网页抓取和 REST API 简介
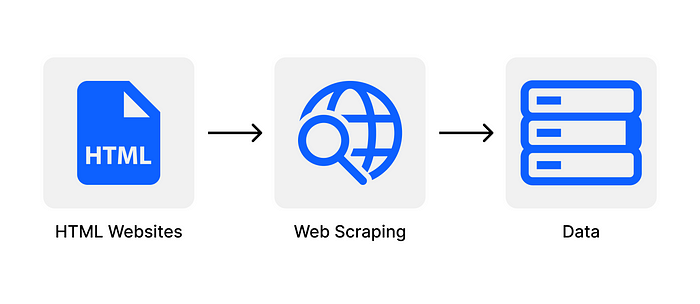
网页抓取是使用计算机程序以自动方式从网站提取和解析数据的过程。这是创建用于研究和学习的数据集的有用技术。虽然网页抓取通常涉及解析和处理 HTML 文档,但某些平台还提供 REST API 来以机器可读格式(如 JSON)检索信息。在本教程中,我们将使用网络抓取和 REST API 创建真实的数据集。
如何运行代码
学习材料的最佳方法是执行代码并亲自进行实验。本教程是一个可执行的 Jupyter 笔记本。
您还可以选择“Run on Colab”或“Run on Kaggle”,但您需要在 Google Colab 或 Kaggle 上创建帐户才能使用这些平台等。
我将在该项目中做什么
1)选择一个网站并描述您的目标
2)使用requests库下载网页
3)使用Beautiful Soup解析和提取信息
4)使用提取的信息创建 CSV 文件
5)编写一个函数:
- 从主题页面获取主题列表
- 从各个主题页面获取顶级存储库列表
- 对于每个主题,创建该主题的顶级存储库的 CSV
GitHub 主题的热门存储库
GitHub URL“ https://github.com/dineshmalappagari/Web-Scraping ”来检查项目。
1)选择一个网站并描述您的目标
——浏览不同的网站并选择进行抓取。查看“项目创意”部分以获取灵感。
— - 确定您想要从网站上抓取的信息。决定输出 CSV 文件的格式。
— -在 Juptyer 笔记本中总结您的项目想法并概述您的策略。使用上面的“新建”按钮。
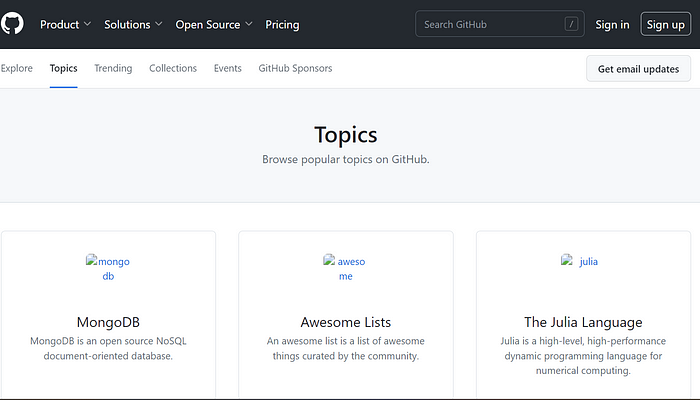
1)我要抓取“ https://github.com/topics”
2)在网站中,我们按字母顺序排列主题。在主题中,我将从主题中选取前 25 个存储库
3)从每个存储库中,我将获取 Repo_name、用户名、Stars 和 URL
2)使用requests库下载网页
— -检查网站的 HTML 源代码并确定要下载的正确 URL。
— -使用requests库将网页下载并保存到本地。
— -创建一个功能来自动下载不同主题/搜索查询。
使用下载网页requests
我们应该安装 !pip 安装请求

requests.get返回一个响应对象,其中包含页面内容和一些使用状态代码指示请求是否成功的信息。在此处了解有关 HTTP 状态代码的更多信息:

让我们将内容保存到具有.html扩展名的文件中。

现在,您可以使用 Jupyter 中的“文件 > 打开”菜单选项并单击显示的文件列表中的3D .html查看该文件。这是打开文件时您将看到的内容:

