论文链接:GODIVA: Generating Open-DomaIn Videos from nAtural Descriptions
文章目录
- 摘要
- 引言
- 相关工作
- Video-to-video generation
- Text-to-image generation
- Text-to-video generation
- GODIVA方法
- 逐帧视频自动编码器
- GODIVA视频生成器
- 实验
- 数据集
- 评价指标
- 自动评估指标
- 人工评估指标
- 实施细节
- 定性结果
- 定量结果
- 结论
摘要
从文本生成视频任务是极具挑战性的任务,由于其训练的高计算需求和答案无限性难以评估。当前的工作通常在简单或小型数据集上进行实现,泛化能力非常有限。本工作提出了GODIVA,一种开放域文本到视频的预训练模型,可以使用三维稀疏注意机制以自回归的方式从文本中生成视频。在 Howto100M 上预训练模型,这是一个包含超过 13600 万个文本-视频对的大规模文本-视频数据集。实验表明,GODIVA 不仅可以在下游视频生成任务上进行微调,而且在zero-shot的文本上也具有良好的零样本能力。本文还提出了一种名为相对匹配 (Relative Matching/RM) 的新指标来自动评估视频生成质量。列出并讨论了一些挑战作为未来的工作。
引言
“创造力是人类智力的一个基本特征,也是人工智能的挑战”。图像和文本生成的最新进展显示了机器的巨大创造力,包括GANs、VAE、RNN和自注意力。然而,AI 代理创建视频仍然是一个挑战,尤其是对于现实世界的多样性。生成视频要求机器不仅创建大量像素,而且还确保它们之间的语义一致性。
从文本生成视频的挑战,即文本到视频生成 (T2V) 任务。给定一个自然描述,T2V 要求机器理解它并创建语义一致的视频。尽管不是太多,但仍有一些工作使用 GAN 来研究这个主题。Video Generation From Text和To Create What You Tell: Generating Videos from Captions使用带有3D卷积的GAN来生成固定长度的低分辨率视频。Conditional GAN with Discriminative Filter Generation for Text-to-Video Synthesis使用条件过滤器来生成不同长度的视频。IRC-GAN: Introspective Recurrent Convolutional GAN for Text-to-video Generation将 LSTM 单元与 2D 卷积网络相结合,对帧质量和时间一致性进行建模。然而,这些工作在简单或小型数据集上进行了实验,泛化能力有限。
除了基于 GAN 的方法外,VQ-VAE 是另一个有前途的研究方向,并且在生成图像和视频方面取得了很大进展,尤其是用于文本到图像生成的 DALL-E。它成功地从文本中生成高质量的图像。本文转向更具挑战性的文本到视频生成任务,其中必须考虑视觉信息的时空连贯性。最近的一些工作Latent Video Transformer、Predicting Video with VQVAE、VideoGen: Generative Modeling of Videos using VQ-VAE and Transformers
将VQ-VAE应用于视频预测任务——预测给定过去的未来视频帧。本文是第一个为 T2V 任务设计一个 VQ-VAE 预训练模型。
本文提出了 GODIVA,使用 VQ-VAE 和三维稀疏注意力从文本中生成开放域视频。首先,训练一个VQ-VAE自动编码器来表示具有离散视频标记的连续视频像素。然后,使用语言作为输入训练三维稀疏注意力模型,将离散视频标记作为标签来生成视频,考虑时间、列和行信息,如图1所示。

本文的贡献有三个方面:(1) 提出了一个开放域文本到视频的预训练模型,该模型具有三维稀疏注意机制,可以显著降低计算成本;(2) 提出了一种新的相对匹配度量(RM),该度量可以同时评价视频生成的视觉质量和语义匹配;(3) 在HowTo100M数据集上对提出的模型进行了预训练,并演示了其在微调和零镜头设置下的视频生成能力。
