NoSQL与Redis6新特性
什么是Redis
- REDIS一个开源的使用 ANSI
C 语言编写、遵守 BSD 协议、支持网络、可基于内存、分布式、可选持久性的键值对(Key-Value)存储数据库,并提供多种语言的 APIRedis的读写性能非常好,官方压测数据为 Redis能读的速度是110000次/s,写的速度是81000次/s - https://redis.io/
Redis的实际工作场景
- JD在若干高并发场景替代了MySQL
- JD商城环境下热点商品数据缓存
- 消息的订阅/发布(部分场景可取代MQ)
- 各种高频读,低频写的数据场景
-
- 排行榜 / 购物车 / 字典数据
- 提供分布式架构下的分布式锁
- 快速实现"交并差"运算
-
- 查询两个读者都买过哪些书籍
-
- 你的XX位好友也关注了这个频道
Redis 6 新特性
多线程IO
- redis 6.0 提供了多线程的支持,redis 6 以前的版本,严格来说也是多线程,只不过执行用户命令的请求时单线程模型,还有一些线程用来执行后台任务, 比如 unlink 删除 大key,rdb持久化等。
- redis 6.0 提供了多线程的读写IO,但是最终执行用户命令的线程依然是单线程的,这样就没有多线程数据的竞争关系,依然很高效。
客户端缓存
- redis 6 提供了服务端追踪key的变化,客户端缓存数据的特性,可以减少网络通信次数
提升了RDB日志加载速度
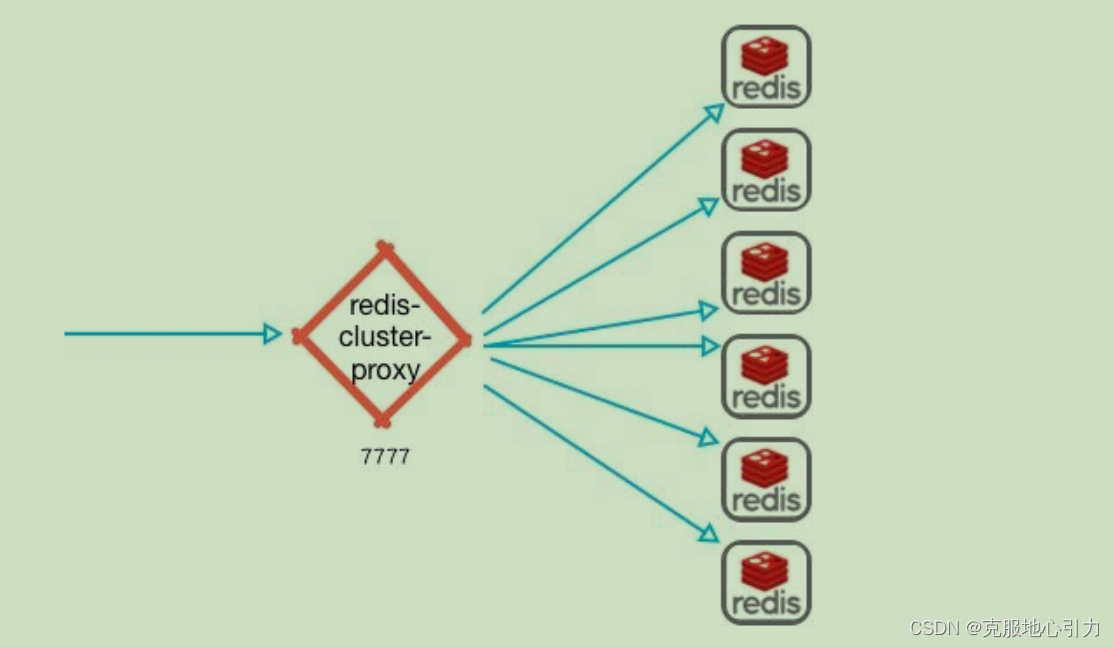
Redis集群代理模块 Redis Cluster proxy
- 在 Redis 集群中,客户端会非常分散,现在为此引入了一个集群代理,可以为客户端抽象Redis 群集,使其像正在与单个实例进行对话一样。同时在简单且客户端仅使用简单命令和功能时执行多路复用。
Linux 安装Redis 6
第一步,更新GCC
GCC是Linux C语言编译器,Redis采用最新版GCC才能编译通过
#安装gcc
yum install -y gcc-c++ autoconf automake
第二步,获取Redis源码,解压编译
cd /usr/local/
wget http://download.redis.io/redis-stable.tar.gz
tar xvzf redis-stable.tar.gz
cd redis-stable
make
echo "redis installed"
第三步,修改配置文件,修改ip访问权限
bind * -::*
第四步,防火墙放行6379端口
firewall-cmd --zone=public --add-port=6379/tcp --permanent
firewall-cmd --reload
第五步,按照修改的配置,重启redis服务器
./redis-server ../redis.conf
Redis数据类型-String
Redis 字符串数据类型的相关命令用于管理 redis 字符串值
应用场景
- 最常用的数据类型,通常用于保存单个对象/记录的数据 . 例如在Web应用中存储某个对象的
JSON文本
Redis String 命令
GET/SET - 获取/设置KV
Redis SET 命令用于设置给定 key 的值。如果 key 已经存储其他值, SET 就覆写旧值,
且无视类型。
redis> SET key "value"
OK
redis> GET key
"value"
GETSET - 获取设置值KV
Redis Getset 命令用于设置指定 key 的值,并返回 key 的旧值。
redis> GETSET db mongodb # 没有旧值,返回 nil
(nil)
redis> GET db
"mongodb"
redis> GETSET db redis # 返回旧值 mongodb
"mongodb"
redis> GET db
"redis"
MGET/MSET命令-批量获取/设置
Redis Mget 命令返回所有(一个或多个)给定 key 的值。 如果给定的 key 里面,有某个 key 不
存在,那么这个 key 返回特殊值 nil 。
redis 127.0.0.1:6379> SET key1 "hello"
OK
redis 127.0.0.1:6379> SET key2 "world"
OK
redis 127.0.0.1:6379> MGET key1 key2 someOtherKey
1) "Hello"
2) "World"
3) (nil)