如果我想编辑文件
检查网页的 HTML 源代码
正如前面提到的,网页是用一种称为 HTML(超文本标记语言)的语言编写的。HTML 是一种 相 当简单的语言,由标签(也称为节点或元素)组成,例<a href="https://jovian.ai" target="_blank">Go to Jovian</a>。HTML 标 签由三部分组成:
- 名称:(
html、head、body、div等)指示标签代表什么以及浏览器应如何解释其中的信息。 - 属性:(
href、target、class、id等)浏览器使用标签的属性来自定义标签的显示方式并决定用户交互时发生的情况。 - 子级:标签可以在开始段和结束段之间包含一些文本或其他标签或两者都包含,例如
<div>Some content</div>。
HTML 文档内部
这是一个简单的 HTML 文档,其中使用了许多常用标签:
<html>
<head>
<title>All About Python</title>
</head>
<body>
<div style="width: 640px; margin: 40px auto">
<h1 style="text-align:center;">Python - A Programming Language</h1>
<img src="https://www.python.org/static/community_logos/python-logo-master-v3-TM.png" alt="python-logo" style="width:240px;margin:0 auto;display:block;">
<div>
<h2>About Python</h2>
<p>
Python is an <span style="font-style: italic">interpreted, high-level and general-purpose</span> programming language. Python's design philosophy emphasizes code readability with its notable use of significant indentation. Its language constructs and object-oriented approach aim to help programmers write clear, logical code for small and large-scale projects. Visit the <a href="https://docs.python.org/3/">official documentation</a> to learn more.
</p>
</div>
<div>
<h2>Some Python Libraries</h2>
<ul id="libraries">
<li>Numpy</li>
<li>Pandas</li>
<li>PyTorch</li>
<li>Scikit Learn</li>
</ul>
</div>
<div>
<h2>Recent Python Versions</h2>
<table id="versions-table">
<tr>
<th class="bordered-table">Version</th>
<th class="bordered-table">Released on</th>
</tr>
<tr>
<td class="bordered-table">Python 3.8</td>
<td class="bordered-table">October 2019</td>
</tr>
<tr>
<td class="bordered-table">Python 3.7</td>
<td class="bordered-table">June 2018</td>
</tr>
</table>
<style>
.bordered-table {
border: 1px solid black; padding: 8px;
}
</style>
</div>
</div>
</body>
</html>练习:复制上面的 HTML 代码并将其粘贴到名为
webpage.html. 要创建新文件,请从菜单栏中选择“文件 > 打开”,然后选择“新建 > 文本”文件。查看保存的文件。你能看到浏览器如何以不同的方式显示不同的标签吗?

练习:对里面的代码进行一些更改
webpage.html。保存文件并再次查看。您看到自己的改变得到体现了吗?尝试一下文件的结构。尝试打破事物并修复它们!
常用标签和属性
以下是一些最常用的 HTML 标签:
htmlheadtitlebodydivspanh1到h6pimgul,ol和litable,tr,th和tdstyle- ……
每个标签支持多个属性。以下是用于修改标签行为的一些常见属性:
idstyleclasshref(与 一起使用<a>)src(与 一起使用<img>)
使用 Beautiful Soup 从 HTML 中提取信息
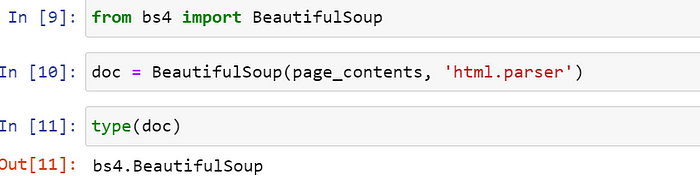
要以编程方式从网页的 HTML 源代码中提取信息,我们可以使用Beautiful Soup库。让我们安装该库并BeautifulSoup从bs4模块导入该类。
3)使用Beautiful Soup解析和提取信息
— -使用 Beautiful soup 解析和探索下载的网页的结构。
——使用正确的属性和方法来提取所需的信息。
— -创建函数以从页面提取到列表和字典中。
— -(可选)如果需要,使用 REST API 获取其他信息。
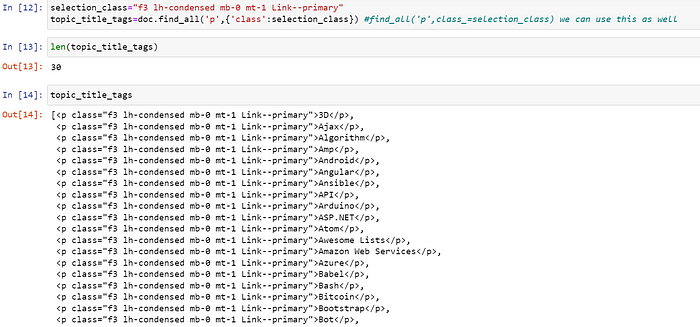
我想抓取 gitHub 中的所有主题
我想获取 gitHub 中所有主题的描述