相关工作
本节简要回顾视频生成的相关工作。首先回顾了近年来被广泛研究的视频到视频生成任务。然后回顾文本到图像和文本到视频的生成。强调了先前模型和本文模型之间的差异。
Video-to-video generation
大多数视频生成研究都集中在视频预测任务上。输入视频的前几帧,视频预测任务预测视频的以下帧。称之为视频到视频 (V2V) 生成,以便与文本到视频 (T2V) 生成进行比较。
现有的视频到视频生成可以分为三类
- 确定性方法使用 RNN 和 CNN 直接对易处理密度进行建模,并利用视频的空间和时间信息。PredNet通过整合之前的预测来预测未来的框架。PredRNN提出了堆叠的ConvLSTM,它在堆栈中的各层之间共享隐藏状态。最近,ContextVP在所有可能的方向上聚合每个像素的上下文信息
- 基于GAN的方法避免了显式密度函数,使用生成器生成视频并使用鉴别器判断视频是否生成。VGAN是第一个使用gan生成视频的模型。之后,TGAN将时空生成器分成时间序列模型和空间模型生成视频。然后,MoCoGAN将潜在空间分解为运动子空间和内容子空间,从而更有效地生成视频。最近TGAN2使用其特定的鉴别器训练每个子生成器
- VAE 方法通过捕获低维表征 z z z并优化似然下界来对近似密度进行建模。SV2P捕获为每个预测序列保持固定的一组潜在变量中的序列不确定性。然后,SVG使用了每一步潜在变量 (SVG-FP) 和具有学习先验 (SVG-LP) 的变体,它使先验在某个时间步成为前一帧的函数。Latent Video Transformer对视频的每一帧进行编码并预测离散的视频特征。
本文模型可以归类为基于 VAE 的模型。与最近的基于VQ-VAE的工作Latent Video Transformer不同,本文模型工作专注于文本到视频的生成任务,而不是视频到视频的生成任务。本文模型还加入了一个三维稀疏注意来模拟视觉标记之间的稀疏关系。
Text-to-image generation
近年来,文本到图像的生成得到了广泛的研究。最相似的工作是DALL-E,它成功地从文本中生成高质量的图像。本文转向一个更具挑战性的文本到视频生成任务,该任务同时考虑了视觉信息的时空连贯性。
Text-to-video generation
与视频到视频的生成不同,文本到视频的生成研究较少。首先,Video Generation From Text和To Create What You Tell: Generating Videos from Captions使用带有3D卷积的GAN来生成固定长度的低分辨率视频。然后,Conditional GAN with Discriminative Filter Generation for Text-to-Video Synthesis使用条件过滤器来生成不同长度的视频。IRC-GAN: Introspective Recurrent Convolutional GAN for Text-to-video Generation将 LSTM 单元与 2D 卷积网络相结合,对帧质量和时间一致性进行建模。
大多数文本到视频生成方法使用基于 GAN 的方法,本文模型为此任务结合了 VQ-VAE。据知,这是第一项使用 VQ-VAE 来完成这项任务的论文。
GODIVA方法
设 x x x是一个可观察的视频,使用离散潜在代码 z z z来表示它,其维度较低。下文展示如何使用VQ-VAE以 z z z来表示 x x x,并对 P ( z ∣ t ) P(z|t) P(z∣t)建模从文本中生成视频,其中 t t t表示给定文本。
逐帧视频自动编码器
对于一个有
L
L
L帧的输入视频
x
∈
R
L
×
H
×
W
×
C
x \in R^{L×H×W×C}
x∈RL×H×W×C,第
l
l
l帧
x
(
l
)
x^{(l)}
x(l)用Eq.(1)表示
y
(
l
)
=
E
(
x
(
l
)
)
,
(1)
y^{(l)}=E(x^{(l)}),\tag{1}
y(l)=E(x(l)),(1)
其中
y
(
l
)
∈
R
(
h
w
)
×
d
