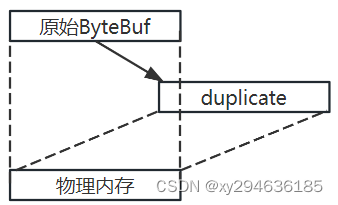
AMDGPU驱动模块的依赖关系如下图,gpu_sched.ko位于GPU驱动架构的中间层,主要负责对应用发送下来的渲染和计算等命令进行调度:

编译gpu_sched.ko
模块源码位于linux-x.x.xx/drivers/gpu/drm/scheduler下,通过CONFIG_DRM_SCHED项配置编译。从Makefile来看,代码量不是很大,只有三个源文件,但子曾经曰过,尿泡虽大无斤两,秤砣虽小挑千斤,这个小小的模块中包含了GPU调度的精髓,这篇文章也是从核心的下手开始分析。

编译一遍:
make drivers/gpu/drm/scheduler/
根据编译过程也可以看到,模块本身对应的源码仅仅有sched_main.c,sched_fence.c,sched_entity.c三个。
接口定义
sched_main.c接口定义
static bool drm_sched_blocked(struct drm_gpu_scheduler *sched);
static __always_inline bool drm_sched_entity_compare_before(struct rb_node *a,
const struct rb_node *b);
void drm_sched_fault(struct drm_gpu_scheduler *sched);
void drm_sched_fini(struct drm_gpu_scheduler *sched);
static struct drm_sched_job *
drm_sched_get_cleanup_job(struct drm_gpu_scheduler *sched);
void drm_sched_increase_karma(struct drm_sched_job *bad);
int drm_sched_init(struct drm_gpu_scheduler *sched,
onst struct drm_sched_backend_ops *ops,
unsigned hw_submission, unsigned hang_limit,
long timeout, struct workqueue_struct *timeout_wq,
atomic_t *score, const char *name, struct device *dev);
int drm_sched_job_add_dependency(struct drm_sched_job *job,
struct dma_fence *fence);
int drm_sched_job_add_implicit_dependencies(struct drm_sched_job *job,
struct drm_gem_object *obj,
bool write);
int drm_sched_job_add_resv_dependencies(struct drm_sched_job *job,
struct dma_resv *resv,
enum dma_resv_usage usage);
int drm_sched_job_add_syncobj_dependency(struct drm_sched_job *job,
struct drm_file *file,
u32 handle,
u32 point);
void drm_sched_job_arm(struct drm_sched_job *job);
static void drm_sched_job_begin(struct drm_sched_job *s_job);
static void drm_sched_job_timedout(struct work_struct *work);
void drm_sched_job_cleanup(struct drm_sched_job *job);
static void drm_sched_job_done(struct drm_sched_job *s_job);
static void drm_sched_job_done_cb(struct dma_fence *f, struct dma_fence_cb *cb);
int drm_sched_job_init(struct drm_sched_job *job,
struct drm_sched_entity *entity,void *owner);
static int drm_sched_main(void *param);
struct drm_gpu_scheduler *
drm_sched_pick_best(struct drm_gpu_scheduler **sched_list,unsigned int num_sched_list);
static bool drm_sched_ready(struct drm_gpu_scheduler *sched);
void drm_sched_resubmit_jobs(struct drm_gpu_scheduler *sched);
void drm_sched_resume_timeout(struct drm_gpu_scheduler *sched,unsigned long remaining);
void drm_sched_rq_add_entity(struct drm_sched_rq *rq,struct drm_sched_entity *entity);
static void drm_sched_rq_init(struct drm_gpu_scheduler *sched,struct drm_sched_rq *rq);
void drm_sched_rq_remove_entity(struct drm_sched_rq *rq,struct drm_sched_entity *entity);
static inline void drm_sched_rq_remove_fifo_locked(struct drm_sched_entity *entity);
static struct drm_sched_entity *
drm_sched_rq_select_entity_fifo(struct drm_sched_rq *rq);
static struct drm_sched_entity * drm_sched_rq_select_entity_rr(struct drm_sched_rq *rq);
void drm_sched_rq_update_fifo(struct drm_sched_entity *entity, ktime_t ts);
static struct drm_sched_entity *drm_sched_select_entity(struct drm_gpu_scheduler *sched);
void drm_sched_start(struct drm_gpu_scheduler *sched, bool full_recovery);
static void drm_sched_start_timeout(struct drm_gpu_scheduler *sched);
void drm_sched_stop(struct drm_gpu_scheduler *sched, struct drm_sched_job *bad);
sched_fence.c
struct drm_sched_fence *drm_sched_fence_alloc(struct drm_sched_entity *entity,
void *owner);
void drm_sched_fence_finished(struct drm_sched_fence *fence);
void drm_sched_fence_free(struct drm_sched_fence *fence);
static void drm_sched_fence_free_rcu(struct rcu_head *rcu);
static const char *drm_sched_fence_get_driver_name(struct dma_fence *fence);
static const char *drm_sched_fence_get_timeline_name(struct dma_fence *f);
void drm_sched_fence_init(struct drm_sched_fence *fence,struct drm_sched_entity *entity);
static void drm_sched_fence_release_finished(struct dma_fence *f);
static void drm_sched_fence_release_scheduled(struct dma_fence *f);
void drm_sched_fence_scheduled(struct drm_sched_fence *fence);
static void drm_sched_fence_set_deadline_finished(struct dma_fence *f,ktime_t deadline);
void drm_sched_fence_set_parent(struct drm_sched_fence *s_fence,struct dma_fence *fence);
static void __exit drm_sched_fence_slab_fini(void);
static int __init drm_sched_fence_slab_init(void);
struct drm_sched_fence *to_drm_sched_fence(struct dma_fence *f);sched_entity.c
static bool drm_sched_entity_add_dependency_cb(struct drm_sched_entity *entity);
static void drm_sched_entity_clear_dep(struct dma_fence *f,struct dma_fence_cb *cb);
void drm_sched_entity_destroy(struct drm_sched_entity *entity);
void drm_sched_entity_fini(struct drm_sched_entity *entity);
long drm_sched_entity_flush(struct drm_sched_entity *entity, long timeout);
int drm_sched_entity_init(struct drm_sched_entity *entity,
enum drm_sched_priority priority,
struct drm_gpu_scheduler **sched_list,
unsigned int num_sched_list,atomic_t *guilty);
static bool drm_sched_entity_is_idle(struct drm_sched_entity *entity);
bool drm_sched_entity_is_ready(struct drm_sched_entity *entity);
static void drm_sched_entity_kill(struct drm_sched_entity *entity);
static void drm_sched_entity_kill_jobs_cb(struct dma_fence *f,struct dma_fence_cb *cb);
static void drm_sched_entity_kill_jobs_work(struct work_struct *wrk);
void drm_sched_entity_modify_sched(struct drm_sched_entity *entity,
struct drm_gpu_scheduler **sched_list,
unsigned int num_sched_list);
struct drm_sched_job *drm_sched_entity_pop_job(struct drm_sched_entity *entity);
void drm_sched_entity_push_job(struct drm_sched_job *sched_job);
void drm_sched_entity_select_rq(struct drm_sched_entity *entity);
void drm_sched_entity_set_priority(struct drm_sched_entity *entity,
enum drm_sched_priority priority);
static void drm_sched_entity_wakeup(struct dma_fence *f,struct dma_fence_cb *cb);
static struct dma_fence *drm_sched_job_dependency(struct drm_sched_job *job,
struct drm_sched_entity *entity);主要接口TRACE
drm_sched_entity_push_job接口用于向GPU发送命令包去执行,尝试追踪其调用堆栈,DRM字符设备操作函数和DRM驱动函数之间建立桥接联系,当通过标准的字符设备驱动调用到KMS驱动后,就可以将驱动转化为DRM框架内部的调用,调动DRM驱动框架的资源驱动GPU,为用户渲染应用服务。