Redis Mset 命令用于同时设置一个或多个 key-value 对。
redis 127.0.0.1:6379> MSET key1 "Hello" key2 "World"
OK
redis 127.0.0.1:6379> GET key1
"Hello"
redis 127.0.0.1:6379> GET key2
1) "World"
SETNX - NIL时设置
Redis Setnx(SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
redis> EXISTS job # job 不存在
(integer) 0
redis> SETNX job "programmer" # job 设置成功
(integer) 1
redis> SETNX job "code-farmer" # 尝试覆盖 job ,失败
(integer) 0
redis> GET job # 没有被覆盖
"programmer"
Redis INCR - 数据自增
Redis Incr 命令将 key 中储存的数字值增一。
如果 key 不存在,那么 key 的值会先被初始化为 0 ,然后再执行 INCR 操作。如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。本操作的值限制在 64 位(bit)有符号数字表示之内。
redis> SET page_view 20
OK
redis> INCR page_view
(integer) 21
redis> GET page_view # 数字值在 Redis 中以字符串的形式保存
"21"
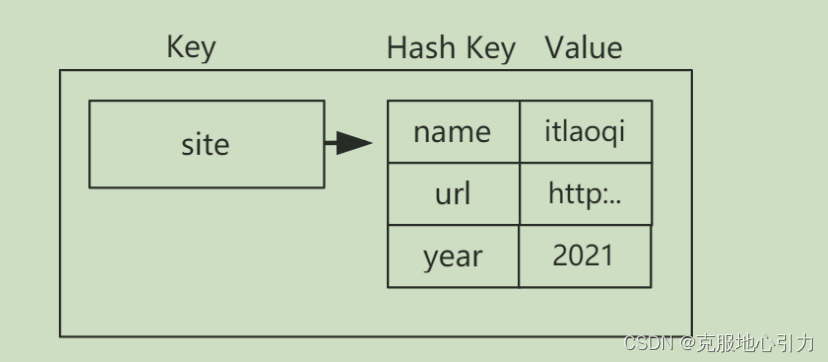
Redis数据类型-Hash
Redis hash 是一个 string 类型的 field(字段) 和 value(值) 的映射表,hash 特别适合用于存储对象。Redis 中每个 hash 可以存储 232 - 1 键值对(40多亿)。
你可以形象的看成每一个Key存储了一个HashMap对象,通过一个Key可以保存一个数据结构。
Redis Hash 命令
HSET 设置单个Hash键值对
redis> HSET myhash field1 "foo"
OK
redis> HGET myhash field1
"foo"
redis> HSET website google "www.g.cn"
(integer) 1
redis>HSET website google "www.google.com"
(integer) 0
HMSET一次性设置多个HASH KV
redis> HMSET myhash field1 "Hello" field2 "World"
OK
redis> HGET myhash field1
"Hello"
redis> HGET myhash field2
"World"
HGET 获取某个redis key的某个hash值
redis> HSET site website google
(integer) 1
redis> HGET site website
"google"
HGETALL 获取某个Key下的所有数据
redis> HSET myhash field1 "Hello"
(integer) 1
redis> HSET myhash field2 "World"
(integer) 1
redis> HGETALL myhash
1) "field1"
2) "Hello"
3) "field2"
4) "World"
redis>
HEXISTS 判断某个Hash Key是否存在
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HEXISTS myhash field1
(integer) 1
redis 127.0.0.1:6379> HEXISTS myhash field2
(integer) 0
HDEL 删除某个Key下的Hash Key
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HDEL myhash field1
(integer) 1
redis 127.0.0.1:6379> HDEL myhash field2
(integer) 0
HVALS 返回HASH VALUE的列表。 当 key 不存在时,返回一个空表。
redis 127.0.0.1:6379> HSET myhash field1 "foo"