B
y^{(l)} \in R^{(hw)×d_{B}}
y(l)∈R(hw)×dB是
h
×
w
h×w
h×w区域的隐变量。然后,对
y
(
l
)
y^{(l)}
y(l)进行量化,得到更紧凑的潜在表示,表示为Eq.(2)
z
i
(
l
)
=
arg
min
j
∣
∣
y
i
(
l
)
−
B
j
∣
∣
2
,
(2)
z_{i}^{(l)}=\underset{j}{\arg \min}||y_{i}^{(l)}-B_{j}||^{2}, \tag{2}
zi(l)=jargmin∣∣yi(l)−Bj∣∣2,(2)
其中
B
∈
R
K
×
D
B∈ R^{K×D}
B∈RK×D是码本,在码本中,对潜在变量的第i个区域
y
i
(
l
)
∈
R
d
B
y^{(l)}_{i} ∈ R^{d_{B}}
yi(l)∈RdB进行搜索,以找到最近的索引
z
(
l
)
∈
R
h
w
z^{(l)}∈R^{hw}
z(l)∈Rhw。然后,将
z
(
l
)
z^{(l)}
z(l)嵌入到Eq.(3)中的码本中。
b
(
l
)
=
B
[
z
(
l
)
]
,
(3)
b^{(l)} = B[z^{(l)}], \tag{3}
b(l)=B[z(l)],(3)
其中
b
(
l
)
∈
R
(
h
w
)
×
d
B
b^{(l)} \in R^{(hw)×d_{B}}
b(l)∈R(hw)×dB是
z
(
l
)
z^{(l)}
z(l)是嵌入。接下来,将
b
(
l
)
b^{(l)}
b(l)发送到解码器,解码器重建原始视频帧,如式(4)所示。
x
^
(
l
)
=
D
(
b
(
l
)
)
,
(4)
\hat{x}^{(l)} = D(b^{(l)}), \tag{4}
x^(l)=D(b(l)),(4)
其中
x
^
(
l
)
∈
R
H
×
W
×
C
\hat{x}^{(l)} \in R^{H×W×C}
x^(l)∈RH×W×C是重建帧。最后,VQ-VAE可以在如Eq.(5)所示的目标中进行训练。
L
V
Q
−
V
A
E
=
1
L
∑
l
=
1
L
∣
∣
x
(
l
)
−
x
^
(
l
)
∣
∣
2
2
+
∣
∣
s
g
[
y
(
l
)
]
−
b
(
l
)
∣
∣
2
2
+
β
∣
∣
y
(
l
)
−
s
g
[
b
(
l
)
]
∣
∣
2
2
,
(5)
L^{VQ-VAE} = \frac{1}{L} \sum^{L}_{l=1}||x^{(l)}-\hat{x}^{(l)}||^{2}_{2} + ||sg[y^{(l)}]-b^{(l)}||^{2}_{2}+\beta||y^{(l)}-sg[b^{(l)}]||^{2}_{2}, \tag{5}
LVQ−VAE=L1l=1∑L∣∣x(l)−x^(l)∣∣22+∣∣sg[y(l)]−b(l)∣∣22+β∣∣y(l)−sg[b(l)]∣∣22,(5)
其中三项分别为重建损失、codebook损失和commitment损失。
β
β
β是权重因子。
S
g
Sg
Sg为停止梯度算子。

图2中,为了生成 W × H = 64 × 64 W × H = 64 × 64 W×H=64×64像素和 L = 10 L = 10 L=10帧的视频,VQ-VAE离散表示的大小为 w × h = 16 × 16 w × h = 16 × 16 w×h=16×16。因此,模型需要总共生成 M = 2560 M = 2560 M=2560个tokens。在生成第 8 个视觉token时,模型只关注前一帧(第 4 个视觉token)或同一帧中的前一个行或列标记(第 7 和第 6 个视觉token)中的相同位置token。
GODIVA视频生成器
本节中专注于通过对条件概率
P
(
z
∣
t
)
P(z|t)
P(z∣t)建模从文本中生成视频。给定一个具有
N
N
N个标记的输入文本
t
∈
R
N
t ∈ R^{N}
t∈RN,文本的嵌入是通过考虑位置信息来计算的,如Eq.(6)所示:
t
e
=
E
t
[
w
o
r
d
i
d
x
]
+
P
(
t
)
[
0
,
1
,
.
.
.