我想为主题 3D 创建 URL
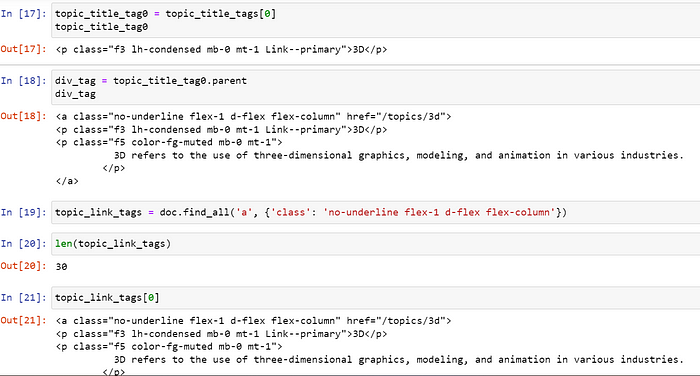
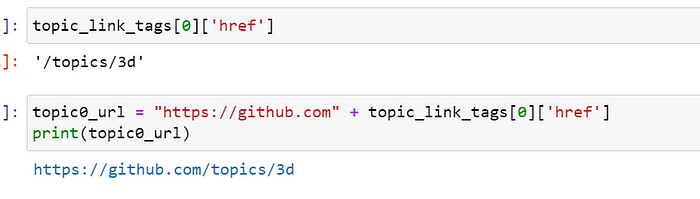
网址已创建
我想创建主题列表

我想创建列表中所有主题的描述

我想为每个主题创建 URL 列表
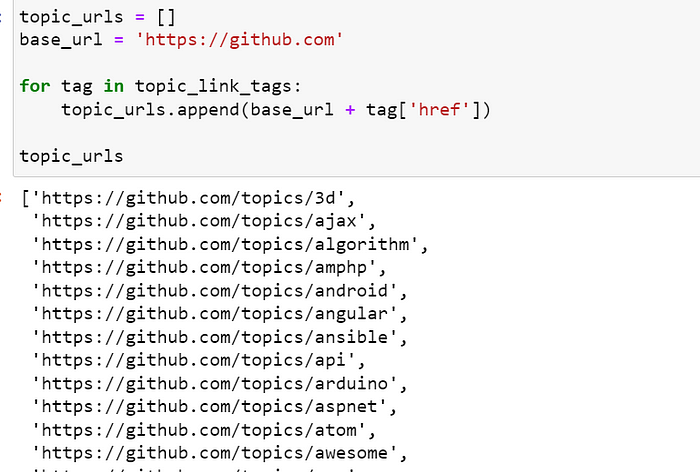
4)使用提取的信息创建 CSV 文件
— -为下载、解析和保存 CSV 的端到端过程创建函数。
— -使用不同的输入执行该函数以创建 CSV 文件的数据集。
— -使用 Pandas 读回 CSV 文件来验证其中的信息。
我想为我的信息创建数据框
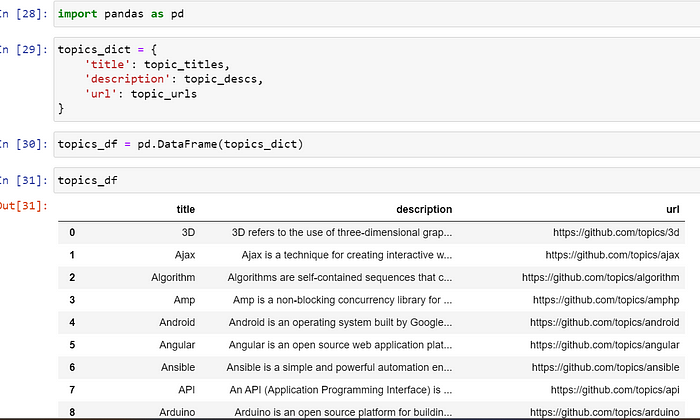
从主题页面获取信息