(integer) 1
redis 127.0.0.1:6379> HSET myhash field2 "bar"
(integer) 1
redis 127.0.0.1:6379> HVALS myhash
1) "foo"
2) "bar"
Redis数据类型-List
List列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者部(右边)
一个列表最多可以包含 2的32次方 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
应用场景
保存有序数据队列,例如: 排行榜ID队列 / XX购物车商品ID队列 / XX班级ID队列
获取到ID队列后,再根据每一个ID获取对应的HASH对象
Redis List 命令
rpush 在队尾插入新数据
> rpush listkey c b a
3
lpush 在队首插入新数据
> lpush listkey f e d
6
lrange 获取队列数据 -1获取所有
> lrange listkey 0 -1
d
e
f
c
b
a
> lrange listkey 0 2
d
e
f
rpop 弹出最右侧数据
> RPOP listkey
a
> lrange listkey 0 -1
d
e
f
c
b
lpop 弹出最左侧数据
> LPOP listkey
d
> lrange listkey 0 -1
e
f
c
b
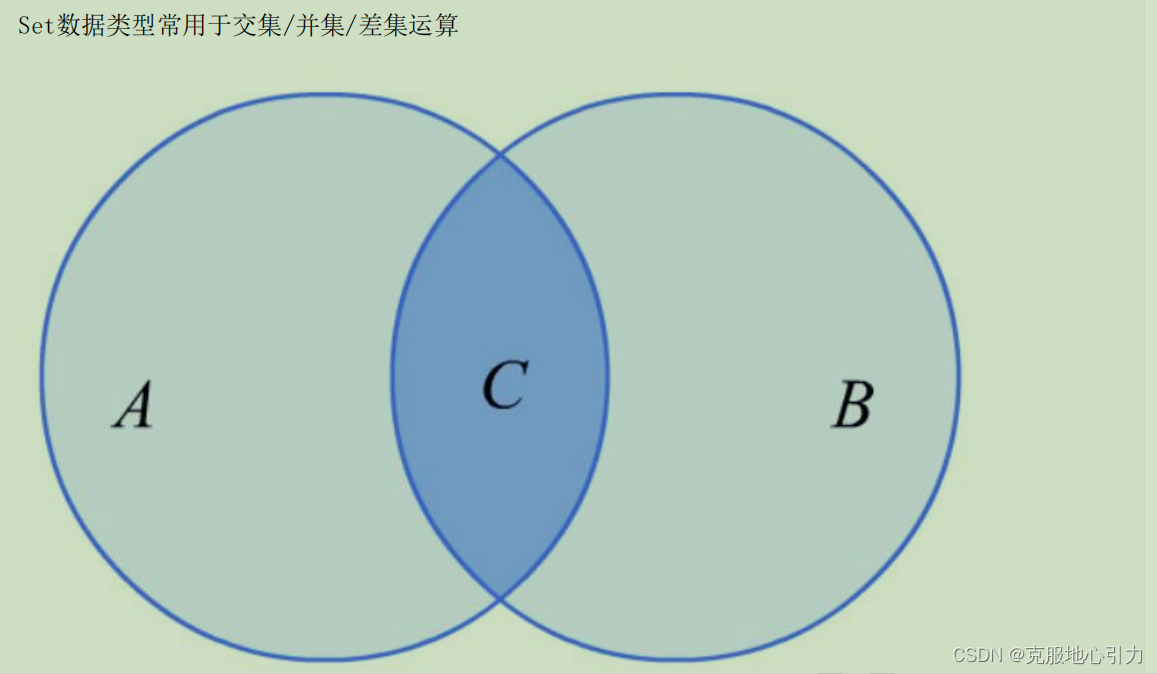
Redis数据类型-Set
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。
Redis 中Set集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1),对Set操作的执行效率极高。
集合中最大的成员数为 232 - 1 (4294967295, 每个集合可存储40多亿个成员)。
应用场景
Redis Set命令
sadd 新增SET 数据
> sadd user:1:follow it
1
smembers 查看Set数据
> smembers user:1:follow
it
> sadd user:1:follow music
1
> sadd user:1:follow his
1
> sadd user:1:follow sports
1
> sadd user:1:follow it
0
> smembers user:1:follow
sports
music
his
it
srandmember 随机提取n个数据 总数不变 抽奖
> srandmember user:1:follow 2
sports
his
> srandmember user:1:follow 2
it
his
spop 随机弹出一个元素 总数减少 抽奖
> spop user:1:follow
sports
> smembers user:1:follow
it
his
music
sdiff 计算差集
> sadd user:2:follow it news ent sports
4
> sdiff user:1:follow user:2:follow
music
his
> sdiff user:2:follow user:1:follow
sports
ent
news
注意:sdiff计算的是以左侧Set为基准,查找在右侧Set不存在的条目
sinter 计算交集 共同好友
> sinter user:1:follow user:2:follow
it
sunion 计算并集
> sunion user:1:follow user:2:follow
sports
it
his
music
ent
news
Redis数据类型-ZSet
Redis 的 ZSet 是 String 类型的有序Set集合,很多地方也被称为SortedSet,Set集合成员是唯一的,这就意味着集合中不能出现重复的数据。
List与ZSet的区别
- List强调数据是按存储顺序有序排列,存储顺序与迭代顺序是一致的
- ZSet则是给出分数进行排序,存储顺序与迭代顺序是不一致的
应用场景
各种多维度排行榜

Redis ZSet命令
zadd - 新增数据
> zadd player:rank 1000 ronaldo 900 messi 800 cronaldo 600 kaka
4
zscore - 获取分数
> zscore player:rank kaka