,
N
−
1
]
,
(6)
t^{e} =E^{t}[word_{idx}]+P^{(t)}[0,1,...,N-1], \tag{6}
te=Et[wordidx]+P(t)[0,1,...,N−1],(6)
其中
E
t
∈
R
S
×
D
E^{t} \in R^{S×D}
Et∈RS×D是文本嵌入矩阵,
S
S
S是文本词典大小,
P
(
t
)
∈
R
N
×
D
P^{(t)} \in R^{N×D}
P(t)∈RN×D是文本位置嵌入矩阵,
t
e
∈
R
N
×
D
t^{e} \in R^{N×D}
te∈RN×D是最后的文本嵌入。使用预训练的VQ-VAE编码器对GT视频中的每帧进行编码,如Eq.(7)所示:
b
(
l
)
=
B
[
arg
min
j
∣
∣
E
(
x
(
l
)
)
j
−
B
j
∣
∣
2
]
,
(7)
b^{(l)}=B[\underset{j}{\arg \min}||E(x^{(l)})_{j}-B_{j}||^{2}], \tag{7}
b(l)=B[jargmin∣∣E(x(l))j−Bj∣∣2],(7)
其中GT视频序列
x
∈
R
L
×
H
×
W
×
C
x \in R^{L×H×W×C}
x∈RL×H×W×C被编码为一系列离散的潜在视觉token嵌入
b
∈
R
M
×
d
B
b \in R^{M×d_{B}}
b∈RM×dB。
M
=
L
×
h
×
w
M = L×h×w
M=L×h×w是视觉tokens的最大值。Eq.(8)计算带有位置信息的算视频嵌入:
v
e
=
L
i
n
e
a
r
(
b
)
+
P
(
v
)
[
0
,
1
,
.
.
.
,
M
−
1
]
,
(8)
v^{e}=Linear(b)+P^{(v)}[0,1,...,M-1], \tag{8}
ve=Linear(b)+P(v)[0,1,...,M−1],(8)
其中线性层将
z
z
z映射到
L
i
n
e
a
r
(
z
)
∈
R
M
×
D
Linear(z) \in R^{M×D}
Linear(z)∈RM×D,和
t
e
t^{e}
te有相同的维度。
P
(
v
)
∈
R
M
×
D
P^{(v)} \in R^{M×D}
P(v)∈RM×D是视频位置嵌入矩阵。
v
e
∈
R
M
×
D
v^{e} \in R^{M×D}
ve∈RM×D是最后的GT视频嵌入。通过自回归的方式可以训练一个解码器生成视频,如公式9所示:
v
m
e
=
D
e
c
o
d
e
r
(
t
e
,
v
<
m
e
)
,
(9)
v^{e}_{m}=Decoder(t^{e}, v^{e}_{<m}), \tag{9}
vme=Decoder(te,v<me),(9)
其中
v
m
e
∈
R
D
v^{e}_{m} \in R^{D}
vme∈RD是在第m步抓换后的视觉嵌入。注意
M
M
M是一个很大的数字,特别是对于真实的视频。为了减少计算,在Eq.(10)中引入了三维稀疏注意层:
h
i
,
j
,
l
(
T
)
=
S
A
(
T
)
(
v
i
,
j
,
<
l
e
)
,
h
i
,
j
,
l
(
R
)
=
S
A
(
R
)
(
v
i
,
j
,
<
l
e
)
,
h
i
,
j
,
l
(
C
)
=
S
A
(
C
)
(
v
i
,
j
,
<
l
e
)
.
