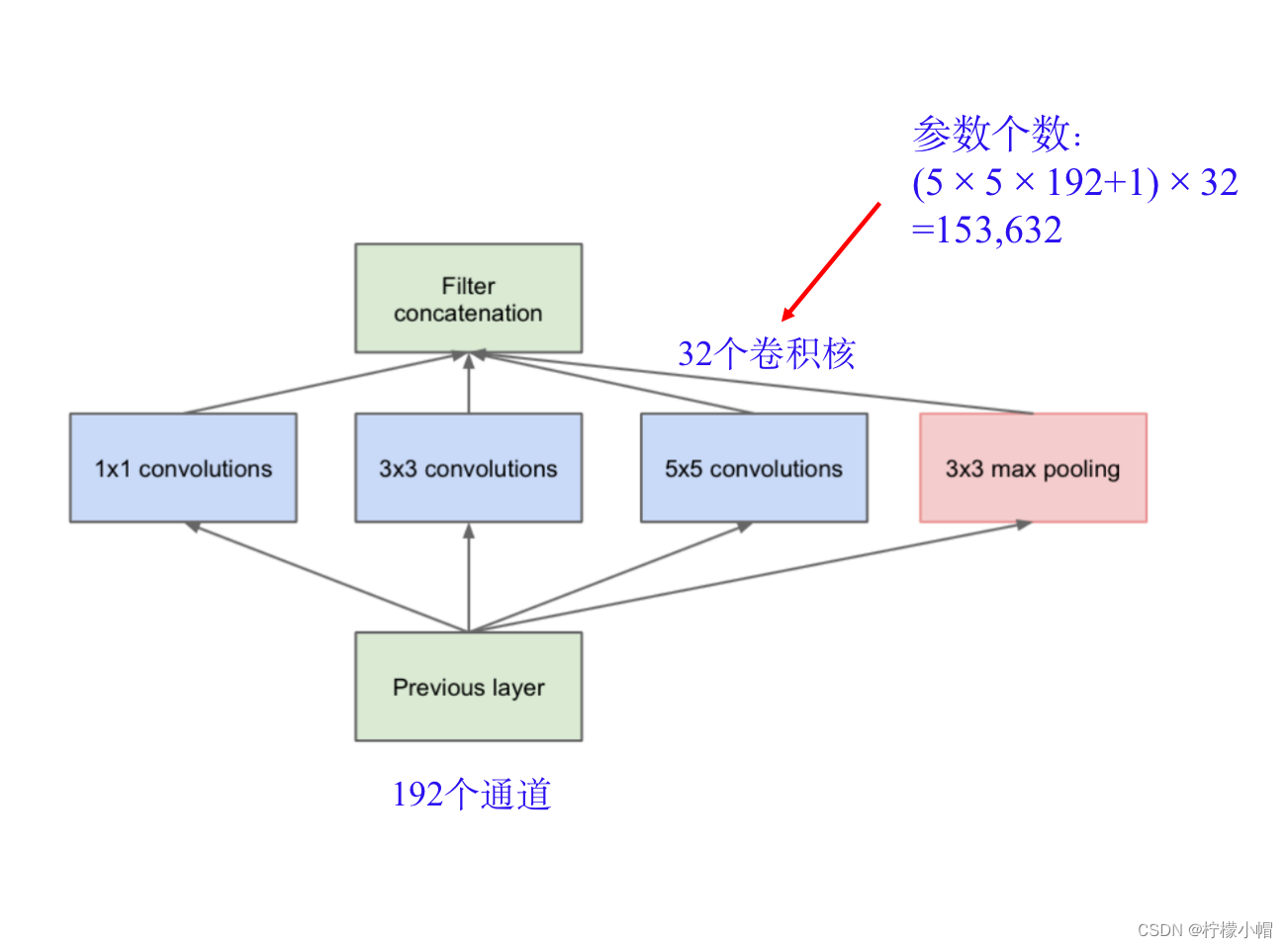
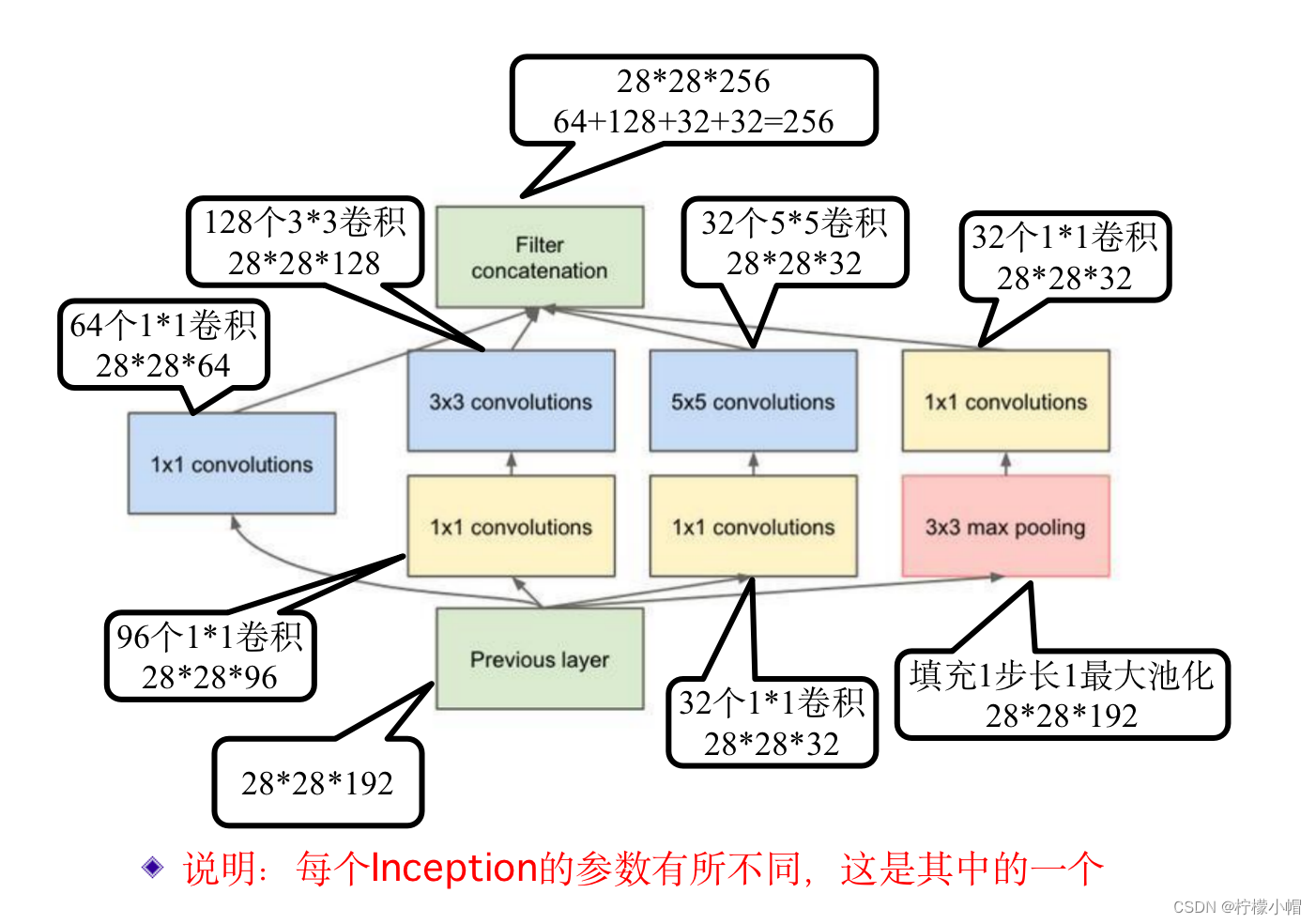
- 从最原始的 inception 讲起,如图所示的就是一个原始的 inception 模块,它由横向的 4 部分组成,从左到右分别是 1×1 卷积、3×3 卷积和 5×5 卷积,最右边还有一个 3×3 的最大池化。每种卷积都有多个卷积核,假定 1×1 卷积有 a 个卷积核,3×3 卷积有 b 个卷积核,5×5 卷积有 c 个卷积核,那么这三个卷积得到的通道数就分别为 a、b、c 个,最右边的 3×3 最大池化得到的通道数与输入一致,假设为 d。将这 4 部分得到的通道再并排在一起,则每个 inception 的输出共有 a+b+c+d 个通道。
- 不同大小的卷积核可以抽取不同粒度的特征,GoogLeNet 通过 inception 在每一层都抽取不同粒度的特征再聚合在一起,达到更充分利用不同粒度特征的目的。
3.1.2 降维的 Inception 模块
- 带降维的 inception 模块,与原始的模块相比较,主要是引入了 3 个 1×1 卷积,两个分别放在了 3×3 卷积和 5×5 卷积的前面,一个放在了最右边 3×3 最大池化的后边。

-