600
zcard - 获取ZSet总量
> zcard player:rank
4
zrank 查看排名(从小到大,从0开始)
> zrank player:rank ronaldo
3
zrem 移除指定元素
> zrem player:rank messi
1
zrange 获取指定范围集合
> zrange player:rank 0 -1
kaka
cronaldo
ronaldo
> zrange player:rank 0 -1 withscores
kaka
600
cronaldo
800
ronaldo
1000
zrevrange 反向排序
> zrevrange player:rank 0 -1 withscores
ronaldo
1000
messi
900
cronaldo
800
zcount 获取符合分数要求数据量
> zcount player:rank 700 1000
2
zrangebyscore 按分数范围获取数据
> zrangebyscore player:rank 700 1000 withscores
cronaldo
800
ronaldo
1000
Redis通用命令
Redis通用命令是Redis全局的管理命令,例如删除Redis Key / 设置过期时间 / 切换数据库都属于通用命令的范畴
Redis通用命令
select 切换数据库
Redis 默认拥有0~15号数据库,通过select命令进行切换,不同数据库间在内存存储上是隔离的,不同数据库允许持有相同的KV
> select 0
OK
> select 10
OK
> select 20
ERR DB index is out of range
> select 15
OK
keys 查询复合表达式要求的Redis key
keys时间复杂度是0(n),会进行"全库扫描",执行效率差,不建议使用
> set hello world
OK
> set java best
OK
> keys he[h-l]*
hello
exists 判断key是否存在
> EXISTS hello
1
> exists hello1
0
expire 设置key过期时长(秒),过期后该key自动删除
> set helloworld java
OK
> expire helloworld 3600
1
ttl 查询key剩余有效期
> ttl helloworld
3590
> ttl helloworld
3589
> ttl helloworld
3588
del 删除指定key
> del helloworld
1
flushdb 清空当前数据库,慎用慎用
> flushdb
OK
flushall 轻松所有数据库,慎用慎用慎用
> flushall
OK
Redis基础设置
几乎所有的Redis配置信息都保存在redis.conf文件中,其中以下几项是最关键的,在这里我们进行讲解
#面向所有IP开放
bind * -::*
#绑定端口号
port 6379
#采用后台方式运行
daemonize yes
#数据库总量
databases 16
#日志文件存储路径
logfile ./redis_log.log
#数据文件保存路径
dir ./
#设置访问密码
requirepass 123456
#启动redis命令
[root@localhost redis-stable]# ./src/redis-server ./redis.conf
#关闭redis命令
[root@localhost redis-stable]# ./src/redis-cli -p 6379
127.0.0.1:6379> auth 123456
127.0.0.1:6379> shutdown save
Redis开发规约
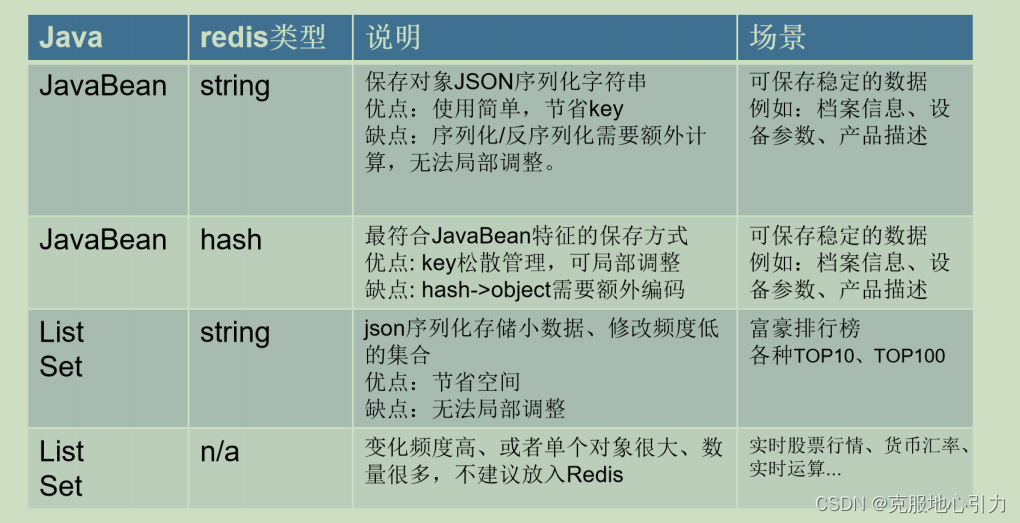
key的设计

不同类型的应用场景
Redis的安全建议
- Redis不要在外网被访问,禁止:bind 0.0.0.0
bind 192.168.132.128 - 更改Redis端口,不要6379
port 8838 - Redis使用非root启动
- Redis没有设置密码或者弱密码,不要与登录密码相同
requirepass 与masterauth - 定期备份,save命令
- 配置好Linux防火墙规则
Spring Boot与Redis交互
Spring Boot 内置了spring-boot-starter-data-redis这个模块用于简化Spring与Redis的交互过程.