(10)
\begin{align*} h^{(T)}_{i,j,l}=SA^{(T)}(v^{e}_{i,j,<l}), \\ h^{(R)}_{i,j,l}=SA^{(R)}(v^{e}_{i,j,<l}), \\ h^{(C)}_{i,j,l}=SA^{(C)}(v^{e}_{i,j,<l}). \\ \end{align*} \tag{10}
hi,j,l(T)=SA(T)(vi,j,<le),hi,j,l(R)=SA(R)(vi,j,<le),hi,j,l(C)=SA(C)(vi,j,<le).(10)
其中
S
A
SA
SA表示自注意力层。
T
,
R
,
C
T,R,C
T,R,C分别表示时间,行和列。
h
i
,
j
,
l
(
T
)
,
h
i
,
j
,
l
(
R
)
,
h
i
,
j
,
l
(
C
)
∈
R
D
h^{(T)}_{i,j,l},h^{(R)}_{i,j,l},h^{(C)}_{i,j,l} \in R^{D}
hi,j,l(T),hi,j,l(R),hi,j,l(C)∈RD是
(
i
,
j
,
l
)
(i,j,l)
(i,j,l)步的隐状态。请注意,将步骤的符号从
m
m
m更改为
(
i
,
j
,
l
)
(i, j, l)
(i,j,l),以便更清楚地表达这三个稀疏注意力。由Eq.(10)可以看出,每个轴的稀疏注意只关注前一个轴上的索引,而不是全局轴上的索引。因此,计算复杂度从
O
(
(
L
h
w
)
2
)
O((Lhw)^{2})
O((Lhw)2)降低到
O
(
L
h
w
(
L
+
h
+
w
)
)
O(Lhw(L + h + w))
O(Lhw(L+h+w))。然后,将三个注意层交替堆叠,如Eq.(11)所示:
h
i
j
l
=
S
A
T
,
S
A
R
,
S
A
C
,
S
A
T
,
.
.
.
,
S
A
C
⏟
R
l
a
y
e
r
s
(
h
<
=
i
,
<
=
j
,
<
=
l
)
,
(11)
h_{ijl}=\underbrace{SA^{T},SA^{R},SA^{C},SA^{T},...,SA^{C}}_{R \, layers}(h_{<=i,<=j,<=l}), \tag{11}
hijl=Rlayers
SAT,SAR,SAC,SAT,...,SAC(h<=i,<=j,<=l),(11)
其中
h
∈
R
M
×
D
h \in R^{M×D}
h∈RM×D是这些堆叠注意力层的输出隐藏状态。然后,
h
h
h被送入到线性层以获得预测的视觉标记的logits,如Eq.(12)所示:
P
(
z
^
∣
t
)
=
s
o
f
t
m
a
x
(
L
i
n
e
a
r
(
h
)
)
,
(12)
P(\hat{z}|t) = softmax(Linear(h)), \tag{12}
P(z^∣t)=softmax(Linear(h)),(12)
其中线性层将
h
h
hd的维度映射到VQ-VAE词典大小
L
i
n
e
a
r
(
h
)
∈
R
M
×
K
Linear(h) \in R^{M×K}
Linear(h)∈RM×K。
z
^
∈
R
M
\hat{z} \in R^{M}
z^∈RM是预测的视觉tokens。最后模型使用交叉熵损失训练,如Eq.(13)所示:
L
=
−
1
M
∑
i
=
1
M
z
i
log
(
P
(
z
^
∣
t
)
)
(13)
L=-\frac{1}{M} \sum^{M}_{i=1}z_{i} \log(P(\hat{z}|t)) \tag{13}
L=−M1i=1∑Mzilog(P(z^∣t))(13)
实验
数据集
在Howto100M数据集上预训练GODIVA,该数据集包含超过136万个文本-视频对。在 MSR-VTT 数据集上评估,该数据集由 10000 个视频clip组成,每个视频clip有 20 个人工注释的标题。还在Moving Mnist数据集和Double Moving Mnist数据集上从头开始训练GODIVA,两者都是从Mnist数据集自动生成的。原始的Moving Mnist数据集有两种运动:上下和左右。本文增加了四个方向:先左后右、先右后左、先上后下、先下后上。