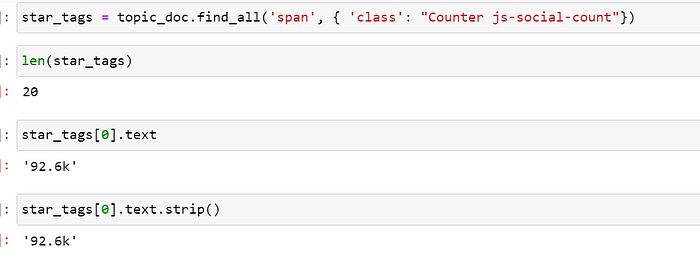
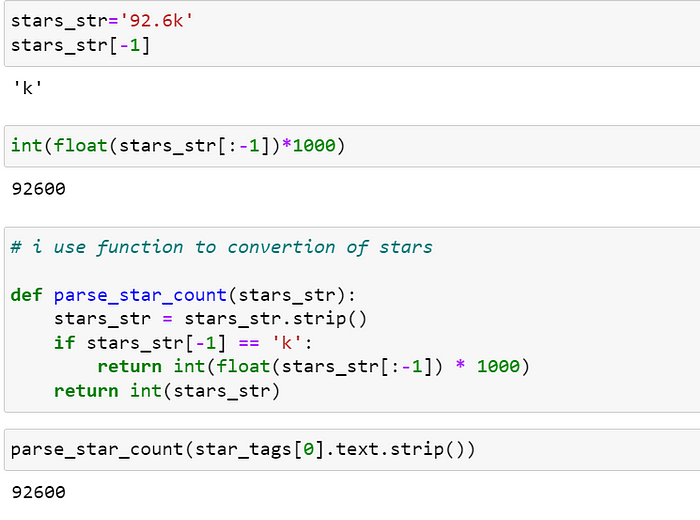
我想将 '92.6k' 转换为 '92600'
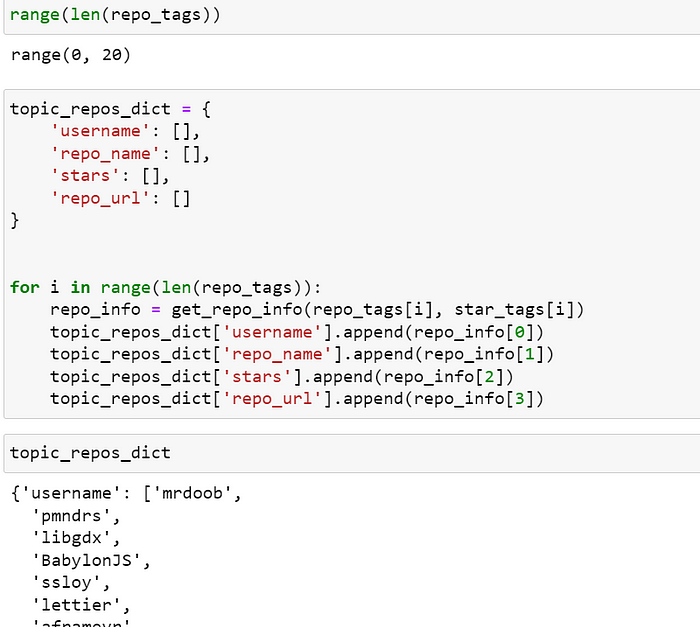
我想使用函数添加我的所有数据

我想将信息存储到我指定列名称的列中
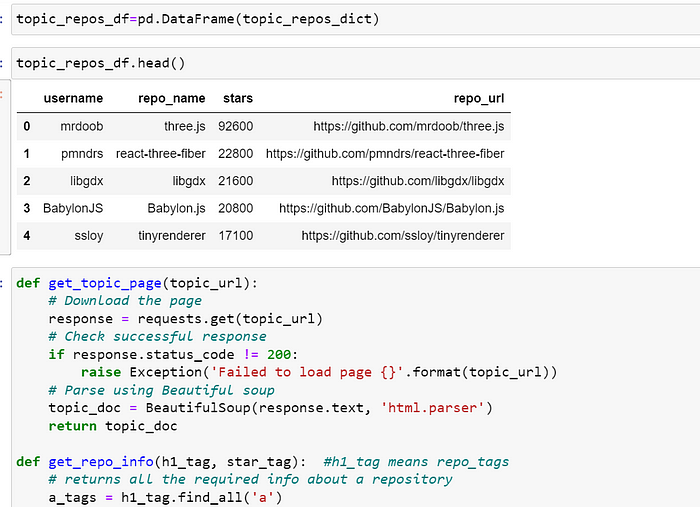

我想检查我的代码如何工作

我们检查一下我们的代码在一行中是如何工作的
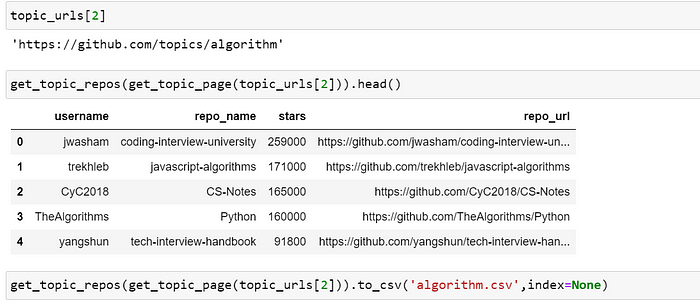
我要为文件写的代码不应该重复
os.path 模块始终是适合 Python 运行的操作系统的路径模块,因此可用于本地路径。
最终代码
导入操作系统
def scrape_topic(topic_url, path):
if os.path.exists(path):
print(“文件 {} 已存在。正在跳过…”.format(path))
return
topic_df = get_topic_repos(get_topic_page(topic_url))
topic_df.to_csv (路径,索引=无)
5)编写一个函数:
- 从主题页面获取主题列表
- 从各个主题页面获取顶级存储库列表
- 对于每个主题,创建该主题的顶级存储库的 CSV