Spring-data-redis是spring大家族的一部分,提供了在spring应用中通过简单的配置访问redis服务,对reids底层开发包(Jedis, JRedis, and RJC)进行了高度封装,RedisTemplate提供了redis各种操作、异常处理及序列化,支持发布订阅,并对spring 3.1cache进行了实现。
引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
额外引入commons-pool2是因为data-redis底层Redis连接池基于apachecommonspool2开发,不加入依赖回报ClassNotFoundException
注意
- Spring Boot 2后默认使用Lettuce作为访问redis的客户端。
- Lettuce是一个可伸缩线程安全的Redis客户端,它利用优秀netty NIO框架来高效地管理连接池。
- 旧版本lettuce存在堆外内存溢出的bug, 5.3版本修复了这个bug, 我们是用 6.1。
配置application.yml
starter-data-redis默认利用lettuce作为连接池组件,配置时除了配置Redis连接信息外,还需要设置连接池
server:
port: 80
spring:
redis:
host: 192.168.31.103
port: 6379
password: 123456
#设置默认访问的数据库
database: 1
#设置超时时间
timeout: 2000
lettuce:
pool:
#最大允许连接数
max-active: 100
#最小空闲连接数,最少准备5个可用连接在连接池候着
min-idle: 5
#最大空闲连接数,空闲连接超过10个后自动释放
max-idle: 10
#当连接池到达上限后,最多等待30秒尝试获取连接,超时报错
max-wait: 30000
利用RedisTemplate对象开发
spring-redis中使用了RedisTemplate来进行redis的操作,在Spring Boot IoC容器启动后创建,在应用中可以直接注入使用
@SpringBootTest
public class RedisTemplateTestor {
@Resource
private RedisTemplate redisTemplate;
@Test
public void testString(){
redisTemplate.opsForValue().set("name" , "itlaoqi");
Map map = new HashMap();
map.put("a", "b");
redisTemplate.opsForValue().set("age" , map);
String name = (String)redisTemplate.opsForValue().get("name");
System.out.println(name);
Map age = (Map)redisTemplate.opsForValue().get("age");
System.out.println(age);
}
@Test
public void testHash(){
redisTemplate.opsForHash().put("website" , "name" , "IT老齐");
Map map = new HashMap<>();
map.put("name", "张三");
map.put("hiredate", "2021-05-06");
redisTemplate.opsForHash().putAll("employee",map);
Map employee = redisTemplate.opsForHash().entries("employee");
System.out.println(employee);
}
@Test
public void testBasic(){
redisTemplate.expire("employee", 30, TimeUnit.MINUTES);
redisTemplate.delete("employee");
}
@Test
public void testList(){
redisTemplate.opsForList();
}
@Test
public void testSet(){
redisTemplate.opsForSet();
}
@Test
public void testZset(){
redisTemplate.opsForZSet();
}
}
详细看这里
RedisTemplate常用方法总结
Spring Boot Redis序列化问题
什么是序列化
把对象转换为字节序列的过程称为对象的序列化。
把字节序列恢复为对象的过程称为对象的反序列化。
对象的序列化主要有两种用途
- 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中
- 在网络上传送对象的字节序列。
Redis为什么要序列化
- 性能可以提高,不同的序列化方式性能不一样
- 可视化工具更好查看
Spring Boot 序列化问题的由来
默认情况下,Redis缓存和Redis模板配置为使用Java本地序列化。Java本地序列化以允许运行由有效远程代码而闻名,但执行过程中可能出现向存在漏洞的库和类注入字节码的骚操作,别有用心的人可以在反序列化过程使应用程序中运行额外(恶意)的代码。因此,不要在不受信任的环境中使用序列化。一般来说,我们强烈推荐任何其他消息格式(如JSON)。如果您担心由于Java序列化而导致的安全漏洞,请考虑核心JVM级别的通用序列化过滤器机制,该机制最初是为JDK9开发的,但后来向后移植到JDK8、7.