引入 1×1 卷积有两个作用。第一,1×1 卷积核由于还有个厚度,相当于在每个通道上的相同位置各选取一个点进行计算,每个点代表了某种模式特征,不同通道代表不同特征,所以其结果就相当于对同一位置的不同特征进行了一次特征组合。第二,就是用 1×1 卷积对输入输出的通道数做变换,减少通道数或者增多通道数,如果输出的通道数少于输入的通道数,就相当于进行降维,反之则是升维。比如输入是 100 个通道,如果用了 60 个 1×1 的卷积核,则输出具有 60 个通道,通道数减少了 40%,就实现了降维操作。在 inception 中增加的 3 个 1×1 卷积,都是为了降维的,所以这种模块被称为带降维的 inception 模块。
-
假设 inception 的输入有 192 个通道,使用 32 个 5×5 的卷积核,那么共有多少个参数呢?
- 由于输入是 192 个通道,则一个卷积核有 5×5×192+1 个参数,其中的 1 是偏置 b。一共 32 个卷积核,则全部参数共有(5×5×192+1)×32=153632 个。
-
如果在 5×5 卷积前增加一层具有 32 个卷积核的 1×1 的卷积的话,则总参数又是多少个呢?
- 1×1 卷积的输入是 192 个通道,则一个卷积核的参数个数为 1×1×192+1,共 32 个卷积核,则参数共有(1×1×192+1)×32=6176 个。1×1 的卷积输出有 32 个通道,输入到 32 个卷积核的 5×5 卷积层,这层的参数总数为(5×5×32+1)×32=25632 个。两层加在一起共有 6176+25632=31808 个参数。