评价指标
定量评估文本到视频生成模型的性能具有挑战性。这主要是由于两个原因:首先,给定一个文本,有无数对应的视频,很难客观判断哪个更好。其次,评估指标应考虑生成视频的视觉质量和语义匹配。为了处理这些挑战,引入了两种指标:基于CLIP的Similarity (SIM) 度量和相对匹配 (RM) 度量自动评估指标以及视觉现实(VR)和语义一致性(SC)度量的人工评估指标
自动评估指标
判断生成视频质量的关键因素是它是否匹配文本。使用预训练的视觉语言匹配模型将不可避免地引入其领域数据的偏差。由于最近的零样本工作 CLIP,它为视觉文本匹配提供了强大的零样本能力,从而减少了这些数据偏差。由于CLIP是在图像和文本之间预先训练的,计算文本和视频的每一帧之间的相似度,然后将平均值作为Eq.(14)中的语义匹配。
S
I
M
(
t
,
v
^
)
=
1
L
∑
l
=
1
L
C
L
I
P
(
t
,
v
^
(
l
)
)
,
(14)
SIM(t, \hat{v})=\frac{1}{L} \sum^{L}_{l=1}CLIP(t, \hat{v}^{(l)}), \tag{14}
SIM(t,v^)=L1l=1∑LCLIP(t,v^(l)),(14)
其中
t
t
t表示输入文本。
v
^
\hat{v}
v^是预测的有
L
L
L帧的视频。注意
S
I
M
SIM
SIM仅仅 提供语义匹配的绝对值。为了进一步降低CLIP模型的影响,将SIM除以文本和GT真实视频之间的相似度,得到相对匹配分数,称之为相对匹配(RM)度量,如Eq.(15)所示:
R
M
(
t
,
v
^
)
=
S
I
M
(
t
,
v
^
)
S
I
M
(
t
,
v
)
,
(15)
RM(t, \hat{v})=\frac{SIM(t, \hat{v})}{SIM(t, v)}, \tag{15}
RM(t,v^)=SIM(t,v)SIM(t,v^),(15)
其中
v
v
v是有
L
L
L帧的GT视频。
R
M
RM
RM指标揭示了与领域无关的生成质量,因为如果生成的视频与文本更相关,显然具有更高的
R
M
RM
RM值。如果生成的视频与文本无关或质量低,则
R
M
RM
RM值将较低。
人工评估指标
为了进行人工评估,邀请 200 名评估者作为测试人员并进行人工评估。
{
M
1
,
M
2
,
.
.
.
,
M
N
}
\{M_{1}, M_{2},..., M_{N} \}
{M1,M2,...,MN}是一组要评估的模型,
T
T
T是测试集中的样本数。为了减少主观偏差,要求测试者将两个模
(
M
i
,
M
j
)
(M_{i},M_{j})
(Mi,Mj)生成的两个视频
(
v
i
,
v
j
)
(v_{i},v_{j})
(vi,vj)的视觉真实性(VR)和语义一致性(SC)分别与相同的查询
q
q
q进行比较,如Eq.(16)、(17)所示:
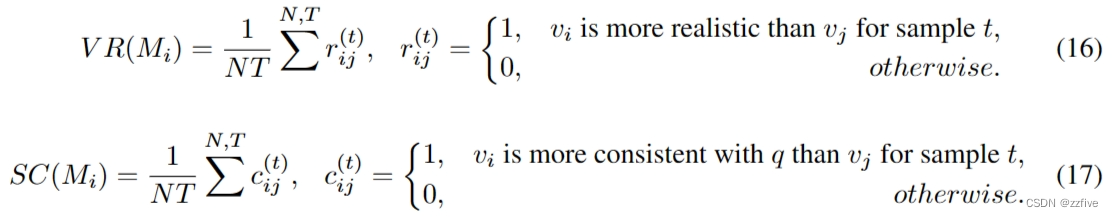
实施细节
输入视频的大小为 L = 10 , H = 64 , W = 64 , C = 3 L = 10, H = 64, W = 64, C = 3 L=10,H=64,W=64,C=3。Eq.(1)中的编码器 E E E和Eq.(4)中的解码器 D D D都是用两个CNN层实现的。核大小为 4,步幅为 2。因此潜在变量的大小为 h × w = 16 × 16 h × w = 16 × 16 h×w=16×16。潜在变量维度 d B = 128 d_{B} = 128 dB=128。Q-VAE码本共有 K = 10000 K = 10000 K=10000个tokens。VQ-VAE 模型在ImageNet上进行了预训练,学习率为1e-3,批量大小为32。注意,当对 Moving Mnist 数据集进行实验时,在该数据集上训练另一个 VQ-VAE。发现这将导致更好的生成性能。