自定义redis序列化方式,提供了多种可选择策略
-
JdkSerializationRedisSerializer
POJO对象的存取场景,使用JDK本身序列化机制,默认机制
ObjectInputStream/ObjectOutputStream进行序列化操作 -
StringRedisSerializer
Key或者value为字符串 -
Jackson2JsonRedisSerializer
利用jackson-json工具,将pojo实例序列化成json格式存储 -
GenericFastJsonRedisSerializer
另一种javabean与json之间的转换,同时也需要指定Class类型
Jackson对象序列化
@Configuration
public class RedisTemplateConfiguration {
@Bean
public RedisTemplate<Object,Object> redisTemplate(RedisConnectionFactory factory){
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(factory);
// 使用Jackson2JsonRedisSerialize 替换默认序列化
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
//忽略任何值为null的属性
objectMapper.setSerializationInclusion(JsonInclude.Include.NON_NULL);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
// 设置key和value的序列化规则
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
// 设置hashKey和hashValue的序列化规则
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
//afterPropertiesSet和init-method之间的执行顺序是afterPropertiesSet 先执行,init-method 后执行。
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
}
Spring Cache声明式事务
自Spring 3.1版本以来,Spring框架支持低侵入的方式向已有Spring应用加入缓存特性。与声明式事务类似,声明式缓存Spring Cache抽象允许一致的API来已支持多种不同的缓存解决方案,同时将对代码的影响减少到最小。
从Spring 4.1开始,Spring已完整支持JSR-107注解和更多的定制选项。

区分Cache与Buffer
很多情况下,Buffer(缓冲)与Cache(缓存)是类似的。然而在表现形式与应用场景上两个的差别还是比较明显的。传统意义上,Buffer作为快速实体与慢速实体之间的桥梁。比如:硬盘上的文件数据会先到内存,再被CPU加载,内存作为Buffer可以减少等待时间,同时利用Buffer可将原本小块数据攒成整块一次性交给处理者,可以有效减少IO。此外,通常至少有一个对象对其可见。
而Cache缓存,相对来说是隐藏的,对于访问者与被访问者来说应该是隐藏的,好的程序设计可以让使用者对缓存无感知,同时它还可以提高性能,允许应用多次、快速的读取缓存数据。
如何使用Spring Cache
第一步,开启Spring Cache
@SpringBootApplication
@EnableCaching //通知Spring Boot启用声明式缓存
public class SpbRedisApplication {
public static void main(String[] args) {
SpringApplication.run(SpbRedisApplication.class, args);
}
}
第二步,在Service方法层面使用@Cacheable等注解声明式的控制缓存
@Service
public class EmpService {
@Resource
EmpDAO empDao;
//对于默认情况下, Redis对象的序列化使用的是JDK序列化.必须要求实体类实现Serili..接口
//Cacheable会将方法的返回值序列化后存储到redis中,key就是参数执行的字符串
//Cacheable的用途就是在执行方法前检查对应的key是否存在,存在则直接从redis中取出不执行方法中的代码
//没有对应的key则执行方法代码,并将返回值序列化保存到redis中
//condition代表条件成立的时候才执行缓存的数据 , 反之有一个unless ,代表条件不成立的时候才获取缓存
@Cacheable(value = "emp" , key = "#empId" ,condition = "#empId != 1000" ,cacheManager = "cacheManager1m")
public Emp findById(Integer empId) {
return empDao.findById(empId);
}
@Cacheable(value = "emp:rank:salary")
public List<Emp> getEmpRank() {
return empDao.selectByParams();
}
//@CachePut 更新缓存,没有key则创建
@CachePut(value="emp" , key="#emp.empno")
public Emp create(Emp emp) {
return empDao.insert(emp);
}
@CachePut(value="emp" , key="#emp.empno")
public Emp update(Emp emp) {
return empDao.update(emp);
}
//@CacheEvict 删除缓存
@CacheEvict(value = "emp",key = "#empno")
public void delete(Integer empno) {
empDao.delete(empno);
}
}
第三步,做一个测试用例,验证缓存是否生效
@SpringBootTest
public class SpringCacheTestor {
@Resource
private EmpService empService;
@Test
public void testFindById(){
Emp emp = empService.findById(1001);
emp = empService.findById(1001);
emp = empService.findById(1001);
emp = empService.findById(1001);
emp = empService.findById(1001);
emp = empService.findById(1001);
System.out.println(emp.getName());
emp = empService.findById(1000);
emp = empService.findById(1000);
emp = empService.findById(1000);
System.out.println(emp.getName());
}
@Test
public void testEmpRank() {
List<Emp> list = empService.getEmpRank();
list = empService.getEmpRank();
for(Emp emp:list){
System.out.println(emp);
}
}
@Test
public void testCreate(){
empService.create(new Emp(1002 , "emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
empService.create(new Emp(1002 , "emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
empService.create(new Emp(1002 , "emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
Emp emp = empService.findById(1002);
System.out.println(emp);
}
@Test
public void testUpdate(){
empService.update(new Emp(1002 , "u-emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
empService.update(new Emp(1002 , "u-emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
empService.update(new Emp(1002 , "u-emp" + new Date().getTime() , new Date() , 1234f , "MARKET"));
Emp emp = empService.findById(1002);
System.out.println(emp);
}
@Test
public void testDelete(){
empService.delete(1002);
//Emp emp = empService.findById(1002);
//System.out.println(emp);
}
}
Spring Cache的亿点点细节调整
在使用Spring Cache的时候有有三点困扰
- 默认Spring Cache采用 :: 分割数据,并不是约定俗称的 冒号 分割
- 默认使用JDK序列化,JDK序列化的问题之前我们也提到了,应该为JSON序列化
- 默认Spring Cache注解是不支持Expire过期的,但这是日常开发中必然会用到的特性,该如何处理呢?
