数据挖掘之Pandas库相关使用
- 一、概念
- 1、介绍
- 2、Pandas的优点
- 3、软件推荐(Jupyter Notebook)
- 4、软件下载网址以及参考文档
- 二、基础知识
- 1、DataFrame属性和方法
- 1.1 结构
- (1)行索引
- (2)列索引
- 1.2 常用属性
- (1)shape
- (2)index
- (3)columns
- (4)values
- (5)T
- 1.3 常用方法
- (1)head()
- (2)tail()
- 2、修改索引
- 2.1 修改行列索引值
- 2.2 重设索引
- 2.3 以某列值设置为新的索引
- (1)语法
- (2)以月份设置新的索引
- (3)设置多个索引,以年和月份
- 3、MultiIndex与Panel
- 3.1 MultiIndex
- 3.2 Panel
- (1)概念
- (2)语法
- 4、Series
- 4.1 概念
- 4.2 创建Series
- (1)指定内容,默认索引
- (2)指定索引
- (3)通过字典数据创建
- 4.3 属性
- (1)index
- (2)values
- 4.4 总结
- 三、基本数据操作
- 1、索引操作
- 1.1 基础数据整理
- 1.2 直接使用行列索引(先列后行)
- 1.3 按名字索引
- 1.4 按数字索引
- 2、赋值操作
- 3、排序
- 3.1 内容排序
- 3.2 索引排序
- 四、DataFrame运算
- 1、算术运算
- 1.1 加法
- 1.2 减法
- 2、逻辑运算
- 2.1 逻辑运算符号 >
- 2.2 逻辑运算符 &
- 2.3 逻辑运算函数
- (1)query(expr) expr: 查询字符串
- (2)isin(values)
- 3、统计运算
- 3.1 describe()
- 3.2 max()
- 3.3 获取最大值的位置
- 3.4 累计统计函数
- 4、自定义运算
- 五、文件的读取与存储
- 1、CSV文件
- 1.1 读取csv文件(read_csv)
- 1.2 写入csv文件(to_csv)
- 2、HDF5文件(二进制文件)
- 2.1 读取HDF5文件(read_hdf)
- 2.2 存储成HDF5文件
- 2.3 拓展
- 3、JSON
- 3.1 读取JSON文件(read_json)
- 3.2 存储JSON文件(to_json)
一、概念
1、介绍
pandas是专门用于数据挖掘的开源python库,以Numpy为基础,借力Numpy模块在计算方面性能高的优势,同时基于matplotlib,能够简便的画图,具有独特的数据结构。
2、Pandas的优点
便捷的数据处理能力
读取文件方便
封装了Matplotlib、Numpy的画图和计算
3、软件推荐(Jupyter Notebook)
使用Jupyter Notebook,是IPython的加强网页版,一个开源Web应用程序,是一款程序员和科学工作者的编程/文档/笔记/展示软件。
.ipynb文件格式是用于计算型叙述的JSON文档格式的正式规范
4、软件下载网址以及参考文档
跳转链接:Jupyter官网
对于新手而言一般用Anacomda上的Jupyter,如果不知道如何安装Anaconda软件的话,可以参考我写的Anaconda+tensorflow最有实效总结版(重装6次的血泪总结)
二、基础知识
1、DataFrame属性和方法
1.1 结构
DataFrame可以看成既有行索引,又有列索引的二维数组
(1)行索引
表明不同行,横向索引,叫index
(2)列索引
表明不同列,纵向索引,叫columns
1.2 常用属性
(1)shape
data.shape
结果