GPU命令执行上下文是由amdgpu_job_run驱动的,其调用上下文是gpu_sched.ko中创建的drm_sched_main内核线程。
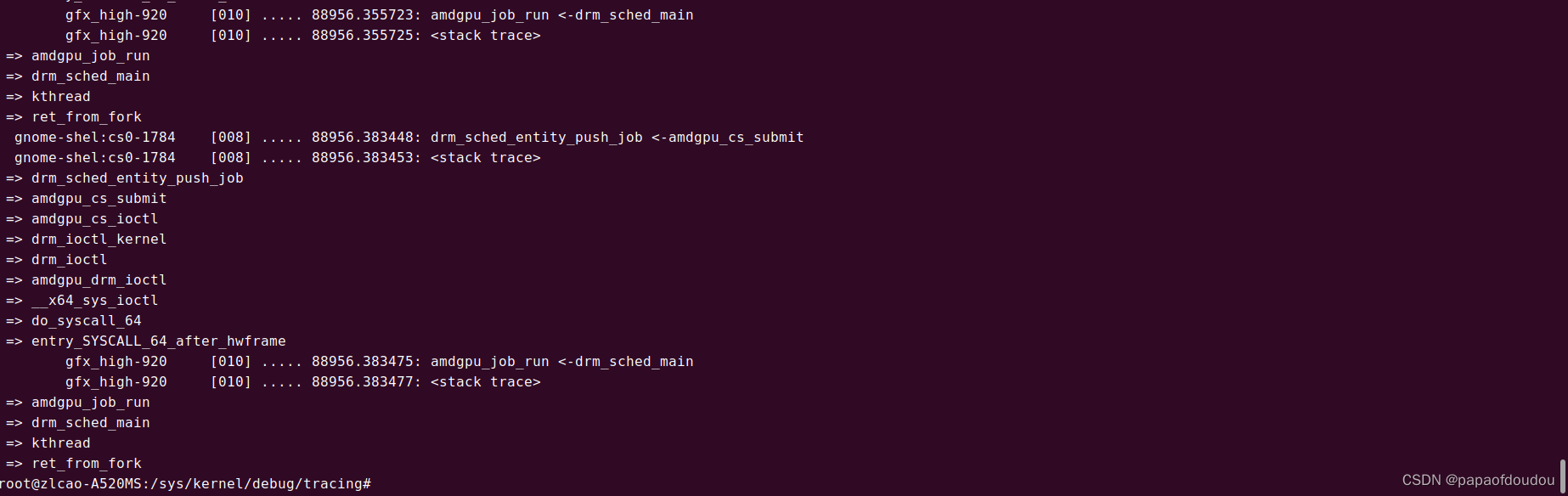
下图是抓到的一个命令包的调度执行周期,命令包首先由用户应用发起调用,在DRM上下文中调用drm_sched_entity_push_job命令包推入命令队列,完成发射。
之后在gpu_sched模块的内核线程中,完成准备,执行,释放的命令执行周期。