通过自定义CacheManager解决上述问题
@Configuration
public class SpringCacheConfgiration {
@Bean
@Primary //设置默认的CacheManager
public CacheManager cacheManager(LettuceConnectionFactory factory){
//加载默认Spring Cache配置信息
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//设置有效期为1小时
config = config.entryTtl(Duration.ofHours(1));
//说明缓存Key使用单冒号进行分割
config = config.computePrefixWith(cacheName -> cacheName + ":");
//Redis Key采用String直接存储
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
//Redis Value则将对象采用JSON形式存储
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//不缓存Null值对象
config = config.disableCachingNullValues();
//实例化CacheManger缓存管理器
RedisCacheManager cacheManager = RedisCacheManager.RedisCacheManagerBuilder
//绑定REDIS连接工厂
.fromConnectionFactory(factory)
//绑定配置对象
.cacheDefaults(config)
//与声明式事务注解@Transactional进行兼容
.transactionAware()
//完成对象构建
.build();
return cacheManager;
}
@Bean
public CacheManager cacheManager1m(LettuceConnectionFactory factory){
//加载默认Spring Cache配置信息
RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();
//设置有效期为1小时
config = config.entryTtl(Duration.ofMinutes(1));
//说明缓存Key使用单冒号进行分割
config = config.computePrefixWith(cacheName -> cacheName + ":");
//Redis Key采用String直接存储
config = config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));
//Redis Value则将对象采用JSON形式存储
config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer()));
//不缓存Null值对象
config = config.disableCachingNullValues();
//实例化CacheManger缓存管理器
RedisCacheManager cacheManager = RedisCacheManager.RedisCacheManagerBuilder
//绑定REDIS连接工厂
.fromConnectionFactory(factory)
//绑定配置对象
.cacheDefaults(config)
//与声明式事务注解@Transactional进行兼容
.transactionAware()
//完成对象构建
.build();
return cacheManager;
}
}
在Service使用时,如果需要特别的过期时间,需要在@Cacheable增加cacheManager属性
@Cacheable(value = "emp" , key = "#empId" ,condition = "#empId != 1000" ,
cacheManager = "cacheManager1m")
public Emp findById(Integer empId) {
return empDao.findById(empId);
}
Redis数据持久化之RDB
Redis持久化介绍
Redis是一个内存数据库,如果没有配置持久化,redis重启后数据就全丢失
因此开启redis的持久化功能,将数据保存到磁盘上,当redis重启后,可以从磁盘中恢复数据。
RDB (Redis DataBase) 全量二进制备份
在指定的时间间隔内将内存中的数据集快照写入磁盘
默认的文件名为dump.rdb
RDB快照的应用场景
save
会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止bgsave
fork创建子进程,RDB持久化过程由子进程负责,会在后台异步进行快照操作,快照同时还可以响应客户端请求- 自动化触发
配置文件来完成,配置触发 Redis的 RDB 持久化条件
比如 “save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave - 主从架构
从服务器同步数据的时候,会发送sync执行同步操作,master主服务器就会执行bgsave
优点
RDB文件紧凑,全量备份,适合用于进行备份和灾难恢复
在恢复大数据集时的速度比 AOF 的恢复速度要快
生成的是一个紧凑压缩的二进制文件
缺点
每次快照是一次全量备份,fork子进程进行后台操作,子进程存在开销
在快照持久化期间修改的数据不会被保存,可能丢失数据
关于RDB的关键配置
Redis.conf
#持久化文件名称