(2)index
DataFrame的行索引列表
data.index
结果

(3)columns
DataFrame的列索引列表
data.columns
结果

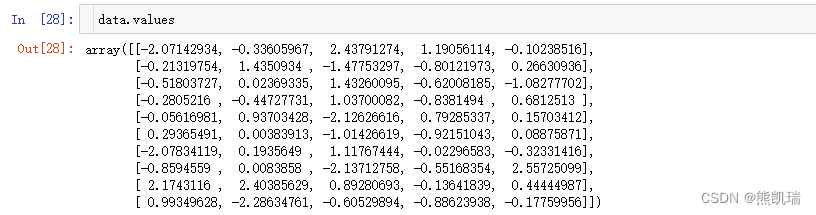
(4)values
直接获取其中array的值
data.values
结果
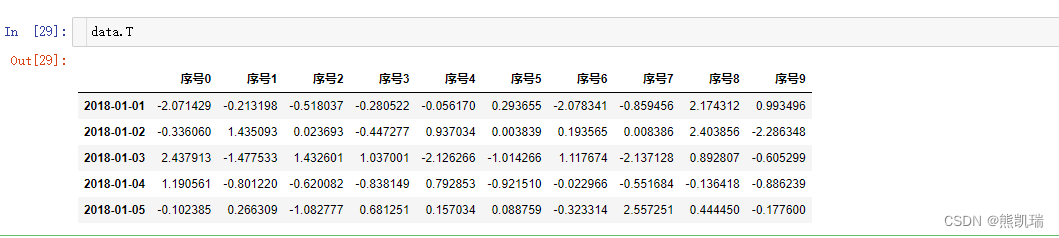
(5)T
转置
data.T
结果
1.3 常用方法
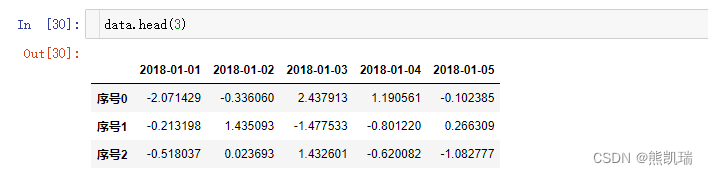
(1)head()
展示前几行的数据
data.head(3)
结果
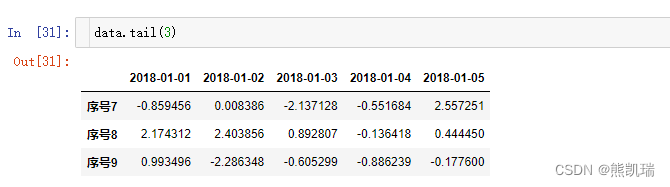
(2)tail()
展示后几行的数据
data.tail(3)
结果
2、修改索引
2.1 修改行列索引值
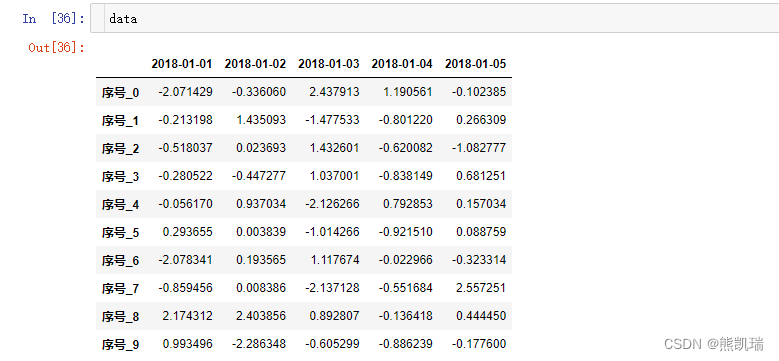
不能单独修改某一个索引,只能整体修改索引
stock_ = ["序号_{}".format(i) for i in range(10)]
data.index = stock_
结果
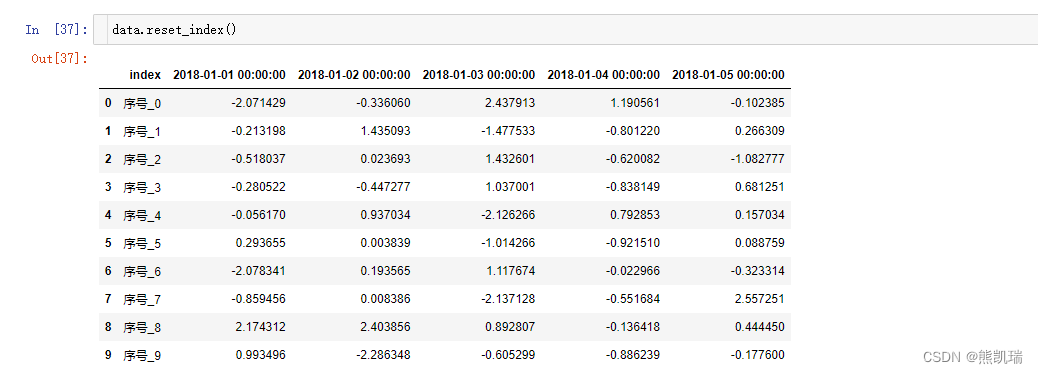
2.2 重设索引
data.reset_index()
结果
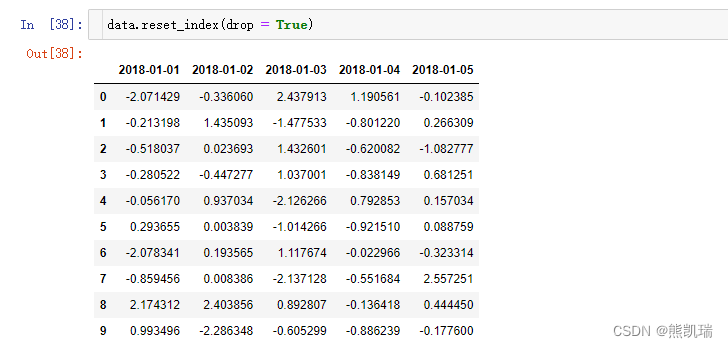
如果
data.reset_index(drop = True)
结果
2.3 以某列值设置为新的索引
(1)语法
set_index(key, drop=True)
keys:列索引名称或者列索引名称的列表
drop: boolean, default True当做新的索引,删除原来的列
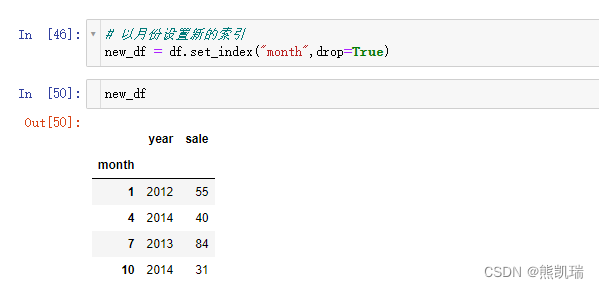
(2)以月份设置新的索引
# 以月份设置新的索引
new_df = df.set_index("month",drop=True)
结果
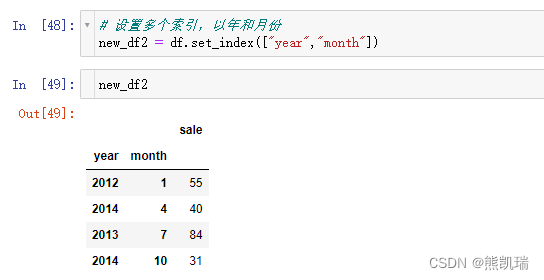
(3)设置多个索引,以年和月份
# 设置多个索引,以年和月份
new_df2 = df.set_index(["year","month"])
结果
3、MultiIndex与Panel
3.1 MultiIndex
多级或分层索引对象
index属性
names: levels的名称
levels: 每个level的元组值
例一
new_df2.index.names
结果

