基于ChatGLM-6B的推理与部署
1.使用git clone命令ChatGLM项目地址,将项目clone到本地。
2.下载ChatGLM-6B模型文件
【注意】运行下面代码的时候,要将源代码中的模型文件路径改成自己的地址,不然会报错!!!
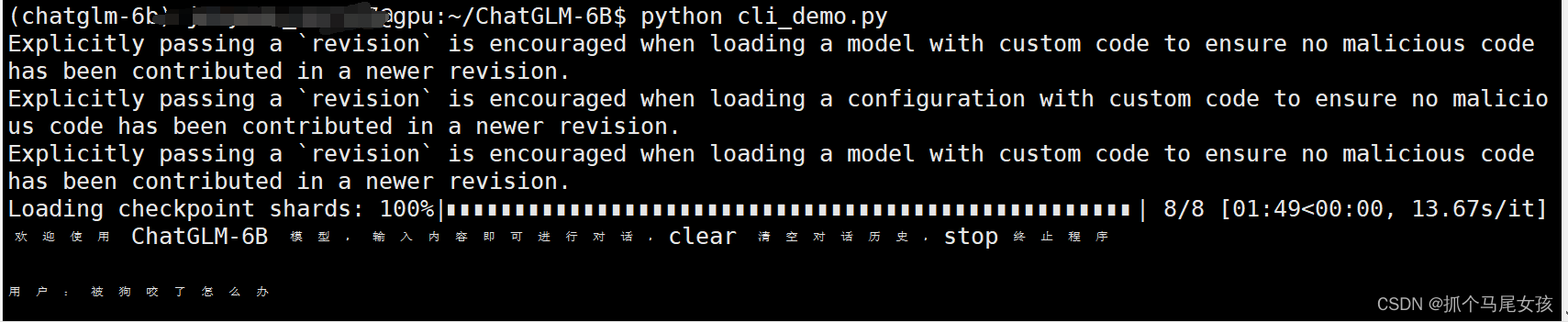
运行以下代码可以在命令行中与ChatGLM进行交互式的对话
python cli_demo.py

运行以下代码可以在网页与ChatGLM进行交互式的对话
python web_demo.py
微调
①从仓库中下载微调的项目
git clone https://github.com/mymusise/ChatGLM-Tuning.git
②配置环境
conda create -n torch1.13 python==3.8
conda activate torch1.13
pip install bitsandbytes==0.37.1
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install accelerate==0.17.1
pip install tensorboard==2.10
pip install protobuf==3.19.5
pip install transformers==4.27.1
pip install icetk
pip install cpm_kernels==1.0.11
pip install datasets==2.10.1
pip install git+https://github.com/huggingface/peft.git # 最新版本 >=0.3.0.dev0
③下载ChatGLM模型地址

④数据处理