-
在没有降维前参数共有 153632 个,降维后的参数量只有 31808 个,只占降维前参数量的 20%左右,可见降维的作用明显。
-
这里在最大池化后面加入 1×1 卷积层是为了降维了,因为输入的通道数可能比较多,用 1×1 卷积把通道数降下来。
3.1.3 GoogleNet 另一特点

- 在靠近输出层用了一层 7×7 的平均池化,这一层一般是个全连接层,在 GoogLeNet 中用平均池化代替了一个全连接层。由于池化是作用在单个通道上的,而每个通道抽取的是相同模式的特征,所以平均池化反映了该通道特征的平均分布情况,起到了对特征的平滑作用。据 GoogLeNet 的提出者介绍说,这样不仅减少了参数量,还可以提高性能。另外就是在第一个 inception 之前分别加入了两层局部响应归一化,在适当的地方加入归一化层是一种常用的手段,其目的是为了防止数据的分布不要产生太大的变化,因为神经网络在训练过程中每一层的参数都在更新,如果前面一层的参数分布发生了变化,那么下一层的数据分布也会随之变化,归一化的作用就是防止这种变化不要太大。除了局部响应归一化外,现在用的更多的是批量归一化。
3.1.4 Inception 词的由来
- inception 一词来源于电影《盗梦空间》的英文名,电影中有一句对话:We need to go deeper(我们需要更加深入),讲述的就是如何在某人大脑中植入思想,寓意进行更深刻的感知。