例二
new_df2.index.levels
结果

3.2 Panel
(1)概念
存储三维结构的容器
Pandas从版本0.20.0开始弃用,在新版本中会报错:推荐使用表示3D数据的方法是DataFrame上的MultiIndex方法
(2)语法
pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None)
样例代码
p = pd.Panel(np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first','second'])
如果一定要使用,则下载指定版本,可能有用:python3下具有Panel()的pandas版本pandas 0.24.2。(我看网上有人下载这个版本有Panel(),不知道是不是真的)
4、Series
4.1 概念
带索引的一维数组(Series结构只有行索引)
4.2 创建Series
通过已有数据创建
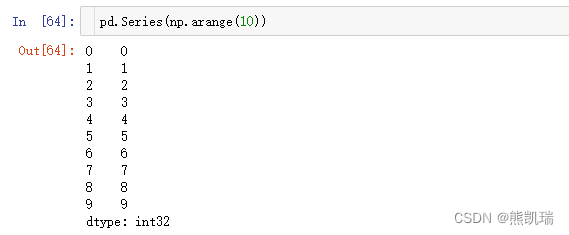
(1)指定内容,默认索引
pd.Series(np.arange(10))
结果
(2)指定索引
# 指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
结果

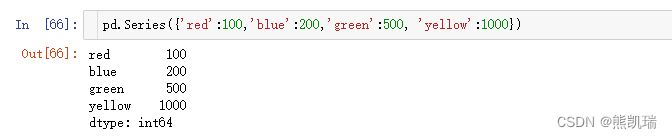
(3)通过字典数据创建
# 通过字典数据创建
pd.Series({'red':100,'blue':200,'green':500, 'yellow':1000})
结果
4.3 属性
(1)index
sr.index
结果