python cover_alpaca2jsonl.py \
--data_path data/alpaca_data.json \
--save_path data/alpaca_data.jsonl \
⑤运行 tokenize_dataset_rows.py 文件
【注】这里需要把tokenize_dataset_rows.py 中的model_name改为自己ChatGLM的地址。
【报错】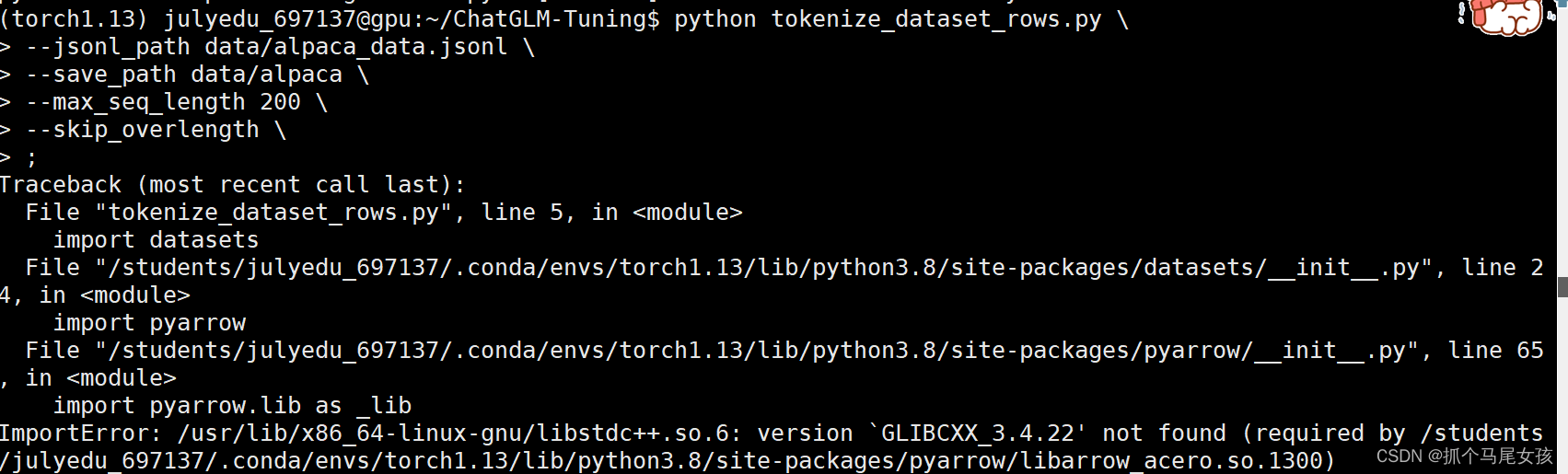
解决方法
pip install pyarrow==6.0.0
python tokenize_dataset_rows.py \
--jsonl_path data/alpaca_data.jsonl \
--save_path data/alpaca \
--max_seq_length 200 \
--skip_overlength False \
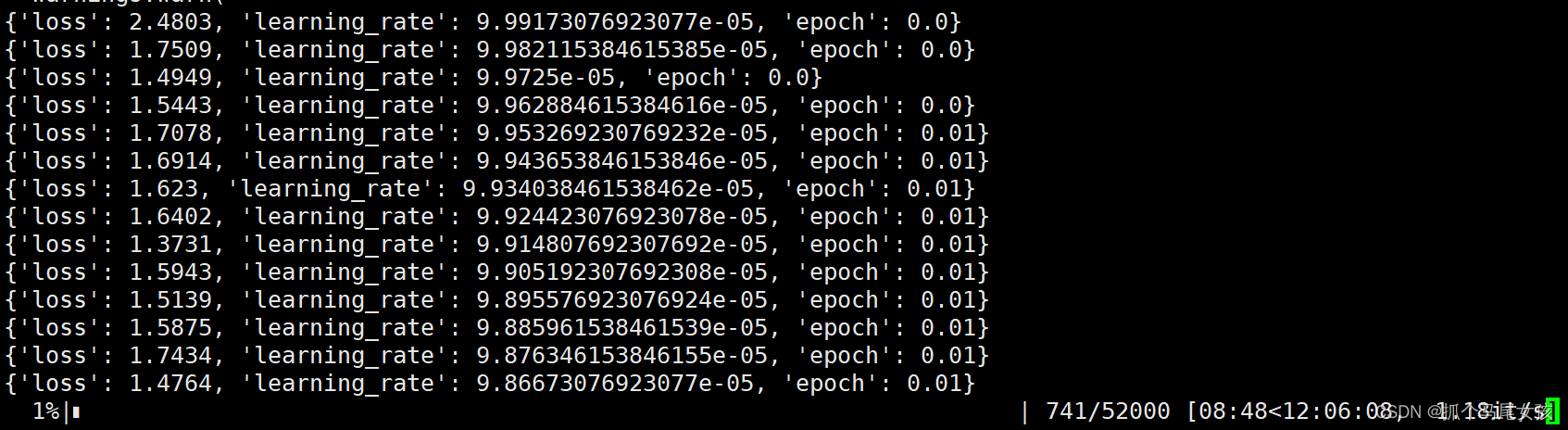
⑥微调
【注】这里需要把finetune.py 中的模型地址改为自己ChatGLM的地址。
python finetune.py \
--dataset_path data/alpaca \
--lora_rank 8 \
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 1 \
--max_steps 52000 \
--save_steps 1000 \
--save_total_limit 2 \
--learning_rate 1e-4 \
--fp16 True \
--remove_unused_columns false \
--logging_steps 50 \
--output_dir output;