dbfilename itlaoqi.rdb
#持久化文件存储路径
dir /usr/local/redis/data
#持久化策略, M秒内有个n个key改动,执行快照
save 3600 1
save 300 100
save 60 10000
#导出rdb数据库文件压缩字符串和对象,默认是yes,会浪费CPU但是节省空间
rdbcompression yes
#导入时是否检查
rdbchecksum yes
Redis数据持久化之AOF
AOF (append only file)增量日志
追加文件的方式,文件容易被人读懂
以独立日志的方式记录每次写命令, 重启时再重新执行AOF文件中的命令达到恢复数据的目的
写入过程宕机,也不影响之前的数据,可以通过 redis-check-aof检查修复问题
核心原理
Redis每次写入命令会追加到aof_buf(缓冲区)
新增x1:v1
新增x2:v2
删除x2
新增x3:v3
覆盖x4:v4
AOF缓冲区根据对应的策略向硬盘做同步操作
高频AOF会带来影响,特别是每次刷盘
同步方式
提供了3种同步方式,在性能和安全性方面做出平衡
appendfsync always
每次有数据修改发生时都会写入AOF文件,消耗性能多appendfsync everysec
每秒钟同步一次,该策略为AOF的缺省策略。appendfsync no
不主从同步,由操作系统自动调度刷磁盘,性能是最好的,但是最不安全
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
AOF Rewrite重写机制
AOF文件越来越大,需要定期对AOF文件进行重写达到压缩
旧的AOF文件含有无效命令会被忽略,保留最新的数据命令
多条写命令可以合并为一个
AOF重写降低了文件占用空间
更小的AOF 文件可以更快地被Redis加载
示例:
新增x1:v1
覆盖x1:v2
覆盖x1:v3
覆盖x1:v4
删除x1
新增x1:v5
Rewrite以后
新增x4:v5
重写触发配置
- 手动触发
bgrewriteaof - 自动触发
-
auto-aof-rewrite-percentage 100
-
- Redis记住上次重写时AOF日志的大小,
比如上一次重写后50mb,当增长率达到100%,
也就是AOF文件达到50+50=100mb后,就会
自动触发rewrite.60mb = 120mb
- Redis记住上次重写时AOF日志的大小,
-
auto-aof-rewrite-min-size 50mb 设置触发Rewrite的最小尺寸
# 是否开启aof
appendonly yes
# 文件名称
appendfilename "appendonly.aof"
# 同步方式,每秒同步
appendfsync everysec
# aof重写期间是否同步
no-appendfsync-on-rewrite no
# 重写触发配置
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 50mb
# 加载aof时如果有错如何处理
# yes表示如果aof尾部文件出问题,写log记录并继续执行。no表示提示写入等待修复后写
入
aof-load-truncated yes
AOF与RDB的取舍
RDB持久化以指定的时间间隔执行数据集的时间点快照。
AOF持久化记录服务器接收的每个写入操作,将在服务器启动时再次读取,重建原始数据。
集。使用与Redis协议本身相同的格式以仅追加方式记录命令,当文件太大时,Redis能够重写。
RDB的优缺点
- 优点
-
- RDB最大限度地提高了Redis的性能,父进程不需要参与磁盘I/O
-
- RDB文件紧凑,全量备份,适合用于进行备份和灾难恢复
-
- 在恢复大数据集时的速度比 AOF 的恢复速度要快
-
- 生成的是一个紧凑压缩的二进制文件
- 缺点
-
- 如果您需要在Redis停止工作时(例如断电后)将数据丢失的可能性降至最低,则RDB并不好
-
- RDB经常需要fork才能使用子进程持久存储在磁盘上。如果数据集很大,Fork可能会非常耗时
AOF的优缺点
- 优点
-
- 数据更加安全
-
- 当Redis AOF文件太大时,Redis能够在后台自动重写AOF
-
- AOF以易于理解和解析的格式,一个接一个地包含所有操作的日志
- 缺点
-
- AOF文件通常比同一数据集的等效RDB文件大
-
- 根据确切的fsync策略,恢复的时候AOF可能比RDB慢
在线上我们到底该怎么做?
- AOF通常作为RDB的补充使用
- 如果Redis中的数据并不是特别敏感或者可以通过其它方式重写生成数据,集群中可以关闭AOF持久化,靠集群的备份方式保证可用性
- 自己制定策略定期检查Redis的情况,然后可以手动触发备份、重写数据;
Redis4.0后开始的rewrite支持混合模式
就是RDB和AOF一起用
直接将rdb持久化的方式来操作将二进制内容覆盖到aof文件中,rdb是二进制,所以很小
有写入的话还是继续append追加到文件原始命令,等下次文件过大的时候再次rewrite
默认是开启状态
AOF日志↓↓↓↓
新增x1:v1
覆盖x1:v2
覆盖x1:v3
覆盖x1:v4
删除x1
新增x1:v5
新增x2:v6
混合模式Rewrite以后
RDB部分(二进制压缩表达):
x1:v5
AOF日志:↓↓↓
新增x3:v7
- 好处
-
- 混合持久化结合了RDB持久化 和 AOF 持久化的优点,采取了rdb的文件小易于灾难恢复
-
- 同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失
- 坏处
-
- 前部分是RDB格式,是二进制,所以阅读性较差
数据恢复
- 先看是否存在aof文件,若存在则先按照aof文件恢复,aof比rdb全,且aof文件也rewrite成rdb二进制格式
- 若aof不存在,则才会查找rdb是否存在
Redis主从复制实战
…