- 神经网络一直在向更深的方向发展,层数越来越多,“更加深入”也正是神经网络研究者所希望的,所以就以 inception 作为了模块名。
3.2 残差网络(ResNet)
- 原则上来说,神经网络越深其性能应该越好,假设已经有了一个 k 层的神经网络,如果在其基础上再增加一层变成 k+1 层后,由于又增加了新的学习参数,k+1 层的神经网络性能应该不会比原来 k 层的差。但是如何建造更深的网络并不是那么容易,往往简单地增加层数效果并不理想,甚至会更差。所以,我们虽然希望构建更深层的神经网络,但由于有梯度消失等问题,深层神经网络训练会更加困难。虽然有些方法可以减弱梯度消失的影响,但当网络达到一定深度后,这一问题还是会出现。实验结果表明,随着神经网络层数的增加,还会发生退化现象,当网络达到一定深度后,即便在训练集上,简单地增加网络层数,损失函数值不但不会减少,反而会增加。下图给出了这样的例子。
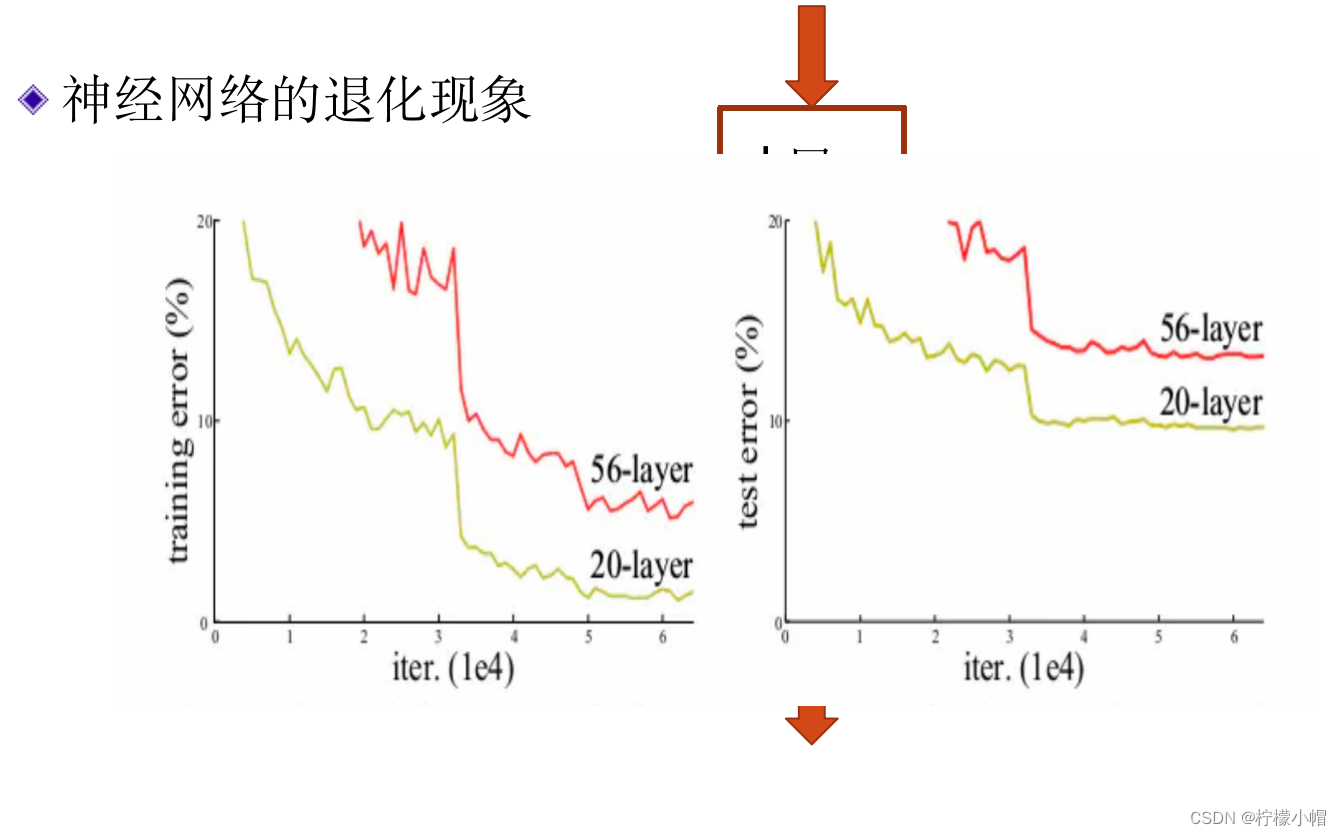
- 横坐标是训练的迭代次数,纵坐标是错误率,其中左边是在训练集上的错误率,右边是在测试集上的错误率。从图中可以看出,无论是在训练集上还是在测试集上,56 层神经网络的错误率都高于 20 层神经网络的错误率。