输入文本的最大长度为 N = 35 N = 35 N=35。维度 D = 1024 D = 1024 D=1024。视觉标记的最大大小为 M = 2560 M = 2560 M=2560。Eq.(10)中的Self-Att使用16个注意头。GODIVA 在Eq.(11)中总共有 R = 12 R = 12 R=12层。 GODIVA 模型在具有 64 V100 GPU 基于Howto100M 数据集进行预训练。它在具有 8 个 V100 GPU 的 MSR-VTT 数据集上进行了微调。两种设置的批量大小为 32,学习率为 5e-4。
定性结果
从两个方面定性地评估本文模型。首先,通过将 GODIVA 与两种先前的方法进行比较来评估模型的零样本能力:T2V和TFGAN。这两种方法都是在从Kinetics和Youtube视频的清理创建的真实数据集上训练的。如图3所示,对于相同的查询“Play golf on grass”,T2V 以 64×64 的分辨率成功地生成了“playing golf”动作和草,但结果看起来很模糊(参见第一行)。TFGAN 以 128×128 的分辨率成功训练并生成更高质量的结果(参见第二行)。T2V 和 TFGAN 都生成与文本相关的视频,但生成的帧在单个场景中,帧之间的差异并不显着。这限制了神经模型的创造力。有趣的是,GODIVA 不仅生成与文本相关的视频,还生成更改场景(参见第三行和第四行)。例如,GODIVA(64×64) 首先显示草地场,然后给运动员一个特写镜头,最后是击中高尔夫球的动作。请注意,GODIVA(64×64) 和 GODIVA(128×128) 是不同的模型,因此它们生成了完全不同的视频。最后一行给出了 GODIVA 生成的另一个 (128×128) 分辨率结果。总的来说,GODIVA 能够生成具有清晰帧和连贯语义的视频。

其次,通过比较GODIVA和几种基于GAN的方法来评估未见过的视频生成能力。图(4)中的模型分别在Moving MNIST数据集和Double Moving MNIST数据集上进行训练。注意在训练集中没有一个视频的caption是“Digit 9 is moving down than up”,可能有一些像是的变体,如“Digit 9 is moving left and right”、“Digit 3 is moving down than up”。GODIVA 成功地生成了语义正确的结果(参见左侧部分的最后一行)。这表明 GODIVA 学习捕获文本和视频之间的语义对齐,而不仅仅是在训练集中搜索视频以找到与输入图像最相似的视频。此外,与最先进的 IRC-GAN 方法相比,GODIVA 生成高质量的视频。数字“9”在空间和时间上都是一致的。右侧Double Moving MNIST的另一个示例显示了类似的现象。

定量结果
通过自动和人工指标定量评估本文模型。为了验证RM度量的有效性,首先在图5(a)中绘制文本和地面真实视频之间的SIM分数。从对角线可以看出,SIM 基本上能够区分语义相似的视频和其他视频。表1显示了 GODIVA 不同设置的消融研究。在 Howto100M 数据集上预训练 GODIVA,并在 MSR-VTT 数据集上对其进行微调。发现 SIM 和 RM 与人类评估指标具有相同的趋势。第一行显示了输入文本和真实视频的结果。第二行表明,GODIVA 的足够规模至关重要。 GODIVA(6 层)表现出比默认的 GODIVA 设置(12 层)更差的性能。下三行显示了三维注意力的有效性。发现 Row Attention 是最重要的。在DALL-E之后,在推理过程中Eq.(12)的前10个概率中随机抽取32次,并使用CLIP排名找到最佳生成的视频。然后在 RM 指标中,性能显着提高到 98.34。


结论
本文提出了一种三维稀疏注意,使用VQ-VAE离散视觉标记从自然描述中生成开放域视频,提出了一种新的相对匹配度量来自动评估生成质量。实验表明,本文模型不仅可以在下游视频生成任务上进行微调,而且在看不见的文本上也具有良好的零样本能力。然而,仍然存在一些挑战:首先,生成高分辨率长视频仍然是一个挑战。当只生成具有10帧的64 × 64分辨率视频时,视觉tokens的总数 M M M已达到2560。其次,自动评估文本到视频的生成任务仍然是一个挑战。未来,基于视频的CLIP度量可以为文本和视频的语义一致性提供更准确的结果。第三,基于 GAN 的方法显示出文本到视频生成的巨大潜力(见图4),它们对开放域数据集的生成能力仍然是一个良好的研究方向。