(2)values
sr.values
结果

4.4 总结
DataFrame是Series的容器
Panel是DataFrame的容器
三、基本数据操作
1、索引操作
1.1 基础数据整理
# 读取文件
data = pd.read_csv("./day/day.csv")
# 删除一些列
data = data.drop(["ma5", "ma10", "ma20"], axis=1)
1.2 直接使用行列索引(先列后行)
data["列名"]["行名"]
例如
data["column"]["row"]
1.3 按名字索引
data.loc["行名"]["列名"]
data.loc["行名","列名"]
例如
data.loc["row"]["column"]
data.loc["row","column"]
1.4 按数字索引
data.iloc[1,0]
2、赋值操作
# 对DataFrame当中的close列进行重新赋值为1
# 直接修改原来的值
data['close'] = 1
# 或者
data.close = 1
3、排序
3.1 内容排序
使用df.sort_values(key=, ascending=) 对内容进行排序
单个键或者多个键进行排序,默认升序
ascending = False: 降序
ascending = True: 升序
# 按某一列进行降序
data = data.sort_values(by='列名', ascending = False)
# 按某几列进行降序
data = data.sort_values(by=['列名1','列名2'], ascending = False)
3.2 索引排序
使用df.sort_index对索引进行排序(从小到大)
data.sort_index()
四、DataFrame运算
1、算术运算
1.1 加法
# 该列所有数字加3
data['列名'].add(3).head()
1.2 减法
# 全部都减100
data.sub(100).head()
2、逻辑运算
2.1 逻辑运算符号 >
# 筛选大于2的数据
data[data['列名'] > 2]
2.2 逻辑运算符 &
# 完成一个多逻辑判断,筛选列1大于2且列2大于15
data[(data['列名1'] > 2)&(data['列名2'] > 15)]
2.3 逻辑运算函数
(1)query(expr) expr: 查询字符串
根据条件进行查询
# 完成一个多逻辑判断,筛选列1大于2且列2大于15
data.query("列名1 > 2 & 列名2 > 15")
(2)isin(values)
判断是否存在
data["列名"].isin({4.1,2.3})
3、统计运算
3.1 describe()
综合分析:能够直接得出很多统计结果:count,mean,std,min,max等
# 统计结果
data.describe()
3.2 max()
获取最大值
data.max()
3.3 获取最大值的位置
data.idxmax()
3.4 累计统计函数
data["列名1"].cumsum()
4、自定义运算
apply(func, axis=0)
func: 自定义函数
axis=0: 默认是列,axis=1 为行进行运算
# 定义一个队列,最大值-最小值的函数
data[['open','close']].apply(lambda x: x.max() - x.min(), axis=0)
五、文件的读取与存储
1、CSV文件
1.1 读取csv文件(read_csv)
pandas.read_csv(filepath_or_buffer, sep=‘,’, delimiter = None)
filepath_or_buffer:文件路径
usecols:指定读取的列名,列表形式
names:给数据添加列名
# csv文件里有列名
data = pd.read_csv("./day/day.csv", usecols=['open', 'high'])
# csv文件里没有列名
data = pd.read_csv("./day/day.csv", names=["open", "high"])
1.2 写入csv文件(to_csv)
DataFrame.to_csv(path_or_buf=None, Sep=‘,’,Columns=None,header=True,index=True, index_label=None, mode=‘w’, encoding=None)
path_or_buf: 文件路径
columns: 增加列名
mode: ‘w’:重写,‘a’ 追加
index: 是否写进行索引
data.to_csv("test.csv",columns=["open"], index=False)
2、HDF5文件(二进制文件)
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
2.1 读取HDF5文件(read_hdf)
pandas.read_hdf(path_or_buf, key=None, **kwargs)
从h5文件当中读取数据
path_or_buffer: 文件路径
key: 读取的键
mode: 打开文件的模式
return: Theselected object
data = pd.read_hdf("./day/day_data.h5")
2.2 存储成HDF5文件
存储时需要指定键,如果反复存储时指定了多个键,则读取时,需要指明是哪个键
data.to_hdf("test.h5", key="close")
指定了多个键,读取时,指明键
data.read_hdf("test.h5", key="close")
2.3 拓展
(1)HDF5在存储是支持压缩,使用方式是blosc,这个是速度最快的,也是pandas默认支持的。
(2)使用压缩可以提高磁盘利用率,节省空间。
(3)HDF5还是跨平台的,可以轻松迁移到hadoop上面。
3、JSON
Json是常用的数据交换格式。
3.1 读取JSON文件(read_json)
pandas.read_json(path_or_buf=None, orient = None, typ = ‘frame’, lines=False)
orient: 告诉API读取的数据采用什么格式(一般都用records)
lines: 按照每行读取json对象
typ:指定转换成的对象类型series或者dataframe
sa = pd.read_json("data.json", orient="records", lines=True)
3.2 存储JSON文件(to_json)
sa.to_json("data.json", orient="records", lines=True)









![【精选】ARMv8/ARMv9架构入门到精通-[前言]](http://assets.processon.com/chart_image/604719347d9c082c92e419de.png)