- 这个问题比较复杂,并不是单纯是因为梯度消失问题造成的。原因可能有很多,还有待于从理论上进行分析和解释。这个例子说明,虽然神经网络加深后原则上效果应该会更好,但是并不是简单地加深网络就可以的,必须有新的思路解决网络加深后所带来的问题。
3.2.1 解决思路
- 残差网络(ResNet)就是解决方案之一。残差网络在 GoogLeNet 之后,曾经以 3.57%的错误率获得 ImageNet 比赛的第一名,首次达到了低于人类错误率的水平。
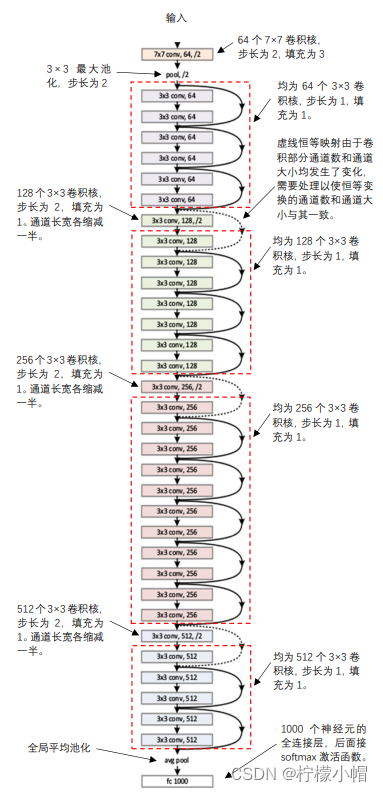
3.2.2 残差模块
- 残差网络主要由多个如图所示的残差模块堆砌而成。一个残差模块含有两个卷积层,第一层卷积后面接一个 ReLU 激活函数,第二层卷积不直接连接激活函数,其输出与一个恒等映射相加后再接 ReLU 激活函数,作为残差模块的输出。这里的恒等映射其实就是把残差模块的输入直接“引”过来,与两个卷积层的输出相加。这里的“相加”指的是“按位相加”,即对应通道、对应位置进行相加,显然这要求输入的通道数和通道的大小与两层卷积后的输出完全一致。如果残差模块的输入用 X 表示(X 表示具有一定大小的多通道输入),两层卷积输出用 F(X)表示,则残差模块的输出
F
′
(
X
)
F'(X)
F′(X)为:
F ′ ( X ) = F ( X ) + X F'(X) = F(X) + X F′(X)=F(X)+X

- 这里的恒等映射感觉像电路中“短路”一样,为什么要这样设计呢?
- 其一,通过“短路”,可以将梯度几乎无衰减地反传到任意一个残差模块,消除梯度消失带来的不利影响。其二,前面我们说过,由于存在退化现象,在一个 k 层神经网络基础上增加一层变成 k+1 层后,神经网络的性能不但不能提高,还可能会下降。残差网络的设计思路是,通过增加残差模块提高神经网络的深度。由于残差模块存在一个恒等映射,会把前面 k 层神经网络的输出直接“引用”过来,而残差模块中的 F(X)部分相当于起到一个“补充”的作用,弥补前面 k 层神经网络不足的部分,二者加起来作为输出。这样既很好地保留了前面 k 层神经网络的信息,又通过新增加的残差模块提供了新的补充信息,有利于提高神经网络的性能。可以说残差网络通过引入残差模块,同时解决了梯度消失和网络退化现象,可谓是一箭双雕。
3.2.3 残差网络
- 因为在残差模块中恒等部分是没有学习参数的,只有 F(X)部分有需要学习的参数,如果把 F ′ ( X ) F'(X) F′(X) 看做是一个理想的结果的话, F ( X ) = F ′ ( X ) − X F(X) = F'(X) - X F(X)=F′(X)−X 就相当于是对误差的估计,残差网络通过一层层增加残差模块,逐步减少估计误差,所以取名残差网络。


- 上图 3 处虚线与其他的恒等映射有所不同。画实线的恒等映射将前面残差模块的输出直接引用过来,是货真价实的恒等映射,而画虚线的恒等映射是需要做一些变换的。
- 残差模块的输出是恒等映射和 2 个卷积层的输出按位相加后再连接激活函数,按位相加就必须通道数一样、通道的大小也一样。而在画虚线的残差模块中,第一个卷积核的步长是 2,使得通道大小的宽和高各缩减了一半,另外卷积核的个数与输入的通道数也不一样了,这样就造成了在该残差模块的卷积层输出不能与恒等映射的输出直接相加了。为此需要对恒等映射进行改造,使得其输出的通道数和通道大小与卷积层的输出一致。怎么改造呢?一种简单的办法就是在恒等映射时加上一个 1×1 的卷积层,其步长和卷积核数与卷积层一致,以便二者可以直接按位相加。
- 还有一点需要说明一下,图所示的残差网络中,同 GoogLeNet 一样,在输出层的前面用一个平均池化代替一个全连接层,但是这里用的是一个全局平均池化。也就是说,经过全局平均池化后,每个通道就变成了只有一个平均数,或者说,通道的大小变成 1×1 了。这相当于用一个具有代表性的平均值代替了一个通道,其效果不仅有效减少了要学习的参数个数,还可以提高神经网络的性能。
4. 总结

-
BP 算法是通过反向传播方法一层一层由输出层向输入层将梯度反传到神经网络的每一层的,在神经网络层数比较多的情况下,梯度值可能会逐步衰减趋近于 0,从而造成距离输入层比较近的神经元的权重无法修正,达不到训练的目的。这种现象称为梯度消失问题。
-
为了消除梯度消失问题带来的影响,提出了一些解决方法。
-
当激活函数采用 sigmoid 函数时这种现象尤为严重,因为在 BP 算法中每次传播都要乘一个激活函数的导数,而 sigmoid 函数的导数值一般比较小,更容易造成梯度消失问题。用 ReLU 激活函数代替 sigmoid 函数是一种消除梯度消失问题的有效手段,因为 ReLU 函数当输入大于 0 时,其导数值为 1,不会由于在反传过程中乘以激活函数的导数而导致梯度消失。这也是这些年来 ReLU 激活函数被广泛使用的原因之一。
-
在 GoogLeNet 中,为了解决梯度消失问题,除了使用 ReLU 激活函数外,还在神经网络的不同位置设置了 3 个输出,损失函数将三部分综合在一起,减少了梯度消失问题带来的不良影响。GoogLeNet 由多个 inception 模块串联组成,每个 inception 模块中采用了不同大小的卷积核,将不同粒度的特征综合在一起。同时采用 1×1 卷积核做信息压缩,有效减少了训练参数,加快了训练速度。
-
原则上来说,神经网络越深其性能应该越好,但是一些实验表明,当网络加深到一定程度之后,即便是在训练集上也会出现随着网络加深而性能下降的现象,这一现象称为网络退化。这是个比较复杂的问题,并不是单纯的梯度消失造成的,还有待于从理论上进行分析和解释。
-
为解决网络退化问题,提出了残差网络 ResNet。残差网络由多个残差模块串联而成,每个残差模块含有两个卷积层,并通过一个恒等映射和卷积层的输出按位相加在一起。从消除梯度消失的角度来说,残差网络由于恒等映射的存在,可以将梯度传递到任意一个残差模块;从消除网络退化的角度来说,残差网络由于恒等映射的存在,每增加一个残差模块都会把前面的神经网络输出直接“引用”过来,而残差模块中的 F(X)部分相当于起到一个“补充”的作用,弥补前面神经网络不足的部分,二者加起来作为输出,这样既很好地保留了前面神经网络的信息,又通过新增加的残差模块提供了新的补充信息,有利于提高神经网络的性能。









![[CISCN 2019 初赛]Love Math 通过进制转换执行命令](https://img-blog.csdnimg.cn/1df743196dab4c79a4fef520071b2726.png)